







 本文详细介绍了Java中的进程间通信、线程间通信方式,包括消息队列、信号量、共享内存以及volatile、wait/notify机制。此外,深入探讨了synchronized与ReentrantLock的区别,并对比分析了数据库索引的实现,特别是MyISAM和InnoDB的差异。最后,梳理了Java基本数据类型、装箱拆箱、对象创建过程、序列化与反序列化以及线程创建的三种方式及其差异。
本文详细介绍了Java中的进程间通信、线程间通信方式,包括消息队列、信号量、共享内存以及volatile、wait/notify机制。此外,深入探讨了synchronized与ReentrantLock的区别,并对比分析了数据库索引的实现,特别是MyISAM和InnoDB的差异。最后,梳理了Java基本数据类型、装箱拆箱、对象创建过程、序列化与反序列化以及线程创建的三种方式及其差异。
2022-Java常问面试题总结2
1. 进程间的通信方式
进程间的通信方式三种分别是消息队列通信、信号量通信和共享内存通信。
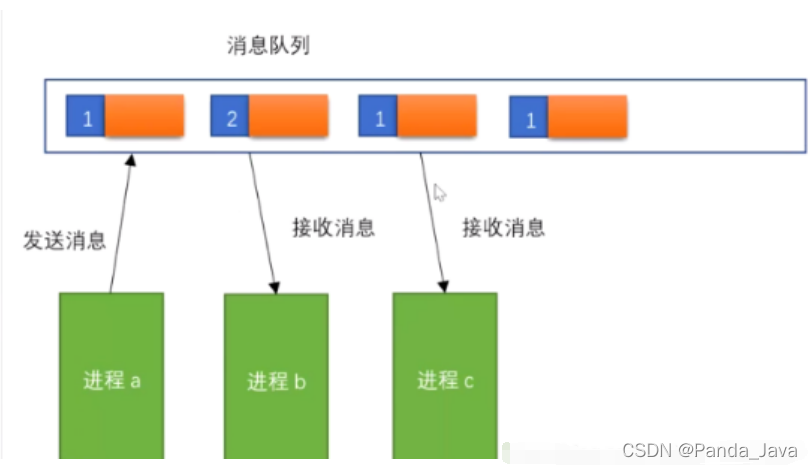
1、消息队列是在两个不相关的进程之间传递数据的一种简单高效的方式,独立于发送进程和接受进程而存在。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
2、信号量是一种提供不同进程或者一个给定的不同线程之间同步的手段。它常作为一种锁机制,防止进程访问共享资源时,其他的进程也访问该资源。主要作为进程之间以及同一进程内的不同线程之间的同步手段。
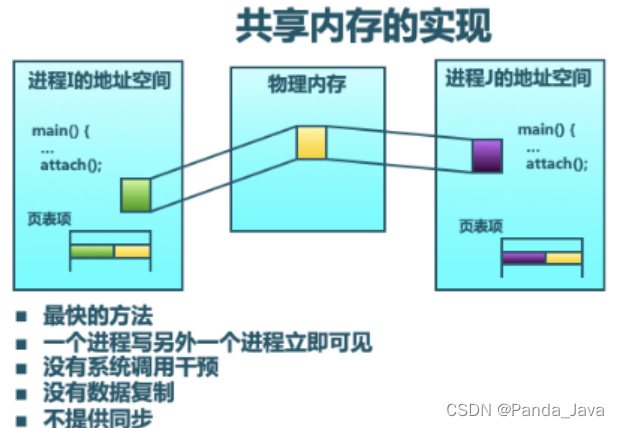
3、共享内存诗指在多个处理器的计算机中,可以被不同的中央处理器访问的大容量的内存。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低的问题专门设计的。它往往与其他通信机制配合使用,来实现进程间的同步通信。
2. 线程程间的通信方式
首先,要短信线程间通信的模型有两种:共享内存和消息传递,以下方式都是基本这两种模型来实现的。我们来基本一道面试常见的题目来分析:
题目:有两个线程A、B,A线程向一个集合里面依次添加元素"abc"字符串,一共添加十次,当添加到第五次的时候,
希望B线程能够收到A线程的通知,然后B线程执行相关的业务操作。
方式一:使用 volatile 关键字
基于 volatile 关键字来实现线程间相互通信是使用共享内存的思想,大致意思就是多个线程同时监听一个变量,当这个变量发生变化的时候 ,线程能够感知并执行相应的业务。这也是最简单的一种实现方式
public class TestSync {
// 定义一个共享变量来实现通信,它需要是volatile修饰,否则线程不能及时感知
static volatile boolean notice = false;
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 实现线程A
Thread threadA = new Thread(() -> {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A向list中添加一个元素,此时list中的元素个数为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
notice = true;
}
});
// 实现线程B
Thread threadB = new Thread(() -> {
while (true) {
if (notice) {
System.out.println("线程B收到通知,开始执行自己的业务...");
break;
}
}
});
// 需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再启动线程A
threadA.start();
}
}
方式二:使用Object类的wait() 和 notify() 方法
众所周知,Object类提供了线程间通信的方法:wait()、notify()、notifyaAl(),它们是多线程通信的基础,而这种实现方式的思想自然是线程间通信。
注意: wait和 notify必须配合synchronized使用,wait方法释放锁,notify方法不释放锁
public class TestSync {
