






注意力机制是深度学习中的一项关键技术,广泛应用于自然语言处理、计算机视觉等多个领域。它通过动态分配权重,使得模型能够聚焦于输入数据中最重要的部分,从而提高模型的性能和可解释性。
一、注意力机制
注意力机制的主要思想是:通过输入或输出,是否可以获得一些信息,这些信息帮助我们确定哪些部分的输入更为重要。通过动态地分配权重,模型能够更有效地捕捉输入数据中的关键信息,从而提高预测的准确性和模型的性能。
为了更好地理解注意力机制的工作原理,我们可以通过一个简单的例子来说明。假设又一个数据集如下图所示,其中橙色点表示已有的数据点,蓝色曲线表示我们想要预测的真实值。
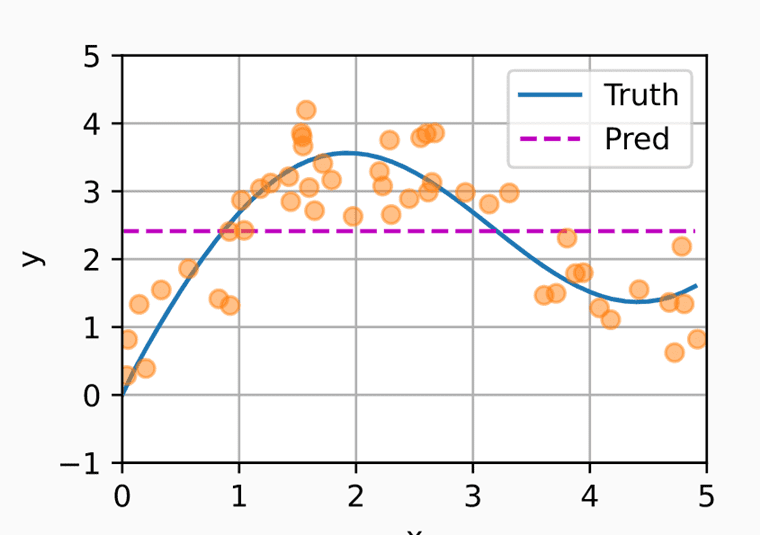
如果使用样本y的均值作为预测值,那么预测结果将是一条紫色虚线。显然,这种预测方法的效果非常差,它忽略了每个数据点的实际值以及它们在曲线中的位置,即每个数据点的重要性。
二、没有参数的注意力池化Attention Pooling

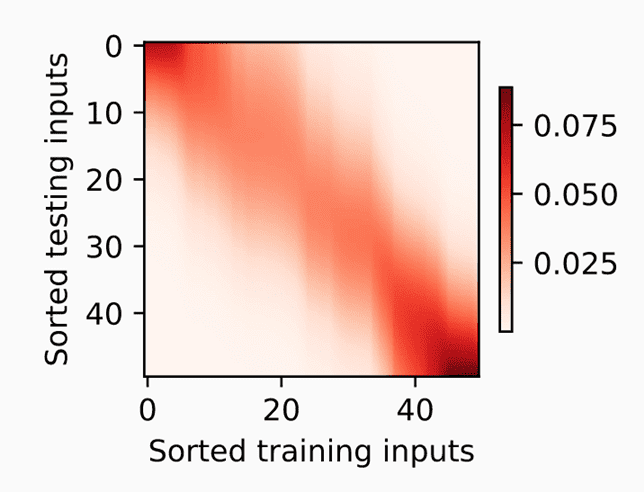
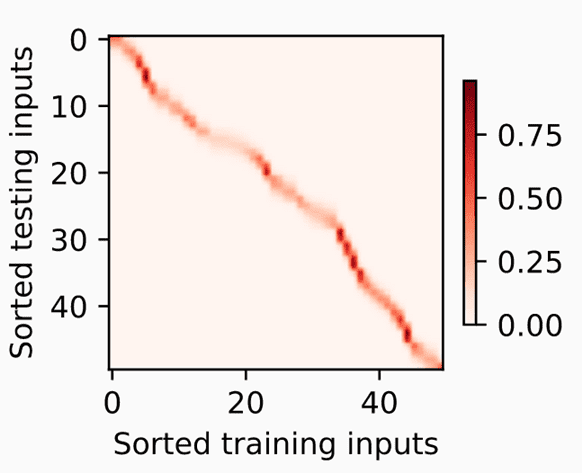
下图展示了输入x和训练集之间的关系。
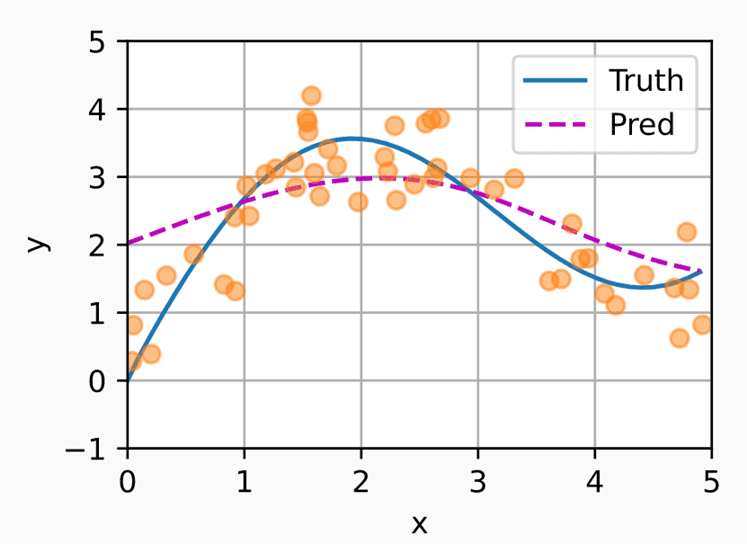
通过x(Query)和(Key) 计算对应的权重。然后取的和作为我们的预测值。这种注意力机制一定程度上改善了我们的预测水平。
三、有参数的注意力池化

在训练之后,效果比无参数的注意力池化更明显了,不过在这个例子中有些过拟合。
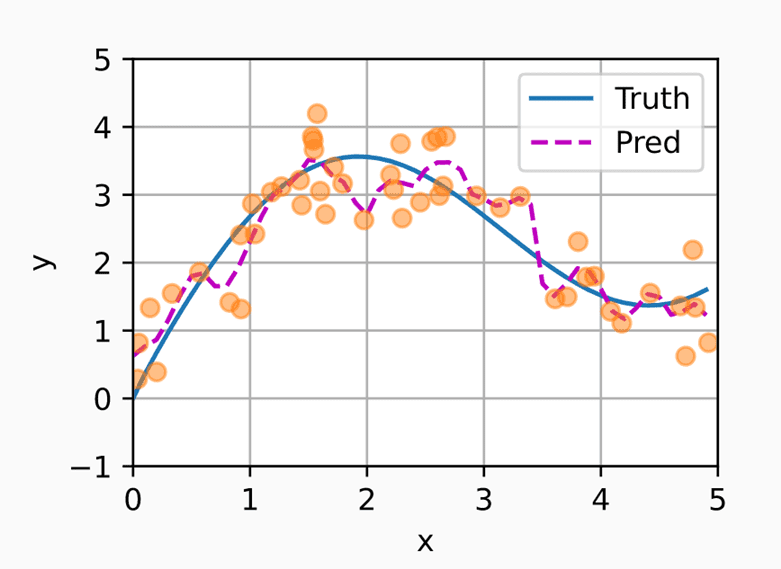
可以看到,还有一个新的观察角度。我们的注意力更集中了。
从上面两个例子可以看出:
-
注意力池化可以是有参数或无参数的。
-
在注意力池化中,每个 Value 都会被分配一个权重。
四、注意力评分方程

「点积注意力(Dot-Product Attention)」

以下是一个简单的Python示例,展示如何实现 Scaled Dot-Product Attention:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行 softmax 操作"""
if valid_lens isNone:
return F.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其 softmax 输出为 0
