




简介与安装
PyTorch 是一个开源的 Python 机器学习库,基于 Torch 库,底层由C++实现,应用于人工智能领域,如计算机视觉和自然语言处理。
PyTorch 最初由 Meta Platforms 的人工智能研究团队开发,现在属 于Linux 基金会的一部分。
PyTorch 特性
-
动态计算图: PyTorch 的计算图是动态的,在执行时构建计算图,这意味着在每次计算时,图都会根据输入数据的形状自动变化。这为实验和调试提供了极大的灵活性,因为开发者可以逐行执行代码,查看中间结果。
-
张量计算: PyTorch 中的核心数据结构是
张量(Tensor),它是一个多维矩阵,可以在 CPU 或 GPU 上高效地进行计算。 -
自动微分求导: PyTorch 的自动微分系统允许开发者轻松地计算梯度,这对于训练深度学习模型至关重要。它通过反向传播算法自动计算出损失函数对模型参数的梯度。
-
丰富的 API: PyTorch 提供了大量的预定义层、损失函数和优化算法,这些都是构建深度学习模型的常用组件。
TensorFlow 和 PyTorch 的对比
| 对比维度 | TensorFlow | PyTorch |
|---|---|---|
| 开发团队 | Meta (Facebook) | |
| 设计理念 | 静态计算图(早期需先定义图,后执行) | 动态计算图(即时执行,更灵活) |
| 易用性 | 学习曲线陡峭,API 较复杂 | 接口简洁,Python 风格,更易调试 |
| 调试支持 | 需依赖 tf.debugging 工具 |
直接使用 Python 原生调试工具(如 pdb) |
| 部署能力 | 工业级部署成熟(TF Serving、TFLite) | 部署生态逐渐完善(TorchScript、ONNX) |
| 社区生态 | 企业用户多(Google、AWS 支持) | 学术界主导,研究论文实现更快速 |
| 移动端支持 | 强(TFLite 轻量化) | 较弱(依赖第三方工具转换) |
| 分布式训练 | 内置 tf.distribute(支持 TPU) |
依赖 torch.distributed(灵活性高) |
| 可视化工具 | TensorBoard(功能全面) | TensorBoard 或 Weights & Biases |
| 典型应用场景 | 生产环境、大型模型部署 | 研究原型开发、快速实验 |
| 代表项目 | Google BERT、DeepMind AlphaFold | OpenAI GPT、Stable Diffusion |
安装
