




代码背景:运用wav2vec2模型微调解决自己的研究问题
报错代码:
Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")问题描述:We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like facebook/wav2vec2-base-960h is not the path to a directory containing a file named preprocessor_config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
问题分析:看报错代码猜测这应该是国内网没办法访问引起的,通过浏览器打开https://huggingface.co发现不通过科学上网网页是打不开的,于是打开科学上网再次运行代码,结果出现了新的报错——HTTPSConnectionPool(host='huggingface.co', port=443.分析这个错误是科学上网配置引起的,不好解决,放弃这个思路。
接下来打开了https://huggingface.co/docs/transformers/installation#offline-mode网址,发现提供了三种离线调运包的方法
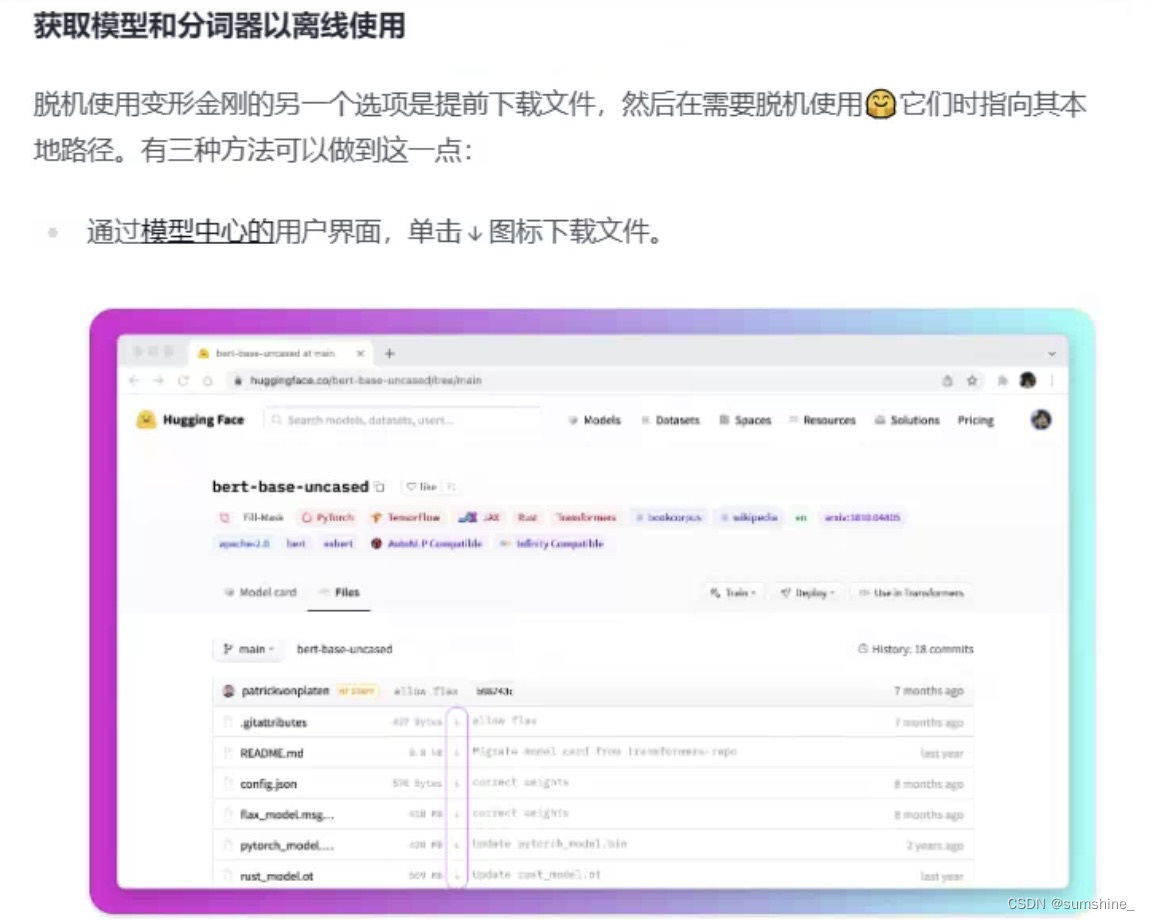

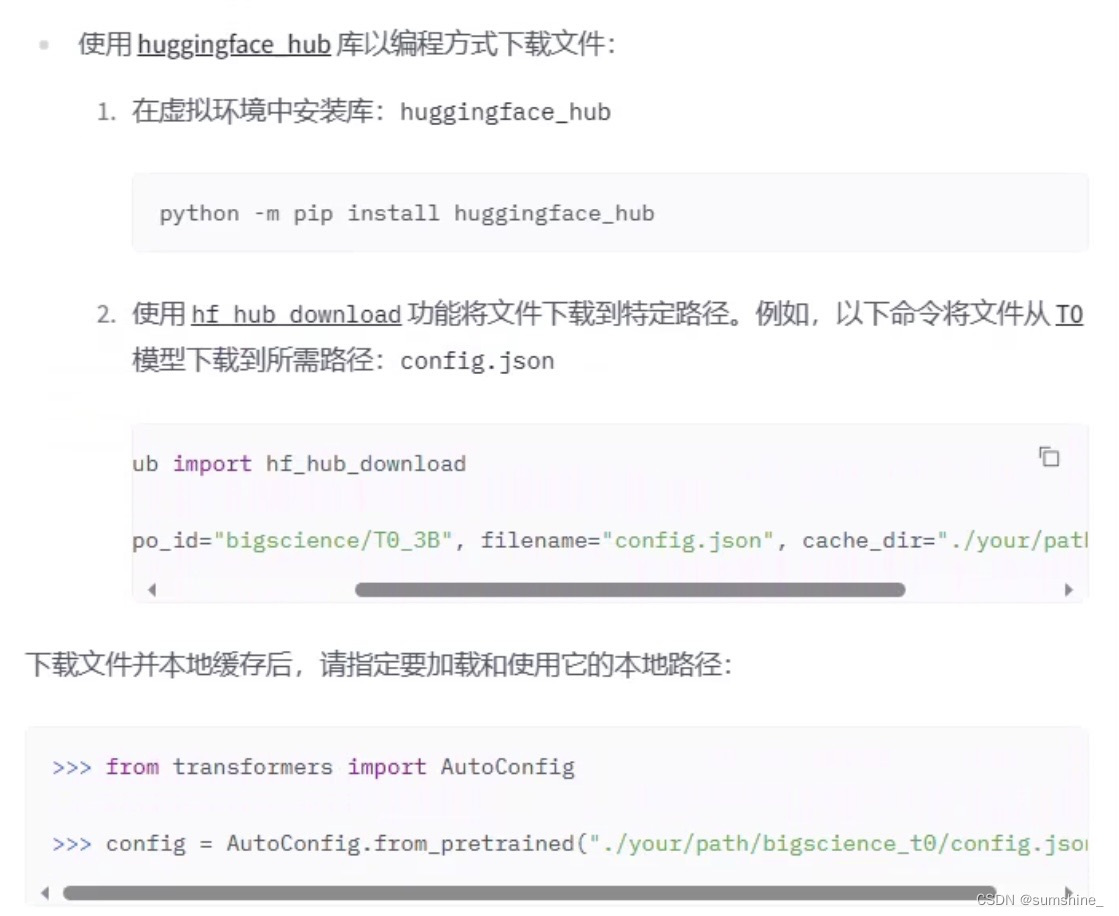
通过提供的离线方法可以解决该问题
解决步骤:
1、科学上网
2、访问网址https://huggingface.co/models ,在搜索框搜索所需模型(我需要facebook/wav2vec2-base-960h)
3、之后点击files and versions下载所需模型(图中红圈部分,弄不清楚要什么就全下载)
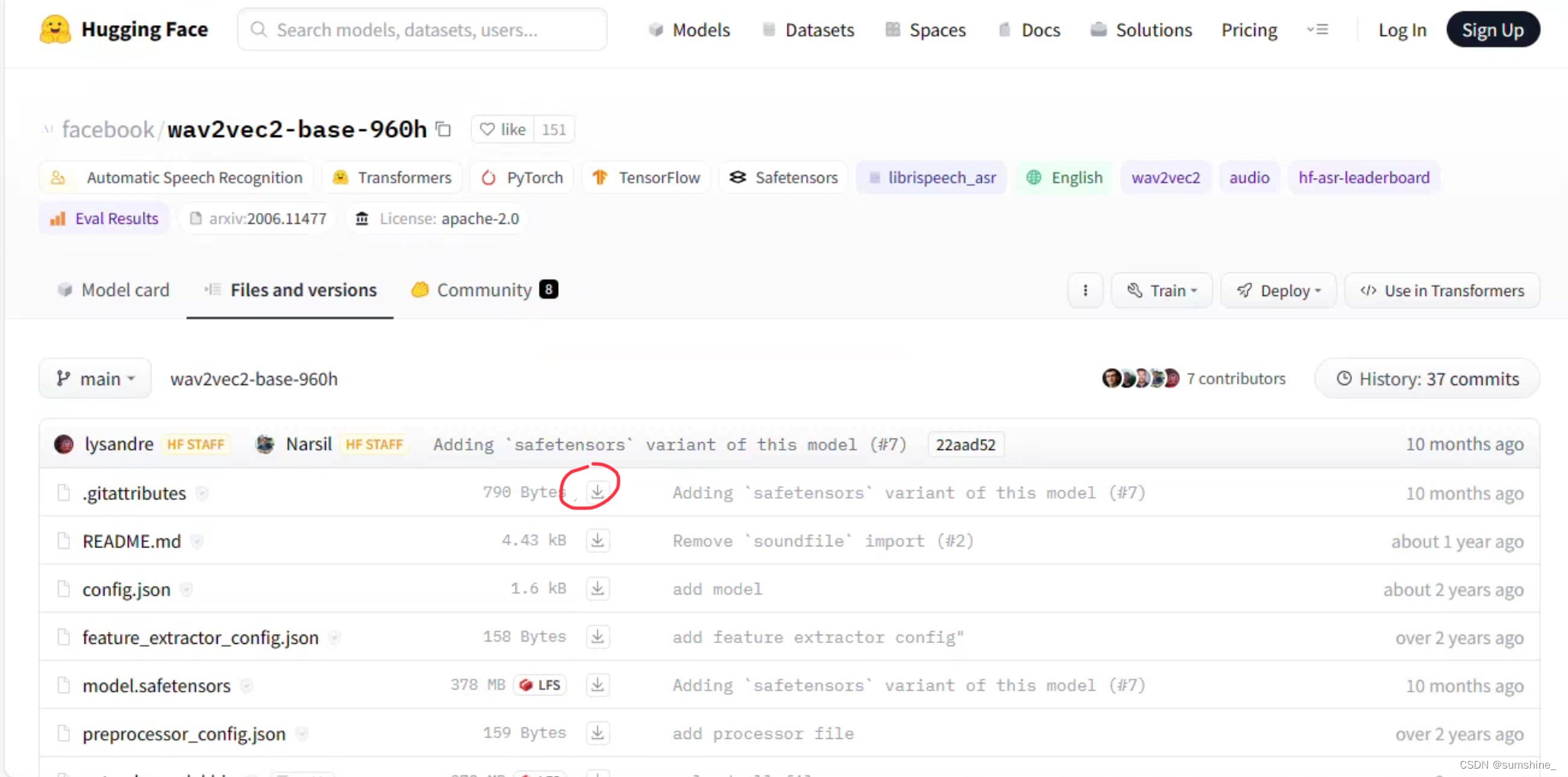
4、更改代码,指明路径(相对路径不熟悉就用绝对路径)
Wav2Vec2Model.from_pretrained("E:/facebook/wav2vec2-base-960h")
















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