X = sequence_mask(X, valid_lens, value=-1e6)
「加性注意力(Additive Attention)」

以下是一个简单的Python示例,展示如何实现加性注意力机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
class AdditiveAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
# 下面一步将 Q 和 K 分别对独自的 W 进行线性变换
queries, keys = self.W_q(queries), self.W_k(keys)
# 输出的:queries[batch_size, num_queries, num_hiddens]
# 输出的:keys[batch_size, num_keys, num_hiddens]
features = queries.unsqueeze(2) + keys.unsqueeze(1)
# broadcasting 相加,features[batch_size, num_queries, num_keys, num_hiddens]
features = torch.tanh(features)
scores = self.w_v(features).squeeze(-1)
# scores[batch_size, num_queries, num_keys]
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
# value 的长度和 key 的长度是一样的。
Masked Softmax
我们通常会将句子进行 padding,填充以使每个 batch 中的句子长度相同,提升训练速度,因此需要将被填充的部分进行掩盖。
一个 mask 的方式就是将需要掩盖的部分加上一个非常小的值(如(-1e6 )),这样 softmax 之后这些部分的权重几乎为零。例如,针对 tensor([10, 10, 2, 2]),其中 2 为 padding_token,进行掩码时加上,那么 softmax 之后就可以得到 tensor([0.5, 0.5, 0, 0])。
当然,掩码还有其他的用途,如在 Transformer 中使用掩码来将注意力锁定在目标前方序列中。
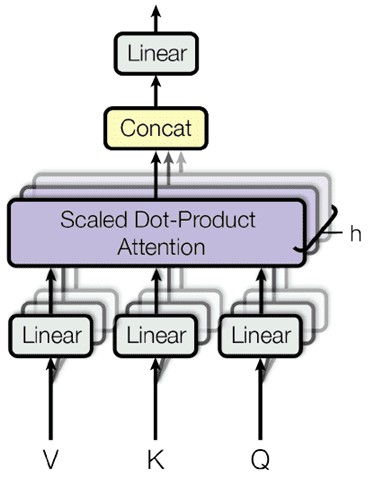
五、Multi-Head Attention