在 Mac M3(Apple Silicon) 上安装 PyTorch,官方已提供原生 MPS(Metal Performance Shaders) 支持,可加速 GPU 计算。
pip install torch torchvision torchaudio
验证安装和 MPS 支持
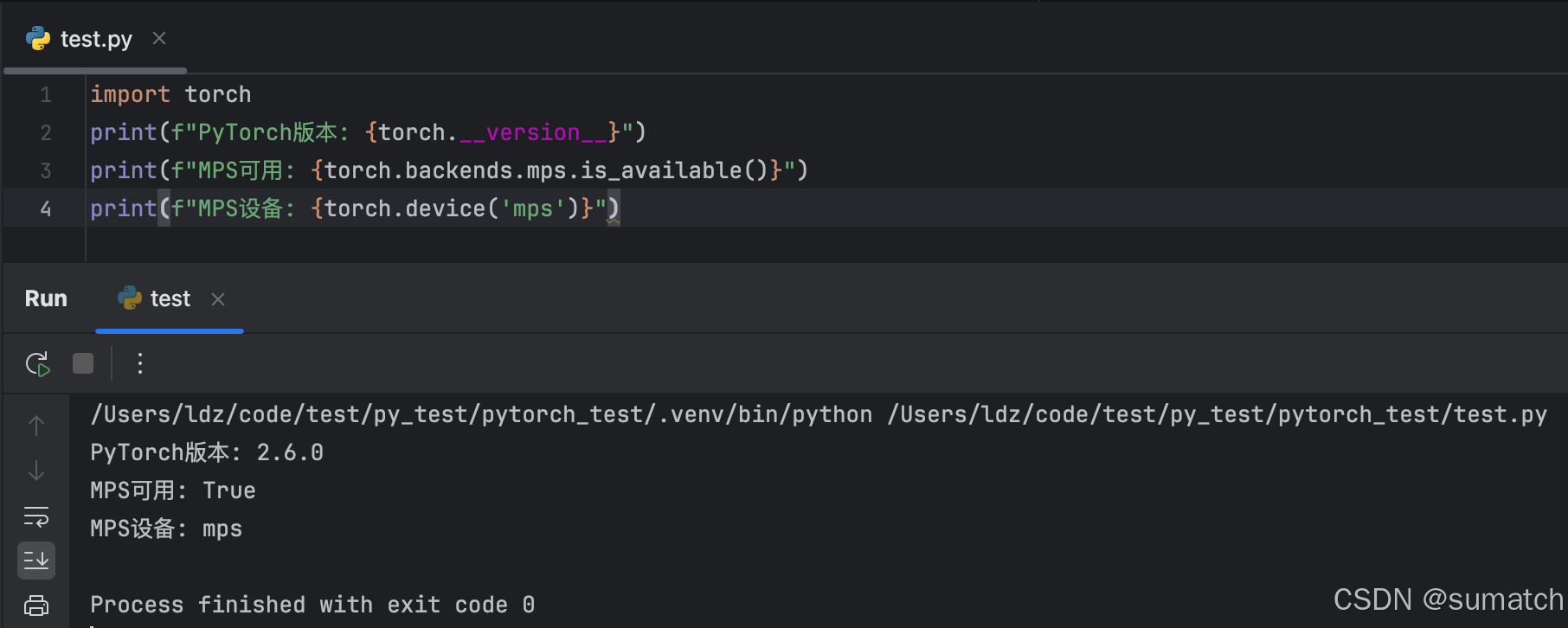
使用 MPS 加速
在代码中显式指定设备为 mps:
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
x = torch.randn(1000, 1000).to(device) # 数据转移到 MPS 设备
基础
训练过程
-
前向传播: 在前向传播阶段,输入数据通过网络层传递,每层应用权重和激活函数,直到产生输出。 -
计算损失: 根据网络的输出和真实标签,计算损失函数的值。 -
反向传播: 反向传播利用自动求导技术计算损失函数关于每个参数的梯度。 -
参数更新: 使用优化器根据梯度更新网络的权重和偏置。 -
迭代: 重复上述过程,直到模型在训练数据上的性能达到满意的水平。
数据类型
在 PyTorch 中,基础数据类型(dtype) 决定了张量(Tensor)中元素的存储方式和计算行为。以下是 PyTorch 支持的主要数据类型及其分类:
-
浮点类型(Float
数据类型 说明 适用场景 torch.float32(或torch.float)32 位单精度浮点数 通用计算(CPU/GPU) torch.float64(或torch.double)64 位双精度浮点数 高精度计算(科学计算) torch.float16(或torch.half)16 位半精度浮点数 GPU 加速(节省显存) torch.bfloat1616 位脑浮点数(保留指数位) TPU/部分 GPU 训练(如 A100) -
整数类型(Integer)
数据类型 说明 范围 torch.int88 位有符号整数 [-128, 127] torch.uint88 位无符号整数 [0, 255] torch.int16(或torch.short)16 位有符号整数 [-32768, 32767] torch.int32(或torch.int)32 位有符号整数 [-2^31, 2^31-1] torch.int64(或torch.long)64 位有符号整数 [-2^63, 2^63-1] -
布尔类型(Boolean)
数据类型 说明 torch.bool布尔值(True/False) -
复数类型(Complex)
