







 本文介绍了一种基于CVPR19的研究工作,该方法通过人为生成包含特定错误类型的姿势数据进行数据增强,以改善姿态估计网络的鲁棒性和准确性。文中详细介绍了网络结构及损失函数的设计。
本文介绍了一种基于CVPR19的研究工作,该方法通过人为生成包含特定错误类型的姿势数据进行数据增强,以改善姿态估计网络的鲁棒性和准确性。文中详细介绍了网络结构及损失函数的设计。
CVPR19
这篇文章本质上应该是做了一个data augmentation的工作……
前面有人做了统计各种pose estimation会产生的错误, 比如missing, jitte, swap等, 得到各种错误的概率分布, 那么其实很自然的想法是人工生成这些错误的姿势, 再refine网络, 这样的数据增强肯定是有用的。
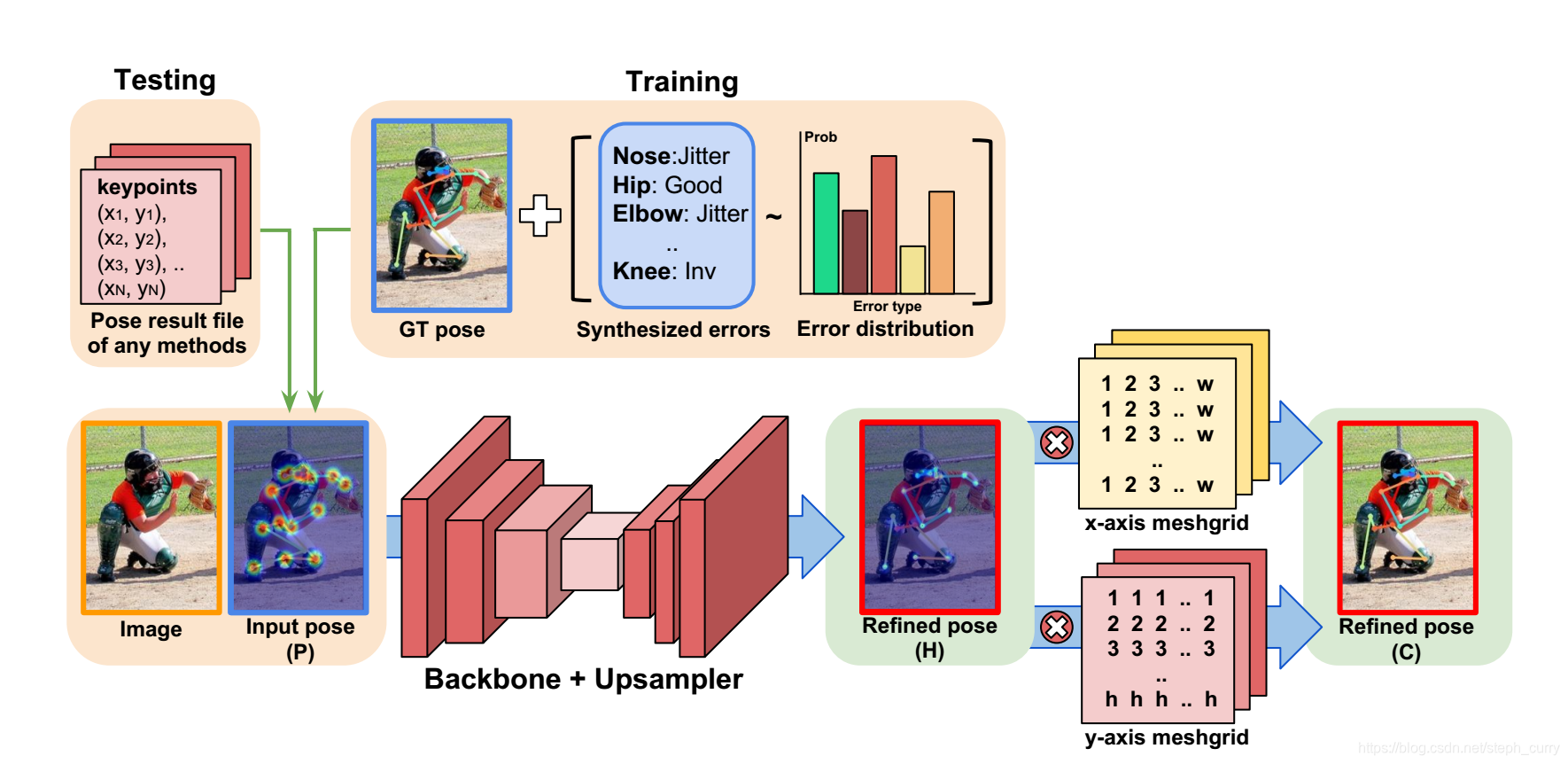
训练时, 输入是图像和生成的相对应的pose, 这个pose可能是包含错误点的, 然后concat,输入到网络中, 这个网络就是Resnet + deconv层, 生成的refine pose H。loss如下:
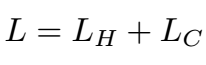
其中:
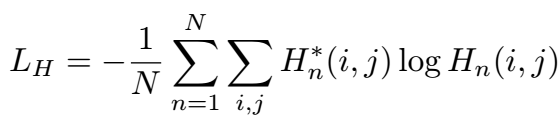
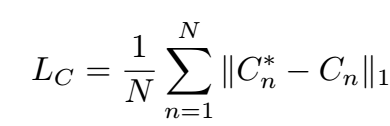
C是坐标, 生成方式(本质就是Integral loss):
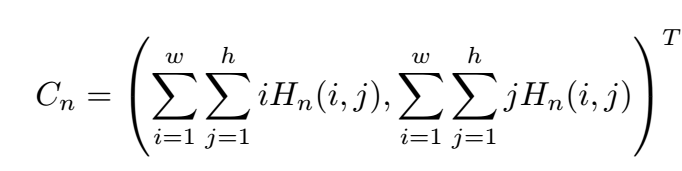
note: 这里H用one-hot向量来监督, 也就是除了keypoint的点为1, 其余位置均为0.这样会起到refine的效果吧。
疑惑:这里把heatmap的loss和坐标点的loss一起计算做回传, 效果会好吗? 一般来说, 彼此之间会互相干扰, 降低精度吧。

















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