多头注意力最出名的便是Transformer了,对于 Transformer,后文也有解析。多头注意力的基本思想是:我们从h个不同的角度来观察Q,K,V。观察的角度越多,获得的信息也就更全面,最后我们再把获得的全部信息拼接起来。
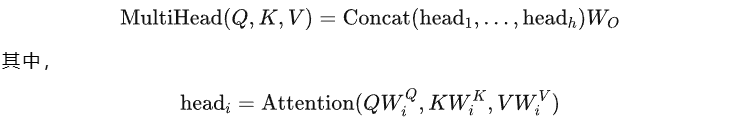
要从h个角度观察一个张量,即对张量做h次不同的映射。之后将h个注意力权重拼接得到最终注意力权重如下图:
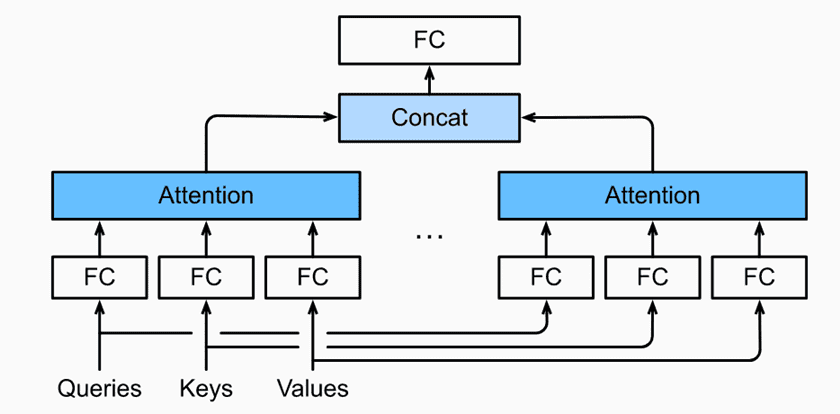
从以下代码可以看出,Q,K,V 三个张量在变化成多头前分别进行了矩阵映射。并且再映射后进行了掩码,valid_lens 就是mask。
#@save
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# Q,K,V [batch_size, len_seq, len_paris, d_model]
# valid_lens [batch_size,] or [batch_size, no. of queries]
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
# QKV [batch_size*num_head, len_sqe, d_model/num_head]
if valid_lens isnotNone:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries, keys, values, valid_lens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat) # [batch_size, len_seq, d_model]
案例1:机械翻译
在自然语言处理中,神经机器翻译(Neural Machine Translation, NMT)是一种基于神经网络的翻译方法。传统的基于 RNN 的 seq2seq 模型在处理长句子时存在信息瓶颈问题,即编码器生成的隐藏状态(hidden state)可能无法充分捕捉到输入序列中的所有信息,导致解码器在生成较长的输出序列时表现不佳。注意力机制(Attention Mechanism)可以有效解决这个问题。
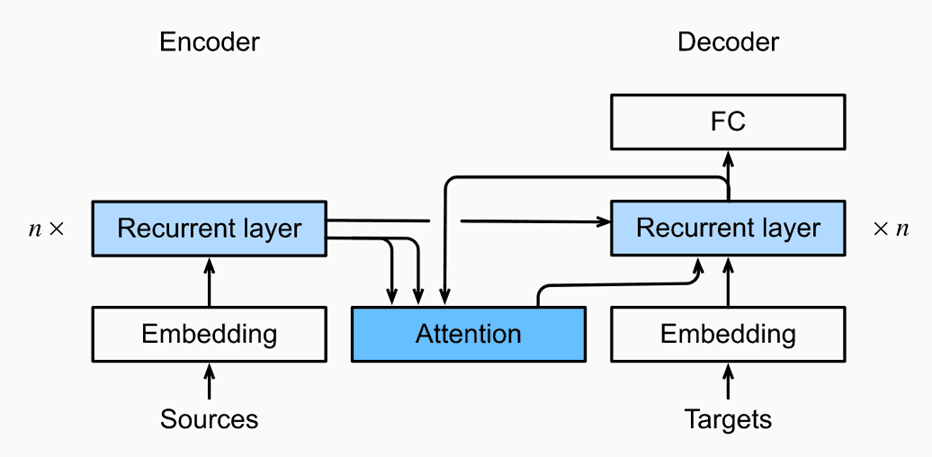
「机械翻译中的注意力机制」
