






 本文讲述了在Caffe中训练UNET模型时遇到的deconvolution层初始化困难问题,导致loss始终居高不下。作者尝试了各种方法,包括使用keras验证数据、借鉴HED网络、自定义初始化参数等。最终通过在HED预训练模型基础上进行finetune,并调整学习率,成功解决了问题。总结了Caffe在数据处理、损失函数和deconvolution层初始化上的不便。
本文讲述了在Caffe中训练UNET模型时遇到的deconvolution层初始化困难问题,导致loss始终居高不下。作者尝试了各种方法,包括使用keras验证数据、借鉴HED网络、自定义初始化参数等。最终通过在HED预训练模型基础上进行finetune,并调整学习率,成功解决了问题。总结了Caffe在数据处理、损失函数和deconvolution层初始化上的不便。
写在开头,珍爱生命,远离Caffe
在keras上做了一个很简单的分割任务,使用unet完成,基本上10个iteration之后accuracy就会到0.96,一个epoch之后accuracy达到0.99。需要在caffe上复现,但是效果一直不理想。
GitHub上下载了一个caffe版的unet,由于医学图像的格式不适合转成jpg,于是我用了hdf5层
layer {
name: "data"
type: "HDF5Data"
top: "img"
top: "mask"
include {
phase: TRAIN
}
hdf5_data_param {
source: "C:/iyuzu/UNet/unet-master/data/train/img.txt"
batch_size: 32
shuffle: false
}
}
写入h5文件的python代码
def img2h5(save_path, X, Y):
batch_size = 8000
num = len(X)
batch_num = int(math.ceil((1.0 * num) / batch_size))
print batch_num
# f=open(save_path + 'imglist.txt','w+')
for i in range(batch_num):
start = i * batch_size
end = min((i + 1) * batch_size, num)
if i < batch_num:
filename = save_path + '/train{0}.h5'.format(i)
else:
filename = save_path + '/test{0}.h5'.format(i)
with h5py.File(filename, 'w') as fh:
# fh.create_dataset('img', data= X.reshape(X.shape[0:3]))
fh.create_dataset('img', data=X[start: end])
fh.create_dataset('mask', data=Y[start: end])
fh.close()
X,Y是提前读取的所有图片和mask的四维数组。根据自己的需求改一下图片读取的代码
X_train = np.ndarray((images_count, 3, IMG_ROWS, IMG_COLS), dtype=np.int16)
Y_train = np.ndarray((images_count, 1, IMG_ROWS, IMG_COLS), dtype=np.uint8)
使用文件路径改好后,使用unet开始训练,loss为sigmoidwithcrossentropy,训练过程中loss一直保持在11304.1不变,无论怎么改学习率或者超参数都不好用。
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #0: dsn1_loss = 11301.4 (* 1 = 11301.4 loss)
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #1: dsn2_loss = 11301.4 (* 1 = 11301.4 loss)
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #2: dsn3_loss = 11301.4 (* 1 = 11301.4 loss)
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #3: dsn4_loss = 11301.4 (* 1 = 11301.4 loss)
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #4: dsn5_loss = 11301.4 (* 1 = 11301.4 loss)
I0325 14:47:08.897768 3840 solver.cpp:244] Train net output #5: fuse_loss = 11301.4 (* 1 = 11301.4 loss)
怀疑是数据问题,检查好几遍之后没有发现问题,用keras加载转成h5的数据训练unet,loss下降很快,数据没有问题。
z是上一层的输出,y的取值在0-1之间,当z为0,y的值为-0.69,带入crossentropyloss的定义式中
由于unet用caffe实现的资料比较少,干脆换一个经典的caffe分割网络HED,使用HED训练之后,结果更神奇了,HED有五层loss和最后一个总的loss,只有第一个loss和最后一层的总loss在变化
第一个loss对应conv1_1,就是第一个卷积层,大小和原图一样,其余的loss都是经过卷积层下采样之后又通过deconvolution得到的,也就是说其他的层什么都没有学到……
基本上可以确定问题出在deconvolution层的初始化问题,而keras中用的时upsampling层不需要初始化参数,所以不存在这个问题。但是caffe中又没有直接的upsampling层……我也不会写caffe的c++的层……死循环哦。
网上查到的方法一些解决deconvolution层初始化困难的方法,就是fcn自带的使用python初始化deconvolution
from __future__ import division
import caffe
import numpy as np
def transplant(new_net, net, suffix=''):
"""
Transfer weights by copying matching parameters, coercing parameters of
incompatible shape, and dropping unmatched parameters.
The coercion is useful to convert fully connected layers to their
equivalent convolutional layers, since the weights are the same and only
the shapes are different. In particular, equivalent fully connected and
convolution layers have shapes O x I and O x I x H x W respectively for O
outputs channels, I input channels, H kernel height, and W kernel width.
Both `net` to `new_net` arguments must be instantiated `caffe.Net`s.
