



 本文通过Python的Pandas, Seaborn等库对Anascombe数据集进行了详细的统计分析,包括计算均值、方差、相关系数,并对每个子数据集进行线性回归分析。同时展示了数据分布的散点图。
本文通过Python的Pandas, Seaborn等库对Anascombe数据集进行了详细的统计分析,包括计算均值、方差、相关系数,并对每个子数据集进行线性回归分析。同时展示了数据分布的散点图。
%matplotlib inline
import random
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
sns.set_context("talk")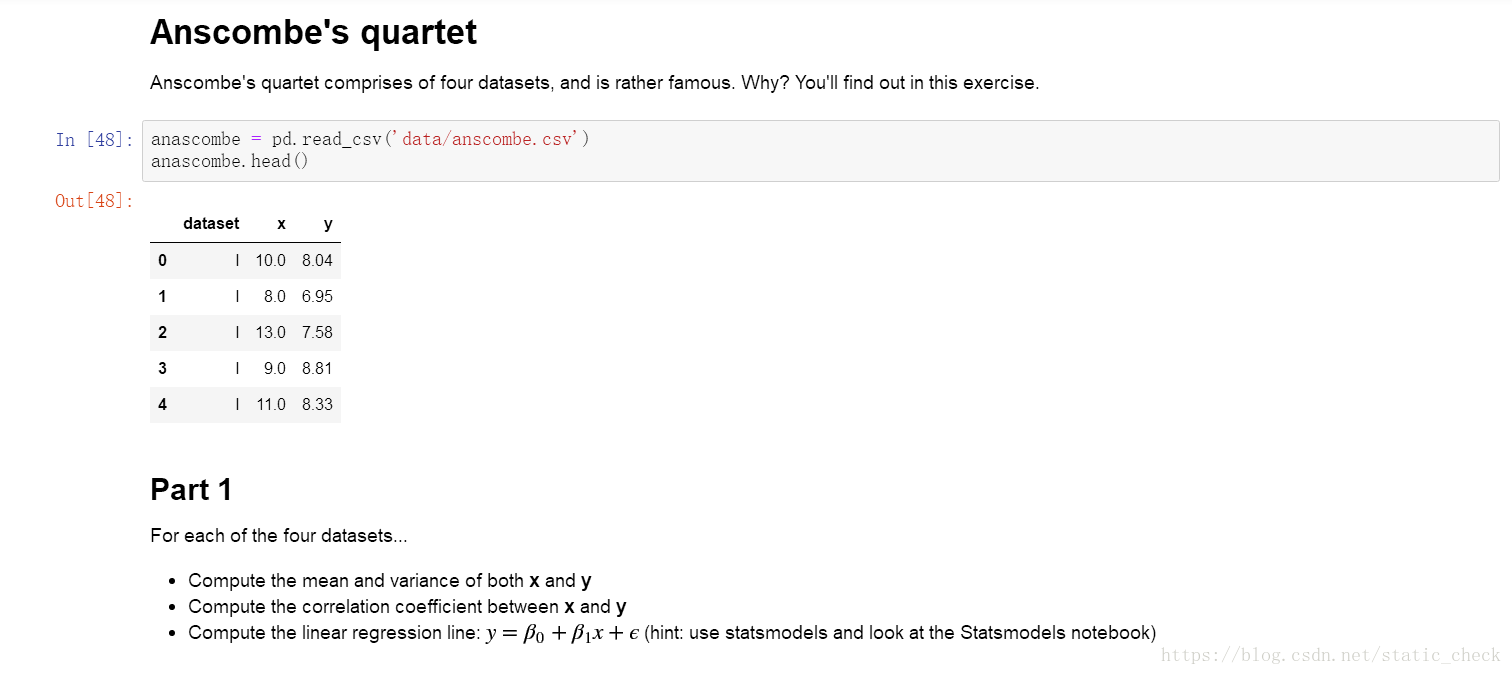
# your code here
# 计算均值
print("\n均值:")
print(anascombe.groupby('dataset')['x'].mean())
print(anascombe.groupby('dataset')['y'].mean())
# 计算方差
print("\n方差:")
print(anascombe.groupby('dataset')['x'].var())
print(anascombe.groupby('dataset')['y'].var())
# 计算相关系数
print("\n相关系数:")
print(anascombe.x.corr(anascombe.y))
# 计算线性回归
dataset = anascombe[(anascombe['dataset']=='I')].reset_index(drop=True)
result = smf.ols('y ~ x', dataset).fit()
print(result.summary())
dataset = anascombe[(anascombe['dataset']=='II')].reset_index(drop=True)
result = smf.ols('y ~ x', dataset).fit()
print(result.summary())
dataset = anascombe[(anascombe['dataset']=='III')].reset_index(drop=True)
result = smf.ols('y ~ x', dataset).fit()
print(result.summary())
dataset = anascombe[(anascombe['dataset']=='IV')].reset_index(drop=True)
result = smf.ols('y ~ x', dataset).fit()
print(result.summary()) 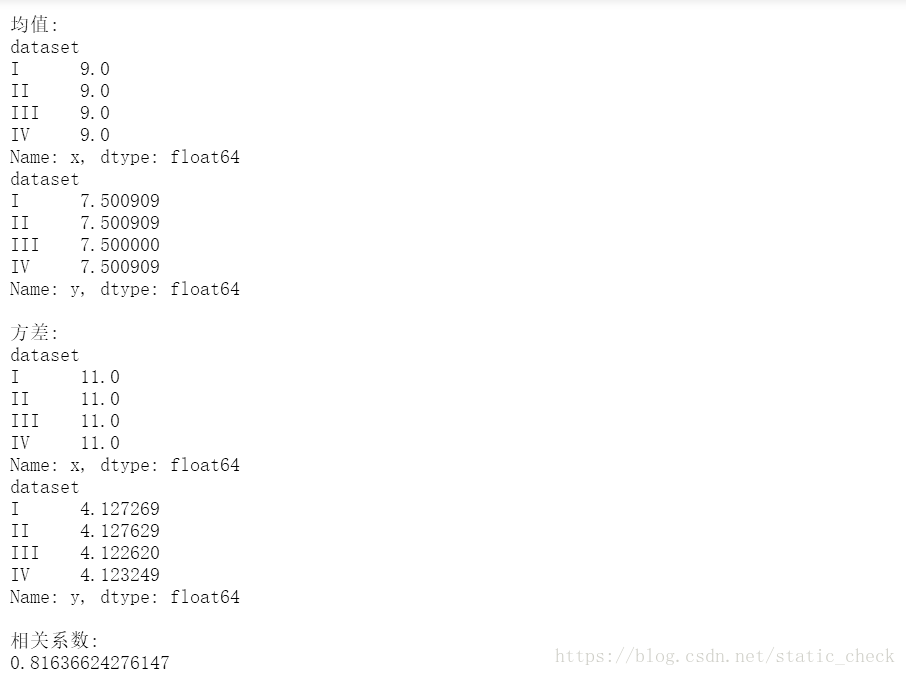
以数据集1为例