在机械翻译过程中,注意力机制使得解码器能够动态地关注编码器输出的不同部分,从而更好地捕捉输入句子中的信息。具体来说,当解码器生成输出序列中的每个字符时,它会使用当前字符的隐藏状态(hidden state)作为 Query,与编码器输出的所有隐藏状态(Keys 和 Values)进行注意力计算,从而得到一个加权和的上下文向量(Context Vector)。这个上下文向量包含了输入句子中与当前输出字符相关的重要信息。
「动手深度学习案例:」
在动手深度学习中的案例中,注意力机制被巧妙地应用在编码器和解码器之间,以解决传统基于 RNN 的 seq2seq 模型在处理长句子时存在的信息瓶颈问题。具体来说,注意力机制使得解码器能够动态地关注编码器输出的不同部分,从而更好地捕捉输入句子中的信息。以下是详细的解释和代码分析:
-
编码器:
- 编码器将输入句子编码成一系列隐藏状态(hidden states)。
- 每个隐藏状态对应输入句子中的一个单词。
- 编码器通常使用 RNN(如 GRU 或 LSTM)来生成这些隐藏状态。
-
解码器
- 解码器在生成输出序列中的每个字符时,使用当前字符的隐藏状态(hidden state)作为 Query。
- 解码器通过注意力机制计算 Query 与编码器所有隐藏状态的相似性分数。
- 根据相似性分数,计算加权和得到上下文向量(Context Vector)。
- 将上下文向量与当前字符的嵌入向量(Embedding Vector)拼接,作为解码器RNN的输入。
- 解码器RNN生成当前字符的隐藏状态,并通过全连接层(Dense Layer)预测下一个字符。
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):# num_hiddens 通常也就是我们词向量的维度了
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens,
num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# Shape of `outputs`: (`num_steps`, `batch_size`, `num_hiddens`).
# Shape of `hidden_state[0]`: (`num_layers`, `batch_size`,
# `num_hiddens`)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# Shape of `enc_outputs`: (`batch_size`, `num_steps`, `num_hiddens`).
