



 本文详细介绍了正则表达式的基本概念、元字符及其在Linux Shell中的应用,包括find、grep、egrep、sed和awk等工具的使用。通过实例展示了如何匹配特定模式,并提供了相关习题进行实践,帮助读者掌握正则表达式的实际操作技巧。
本文详细介绍了正则表达式的基本概念、元字符及其在Linux Shell中的应用,包括find、grep、egrep、sed和awk等工具的使用。通过实例展示了如何匹配特定模式,并提供了相关习题进行实践,帮助读者掌握正则表达式的实际操作技巧。
目录
常见元字符(支持的工具:find、grep、egrep、sed和awk)
正则表达式概述
正则表达式定义
正则表达式,又称正规表达式,常规表达式
使用字符串 来描述,匹配一系列符合某个规则的字符串(主要匹配命令结果和文本内容)
正则表示式组成:
普通字符:大小写字母,数字,标点符号及一些其他符号
元字符:在正则表达式中具有特殊意思的专用字符
常见元字符(支持的工具:find、grep、egrep、sed和awk)
| 匹配符 | 表示含义 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结束的位置 |
| . | 匹配除\n之外的任意的一个字符 |
| * | 匹配前面子表达式0次或者多次, |
| [list] | 匹配list列表中的一个字符 |
| [^list] | 匹配任意非list列表中的一个字符 |
| \{n\} | 匹配前面的子表达式n次 |
| \{n,\} | 匹配前面的子表达式不少于n次 |
| \{n,m\} | 匹配前面的子表达式n到m次 |
| 注:egrep、awk使用{n}、{n,}、{n,m}匹配时“{}"前不用加“\" | |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于[~0-9]。 |
| \s | 空白符 |
| \S | 非空白符 |
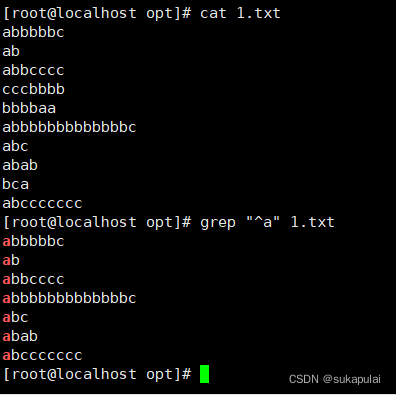
例:匹配以a为开头的
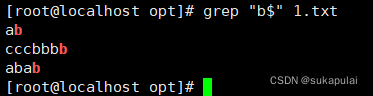
匹配以b结尾的
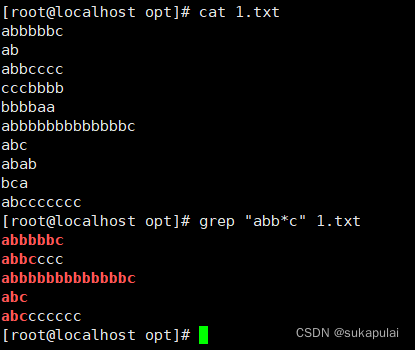
*号匹配前面的b零次或者多次
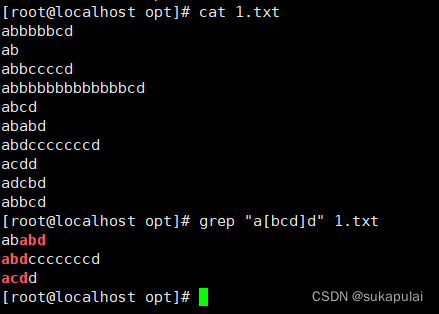
匹配[ ]里面任意一个字符
匹配除了bcd其他以外的字符
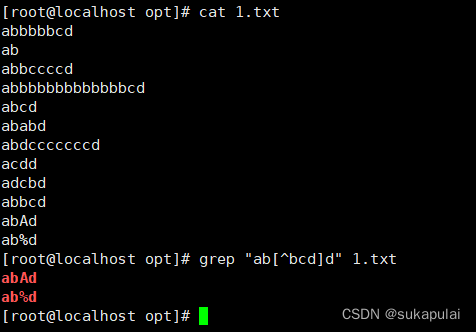
只匹配一个b

只匹配两个b
![]()
匹配前面的字符至少两次

匹配前面的字符一到两次

egrep可以实现不加转义字符
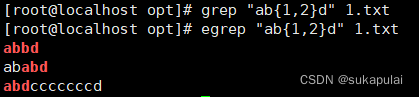
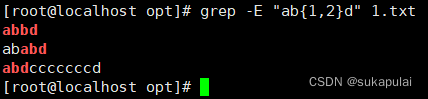
grep -E可以实现不加转义字符
扩展正则表达式
支持的工具:egrep、awk 或 grep -E 和 sed -r
| 匹配符 | 表示含义 |
|---|---|
| + | 匹配前面子表达式1次以上 |
| ? | 匹配前面子表达式0次或者一次 |
| () | 将括号中的字符串作为一个整体 |
| | | 以或的方式匹配字条串 |
例:+与星号相似,表示其前面字符出现一次或多次,但必须出现一次,>=1
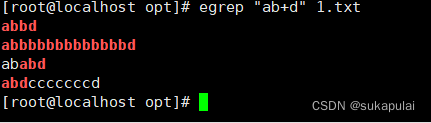
?只匹配前面字符的0次或者一次
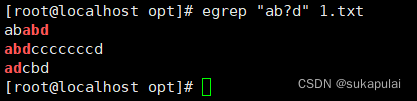
将括号中的字符串作为一个整体和+一起运用
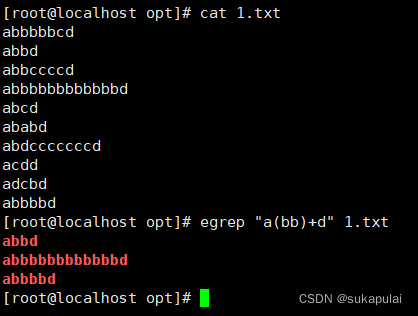
|或的效果 bb或c
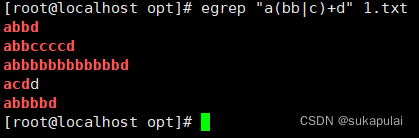
习题
[root@localhost opt]# cat 2.txt
02588888888
025-5555555555
025 12345678
025 54321678
025ABC88888
025-85432109把 02588888888 025 54321678 025-85432109 过滤出来并全部泛红
[root@localhost opt]# grep -E "^025(\s*|-)[58][0-9]{7}$" 2.txt
02588888888
025 54321678
025-85432109


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