"""
for p in net.params:
p_new = p + suffix
if p_new not in new_net.params:
print 'dropping', p
continue
for i in range(len(net.params[p])):
if i > (len(new_net.params[p_new]) - 1):
print 'dropping', p, i
break
if net.params[p][i].data.shape != new_net.params[p_new][i].data.shape:
print 'coercing', p, i, 'from', net.params[p][i].data.shape, 'to', new_net.params[p_new][i].data.shape
else:
print 'copying', p, ' -> ', p_new, i
new_net.params[p_new][i].data.flat = net.params[p][i].data.flat
def upsample_filt(size):
"""
Make a 2D bilinear kernel suitable for upsampling of the given (h, w) size.
"""
factor = (size + 1) // 2
if size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:size, :size]
return (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
def interp(net, layers):
"""
Set weights of each layer in layers to bilinear kernels for interpolation.
"""
for l in layers:
m, k, h, w = net.params[l][0].data.shape
# if m != k and k != 1: #我把这句话注释了,因为我的网络结构里面不需要m和k相等,留着会报错
# print 'input + output channels need to be the same or |output| == 1'
# raise
if h != w:
print 'filters need to be square'
raise
filt = upsample_filt(h)
for kk in range(k):
net.params[l][0].data[range(m), kk, :, :] = filt
def expand_score(new_net, new_layer, net, layer):
"""
Transplant an old score layer's parameters, with k < k' classes, into a new
score layer with k classes s.t. the first k' are the old classes.
"""
old_cl = net.params[layer][0].num
new_net.params[new_layer][0].data[:old_cl][...] = net.params[layer][0].data
new_net.params[new_layer][1].data[0,0,0,:old_cl][...] = net.params[layer][1].data
然后在solver里面调用上面的文件初始化参数
import sys
caffe_root = r'C:\iyuzu\caffe-master\caffe-master'
sys.path.append(caffe_root+r'\python')
import caffe
sys.path.append(r'C:\iyuzu\UNet\unet-master')
import surgery
import numpy as np
import os
weights = 'C:/iyuzu/UNet/unet-master/snapshot/_iter_2000.caffemodel'
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver('.\solver.prototxt')
solver.net.copy_from(weights)
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
train = solver.solve()
训练之后确实loss会改善,不在都是11304.1,但是几十个iteration之后会发现loss一直徘徊在9000左右不在下降,训练再久都没用,改了lr也没有效果。
所以还是deconcolution的初始化问题,最后还是要站在巨人的肩膀上,在hed公开的caffemodel的基础上进行finetune(unet没有公开的训练好的caffemodel),然后
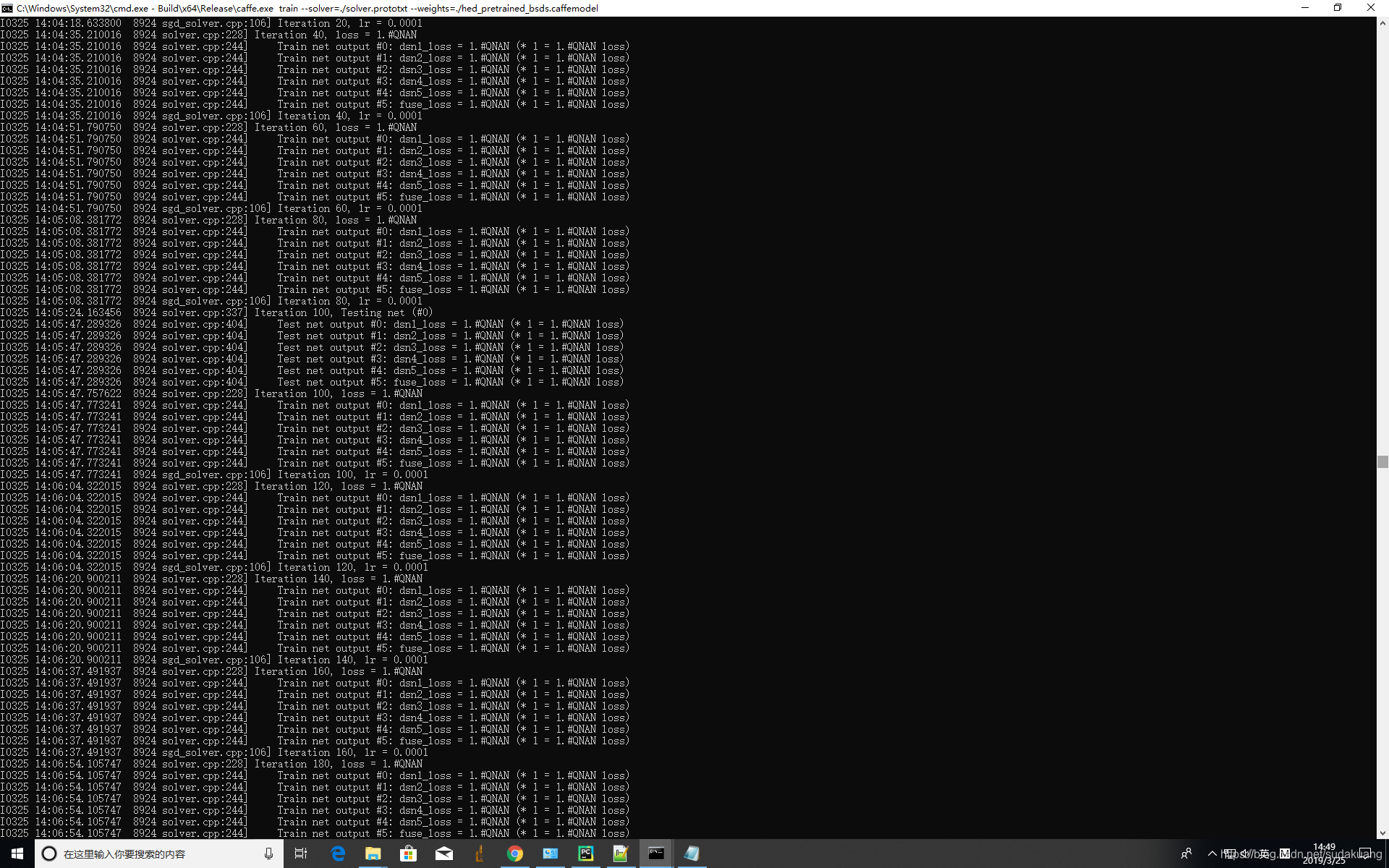
五个loss不一样了,但是下一次iteration就是nan了。遇到这种情况一般解决办法就是调低lr,调低lr,调低lr……
总的lr调低以后还是不行,再调低第五层的loss在训练文件prototxt中对应位置的lr_mult,调小几个数量级试一下
###DSN conv 5###
layer { name: 'score-dsn5' type: "Convolution" bottom: 'conv5_3' top: 'score-dsn5'
