



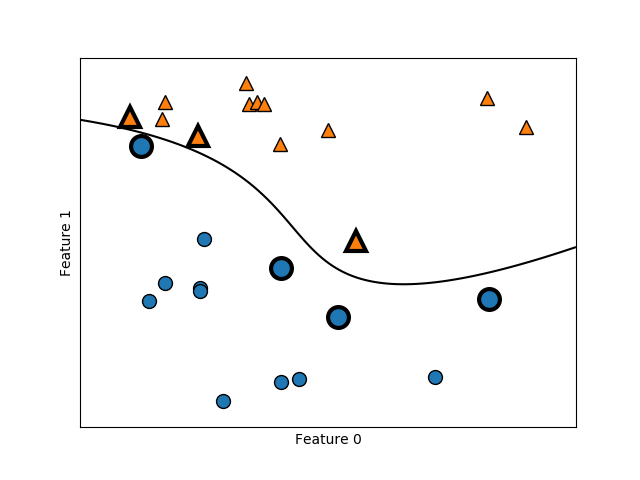
 本文通过使用Python的scikit-learn库中的SVM(支持向量机)分类器,对人工创建的数据集进行分类。展示了如何训练模型,绘制决策边界,并突出显示支持向量。同时,解释了支持向量的类别标签由双系数的符号决定。
本文通过使用Python的scikit-learn库中的SVM(支持向量机)分类器,对人工创建的数据集进行分类。展示了如何训练模型,绘制决策边界,并突出显示支持向量。同时,解释了支持向量的类别标签由双系数的符号决定。
import graphviz import mglearn from mpl_toolkits.mplot3d import Axes3D from sklearn.datasets import load_breast_cancer, make_blobs from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier, export_graphviz from IPython.display import display import matplotlib.pyplot as plt import numpy as np import matplotlib as mt import pandas as pd X, y = mglearn.tools.make_handcrafted_dataset() svm = SVC(kernel='rbf', C=100, gamma=0.1).fit(X, y) mglearn.plots.plot_2d_separator(svm, X, eps=.5) mglearn.discrete_scatter(X[:, 0], X[:, 1], y) # plot support vectors sv = svm.support_vectors_ print(sv) # class labels of support vectors are given by the sign of the dual coefficients sv_labels = svm.dual_coef_.ravel() > 0 mglearn.discrete_scatter(sv[:, 0], sv[:, 1], sv_labels, s=15, markeredgewidth=3) plt.xlabel("Feature 0") plt.ylabel("Feature 1") plt.show()


















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









