



 本文介绍了作者使用Python进行网络爬虫获取前程无忧网的python岗位数据,并进行数据分析,包括学历与月薪、经验与月薪、学历/经验/月薪三者关系等的关联分析,揭示了学历、经验对薪资的影响,以及不同地区的岗位需求分布。
本文介绍了作者使用Python进行网络爬虫获取前程无忧网的python岗位数据,并进行数据分析,包括学历与月薪、经验与月薪、学历/经验/月薪三者关系等的关联分析,揭示了学历、经验对薪资的影响,以及不同地区的岗位需求分布。
python 岗位数据分析
一.前言
前一段时间学习并写了一些网络爬虫,基于python的,通过网上找一些例子,爬到了很多数据,虽然说不能完全的突破反反爬技术,但是对于大多数反爬不强的网站来说,获取数据还是不难的,这些数据都是网上看的到的,爬虫只是将你所需要的数据集中起来,然而这大量的数据对于我们来说是没什么用的,我们要做的是从大量的数据中获取对我们有用的东西,要实现这一过程,就需要对数据进行数据分析与挖掘.
二.什么是数据分析与挖掘呢?
数据怎样才能对人有用呢?其实数据本身是没有用的,必须要经过一定的处理,比如你手机上的记步功能,通过对你的每一天进行记步,可以反映你的基本运动量(如果你没进行其他锻炼的话),还可以反映出你消耗的能量(卡路里,我手机上是这样),看你这一天的运动量达标情况,等等.这一过程就进行了初步的数据分析与挖掘,哪是数据?步数,哪是分析?这是一个用来获取结果的过程,手机里的程序自动帮你完成了,还有数据挖掘,通过分析得到的结果来预测其它方面的事情,挖掘出数据表面上展现不出来的东西(这往往是商机).
还有一个例子,沃尔玛超市的啤酒和尿布的故事,相信很多人都会说这两件事有什么联系,表面上是没有联系,然而通过对人们的购买数据分析,发现男人一般买尿布的时候,会同时购买啤酒,这样就发现了相互之间的联系,然后运用到实践中去,把啤酒和尿布摆放在一起就可以卖更多,这就是商机.
事实如此,当我们获取的数据非常大的时候,里面就包含了很多有用的信(information),然而往往这些数据十分杂乱,只有经过清洗和整合,得到信息.下一步我们需要从信息中将规律总结出来,发现他们之间的相互关系,称为知识(knowledge),然后运用知识去发现和预测未来
三.实战
由于我也是刚刚自学了一点数据分析与挖掘可视化,加上手头上有现成的数据,就简单的对python岗位的数据进行了分析,小试牛刀.本次数据分析纯属个人喜好,分析所得的结果和结论仅仅是本项目所得,不做参考!
1.数据获取
目标网站: 爬取的是前程无忧网
编程语言: 采用python语言编写(python35)
编辑器: pycharm
所需的库有: requests, pandas, time, lxml, re, matplotlib, pyecharts库
储存文件:csv文件,utf-8编码
import requests
import pandas as pda
from lxml import etree
def data(url):
urls = []
head = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
r = requests.get(url,headers=head)
r.encoding = r.apparent_encoding
selector = etree.HTML(r.text)
divs = selector.xpath('//*[@id="resultList"]/div')
for div in divs[3:53]:#信息所在的div[3]开始,每一页有50条
url1 = div.xpath('p/span/a/@href')#找到每一条信息的url
urls.append(url1[0])
indexdata(urls)#用来获取这一页中50条信息的详细信息
nexturl = selector.xpath('//*[@id="resultList"]/div[55]/div/div/div/ul/li[8]/a/@href')[0]
if nexturl:
data(nexturl)
#相当于翻页功能,判断下一页是否存在,如果存在就调用自身进行下一页的爬取.
def indexdata(urls):
item = {'职位':'','月薪':'','公司':'','学历':'','经验':'','地址':''}
head = {
'Cookie':'太长,省略',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
try:
for url in urls:
data = requests.get(url,headers=head)
data.encoding = data.apparent_encoding
selector = etree.HTML(data.text)
item['职位'] = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/@title')[0]
item['月薪'] = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()')[0]
item['公司'] = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@title')[0]
m = selector.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()')#地址,经验,学历信息在一个字符串中
item['地址'] = "".join(m[0].split())
item['经验'] = "".join(m[1].split())
item['学历'] = "".join(m[2].split())
data_df = pda.DataFrame(item,index=[0])
data_df.to_csv('储存地址', mode='a')#获取每一个岗位的详细信息,保存为.csv文件
print(url+'___________ok')
except:
print('')
if __name__=='__main__':
#第一页url
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=03%2C04%2C05%2C06&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
data(url)
爬取信息量12000条
代码有不足的点,可以和博主交流,谢谢!