param { lr_mult: 0.00001 decay_mult: 1 } param { lr_mult: 0.00002 decay_mult: 0}
convolution_param { engine: CAFFE num_output: 1 kernel_size: 1 } }
layer { type: "Deconvolution" name: 'upsample_16' bottom: 'score-dsn5' top: 'score-dsn5-up'
param { lr_mult: 0 decay_mult: 1 } param { lr_mult: 0 decay_mult: 0}
convolution_param { kernel_size: 32 stride: 16 num_output: 1 } }
layer { type: "Crop" name: 'crop' bottom: 'score-dsn5-up' bottom: 'img' top: 'upscore-dsn5' }
layer { type: "SigmoidCrossEntropyLoss" bottom: "upscore-dsn5" bottom: "mask" top:"dsn5_loss" loss_weight: 1}
最后slover的lr是1e-7的时候,第五层lr_mult=1e-5的时候,终于work了,loss开始下降
I0325 14:52:00.175212 2736 solver.cpp:228] Iteration 3060, loss = 21926.3
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #0: dsn1_loss = 8542.15 (* 1 = 8542.15 loss)
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #1: dsn2_loss = 7356.63 (* 1 = 7356.63 loss)
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #2: dsn3_loss = 3928.57 (* 1 = 3928.57 loss)
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #3: dsn4_loss = 851.404 (* 1 = 851.404 loss)
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #4: dsn5_loss = 625.175 (* 1 = 625.175 loss)
I0325 14:52:00.175212 2736 solver.cpp:244] Train net output #5: fuse_loss = 622.345 (* 1 = 622.345 loss)
I0325 14:52:00.175212 2736 sgd_solver.cpp:106] Iteration 3060, lr = 1e-008
I0325 14:52:13.997128 2736 solver.cpp:228] Iteration 3080, loss = 21844.2
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #0: dsn1_loss = 8544.59 (* 1 = 8544.59 loss)
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #1: dsn2_loss = 7304.57 (* 1 = 7304.57 loss)
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #2: dsn3_loss = 3879.47 (* 1 = 3879.47 loss)
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #3: dsn4_loss = 854.137 (* 1 = 854.137 loss)
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #4: dsn5_loss = 663.732 (* 1 = 663.732 loss)
I0325 14:52:13.997128 2736 solver.cpp:244] Train net output #5: fuse_loss = 597.666 (* 1 = 597.666 loss)
I0325 14:52:13.997128 2736 sgd_solver.cpp:106] Iteration 3080, lr = 1e-008
keras一个小时可以搞定的工作,在caffe上弄了两个礼拜,感谢领导好脾气没有开了我……
总结一下
1.就是caffe的data层用起来不方便,需要自己转数据(ps:尝试用python层读取数据,pycaffe接口编译好之后,调用py层的时候一直有一个 错误
No to_python (by-value) converter found for C++ type: class caffe::LayerParameter
查了好久也没找到解决办法,只能放弃了
2.caffe的loss种类比较少,我又不会写C++
3. deconvolution层的自动初始化困难。

















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









