




团队模型、论文、博文、直播合集,点击此处浏览
一、背景
这里我就直接贴上跟ChatGPT的对话作为背景输入,说真的,它的回答比我写的还要专业,具体见如下截图:
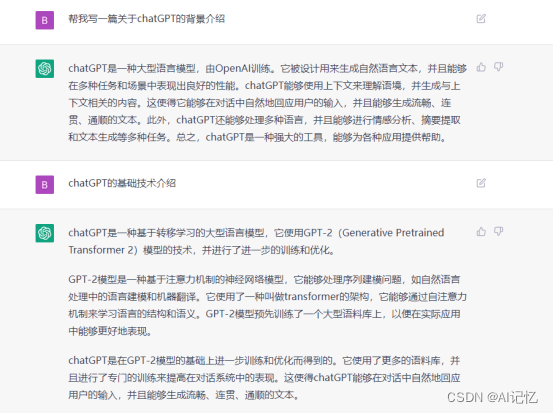
二、原理
从官网介绍可以看到,ChatGPT与InstructGPT是同源的模型。那么接下来我们来看下什么是InstructGPT。从字面上来看,顾名思义,它就是指令式的GPT,“which is trained to follow an instruction in a prompt and provide a detailed response”。接下来我们来看下InstructGPT论文[1]中的主要原理:
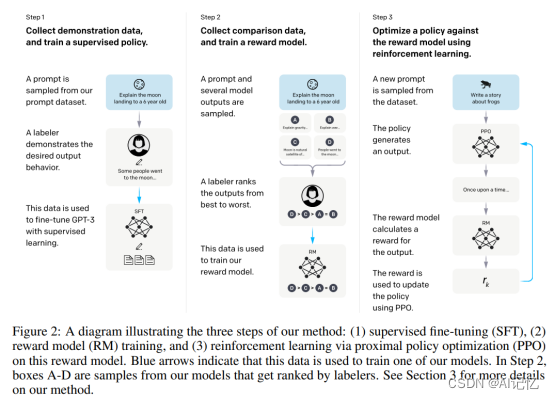
从该图可以看出,InstructGPT是基于GPT-3模型训练出来的,具体步骤如下:
步骤1.)从GPT-3的输入语句数据集中采样部分输入,基于这些输入,采用人工标注完成希望得到输出结果与行为,然后利用这些标注数据进行GPT-3有监督的训练。该模型即作为指令式GPT的冷启动模型。
步骤2.)在采样的输入语句中,进行前向推理获得多个模型输出结果,通过人工标注进行这些输出结果的排序打标。最终这些标注数据用来训练reward反馈模型。
步骤3.)采样新的输入语句,policy策略网络生成输出结果,然后通过reward反馈模型计算反馈,该反馈回过头来作用于policy策略网络。以此反复,这里就是标准的reinforcement learning强化学习的训练框架了。
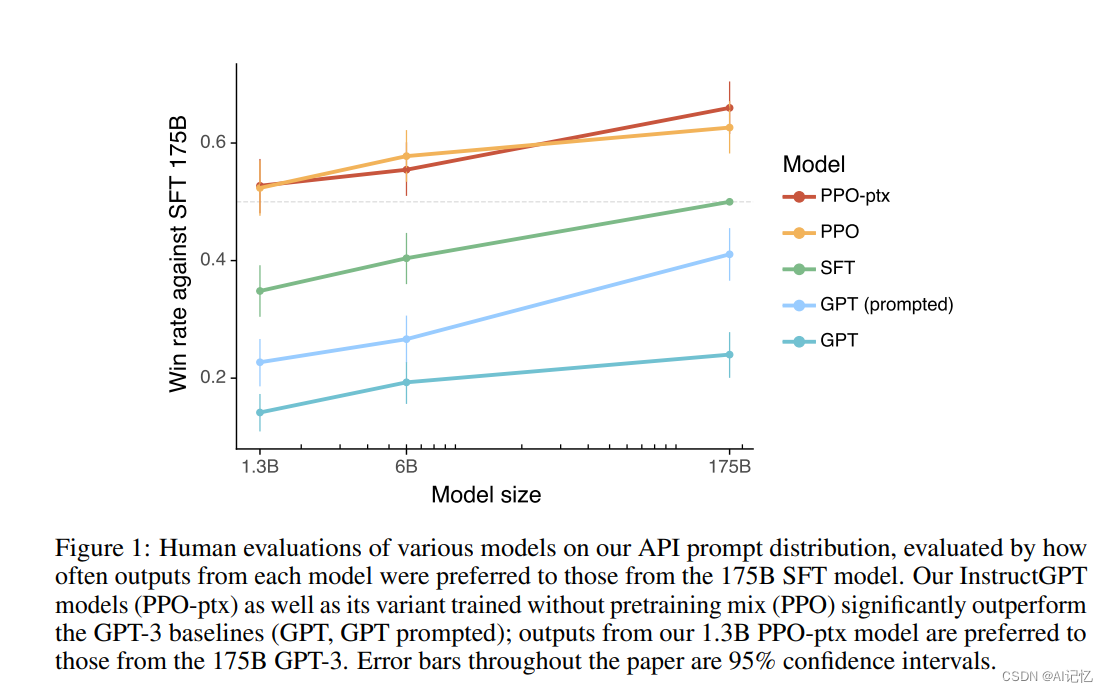
所以总结起来ChatGPT(对话GPT)其实就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通过人工标注方式训练出强化学习的冷启动模型与reward反馈模型,最后通过强化学习的方式学习出对话友好型的ChatGPT模型。如下是论文中相应对话友好型的定量结果(其中PPO-ptx曲线就是InstructGPT模型),可以看到在回答友好型上InstructGPT是远超原始GPT的:
ChatGPT它非常擅长对话、情感分析、文本生成、摘要提取等,有了这些直接打开了更广阔的应用面。可想而知,如若在垂直领域做定向训练,它将会发挥出更极致的性能,即可作咨询用途,同时也可以辅助创作(这将颠覆很多行业的工作方式)等等。
效果是非常惊艳的,使用完之后的体感是这应该能辅助到各行各业中,应用空间无限大,这类技术可能会成为未来AI系统的基石应用之一。
三、其他
文生图体验,文章《人工智能内容生成元年—AI绘画原理解析》中已介绍到Midjourney的用户通过该文生图的能力,在美国科罗拉多州举办的艺术博览会,《太空歌剧院》的画作获得数字艺术类别冠军。相应参与界面如下:
四、文献
[1]InstructGPT:https://arxiv.org/abs/2203.02155



















 1792
1792






 到【灌水乐园】发言
到【灌水乐园】发言