2.数据分析
(1)先做一个大致的分析,学历与月薪的关系
def tempdf(data): #月薪/学历
mpl.rcParams['font.sans-serif'] = ['SimHei']#图片不能显示中文的,加上这句话
listtemp = []
pattern = re.compile(r'\d+\.?\d*',re.S)#因为获取的数据为一个字符串,需要提取其中的数值
mod = re.compile(r'[/](.*)', re.S)#这个是因为有的是月薪,有的是年薪
for item in data['月薪']:
result = re.findall(pattern,item)
#print(result)
if re.findall(mod,item)[0]=='年':#进行判断换算成月薪
try:
mony = ((float(result[0])+float(result[1]))*10**4)/2/12
listtemp.append(mony)
except:
mony = (float(result[0])* 10 ** 4)/12
listtemp.append(mony)
else:
if '万'in item:
try:
mony1 = ((float(result[0])+float(result[1]))*10**4)/2
listtemp.append(mony1)
except:
mony1 = (float(result[0]) * 10 ** 4)
listtemp.append(mony1)
else:
try:
mony2 = ((float(result[0])+float(result[1]))*10**3)/2
listtemp.append(mony2)
except:
mony2 = (float(result[0])* 10 ** 3)
listtemp.append(mony2)
data1 = data.copy()
data1['mean月薪'] = listtemp
mean = data1.groupby('学历')['mean月薪'].mean()#通过对学历进行分组,然后对求平均值
#下面是画条形图
x = mean.index
y = mean.values
plb.title('平均月薪/学历')
plb.xlabel('学历') # x轴标题
plb.ylabel('平均月薪')# y轴标题
rat = plb.bar(x,y,facecolor='lightskyblue',width = 0.35,yerr = 200,xerr = 0.5,edgecolor = 'white')
'''
width表示条形图宽度,edgecolor设定条形图边缘颜色
画图过程中图中的数据超过了图 的上边距,看网上说要设置xerr,yerr,但是具体不知道怎么用,有知道的大神告诉小弟一下,谢谢!
'''
plb.legend((rat,), ("图例",)) # 设置图例
plb.grid(axis='x',linestyle='-.') # 设置网格,形式
plb.grid(axis='y',linestyle='-.')
for rect in rat:
height = rect.get_height()
plb.text(rect.get_x() + rect.get_width() / 2., 1.03 * height, '%s' % float(height),ha='center')
plb.show()
代码有不足的点,可以和博主交流,谢谢!
这是运行结果
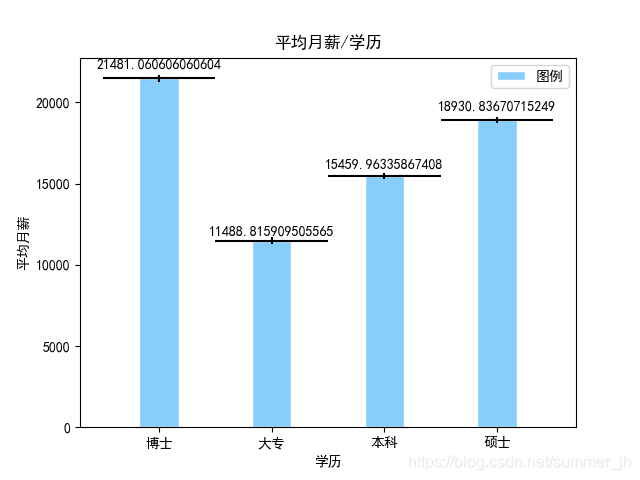
通过上图我们可以得出一些简单的结论:上面的条形图大致可以反映出的信息是学历越高,招聘公司所给的月薪越高,
学历越高,起点越高。(额,感觉不需要分析就可以得出来,尴尬!没事,毕竟第一次做,享受过程就好)
(2)月薪与经验的关系
def Exp_M(data):
mpl.rcParams['font.sans-serif'] = ['SimHei']
pattern = re.compile(r'\d+\.?\d*', re.S)
exps_n = []
for item in data['经验']:
result = re.findall(pattern,item)
if result:#这个地方感觉不知道怎么写,然后就用了这个方法
if int(result[0]) == 1:
exps_n.append('1年')
elif int(result[0]) ==2:
exps_n.append('2年')
elif int(result[0]) == 3:
exps_n.append('3-4年')
elif int(result[0]) == 5:
exps_n.append('5-7年')
elif int(result[0]) == 8:
exps_n.append('8-9年')
else:
exps_n.append('10年')
else:
exps_n.append('无经验')
data1 = data.copy()
data1['re_exp'] = exps_n
ave_m = data1.groupby('re_exp')['mean月薪'].mean()#通过上面得到的经验进行分组,然后再对月薪求平均值
#画图
x = ave_m.values
y = ave_m.index
plb.title('平均月薪/工作经验')
plb.xlabel('平均月薪') # x轴标题
plb.ylabel('工作经验') # y轴标题
b = plb.barh(y,x,facecolor='orange',height=0.3)
for rect in b:
w = rect.get_width()
plb.text(w, rect.get_y() + rect.get_height() / 2, '%d' % int(w), ha='left', va='center')
plb.legend((b,), ("图例",)) # 设置图例
plb.grid(axis='x', linestyle='-.') # 设置网格,形式
plb.grid(axis='y', linestyle='-.')