# Shape of `hidden_state[0]`: (`num_layers`, `batch_size`,
# `num_hiddens`)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output `X`: (`num_steps`, `batch_size`, `embed_size`)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# Shape of `query`: (`batch_size`, 1, `num_hiddens`)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# Shape of `context`: (`batch_size`, 1, `num_hiddens`)
context = self.attention(query, enc_outputs, enc_outputs,
enc_valid_lens)
# Concatenate on the feature dimension
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# Reshape `x` as (1, `batch_size`, `embed_size` + `num_hiddens`)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [
enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
「数据处理」
在机械翻译任务中,输入句子的长度通常是不固定的。为了进行批量训练,通常会使用以下方法:
Padding:
- 将句子填充到相同的长度,使得每个 batch 中的句子长度相同。
- 使用 padding token(如)填充较短的句子。
Bucketing:
- 将句子按照长度排序。
- 将长度相似的句子分到同一个 batch 中。
- 这样可以减少 padding 的数量,提高训练效率。
「Bucketing操作步骤」
- 排序:首先将所有句子按照长度进行排序。这有助于将长度相似的句子放在一起,减少 padding 的数量。
- 填充:将长度较短的句子填充到与最长句子相同的长度。填充时使用 padding token(如)。
- 分批:将填充后的句子分到同一个 batch 中,这样可以确保每个 batch 中的句子长度相同,便于进行批量训练。
「示例」
假设我们有以下句子:
- 句子1: “hello world”
- 句子2: “good morning”
- 句子3: “how are you”
- 句子4: “I am fine thank you”
排序:
- 按照句子长度排序:
- 句子1: “hello world” (2 个词)
- 句子2: “good morning” (2 个词)
- 句子3: “how are you” (3 个词)
- 句子4: “I am fine thank you” (5 个词)
填充:
- 句子1: “hello world”
- 句子2: “good morning”
- 句子3: “how are you”
- 句子4: “I am fine thank you”
- 将句子填充到与最长句子相同的长度(5 个词):
分批:
-
Batch 1: [“hello world”, “good morning”]