数据类型 说明 torch.complex6464 位复数(32 位实部+虚部) torch.complex128128 位复数(64 位实部+虚部)
常用操作示例
-
指定数据类型创建张量
import torch # 创建指定类型的张量 x_float32 = torch.tensor([1.0, 2.0], dtype=torch.float32) x_int64 = torch.tensor([1, 2], dtype=torch.int64) x_bool = torch.tensor([True, False], dtype=torch.bool) -
转换数据类型
x = torch.tensor([1, 2], dtype=torch.int32) x_float = x.float() # 转换为 float32 x_double = x.double() # 转换为 float64 -
检查数据类型
print(x.dtype) # 输出: torch.int32
张量(Tensor)
张量(Tensor)是 PyTorch 中的核心数据结构,用于存储和操作多维数组。
张量可以视为一个多维数组,支持加速计算的操作。
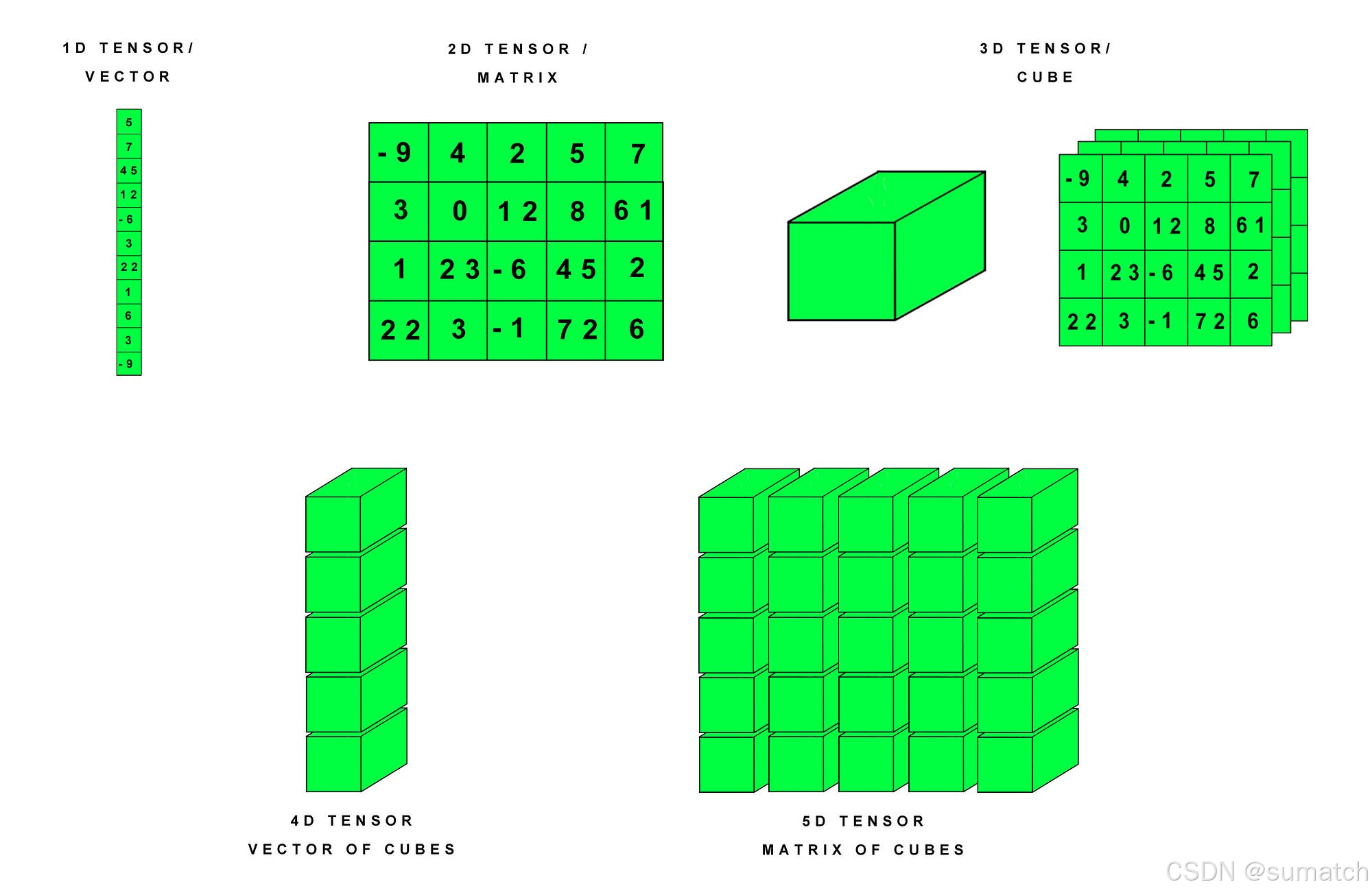
在 PyTorch 中,张量的概念类似于 NumPy 中的数组,但是 PyTorch 的张量可以运行在不同的设备上,比如 CPU 和 GPU,这使得它们非常适合于进行大规模并行计算。
-
维度(Dimensionality):张量的维度指的是数据的多维数组结构。例如,一个标量(0维张量)是一个单独的数字,一个向量(1维张量)是一个一维数组,一个矩阵(2维张量)是一个二维数组,以此类推。 -
形状(Shape):张量的形状是指每个维度上的大小。例如,一个形状为 (3, 4) 的张量意味着它有3行4列。 -
数据类型(Dtype):张量中的数据类型定义了存储每个元素所需的内存大小和解释方式。PyTorch支持多种数据类型,包括整数型(如torch.int8、torch.int32)、浮点型(如torch.float32、torch.float64)和布尔型(torch.bool)。
创建张量
从数据直接创建:
| 具体方法 | 语法示例 | 适用场景 |
|---|---|---|
| 从 Python 列表/NumPy 数组转换 | torch.tensor([[1, 2], [3, 4]]) |
需要精确控制初始数据时 |
| 从 NumPy 数组转换(共享内存) | torch.from_numpy(np_array) |
与 NumPy 交互时 |
初始化创建:
