



1. 列表:
list[1 : -1 : 2] # 列表中第一位到最后一位,步长为2
list[1 : -1 : -2] # 列表中最后一位到第一位,步长为2
list.append(a) 把a添加到最后面
list.insert(3,a) 把a添加到索引为3的位置
list.remove(list[3]) 删除
del list[3] 可以删除list[3],也可以删除list–>del list
list.pop(3) 删除索引为三的值,并将其返回
list.count(a) 计算a元素出现的次数
list.index(a) 返回a元素的索引值,以第一个a为主,根据内容找位置
list.reverse() 将list列表反转
list.sort() 数值从大到小排序;字符串按照ASCII码中的顺序排列
list.sort(reverse = True) 数值从小到大排序;

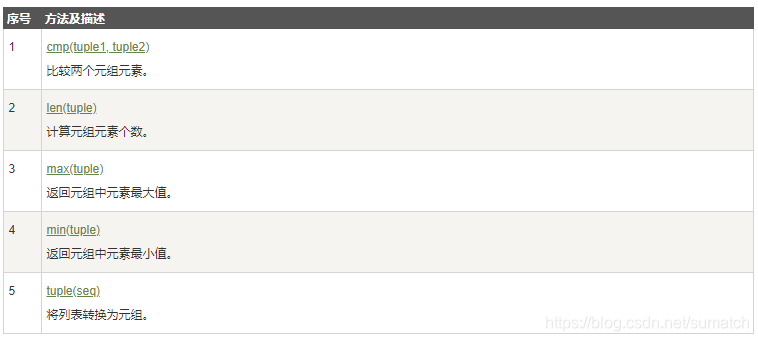
2. 元组:
a = (12,)最后一位也要加逗号
枚举enumerate()
a = [2,3] 此时a是列表
a,b = [2,3] 此时a = 2,b = 3
不可变类型:整型,字符串,元组
可变类型:列表,字典
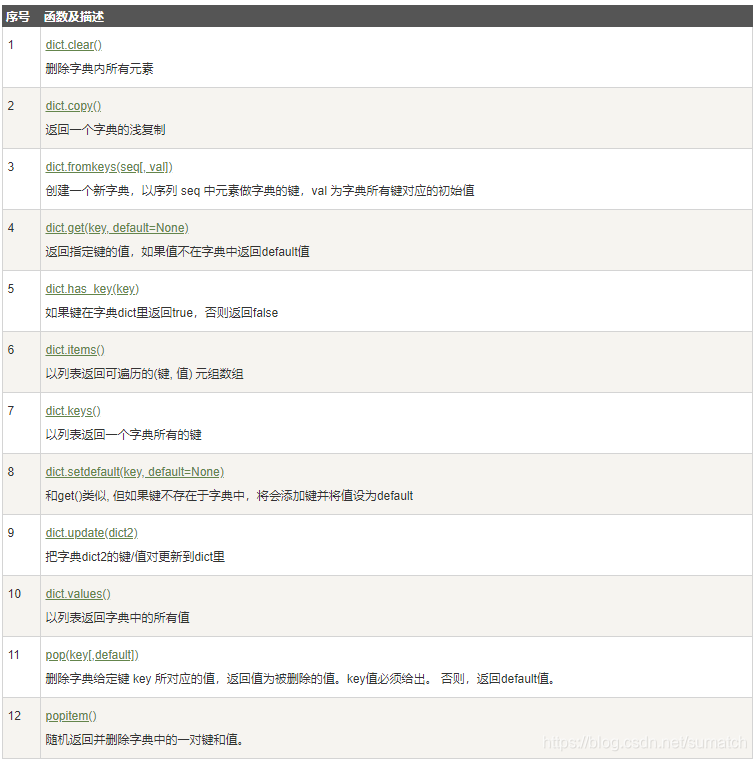
3. 字典:
特点:无序,键唯一
字典的key值是可哈希的,字典的存储结构是哈希表, 这样字典的查找性能就会很好(前提是处理好碰撞), 所以字典的key必须是可哈希的
要求每一个存放到字典中的对象都要实现hash函数,这个函数可以产生一个int值,叫做hash value(哈希值),通过这个int值,就可以快速确定对象在字典中的位置。然而,由于Hash碰撞的存在,可能存在两个对象的Hash值是相同的,所以查找字典的过程中,要比较hash值,还要比较value的值
dict.setdefault(key, default=None)方法
如果键存在,不改动,返回字典中相应的键对应的值;
如果键不存在,在字典中增加新的键值对,并返回相应的值。
4. 字符串:
str =’ ’.join(a,b) 拼接a,b,以’ ’的内容相连。
count(str, beg = 0, end = len(string)) 返回str在string中出现的次数。
replace(old, new) 替换字符串
lstrip() / rstrip() / strip() 去除字符串左/右/左右/或者指定字符
lower() 将所有大写字母转为小写
upper() 将所有小写字母转为大写
swapcase() 将所有大写字母转为小写,所有小写字母转为大写
题目:
- 可以一层一层的进入所有层
- 可以每一层返回上一层
- 可以在任一层退出 主菜单
menu = {
'北京':{
'朝阳':{
'国贸':{
'CICC':{},
'HP':{},
'CCTV':{},
},
'望京':{
'陌陌':{},
'奔驰':{},
'360':{},
},
'三里屯':{
'优衣库':{},
'apple':{},
},
},
'昌平':{
'沙河':{
'老男孩':{},
'阿泰包子':{},
},
'天通苑':{
'链家':{},
'我爱我家':{},
},
'回龙观':{},
},
'海淀':{
'五道口':{
'谷歌':{},
'网易':{},
'Sohu':{},
'Sogo':{},
'快手':{},
},
'中关村':{
'youku':{},
'aiqiyi':{},
'汽车之家':{},
'QQ':{},
},
},
},
'上海':{},
'山东':{},
}
current_layer = menu #初始化,第一次为menu
parent_layers = []
while True:
for key in current_layer:
print(key)
choice = input(">>>:").strip()
if len(choice) == 0:continue
if choice in current_layer:
parent_layers.append(current_layer)
current_layer = current_layer[choice]
elif choice == "back":
if current_layer: # []
current_layer = parent_layers.pop(-1) # .pop()删除并返回最后一个值
else:
print("error ")
5. 集合(set)
是一个无序的不重复元素序列。只能用遍历来查找里面的元素。in/not in判断元素是否在集合中。
可以使用 set() 函数创建集合
集合分类:可变集合、不可变集合
可变集合set():可添加和删除元素,非可哈希的,不能做字典的键,不可做其他集合的元素
不可变集合fronzenset(): 与set()相反
给集合添加元素:
s.add(“abc”) #将 “abc” 添加到集合中
s.update(“abc”) #将 ”a”,”b”,”c” 添加到集合中

集合操作符:
交集s1.intersection(s2) s1 & s2
并集s1.union(s2)) s1 | s2
差集s1.difference(s2)) s1 – s2
对称差集 s1.symmetric_difference(s2) s1 ^ s2
子集s1.issubset(s2)) s1 < s2
set(‘alex’) == set(‘allxe’) #集合自动删除重复的元素
# set(‘alex’) 就是{‘a’, ‘l’, ‘e’, ‘x’}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









