






一、软件介绍
文末提供程序和源码下载
Superduper 是一个基于 Python 的框架,用于在您自己的数据上构建端到端 AI 数据工作流和应用程序,并与主要数据库集成。它支持最新的技术和技巧,包括LLMs向量搜索、RAG、多模态以及经典的 AI 和 ML 范式。开发人员可以通过构建组合和声明性对象来利用 Superdoper,这些对象将部署、编排和版本控制等细节外包给 Superduper 引擎。这使开发人员可以完全避免实施 MLOps、ETL 管道、模型部署、数据迁移和同步。使用 Superduper 就是简单的“CAPE”:连接到您的数据,将任意 AI 应用于该数据,在任意数据上打包和重用应用程序,并对生成的 AI 输出和数据执行 AI 数据库查询和预测。
Connect 连接
db = superduper('mongodb|postgres|mysql|sqlite|duckdb|snowflake://<your-db-uri>')
Apply 应用
listener = MyLLM('self_hosted_llm', architecture='llama-3.2', postprocess=my_postprocess).to_listener('documents', key='txt')
db.apply(listener)
Package 包
application = Application('my-analysis-app', components=[listener, vector_index])
template = Template('my-analysis', component=app, substitutions={'documents': 'table'})
template.export('my-analysis')
Execute 执行
query = db['documents'].like({'txt', 'Tell me about Superduper'}, vector_index='my-index').select()
query.execute()
二、软件特点
plugins 和
templates 目录中提供了一系列预构建的功能。特别是,当 AI 和数据需要以持续和紧密集成的方式交互时,Superduper 表现出色。以下是一些说明性示例,您可以从我们的模板中试用:
语义多模态向量搜索(图像、文本、视频)
具有特殊要求的检索增强生成(数据获取涉及语义搜索以及业务规则和预处理)
LLM对数据库托管数据进行微调
使用多模态数据进行迁移学习
三、核心功能
- 创建一个由您自己的 Superduper data-AI 连接/数据层
- databackend (数据库/ datalake/ 数据仓库)
- 元数据存储(与 DataBackEnd 相同或其他)
- artifact store (用于存储大型对象)
- 计算实现
- 使用声明式编程模型构建复杂的功能单元 ( Component ),该模型使用一组简单的基元和基类与 databackend 中的数据紧密集成。
- 构建更大的功能单元,将多个相互关联的 Component 实例包装到一个 AI 数据 Application 中
- 重用经过实战检验 Component 的 实例 Model 和 使用 Template 的 Application 实例,为开发人员提供了一个简单的起点,以便开始困难的 AI 实施
- 透明、可读、Web 友好且高度可移植的序列化协议“Superduper-protocol”,用于传达实验结果,使 Application 世系和版本控制易于遵循,并创建从 AI 世界到数据库/类型数据世界的优雅 segway。
- 使用 Model 实例输出和主要数据后端数据的组合来执行查询,以支持最新一代的 AI 数据应用程序,包括各种形式的矢量搜索、RAG 等等。
四、主要优势
极大的灵活性
将任何基于 Python 的 AI 模型、来自生态系统的 API 与最成熟、经过实战检验的数据库和仓库相结合;Snowflake、MongoDB、Postgres、MySQL、SQL Server、SQLite、BigQuery 和 Clickhouse 都受支持。
无缝集成,避免 MLOps
无需使用声明性和组合性 Superduper 组件实现 MLOps,这些组件指定模型和数据应达到的最终状态。
提升代码的可重用性和可移植性
将组件打包为模板,公开在社区和组织中重用和交流 AI 应用程序所需的关键参数。
节省成本
实现向量搜索和嵌入生成,而无需专用的向量数据库。在自托管模型和 API 托管模型之间轻松切换,无需更改重大代码。
无需任何额外工作即可迁移到生产环境
Superduper 的 REST API 允许提供已安装的模型,而无需额外的开发工作。对于企业级可扩展性、故障保护、安全性和日志记录,使用 Superduper 创建的应用程序和工作流程可以在 Superduper enterprise 上一键部署。
main 分支中有哪些新增功能?