| 具体方法 | 语法示例 | 适用场景 |
|---|---|---|
| 全零张量 | torch.zeros(2, 3) |
初始化权重/占位符 |
| 全一张量 | torch.ones(2, 3) |
初始化固定值张量 |
| 单位矩阵 | torch.eye(3) |
线性代数运算 |
| 等差数列张量 | torch.arange(0, 10, 2) |
生成连续数值 |
| 均匀分布随机张量 | torch.rand(2, 3) |
初始化权重(范围 [0, 1)) |
| 正态分布随机张量 | torch.randn(2, 3) |
初始化权重(均值 0,方差 1) |
| 自定义范围随机整数 | torch.randint(0, 10, (2, 3)) |
生成离散随机值 |
特殊初始化:
| 具体方法 | 语法示例 | 适用场景 |
|---|---|---|
| 空张量(未初始化,值不确定) | torch.empty(2, 3) |
高性能场景(需立即覆盖数据时) |
| 与现有张量同形状 | torch.zeros_like(input_tensor) |
快速创建形状匹配的张量 |
| 复制现有张量(可改设备/数据类型) | torch.clone(input_tensor) |
深拷贝张量 |
高级创建:
| 具体方法 | 语法示例 | 适用场景 |
|---|---|---|
| 对角线张量 | torch.diag(torch.tensor([1, 2, 3])) |
构建对角矩阵 |
| 稀疏张量 | torch.sparse_coo_tensor(indices, values, size) |
处理稀疏数据 |
| 自定义数值填充 | torch.full((2, 3), fill_value=5) |
需要特定填充值 |
设备控制:
| 具体方法 | 语法示例 | 适用场景 |
|---|---|---|
| 直接在 GPU 上创建 | torch.tensor([1, 2], device='cuda') |
GPU 加速计算 |
| 从 GPU 复制到 CPU | cpu_tensor = gpu_tensor.cpu() |
设备间数据传输 |
示例:
import torch
# 创建一个 2x3 的全 0 张量
a = torch.zeros(2, 3)
print(a)
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
# 创建一个 2x3 的全 1 张量
b = torch.ones(2, 3)
print(b)