plb.show()
代码有不足的点,可以和博主交流,谢谢!
这是运行结果
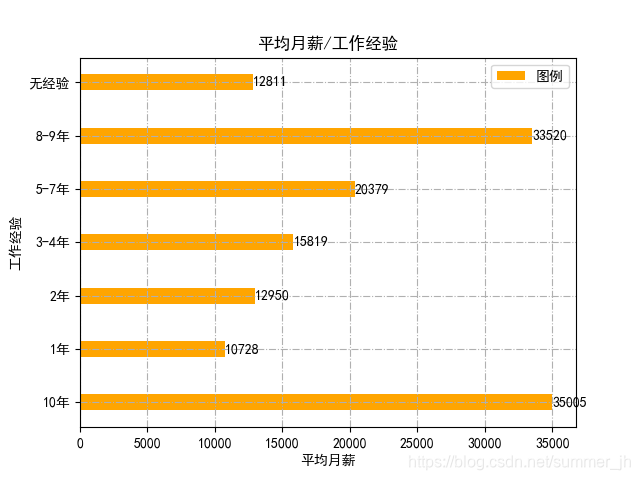
通过图表,我们可以发现python岗位月薪是随工作经验的增长而递增的(感觉是废话!),工作十年的比一年的月薪高3.5倍左右(其实不只,因为招十年工作经验的数据量少,一般线下招)一年工作经验的工资在一万左右还是可观的,然而图中无工作经验的竟然和2年工作经验的差不多,难道是数据出错了?其实不是,而是招无工作经验的基本都是本科学历以上的,所以。。。。,值得我们深思!
(3)月薪/学历/工作经验三个之间的关系
def HigExpMo(data):
mpl.rcParams['font.sans-serif'] = ['SimHei']
atr =[]
m = data.groupby('re_exp').apply(lambda s:s.groupby('学历')['mean月薪'].mean())#这个地方注意一下,先对工作经验分组,把分组结果用apply进行广播,然后再对学历进行广播,然后对月薪求平均值
val = m.values.tolist()#将ndarray转化为list列表
val.insert(4,0)这里是因为学历为博士的,招聘公司没有招工作经验为,补零
val.insert(20,0)
#print(val)
for i in range(0,4):
lis = []
for j in range(0,7):
lis.append(val[4*j+i])
atr.append(lis)
#下面画图,对并列条形图还不熟悉,参考网上的
total_width, n = 0.8, 2
width = total_width / n / 2
x = [0, 1, 2, 3, 4, 5, 6]
plb.bar(x, atr[0], width=width, label='博士', fc='y')
for i in range(len(x)):
x[i] = x[i] + width
plb.bar(x , atr[1], width=width, label='大专', fc='r')
for i in range(len(x)):
x[i] = x[i] + width
plb.bar(x , atr[2], width=width, label='本科', fc='g')
for i in range(len(x)):
x[i] = x[i] + width
plb.bar(x , atr[3], width=width, label='硕士',tick_label = m.index.levels[0], fc='b')
plb.title('平均月薪/经验/学历')
plb.xlabel('经验') # x轴标题
plb.ylabel('平均月薪') # y轴标题
plb.grid(axis='x', linestyle='-.') # 设置网格,形式
plb.grid(axis='y', linestyle='-.')
plb.legend(loc='upper rigth')
plb.show()
代码有不足的点,可以和博主交流,谢谢!