public static void main(String[] args) {
// 定义一个锁对象
Object lock = new Object();
List<String> list = new ArrayList<>();
// 实现线程A
Thread threadA = new Thread(() -> {
synchronized (lock) {
for (int i = 1; i <= 10; i++) {
list.add("abc");
System.out.println("线程A向list中添加一个元素,此时list中的元素个数为:" + list.size());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (list.size() == 5)
lock.notify();// 唤醒B线程
}
}
});
// 实现线程B
Thread threadB = new Thread(() -> {
while (true) {
synchronized (lock) {
if (list.size() != 5) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程B收到通知,开始执行自己的业务...");
}
}
});
// 需要先启动线程B
threadB.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再启动线程A
threadA.start();
}
}
线程A发出notify()唤醒通知之后,依然是走完了自己线程的业务之后,线程B才开始执行,这也正好说明了,notify()方法不释放锁,而wait()方法释放锁。
3. synchronized和ReentrantLock的区别
ReentrantLock 与 synchronized答案1
- ReentrantLock 通过方法 lock()与 unlock()来进行加锁与解锁操作,与 synchronized 会
被 JVM 自动解锁机制不同,ReentrantLock 加锁后需要手动进行解锁。为了避免程序出
现异常而无法正常解锁的情况,使用 ReentrantLock 必须在 finally 控制块中进行解锁操
作。 - ReentrantLock 相比 synchronized 的优势是可中断、公平锁、多个锁。这种情况下需要
使用 ReentrantLock
答案2
① 两者都是可重入锁
两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
② synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
③ ReentrantLock 比 synchronized 增加了一些高级功能
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)
ReentrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。 ReentrantLock默认情况是非公平的,可以通过 ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。
synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify()/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知” ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
4. 数据库索引的实现方式
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
1.
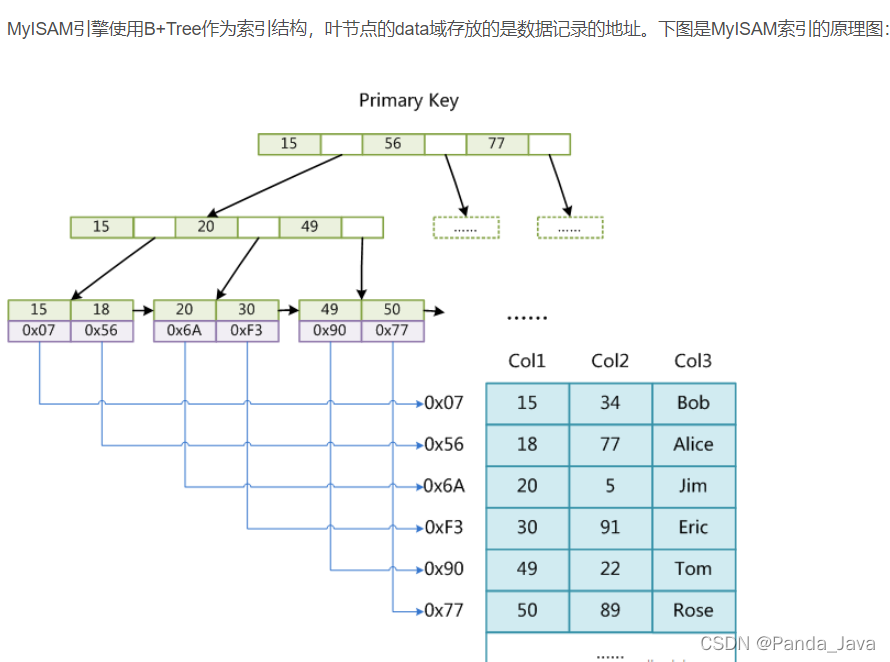
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
2. 虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
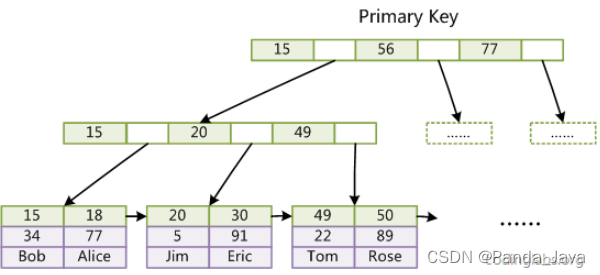
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
链接: 数据库索引的实现方式.
