




 本文详细介绍了大端和小端模式下数据在内存中的存储方式,以及边界对齐的概念,解释了处理器如何通过边界对齐提高数据处理效率。
本文详细介绍了大端和小端模式下数据在内存中的存储方式,以及边界对齐的概念,解释了处理器如何通过边界对齐提高数据处理效率。
一、大端模式和小端模式
计算机的字节顺序模式分为大端数据模式和小端数据模式,它们是根据数据在内存中的存储方式来区分的。其中,大端和小端和计算机的字长没有关系,而是固有的特性。
- Little-Endian 就是低位字节存放在内存的低地址端,高位字节存放在内存的高地址端。
- Big-Endian 就是高位字节存放在内存的低地址端,低位字节存放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:
(1)大端模式(正序):
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
(2)小端模式(逆序):
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
(3)下面是两个具体例子:
- 16bit 宽的数 0x1234 在 Little-endian 模式(以及 Big-endian 模式)CPU内存中的存放方式(假设从地址 0x4000 开始存放)为:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 |
|---|---|---|
| 0x4000 | 0x34 | 0x12 |
| 0x4001 | 0x12 | 0x34 |
- 32bit宽的数0x12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 |
|---|---|---|
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
二、边界对齐
内存对齐,也叫边界对齐(Boundary Alignment),是处理器为了提高处理性能而对存取数据的起始地址所提出的一种要求。编译器为了使我们编写的C程序更有效,就必须最大限度地满足处理器对边界对齐的要求。
要求如下,即对于存放某长度为 m 字节的数据,存放首地址需为 m 字节的整数倍,同时,结构体整体的大小是最大成员长度的整数倍。
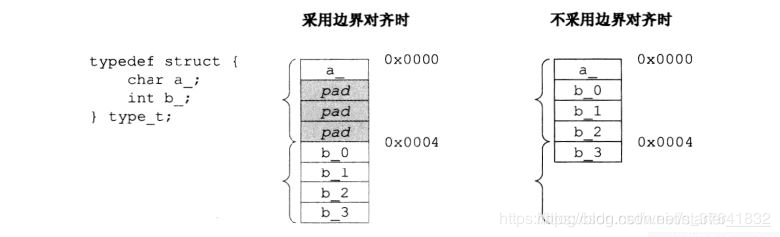
从处理器的角度来看,需要尽可能减少对内存的访问次数以实现对数据结构进行更加高效的操作。为什么呢?因为尽管处理器包含了缓存,但它在处理数据时还得读取缓存中的数据,读取缓存的次数当然是越少越好!
如上图所示,在采用边界对齐的情况下,当处理器需要访问 a_ 变量和 b_ 变量时都只需进行一次存取(图中花括号表示一次存取操作)。若不采用边界对齐,a_ 变量只要一次处理器操作,而 b_ 变量却至少要进行两次操作。对于 b_,处理器还得调用更多指令将其合成一个完整的 4 字节,这样无疑大大降低了程序效率。

















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