我们正在开发即将发布的 0.5.0 .在此版本中,我们将提供:
用于更新已应用组件的正常更新架构
这意味着更改 Prompt 或 parameter Component 并不意味着从头开始所有组件。这也为回滚和版本固定奠定了基础。
利用 Template 类的智能表单构建器
这将允许开发人员将其应用程序公开为无代码接口。
基于 Python 原生类型注释的序列化
from superduper import typing as t
class MyPDF:
path: t.File
my_func: t.Blob
my_other_func: t.Pickle
五、 开始
安装:
pip install superduper-framework
查看可用的预构建模板:
superduper ls
连接并应用预构建的模板:
(注意:预构建的模板仅受 Python 3.10 支持;您可以使用 Python 3.11+ 中的所有其他功能。
# e.g. 'mongodb://localhost:27017/test_db'
SUPERDUPER_DATA_BACKEND=<your-db-uri> superduper apply simple_rag
对结果执行查询或预测:
from superduper import superduper
db = superduper('<your-db-uri>') # e.g. 'mongodb://localhost:27017/test_db'
db['rag'].predict('Tell me about superduper')
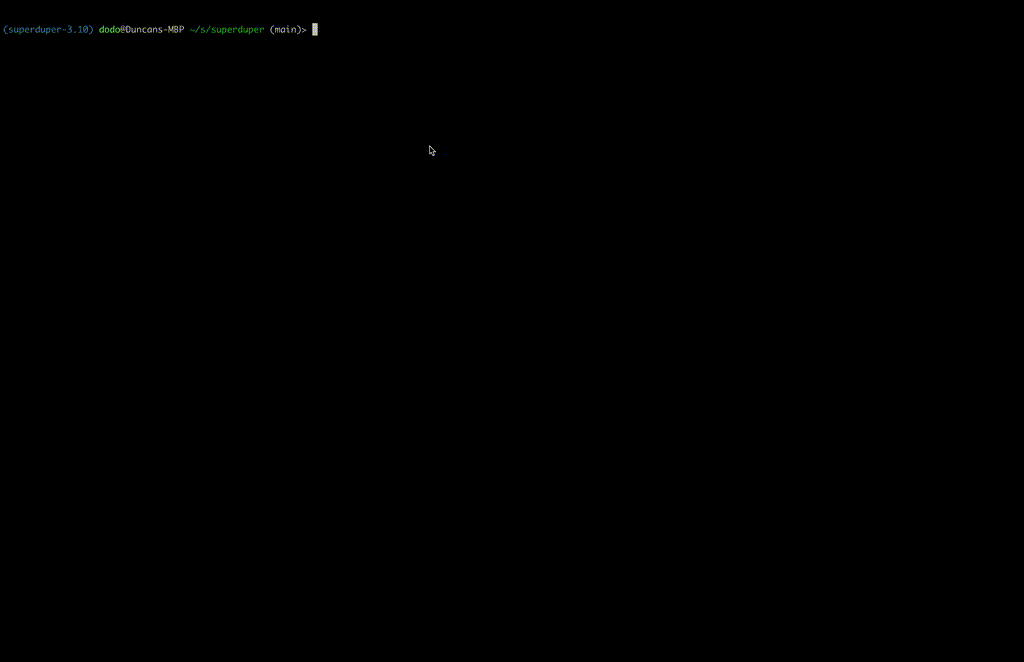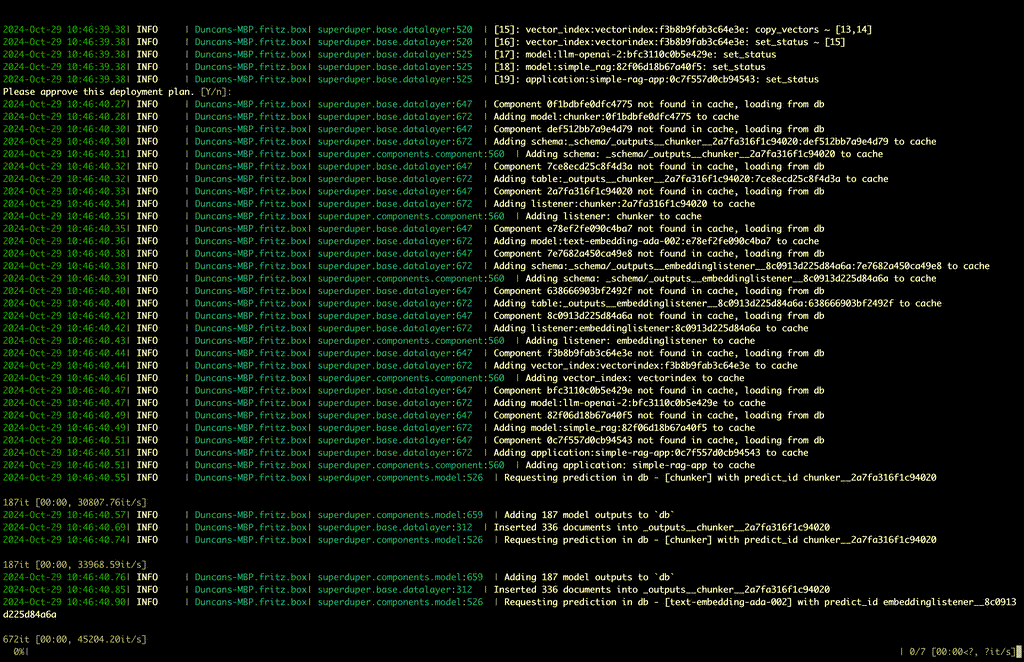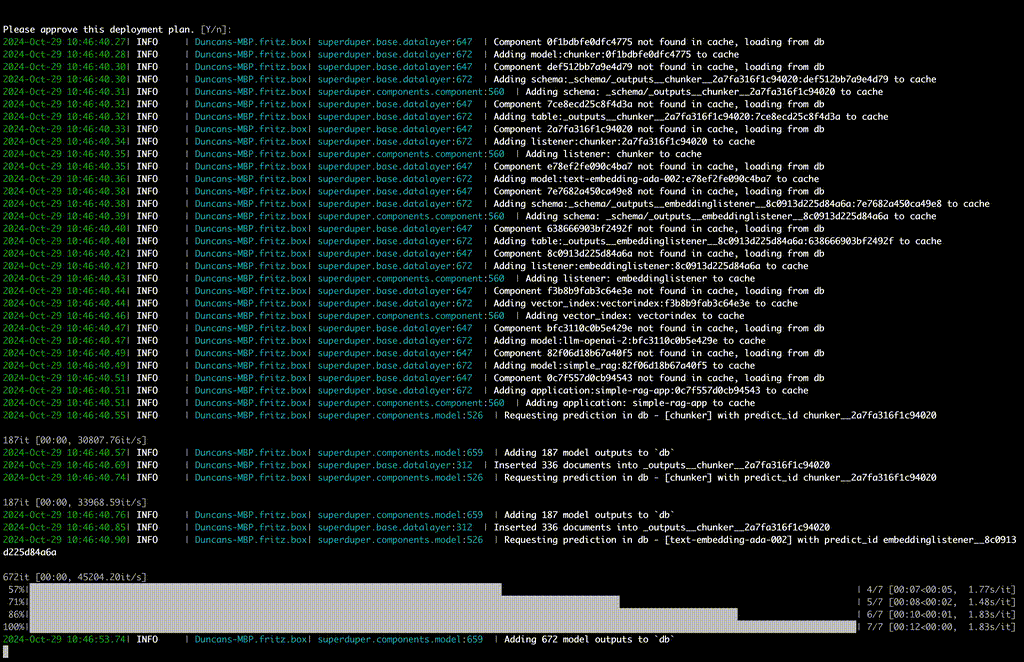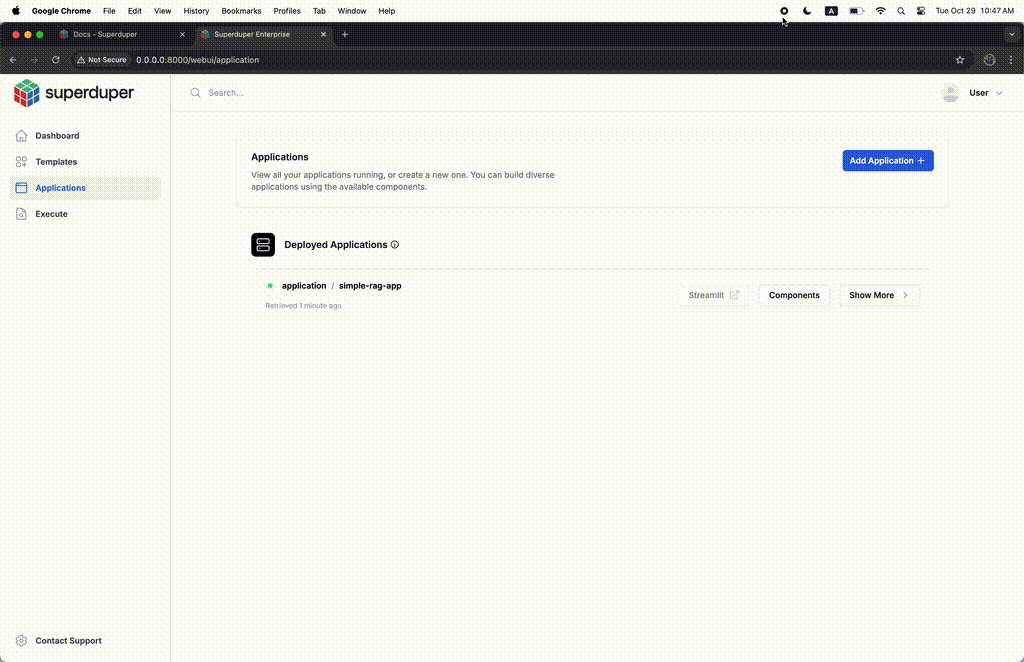
在 Superduper 界面中查看和监控所有内容。从命令行:
superduper start
完成这些之后,您就可以构建自己的组件、应用程序和模板了!
首先将现有模板复制到您自己的开发环境:
superduper bootstrap <template_name> --destination templates/my-template
编辑 build.ipynb 笔记本,以构建您自己的功能。
当前支持的数据存储
MongoDB
MongoDB Atlas
PostgreSQL
MySQL (MySQL的
SQLite
DuckDB
谷歌 BigQuery
Microsoft SQL Server (MSSQL)
六、软件源码下载
GitHub作者地址:https://github.com/superduper-io/superduper
本文信息来源于作者GitHub地址


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









