




 VITON是一个2018年的研究工作,提出了一个图像为基础的虚拟试衣网络,用于合成人穿上目标衣服的效果。网络采用多任务编码器-解码器结构,结合人体姿态热图、人体分割和脸部头发分割信息,生成逼真的试衣图像。通过细节网络进行精细化处理,处理衣服变形和合成图像的细节。实验结果显示,VITON在保留人物姿势、身体形状和目标衣服细节方面表现出色。
VITON是一个2018年的研究工作,提出了一个图像为基础的虚拟试衣网络,用于合成人穿上目标衣服的效果。网络采用多任务编码器-解码器结构,结合人体姿态热图、人体分割和脸部头发分割信息,生成逼真的试衣图像。通过细节网络进行精细化处理,处理衣服变形和合成图像的细节。实验结果显示,VITON在保留人物姿势、身体形状和目标衣服细节方面表现出色。
[paper]VITON: An Image-based Virtual Try-on Network(2018)
[code]VITON
效果

网络结构
-
人的量化表示
- 人姿态热图
人的姿态用18个关键点表示。为了利用空间布局,每个关键点都将进一步转换为热图,关键点周围11x11领域设置为1,其他位置区域设置为0。然后将热图堆叠到18通道的姿势热图中。 - 人体表示
衣服的外观高度取决于人身体不同部位的位置和形状,使用人体解析算法对人身体的不同部位进行分割,将分割图进一步转换为1通道的二进制掩码,其中除了人脸和头发人身体用1表示,其他都用0表示。二进制掩码图下采样到较低的分辨率,避免在身体形状和目标衣服发生冲突出现伪像。 - 人脸和头发分割
使用人体分析提取人的脸部和头发区域的RGB通道,用来在生成新图像时注入身份信息。

- 人姿态热图
-
多任务编解码生成器
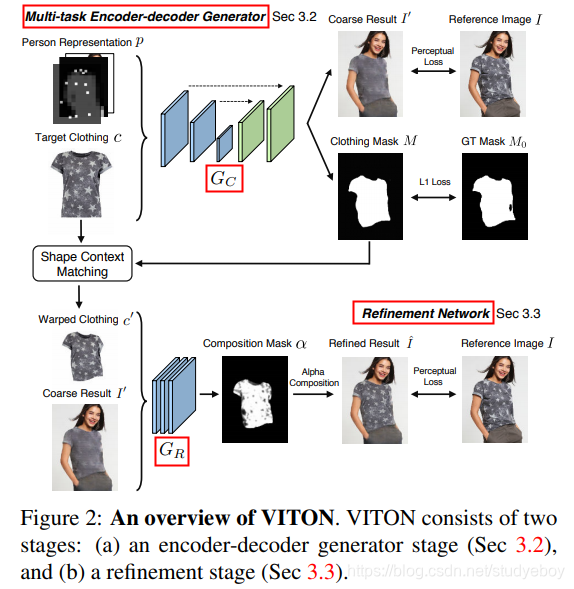
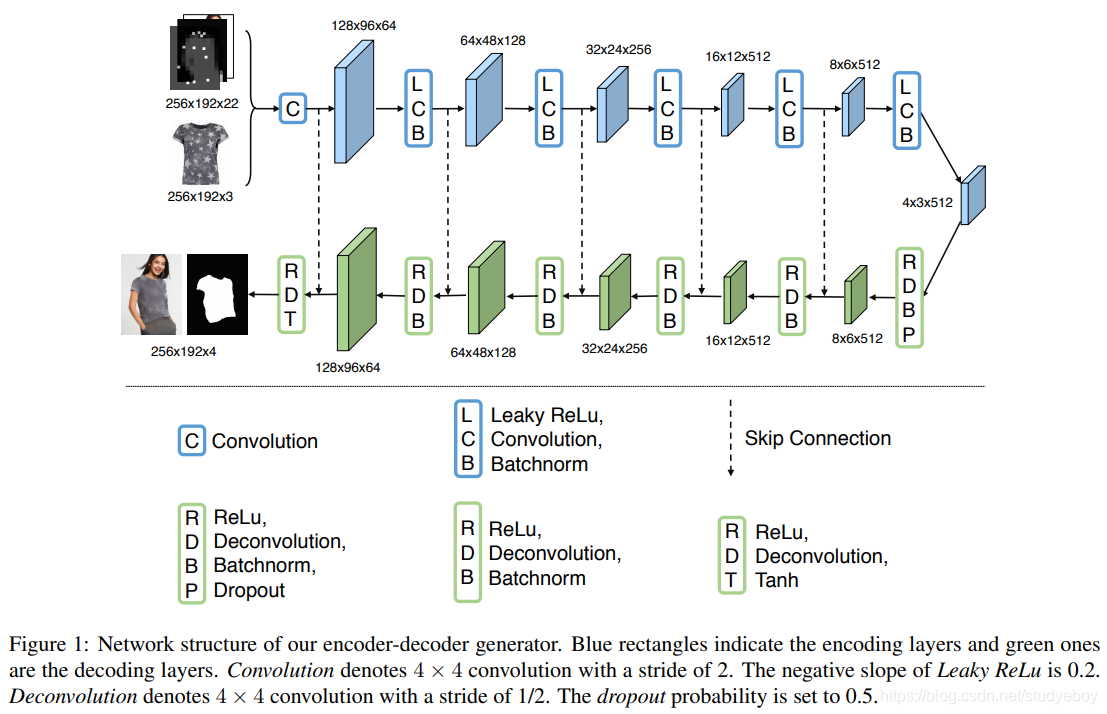
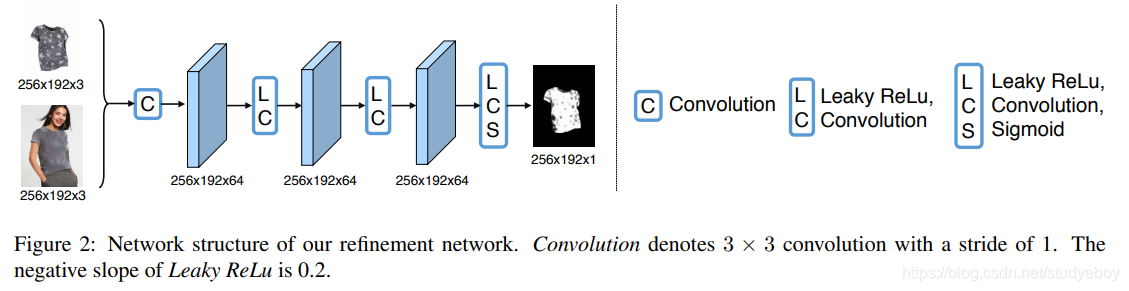
给定衣服无关的人的表示p和目标衣服c,通过c到p中相应区域的转换的重构方式来合成参考图像。利用多任务编码器-解码器框架,生成穿衣服的人像以及该人的衣服蒙版,进一步使用预测的衣服蒙版来细化所生成的结果。编码器-解码器是U-Net体现结构的一种通用类型,使用跳过连接可以通过旁路连接直接在层之间共享信息。
用 G C G_C GC表示编码器-解码器生成器,输入目标衣服 c c c和人的表示 p p p,输出合成图像 I ′ I' I′(3通道彩色图像)和衣服掩码 M M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