-
Batch 2: [“how are you”, “I am fine thank you”]
-
将填充后的句子分到同一个 batch 中:
通过 bucketing,可以减少每个batch中的padding数量,提高训练效率。
「Teacher forcing」
Teacher forcing 是一种训练技巧,通过在训练过程中使用真实的前一个字符作为解码器的输入,而不是使用解码器预测的字符。这样可以加速训练过程,提高模型的性能。随着训练的进行,可以逐渐减少 teacher forcing 的比率,使得模型逐渐适应使用自己预测的字符作为输入。
案例 2: Transformers
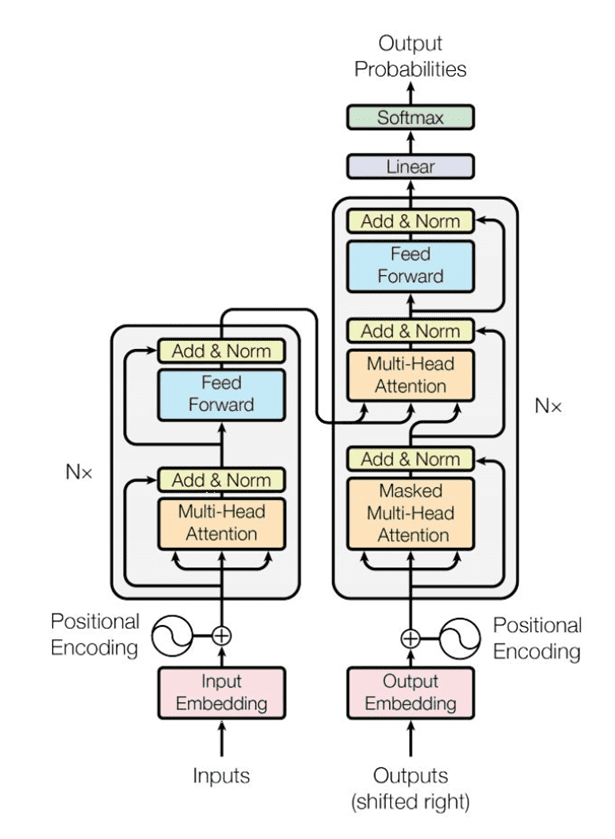
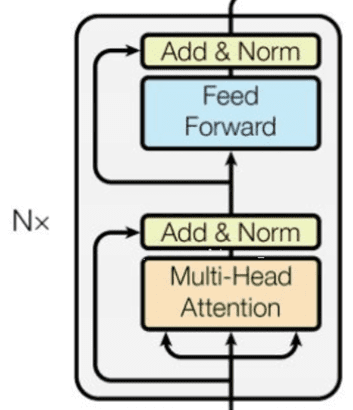
Transformer模型分为编码器(Encoder)和解码器(Decoder)两大部分。编码器和解码器都由多个相同的层堆叠而成,每个层包含自注意力机制、多头注意力机制和前馈神经网络(Feed-Forward Neural Network)。此外,每个子层的输出都会通过残差连接(Residual Connections)和层归一化(Layer Normalization)来增强模型的稳定性和训练效果。
位置编码(Positional Encoding)
位置编码,即给词向量添加上这个词在句中位置的信息:

代码实现:
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: torch.Tensor):
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])
位置编码的性质:
- 线性变换: 任意两个单词的位置编码信息可以通过线性变换得到。
- 相离很远的词也可以产生反映:
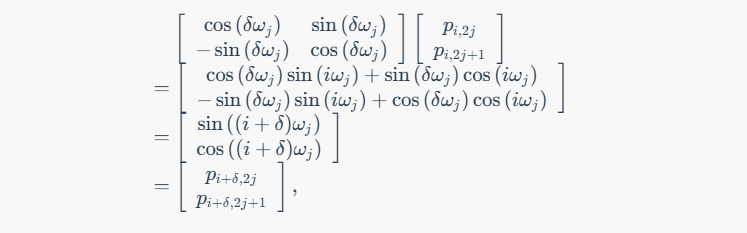
Scaled Dot-Product Attention
Scaled Dot-Product Attention 是 Transformer 中最基础的注意力机制。公式如下:
其中,Q、K 和 V 分别代表 Query、Key 和 Value,d_k 是 Key 向量的维度大小。
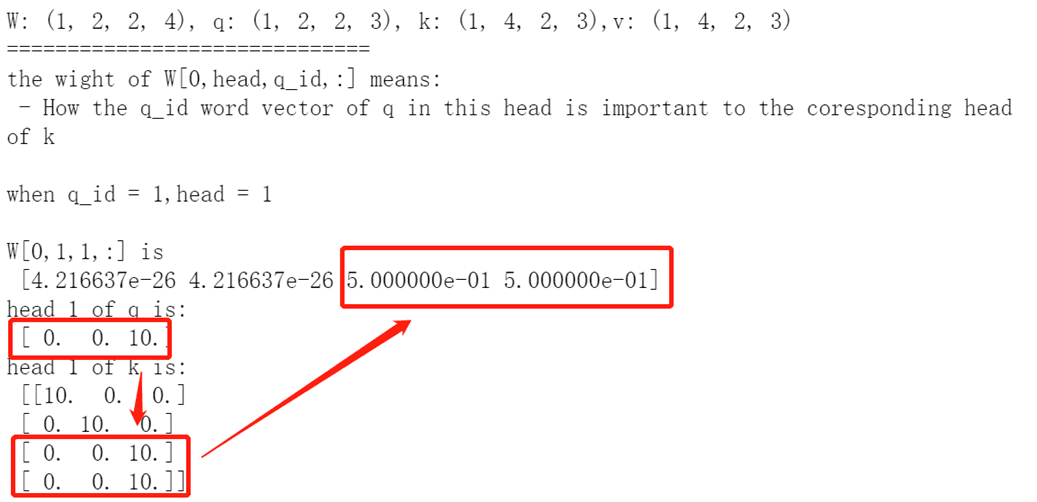
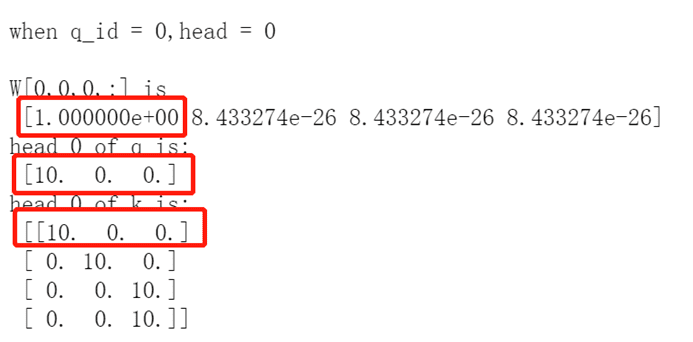
下面是一个小小的测试,可以看出,当向量之间相似度越大,他们之间的注意力权重也就越大。
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
其中,
- 归一化: 通过对点积结果进行缩放(除以 sqrt(d_k)),可以避免梯度消失问题。
- 余弦相似度:由于输入和输出通常已经做过层归一化(Layer Normalization),点积注意力相当于余弦相似度。
Multi-Head Attention
多头注意力机制通过从多个不同的角度观察输入序列,从而捕捉到更丰富的信息。
公式如下:
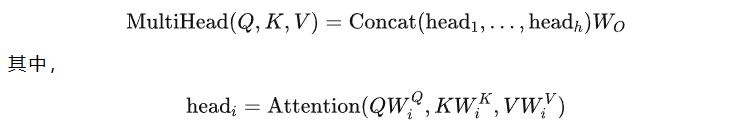
代码实现:
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# Q,K,V [batch_size, len_seq, len_paris, d_model]