# your code here
sns.set(style='whitegrid')
sns.FacetGrid(anascombe, col="dataset", hue="dataset", size=3) .map(plt.scatter, 'x', 'y') 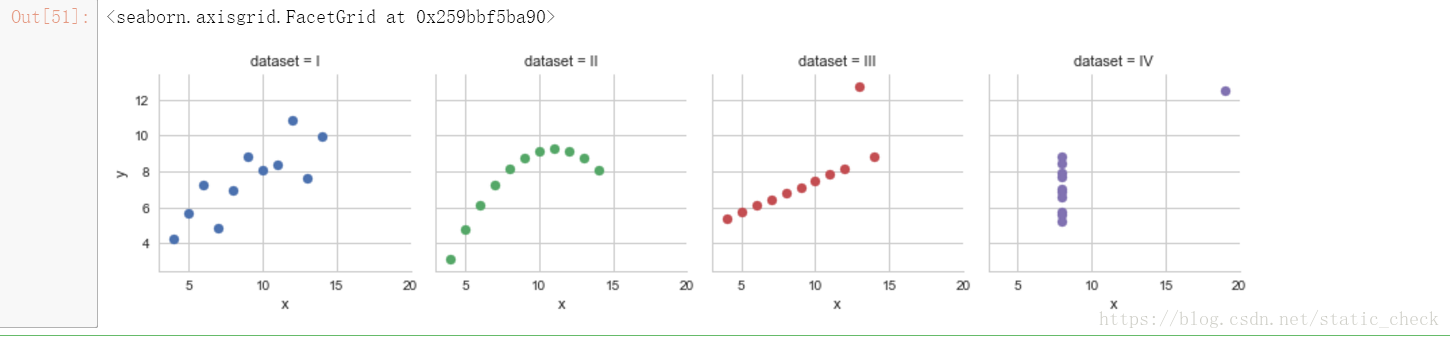

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









