







 本文介绍在.NET Core环境下读取中文编码文件的解决方案,通过注册CodePagesEncodingProvider并使用GB2312编码读取文件,成功解决了中文乱码问题。
本文介绍在.NET Core环境下读取中文编码文件的解决方案,通过注册CodePagesEncodingProvider并使用GB2312编码读取文件,成功解决了中文乱码问题。
我要干啥
一个txt文本文件,里面存了上千个文件的完整路径。获取到这些文件的文件名,就想着尝试下在dotnet core下编一个小程序来自动完成。
程序的思路还是很简单的:首先将txt文件中的文件名按行读取到string[]类型变量中;而后用LastIndexOf函数查找最后一个"\\"字符,用SubString截取文件名;最后把得到的文件名列表保存到文件中。
using System;
using System.Collections.Generic;
using System.IO;
namespace GetFileNames
{
class Program
{
private static string infile;
private static string outfile;
static void Main(string[] args)
{
if (args.Length >= 2)
{
infile = args[0];
outfile = args[1];
string[] inlines = File.ReadAllLines(infile);
List<string> outlines = new List<string>();
foreach (string line in inlines)
{
int substart = line.LastIndexOf("/") + 1;
int sublength = line.Length - substart;
if (substart <= 0 || sublength <= 0)
outlines.Add("");
else
outlines.Add(line.Substring(substart, sublength));
}
File.WriteAllLines(outfile, outlines);
Console.WriteLine("Mission complete!");
}
}
}
}
代码很简单,跑起来吧。可是,在读取文件的时候却遇到了问题:文件中的中文读进来后全部变成了乱码!
问题出哪儿啦
肯定是编码的问题。于是用记事本打开了txt文件,看到右下角显示的文件编码为ANSI。
![]()
于是尝试改变读入文件的编码方式。也就是在File.ReadAllLines()函数中增加一个文件编码的参数。当然还要添加对引用
using System.Text;
string[] inlines = File.ReadAllLines(infile, Encoding.Default);可是具体要增加那种编码呢?试了几个都不好使。后来使用Encoding.GetEncodings()方法获取了全部支持的编码格式,发现一共才8种:UTF8、UTF7、UTF32、Unicode、BigEndianUnicode、ASCII、Default。而我要读取的ANSI格式不再这个范围之内。
因为对字符编码也不太了解,于是上网搜了一下,发现cnblog上有一篇写的很好的文章:编码方式之ASCII、ANSI、Unicode概述。
2、ANSI
ANSI全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先ANSI不是指的一种特定的编码,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容ASCII
但互相不兼容的字符编码,微软统称为ANSI编码
(GBK是在国家标准GB2312基础上进行了扩容,包含的字符更多)
补充:在windows下输入命令行的黑框下,右键再点击属性可以看到当前的编码方式和代码页
代码页也称为“内码表”,是与特定语言的字符集相对应的一张表。操作系统中不同的语言和区域设置可能使用不同的代码页(代码页一般与其所直接对应的字符集之间并非完全等同,往往因为种种原因
(比如标准跟不上现实实践的需要)而会对字符集有所扩展)

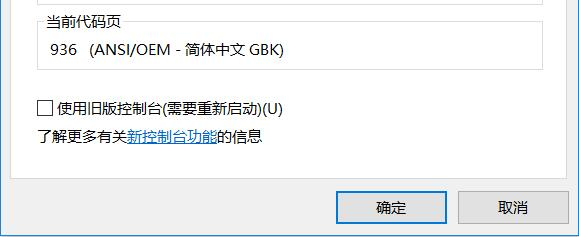
根据这篇文章的描述,我们可以知道,输入的txt文件的编码格式应该是GB2312,于是将读取文件的代码改为
string[] inlines = File.ReadAllLines(infile, Encoding.GetEncoding("GB2312"));于是,我的到了一个大大的错误提示!GB2312是不支持的编码名称。
