






此下级文件包括tank数据集与tank-pose数据集,前者为BOX目标识别,后者为pose姿态估计识别。具体数据内容会通过网盘或者直接放在实验室的电脑里的方式供大家使用,大家想用但是找不到的话可以直接给我发消息哈。该数据集在没有老师和我的允许下,不允许与外组共享,仅供咱们组自己使用!!!
也希望大家能够共同扩充这个数据集,制作一个独属于咱们实验室的战场场景数据集,拥有属于自己的数据集对以后比赛、发文章、做项目什么的都会有非常大的帮助。
(1)tank数据集文件内包含自制坦克数据集内包括真实坦克顶视图片和模拟坦克顶视图片共5315张(其实大都是游戏图片,只有文件的最后有几张真实图片,写论文的时候这样写会高级一点),为提升模型泛化能力防止过拟合,收集含山地、森林、城市、沙漠、高原、雪地、沿海地区等目标场景的图片。数据集内训练集、验证集、测试集按7:2:1划分,训练集为3721张,验证集为1063张,测试集为531张。
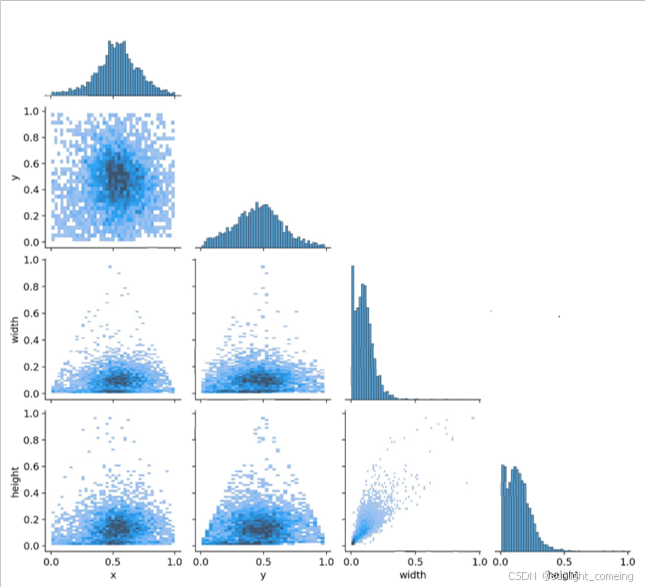
图1 box数据集中心点横纵坐标以及框的高宽关系图
(2)tank-pose数据集选取合适的顶视视角下装甲车辆姿态估计图片1388张,数据集里训练集、验证集、测试集按照7:2:1进行划分,划分后的训练集个数为971张,验证集为278张,测试集为139张。数据集内包括山地、森林、城市、沙漠、高原、雪地、沿海地区等场景。
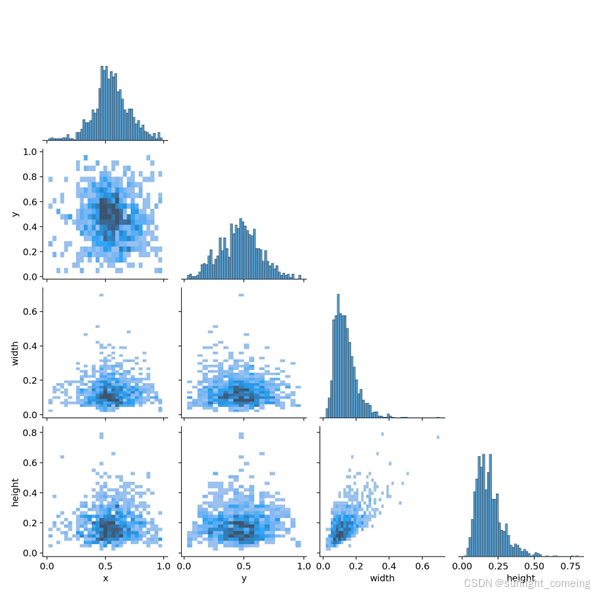
图2 pose 数据集中心点横纵坐标以及框的高宽关系图
两个数据集的制作分别是使用了libelimg与coco-annotator。Libelimg没什么好说的,就是大家最常用了数据集标注软件,pip就能直接下载。coco-annotator是国外网站,需要翻墙并且使用docker,建立docker过程比较麻烦,我全程使用gpt帮我建立,出错就输入给gpt,当时也没想到gpt能完全搞定,整个过程就没有记录,导致现在已经登录不上之前的coco-annotator网站,建议大家在自己整的时候做好全程记录。
![]()
图3数据集txt文件举例
如图3所示是pose数据集txt文件内容,0是类别 类比后四个数为矩形框的坐标信息,从这以后 以3个数为一组是关键点信息,每组内的三个数分别是x坐标、y坐标、关键点是否被遮挡。 数字2表示没有被遮挡
如果你使用了coco-annotator,我在pose数据集的文件里附上了json转txt的py文件,以及数据集化分py文件,大家可以直接带入并使用。
除了coco-annotator以外我还想过其他的标注方法,roboflow,CVAT、libelme,这些都不如coco-annotator,而且,YOLO的姿态估计标注需要标注box、关键点、以及关键点是否被遮挡这三个信息。只有coco-annotator在标注界面会显示“关键点是否被遮挡”按钮,并且显示关键点顺序和连线,非常方便后面数据集的检查和更正。
如果大家标注的数据集关键点位置都没有被遮挡,即不需要考虑是否被遮挡这件事情,就可以使用libelme了。使用libelme的过程如下:
- 先使用box矩形框框选
- 使用关键点指针进行关键点标注
- 将导出的json文件转换成txt(记得归一化)
- 在txt文件的关键点xy坐标后输入 “空格 2 空格” (就是相当于自己手动输入没有被遮挡的信息。)


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