5 Java基础-八大基本数据类型
自从Java发布以来,基本数据类型就是Java语言的一部分,分别是byte, short, int, long, char, float, double, boolean.
其中:
整型:byte, short, int, long
字符型:char
浮点型:float, double
布尔型:boolean
6 装箱与拆箱
装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
7 new 一个对象在堆中的历程(公众号文章)
链接: new 一个对象在堆中的历程.
8. 序列化和反序列化是什么?
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程;
链接: 序列化和反序列化的底层实现原理是什么.
9. 线程、进程、协程相同点和不同点
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。协程与线程主要区别是它将不再被内核调度,而是交给了程序自己而线程是将自己交给内核调度,所以也不难理解golang中调度器的存在。
链接: 线程、进程、协程相同点和不同点.
10. HTTP1.0和HTTP1.1和HTTP2.0的区别
1 HTTP1.0和HTTP1.1的区别
长连接(Persistent Connection)
HTTP1.1支持长连接和请求的流水线处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启长连接keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。HTTP1.0需要使用keep-alive参数来告知服务器端要建立一个长连接。
2 HTTP1.1和HTTP2.0的区别
多路复用
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
链接: HTTP1.0和HTTP1.1和HTTP2.0的区别.
11. 三种创建线程的区别
11.1 继承Thread类创建线程
通过继承Thread类来创建并启动多线程的一般步骤如下
1】定义Thread类的子类,并重写该类的run()方法,该方法的方法体就是线程需要完成的任务,run()方法也称为线程执行体。
2】创建Thread子类的实例,也就是创建了线程对象
3】启动线程,即调用线程的start()方法
代码实例
public class MyThread extends Thread{//继承Thread类
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
new MyThread().start();//创建并启动线程
}
}
11. 2 实现Runnable接口创建线程
通过实现Runnable接口创建并启动线程一般步骤如下:
1】定义Runnable接口的实现类,一样要重写run()方法,这个run()方法和Thread中的run()方法一样是线程的执行体
2】创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程
对象
3】第三部依然是通过调用线程对象的start()方法来启动线程
代码实例:
public class MyThread2 implements Runnable {//实现Runnable接口
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
//创建并启动线程
MyThread2 myThread=new MyThread2();
Thread thread=new Thread(myThread);
thread().start();
//或者 new Thread(new MyThread2()).start();
}
}
11.3 使用Callable和Future创建线程
1】创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
2】使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
3】使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
4】调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
代码实例:
public class Main {
public static void main(String[] args){
MyThread3 th=new MyThread3();
//使用Lambda表达式创建Callable对象
//使用FutureTask类来包装Callable对象
FutureTask<Integer> future=new FutureTask<Integer>(
(Callable<Integer>)()->{
return 5;
}
);
new Thread(task,"有返回值的线程").start();//实质上还是以Callable对象来创建并启动线程
try{
System.out.println("子线程的返回值:"+future.get());//get()方法会阻塞,直到子线程执行结束才返回
}catch(Exception e){
ex.printStackTrace();
}
}
}
11.4 三种创建线程方法对比
实现Runnable和实现Callable接口的方式基本相同,不过是后者执行call()方法有返回值,后者线程执行体run()方法无
返回值,因此可以把这两种方式归为一种这种方式与继承Thread类的方法之间的差别如下:
1、线程只是实现Runnable或实现Callable接口,还可以继承其他类。
2、这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
3、但是编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
4、继承Thread类的线程类不能再继承其他父类(Java单继承决定)。
注:一般推荐采用实现接口的方式来创建多线程

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