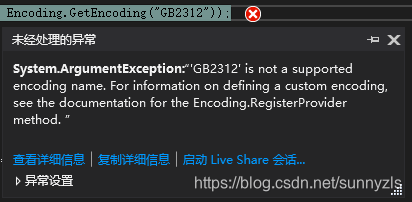
于是查阅了Encoding 类的官方文档。发现了很多编码,Net Framework和.Net Core都没有支持。
代码页 名称 显示名称 .NET Framework 支持 .NET Core 支持 37 IBM037 IBM EBCDIC (美国-加拿大) 437 IBM437 OEM 美国 500 IBM500 IBM EBCDIC (国际) 708 ASMO-708 阿拉伯语(ASMO 708) 720 DOS-720 阿拉伯语(DOS) 737 ibm737 希腊语(DOS) 775 ibm775 波罗的语(DOS) 850 ibm850 西欧(DOS) 852 ibm852 中欧语(DOS) 855 IBM855 OEM 西里尔语 857 ibm857 土耳其语(DOS) 858 IBM00858 OEM 多语言拉丁语 I 860 IBM860 葡萄牙语(DOS) 861 ibm861 冰岛语(DOS) 862 DOS-862 希伯来语(DOS) 863 IBM863 加拿大法语(DOS) 864 IBM864 阿拉伯语(864) 865 IBM865 北欧语(DOS) 866 cp866 西里尔语(DOS) 869 ibm869 现代希腊语(DOS) 870 IBM870 IBM EBCDIC (多语言拉丁语-2) 874 windows-874 泰语(Windows) 875 cp875 IBM EBCDIC (现代希腊语) 932 shift_jis 日语 (Shift-JIS) 936 gb2312 简体中文(GB2312) ✓ 949 ks_c_5601-1987 朝鲜语 950 big5 繁体中文(Big5) 1026 IBM1026 IBM EBCDIC (土耳其拉丁语-5) 1047 IBM01047 IBM 拉丁语-1 1140 IBM01140 IBM EBCDIC (美国-加拿大-欧洲) 1141 IBM01141 IBM EBCDIC (德国-欧洲) 1142 IBM01142 IBM EBCDIC (丹麦-挪威-欧洲) 1143 IBM01143 IBM EBCDIC (芬兰-瑞典-欧洲) 1144 IBM01144 IBM EBCDIC (意大利-欧洲) 1145 IBM01145 IBM EBCDIC (西班牙-欧洲) 1146 IBM01146 IBM EBCDIC (英国-欧洲) 1147 IBM01147 IBM EBCDIC (法国-欧洲) 1148 IBM01148 IBM EBCDIC (国际-欧洲) 1149 IBM01149 IBM EBCDIC (冰岛语-欧洲) 1200 utf-16 Unicode ✓ ✓ 1201 unicodeFFFE Unicode (大字节序) ✓ ✓ 1250 windows-1250 中欧语(Windows) 1251 windows-1251 西里尔语(Windows) 1252 GB2312 西欧语(Windows) ✓ 1253 windows-1253 希腊语(Windows) 1254 windows-1254 土耳其语(Windows) 1255 windows-1255 希伯来语(Windows) 1256 windows-1256 阿拉伯语(Windows) 1257 windows-1257 波罗的语(Windows) 1258 windows-1258 越南语(Windows) 1361 Johab 韩语(Johab) 10000 macintosh 西欧(Mac) 10001 x-mac-日语 日语(Mac) 10002 x-mac-chinesetrad 繁体中文(Mac) 10003 x-mac-韩语 朝鲜语(Mac) ✓ 10004 x-mac-arabic 阿拉伯语(Mac) 10005 x-mac-hebrew 希伯来语(Mac) 10006 x-mac-希腊语 希腊语(Mac) 10007 x-mac-cyrillic 西里尔语(Mac) 10008 x-mac-chinesesimp 简体中文(Mac) ✓ 10010 x-mac 罗马尼亚语(Mac) 10017 x-mac-乌克兰语 乌克兰语(Mac) 10021 x-mac-泰语 泰语(Mac) 10029 x-mac-ce 中欧语(Mac) 10079 x-mac-冰岛语 冰岛语(Mac) 10081 x-mac-turkish 土耳其语(Mac) 10082 x-mac-克罗地亚语 克罗地亚语(Mac) 12000 utf-32 Unicode (UTF-32) ✓ ✓ 12001 utf-32BE Unicode (UTF-16 32 大字节序) ✓ ✓ 20000 x-中文-CNS 繁体中文(CNS) 20001 x-cp20001 