# tensor([[1., 1., 1.],
# [1., 1., 1.]])
# 创建一个 2x3 的随机数张量
c = torch.randn(2, 3)
print(c)
# tensor([[-0.9105, 0.2726, -1.2604],
# [ 1.4011, -0.5314, -0.7574]])
# 从 NumPy 数组创建张量
import numpy as np
numpy_array = np.array([[1, 2], [3, 4]])
tensor_from_numpy = torch.from_numpy(numpy_array)
print(tensor_from_numpy)
# tensor([[1, 2],
# [3, 4]])
# 在指定设备(CPU/GPU)上创建张量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
d = torch.randn(2, 3, device=device)
print(d)
# tensor([[ 1.7682, -1.7740, -1.9805],
# [-1.1396, -0.6919, 0.3156]])
张量的属性

张量操作:
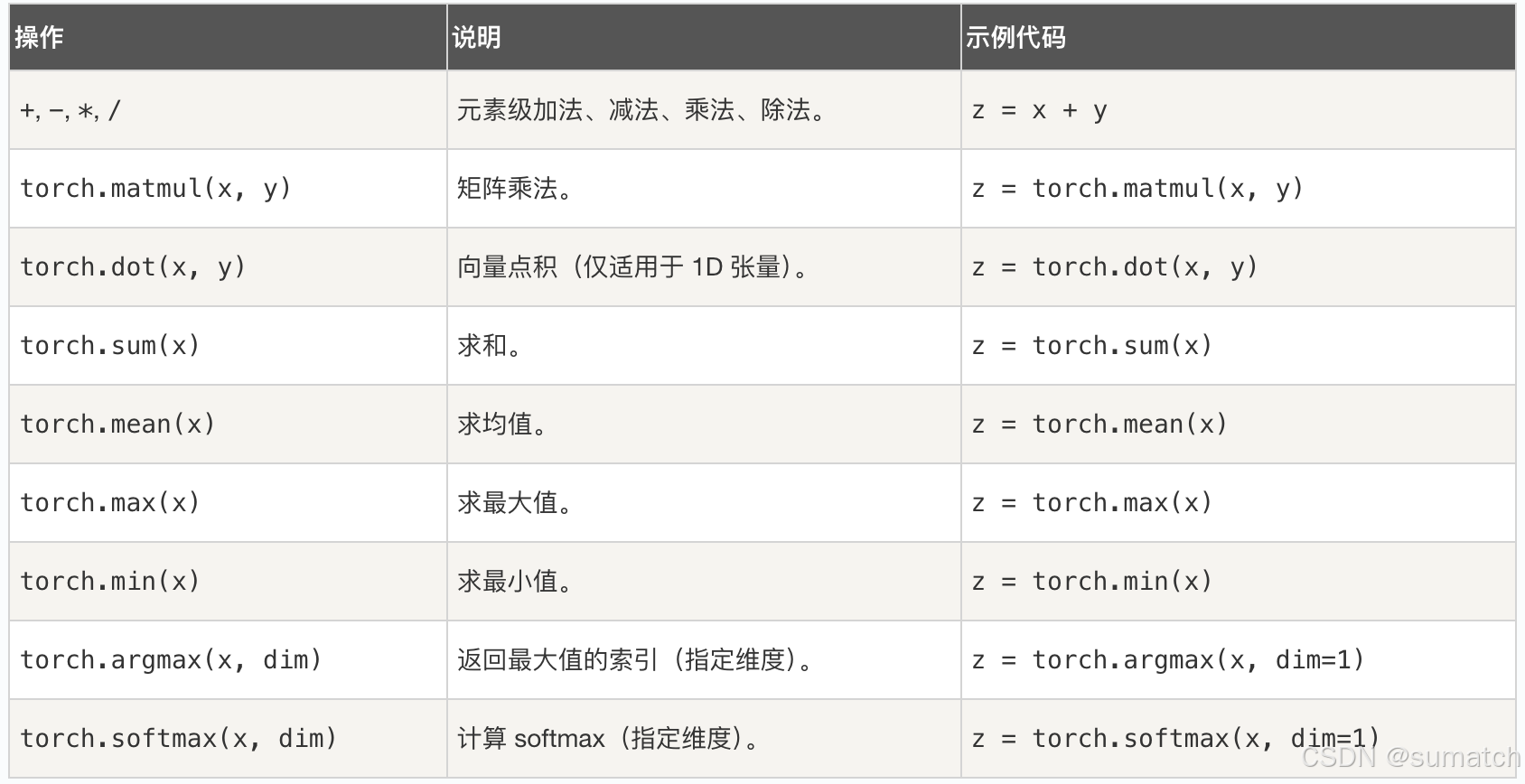
形状操作
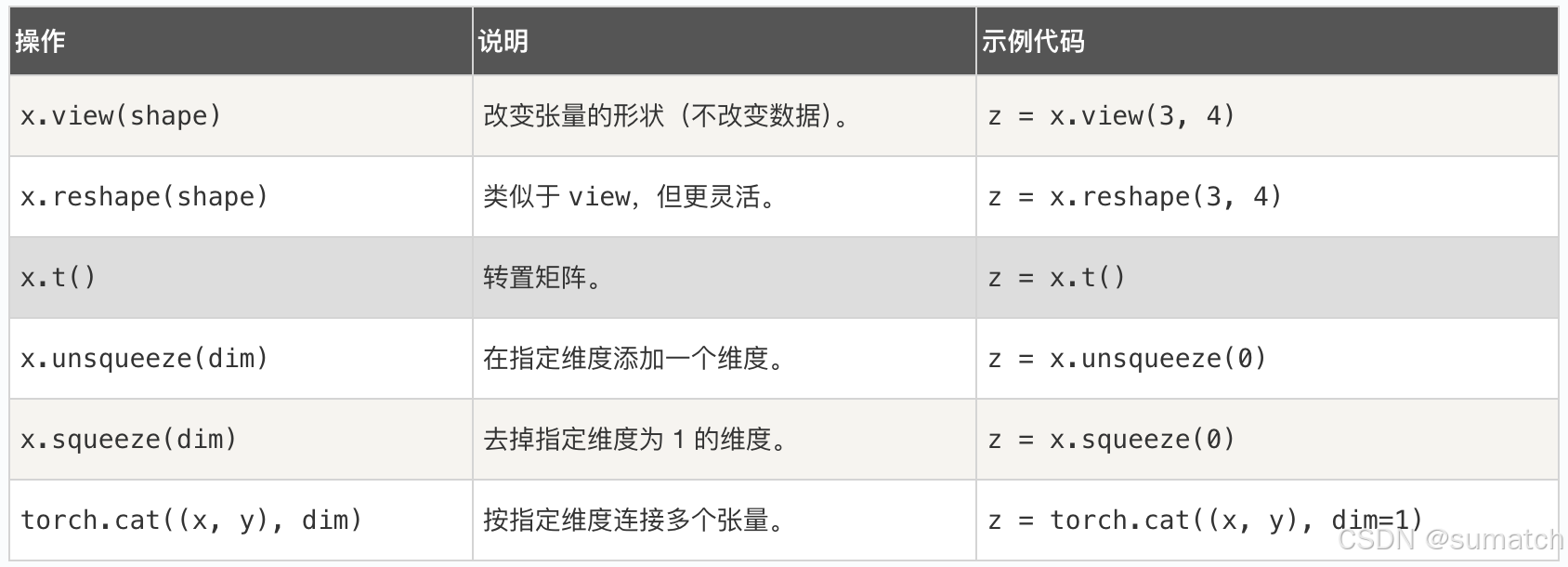
import torch
# 张量相加
e = torch.randn(2, 3)
f = torch.randn(2, 3)
print(e + f)
# 逐元素乘法
print(e * f)
# 张量的转置
g = torch.randn(3, 2)
print(g.t()) # 或者 g.transpose(0, 1)
# 张量的形状
print(g.shape) # torch.Size([3, 2])
张量与设备
PyTorch 张量可以存在于不同的设备上,包括 CPU 和 GPU,你可以将张量移动到 GPU 上以加速计算:
if torch.cuda.is_available():
tensor_gpu = tensor_from_list.to('cuda') # 将张量移动到GPU
梯度和自动微分
PyTorch 的张量支持自动微分,这是深度学习中的关键特性。当你创建一个需要梯度的张量时,PyTorch 可以自动计算其梯度:
import torch
# 创建一个需要梯度的张量
tensor_requires_grad = torch.tensor([1.0], requires_grad=True)
# 进行一些操作
tensor_result = tensor_requires_grad * 2
# 反向传传播,计算梯度
tensor_result.backward()
print(tensor_requires_grad.grad) # tensor([2.])