这是运行结果
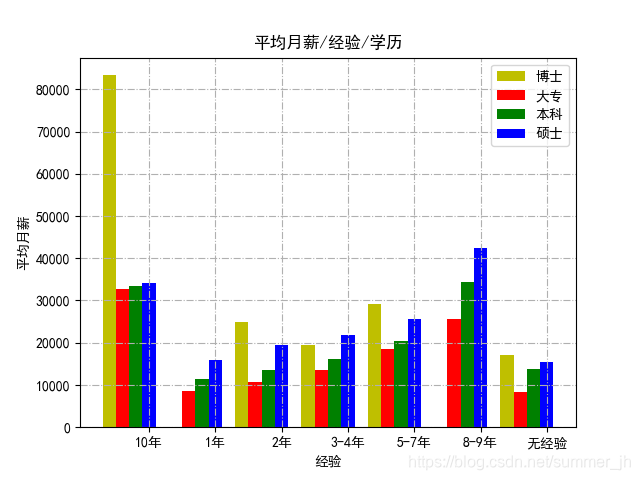
这个图表更加详细,当然得出的结果也更详细,通过上图可以看出,在工作经验相同的情况下,学历占很大的优势,特别是工作经验在十年以下的,博士与大专的月工资相差一万上下,但是到了十年以上,工资基本和学历没多大关系,招聘公司主要注重你的技术,除非你学历非常高。从上图还可以看出,当工作经验达到6年左右,平均月薪 可以达到2万左右,这也是一个分水岭,工作达到6年以上,月薪将大幅增长。
(4)学历需求比,工作经验比
def Demand_Rate(data): #学历需求比例,工作经验需求比例
mpl.rcParams['font.sans-serif'] = ['SimHei']
item = data['学历'].value_counts()
explode = [0.1, 0, 0, 0]
plb.title('学历需求比')
plb.axes(aspect=1)
plb.pie(x=item.values, labels=item.index, explode=explode, autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle=0, pctdistance=0.6)
'''
explode参数表示每个区域的间隔,autopct参数%3.1f%%表示精确到小数点后一位
shadow=True表示显示阴影,labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
startangle,起始角度,0,表示从0开始逆时针转,为第一块
pctdistance,百分比的text离圆心的距离
'''
plb.show()
exps = {'无经验':0}
pattern = re.compile(r'\d+\.?\d*', re.S)
for item in data['经验']:
result = re.findall(pattern,item)
if result:
try:
exp = str(result[0]) + '-' + str(result[1]) + '年经验'
except:
exp = str(result[0]) + '年经验'
if exp not in exps.keys():
exps[exp] = 1
else:
exps[exp] = exps[exp] + 1
else:
exps['无经验'] = exps['无经验'] + 1
explode1 = [0.1, 0, 0, 0.1, 0, 0, 0]
plb.axes(aspect=1)
plb.pie(x=exps.values(), labels=exps.keys(), explode=explode1, autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle=0, pctdistance=0.6)