TCA 台湾 20002 x-中文-Eten 繁体中文(Eten) 20003 x-cp20003 IBM5550 台湾 20004 x-cp20004 TeleText 台湾 20005 x-cp20005 Wang 台湾 20105 x-IA5 西欧(IA5) 20106 x-IA5-德语 德语(IA5) 20107 x IA5-瑞典语 瑞典语(IA5) 20108 x-IA5-Norwegian 挪威语(IA5) 20127 us-ascii US-ASCII ✓ ✓ 20261 x-cp20261 T.61 20269 x-cp20269 ISO-6937 20273 IBM273 IBM EBCDIC (德国) 20277 IBM277 IBM EBCDIC (丹麦-挪威) 20278 IBM278 IBM EBCDIC (芬兰-瑞典) 20280 IBM280 IBM EBCDIC (意大利) 20284 IBM284 IBM EBCDIC (西班牙) 20285 IBM285 IBM EBCDIC (英国) 20290 IBM290 IBM EBCDIC (日语片假名) 20297 IBM297 IBM EBCDIC (法国) 20420 IBM420 IBM EBCDIC (阿拉伯语) 20423 IBM423 IBM EBCDIC (希腊语) 20424 IBM424 IBM EBCDIC (希伯来语) 20833 x-EBCDIC-KoreanExtended IBM EBCDIC (朝鲜语扩展) 20838 IBM-泰语 IBM EBCDIC (泰语) 20866 koi8-r 西里尔语(KOI8-RU-R) 20871 IBM871 IBM EBCDIC (冰岛语) 20880 IBM880 IBM EBCDIC (西里尔语俄语) 20905 IBM905 IBM EBCDIC (土耳其语) 20924 IBM00924 IBM 拉丁语-1 20932 EUC-JP 日语(JIS 0208-1990 和0212-1990) 20936 x-cp20936 简体中文(GB2312-80) ✓ 20949 x-cp20949 韩语 Wansung ✓ 21025 cp1025 IBM EBCDIC (西里尔语塞尔维亚语-保加利亚语) 21866 koi8-ru-u 西里尔语(KOI8-RU) 28591 iso-8859-1 西欧语(ISO) ✓ ✓ 28592 iso-8859-2 中欧语(ISO) 28593 iso-8859-3 拉丁语3(ISO) 28594 iso-8859-4 波罗的语(ISO) 28595 iso-8859-5 西里尔语(ISO) 28596 iso-8859-6 阿拉伯语(ISO) 28597 iso-8859-7 希腊语(ISO) 28598 iso-8859-8 希伯来语(ISO-Visual) ✓ 28599 iso-8859-9 土耳其语(ISO) 28603 iso-8859-13 爱沙尼亚语(ISO) 28605 iso-8859-15 拉丁语9(ISO) 29001 x-Europa 欧洲 38598 iso-8859-8-i 希伯来语(ISO-逻辑) ✓ 50220 iso-2022-jp 日语(JIS) ✓ 50221 csISO2022JP 日语(JIS-允许1字节假名) ✓ 50222 iso-2022-jp 日语(JIS-允许1字节假名-SO/SI) ✓ 50225 iso-2022-kr 朝鲜语(ISO) ✓ 50227 x-cp50227 简体中文(ISO-2022) ✓ 51932 euc-jp 日语(EUC) ✓ 51936 EUC-CN 简体中文(EUC) ✓ 51949 euc-kr 韩语(EUC) ✓ 52936 hz-gb-2312 简体中文(HZ) ✓ 54936 GB18030 简体中文(GB18030) ✓ 57002 x-iscii-de ISCII 梵文 ✓ 57003 x-iscii-be ISCII 孟加拉语 ✓ 57004 x-iscii-ta ISCII 泰米尔语 ✓ 57005 x-iscii-te ISCII 泰卢固语 ✓ 57006 x-iscii-as ISCII 阿萨姆语 ✓ 57007 x-iscii-or ISCII 奥里雅语 ✓ 57008 x-iscii-ka ISCII 埃纳德文 ✓ 57009 x-iscii-ma ISCII 马拉雅拉姆语 ✓ 57010 x-iscii-gu ISCII 古吉拉特语 ✓ 57011 x-iscii-pa ISCII 旁遮普语 ✓ 65000 utf-7 Unicode (UTF-7) ✓ ✓ 65001 utf-8 Unicode (UTF-8) ✓ ✓