# valid_lens [batch_size,] or [batch_size, no. of queries]
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
# QKV [batch_size*num_head, len_sqe, d_model/num_head]
if valid_lens isnotNone:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries, keys, values, valid_lens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat) # [batch_size, len_seq, d_model]
前馈神经网络(Feed-Forward Neural Network)
前馈神经网络是一个简单的两层线性变换,中间使用 ReLU 激活函数。公式如下:
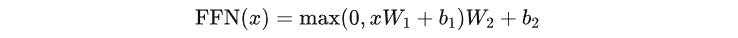
代码实现:
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
参数设置:
- ffn_num_input:输入维度。
- ffn_num_hiddens:隐藏层维度(通常设置为 2048)。
- ffn_num_outputs:输出维度(与输入维度相同)。
正则化(Regularization)
Transformer 模型中使用了两种正则化技术:
- Dropout: 在每个子层的输出后,再加之前,添加了一个 0.1 的 dropout。
- Layer Normalization: 在每个子层的输入前进行层归一化。
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y): # X 为每个 sub-layer 的输出
return self.ln(self.dropout(Y) + X)
其中,
- 残差连接: 残差连接有助于梯度的传播,提高模型的训练稳定性。
- 层归一化: 层归一化可以加速训练过程,提高模型的性能。
编码器层(Encoder Layer)
编码器层由多头注意力机制和前馈神经网络组成。每个子层的输出都会通过残差连接和层归一化来增强模型的稳定性和训练效果。
class EncoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout, use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y)) # [batch_size, len_seq, d_model]
-
自注意力机制: 编码器层使用自注意力机制来捕捉输入序列中的依赖关系。
-
前馈神经网络: 通过前馈神经网络捕捉局部特征。
解码器层(Decoder Layer)
解码器层与编码器层类似,但包含一个额外的多头注意力机制,用于将解码器的输出与编码器的输出进行注意力计算。此外,解码器层中的自注意力机制使用了掩码,使得一个单词只能注意到前面的单词。
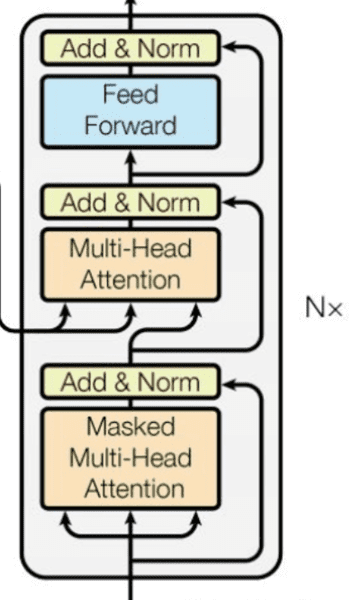
class DecoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# During training, all the tokens of any output sequence are processed
