




 本文介绍了K近邻(K Nearest Neighbors)模型在回归任务中的应用,通过数学表达式和示例说明了K近邻模型如何利用最近邻的实例进行预测。讨论了K值的选择对模型稳定性的影响,并对比了K近邻模型在不同输入空间中的表现,指出在高维度输入空间中可能存在的问题。同时,文章还简要提到了K近邻模型在分类问题上的运用。
本文介绍了K近邻(K Nearest Neighbors)模型在回归任务中的应用,通过数学表达式和示例说明了K近邻模型如何利用最近邻的实例进行预测。讨论了K值的选择对模型稳定性的影响,并对比了K近邻模型在不同输入空间中的表现,指出在高维度输入空间中可能存在的问题。同时,文章还简要提到了K近邻模型在分类问题上的运用。
2.4 K近邻模型
设某回归任务的输入包含两个变量,将它们的值视为平面上点的坐标。如图2.1所示,灰点代表训练数据中的输入,白点代表输出待预测的输入。假如采用2.3节介绍的平均值法,当白点与黑点重合时,因为在该处只有一个训练实例,所以平均值不能很好地代表期望值;而当白点处于更有可能的其他位置时,因为在该处没有训练实例,无法预测输出值。为走出此困境,自然的想法是,在计算平均值时,扩大取其输出的实例的范围。假设输出待预测的输入为x,原来要求找到训练数据中输入等于x的实例,现在则放宽到所有输入处于x的某邻域的实例。在图2.1中,以白点为中心所画的圆就代表一个这样的区域,在该区域内,可用于为白点取平均值的灰点有8个。
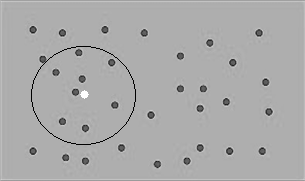
图2.1 某个输入邻近区域内的实例
用数学语言表达,就是用以下函数![]() 作为
作为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