打印原始张量的梯度值,结果是 [2.],这是因为:
- 计算过程是
y = 2x - 导数
dy/dx = 2 - 所以当
x=1.0时,梯度值为2
这段代码展示了 PyTorch 自动微分系统的核心功能,是神经网络训练中反向传播的基础。
自动求导
在深度学习中,自动求导主要用于两个方面:一是在训练神经网络时计算梯度,二是进行反向传播算法的实现。
动态图与静态图:
-
动态图(Dynamic Graph):在动态图中,计算图在运行时动态构建。每次执行操作时,计算图都会更新,这使得调试和修改模型变得更加容易。PyTorch使用的是动态图。
-
静态图(Static Graph):在静态图中,计算图在开始执行之前构建完成,并且不会改变。TensorFlow最初使用的是静态图,但后来也支持动态图。
PyTorch 提供了自动求导功能,通过 autograd 模块来自动计算梯度。
torch.Tensor 对象有一个 requires_grad 属性,用于指示是否需要计算该张量的梯度。
当你创建一个 requires_grad=True 的张量时,PyTorch 会自动跟踪所有对它的操作,以便在之后计算梯度。
import torch
# 创建一个需要计算梯度的张量
x = torch.randn(2, 2, requires_grad=True)
print(x)
# tensor([[ 1.2989, 1.3075],
# [-0.3233, 0.4261]], requires_grad=True)
# 执行某些操作
y = x + 2
# y = [[1.2989+2, 1.3075+2],
# [-0.3233+2, 0.4261+2]]
# = [[3.2989, 3.3075],
# [1.6767, 2.4261]]
z = y * y * 3
# z = [[3.2989²×3, 3.3075²×3],
# [1.6767²×3, 2.4261²×3]]
# = [[32.6438, 32.8187],
# [8.4324, 17.6527]]
# z.mean()表示计算张量z中所有元素的平均值(算术平均数)
out = z.mean()
# out = (32.6438 + 32.8187 + 8.4324 + 17.6527) / 4
# = 91.5476 / 4
# ≈ 22.8869
print(out)
# tensor(22.8894, grad_fn=<MeanBackward0>)
反向传播
在神经网络训练中,自动求导主要用于实现反向传播算法。
反向传播是一种通过计算损失函数关于网络参数的梯度来训练神经网络的方法。在每次迭代中,网络的前向传播会计算输出和损失,然后反向传播会计算损失关于每个参数的梯度,并使用这些梯度来更新参数。
一旦定义了计算图,可以通过 .backward() 方法来计算梯度。
x = torch.tensor([[1.2989, 1.3075],
[-0.3233, 0.4261]], requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean()
# 反向传播,计算梯度
out.backward()
# 查看 x 的梯度
print(x.grad)
# tensor([[4.9483, 4.9612],
# [2.5150, 3.6392]])


前向传播与损失计算
import torch
import torch.nn as nn
# 定义一个简单的全连接神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 2) # 输入层到隐藏层
self.fc2 = nn.Linear(2, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x)) # ReLU 激活函数
x = self.fc2(x)
return x
# 创建网络实例
model = SimpleNN()
# 随机输入
x = torch.randn(1, 2)
# 前向传播
output = model(x) # 模型预测值
print(output)
# tensor([[0.6781]], grad_fn=<AddmmBackward0>)
# 定义损失函数(例如均方误差 MSE = 1/n * Σ(y_pred - y_true)^2)
criterion = nn.MSELoss()
target = torch.randn(1, 1) # 目标值
print(target)
# tensor([[-0.4049]])
# 计算损失
loss = criterion(output, target)
# loss = (output - target)^2
# = (0.6781 - (-0.4049))^2
# = (1.0830)^2
# ≈ 1.1730
print(loss)
# tensor(1.1730, grad_fn=<MseLossBackward0>)
优化器(Optimizers)
优化器是模型训练的"方向盘",负责高效、稳定地更新参数。
在 PyTorch 中,优化器(Optimizer) 是训练神经网络的核心组件,其作用是 通过反向传播计算出的梯度,动态调整模型参数(权重和偏置),以最小化损失函数。
-
核心作用
功能 说明 参数更新 根据梯度下降算法,自动调整模型参数( weight和bias)。学习率控制 通过设置学习率( lr),控制参数更新的步长(避免震荡或收敛过慢)。梯度处理 支持动量(Momentum)、自适应学习率等策略,加速收敛或避免局部最优。 批量处理 兼容不同批量大小(Batch Size),适应 SGD、Mini-batch GD 等训练方式。
-
优化器的工作流程
import torch.optim as optim # 定义模型和优化器 model = SimpleModel() # 假设有一个简单的模型 optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降 for epoch in range(100): # 前向传播 output = model(x) loss = criterion(output, target) # 反向传播 optimizer.zero_grad() # 清空梯度(重要!) loss.backward() # 计算梯度 # 参数更新 optimizer.step() # 根据梯度更新参数</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1666
1666




 到【灌水乐园】发言
到【灌水乐园】发言