那要怎么办呢!在错误信息中心提到了Encoding.RegisterProvider 方法。其中的一段描述似乎又有了一线希望:
利用 RegisterProvider 方法,你可以注册派生自 EncodingProvider 的类,使字符编码在不支持它们的平台上可用。 注册编码提供程序后,可通过调用任何 Encoding.GetEncoding 重载来检索它支持的编码。 如果有多个编码提供程序,Encoding.GetEncoding 方法将尝试从每个提供程序检索指定的编码,并从最近注册的提供程序开始。
使用 RegisterProvider 方法注册编码提供程序还会在传递
0的参数时,修改encoding.getencoding (int32)和encoding.getencoding (int32,EncoderFallback,DecoderFallback)方法的行为:
如果注册的提供程序是 CodePagesEncodingProvider,则在 Windows 操作系统上运行时,该方法将返回与系统活动代码页匹配的编码。
自定义编码提供程序可以选择在其中一个 GetEncoding 方法重载传递
0的参数时要返回哪种编码。 提供程序还可以选择不通过让 EncodingProvider.GetEncoding 方法返回null来返回编码。
顺着CodePagesEncodingProvider这条线找下去,在微软的官方文档,对CodePagesEncodingProvider.Instance 属性的描述中有这样一段话:
若要检索在 Windows 桌面的 .NET Framework 中存在但在 .NET Core 中不存在的编码,请执行以下操作:
将对代码页程序集的引用添加到你的项目。
获取静态 CodePagesEncodingProvider.Instance 属性中的 EncodingProvider 对象。
将 EncodingProvider 对象传递到 Encoding.RegisterProvider 方法,以使 EncodingProvider 对象提供的编码可供公共语言运行时使用。
调用 Encoding.GetEncoding 重载以检索编码。 Encoding.GetEncoding 方法将调用相应的 EncodingProvider.GetEncoding 方法来确定它是否可以提供请求的编码。
这段话就是解决问题的关键。
解决问题的方法:
- 安装System.Text.Encoding.CodePages NuGet包。也就是上面那段话中的第1点。
- 使用Encoding.RegisterProvider方法注册编码。对应上面那段话中的第2、3点。
- 使用Encoding.GetEncoding("GB2312")获取文本文件对应的编码。
完整代码如下:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
namespace GetFileNames
{
class Program
{
private static string infile;
private static string outfile;
static void Main(string[] args)
{
// 注册编码
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
if (args.Length >= 2)
{
infile = args[0];
outfile = args[1];
// 获取并使用GB2312编码读取文本文件
string[] inlines = File.ReadAllLines(infile, Encoding.GetEncoding("GB2312"));
List<string> outlines = new List<string>();
foreach (string line in inlines)
{
int substart = line.LastIndexOf("/") + 1;
int sublength = line.Length - substart;
if (substart <= 0 || sublength <= 0)
outlines.Add("");
else
outlines.Add(line.Substring(substart, sublength));
}
File.WriteAllLines(outfile, outlines);
Console.WriteLine("Mission complete!");
}
}
}
}
不知大家有没有注意到,我再保存文件的时候没有指定编码方式,最后的得到的文件是UTF-8编码格式的。
![]()

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