plb.show()
代码有不足的点,可以和博主交流,谢谢!
这是运行结果
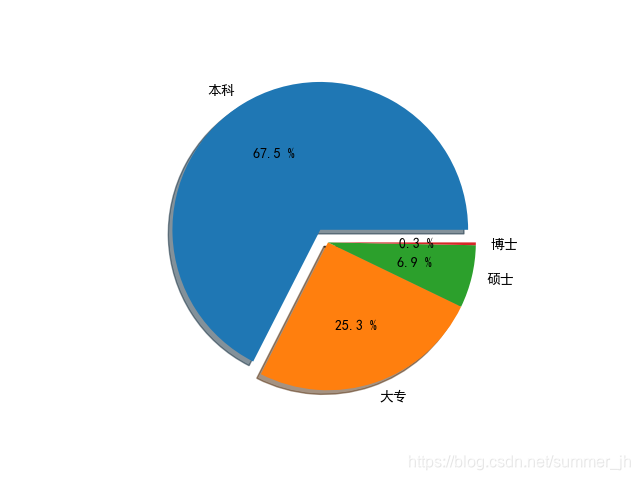
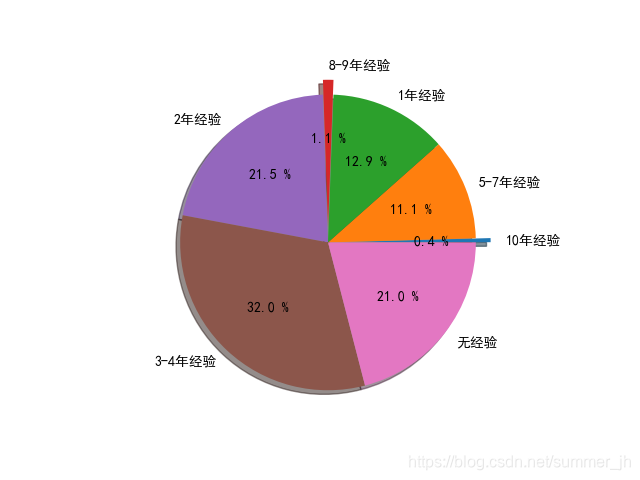
学历需求,本科和大专学历占一大部分,在完成相同工作量的情况下,本科和专科薪资低 ,招聘公司更倾向于本,专科,工作经验需求主要在5-7年以下,第一也与薪资有关,第二,年轻有创造力,能为公司带来更多收益
(5)职位需求量分布图
def City_ra(data):
mpl.rcParams['font.sans-serif'] = ['SimHei']
mod = re.compile(r'(.*)[-]', re.S)
adress = []
for item in data['地址']:#这里是因为有的地址是一个城市名,有的是'城市名-详细地址'形式,这里统统换成城市名,便于画图
if '-' in item:
result = re.findall(mod,item)
adress.append(result[0])
else:
adress.append(item)
data1 = data.copy()
data1['adress'] = adress
adress_num = data1['adress'].value_counts()
geo = Geo("全国各大城市对python职位的需求量分析", title_color="#fff", title_pos="center", width=1200, height=600,background_color='#404a59')
geo.add("空气质量评分", adress_num.index, adress_num.values, type="effectScatter", is_random=True, effect_scale=5, visual_range=[0, 5],
visual_text_color="#fff", is_visualmap=True, is_roam=False)
geo.render(path="地址")
代码有不足的点,可以和博主交流,谢谢!
这是运行结果
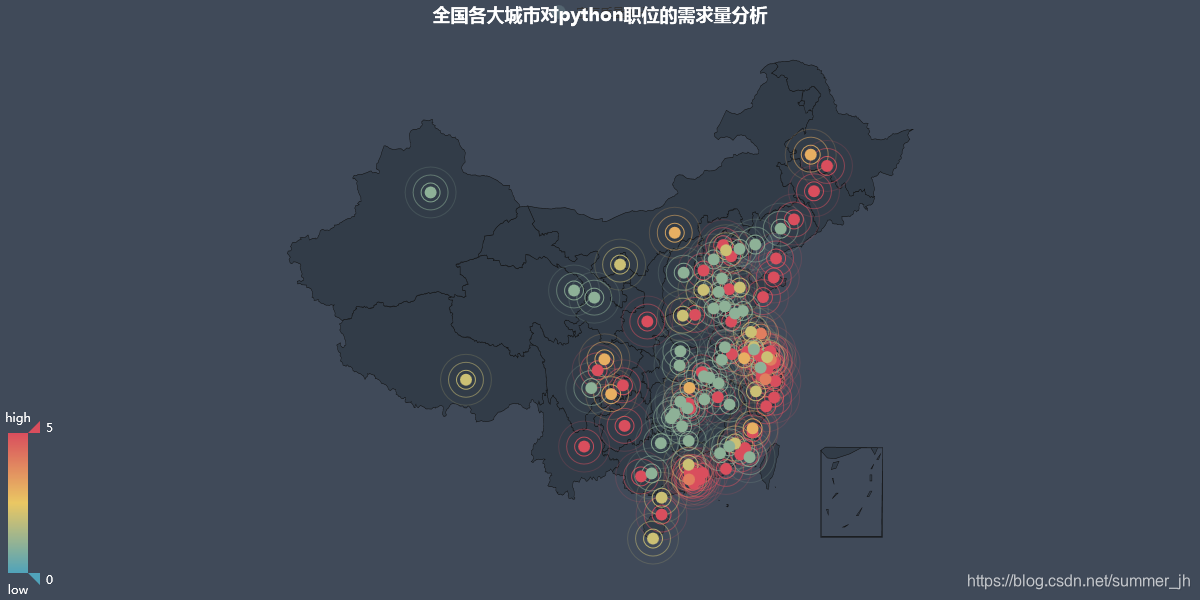
这其实是一个动图,
需求量主要集中在北上广深,杭州,成都等地,其他省会城市也有不少需求量,符合80/20法则
好了 ,写的差不多了,后续将继续学习和完善!

















 2566
2566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