# at the same time, so `state[2][self.i]` is `None` as initialized.
# When decoding any output sequence token by token during prediction,
# `state[2][self.i]` contains representations of the decoded output at
# the `i`-th block up to the current time step
if state[2][self.i] isNone:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# Shape of `dec_valid_lens`: (`batch_size`, `num_steps`), where
# every row is [1, 2, ..., `num_steps`]
dec_valid_lens = torch.arange(1, num_steps + 1,
device=X.device).repeat(
batch_size, 1)
else:
dec_valid_lens = None# 非训练的时候,input 都是一个一个放进来的,不需要掩码。
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# Y (`batch_size`, `num_steps`, `num_hiddens`)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
# 第二层用的 K 和 V 都是 encoder 的 output。
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
-
自注意力机制: 解码器层使用自注意力机制来捕捉输出序列中的依赖关系,并使用掩码确保一个单词只能注意到前面的单词。
-
编码器-解码器注意力机制: 解码器层中的第二个多头注意力机制将解码器的输出与编码器的输出进行注意力计算,从而捕捉输入序列中的信息。
编码器(Encoder)
编码器由词嵌入(Embedding)和位置编码(Positional Encoding)组成,之后注入到由多个编码器层堆叠而成的序列中。
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(
"block" + str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
解码器(Decoder)
解码器负责生成输出序列。解码器由多个解码器层堆叠而成,每个解码器层包含两个多头注意力机制和一个前馈神经网络。第一个多头注意力机制用于自注意力(self-attention),第二个多头注意力机制用于将解码器的输出与编码器的输出进行注意力计算。
import torch
import torch.nn as nn
import math
class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(
"block" + str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
# state[0]:编码层输出
# state[1]: 编码层输出对应的掩码
# state[2]:上一个 decoder block 的输入
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# Decoder self-attention weights
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# Encoder-decoder attention weights
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
优化器(Optimizer)
在训练 Transformer 模型时,选择合适的优化器和学习率调度策略对于模型的性能至关重要。这里使用Adam 优化器,学习率调度方案如下:

「代码实现」
以下是一个简单的示例代码,展示如何在 PyTorch 中实现上述学习率调度方案:
import torch
import torch.optim as optim
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step isNone:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
# 示例使用
model_size = 512
factor = 1
warmup = 4000
optimizer = optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)
scheduler = NoamOpt(model_size, factor, warmup, optimizer)
for step in range(1, 10001):
scheduler.step()
print(f'Step {step}, Learning Rate: {scheduler.rate()}')
训练和测试
训练时的步骤:
- 编码器:
- 将原句子输入编码器,输出编码器的隐藏状态 enc_outputs。
- 解码器:
- 将目标语句右移一位,并在开头加上句子开头编码。
- 将调整后的目标语句输入解码器,同时进行训练。
- 在解码器的输出后加上一个线性层和一个 softmax 层,计算 cross entropy loss。
- 进行梯度下降,更新模型参数。
测试时的步骤:
- 编码器:
- 将原句子输入编码器,输出编码器的隐藏状态 enc_outputs。
- 解码器:
- 解码器一开始使用作为输入。
- 一个单词输入,通过解码器会得到一个单词输出。
- 多次执行解码器直到,生成一个完整的句子。
- 测试时不需要对解码器的注意力层进行注意力掩码。
「示例代码」
以下是一个简单的示例代码,展示如何使用 Transformer 编解码器进行训练和测试:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们已经定义了 TransformerEncoder 和 TransformerDecoder
# encoder = TransformerEncoder(...)
# decoder = TransformerDecoder(...)
# 示例数据
src = torch.randint(0, 10, (10, 2)) # 源句子,形状 [src_len, batch_size]
tgt = torch.randint(0, 10, (15, 2)) # 目标句子,形状 [tgt_len, batch_size]
# 初始化编码器和解码器
vocab_size = 10
key_size = 256
query_size = 256
value_size = 256
num_hiddens = 256
norm_shape = [256]
ffn_num_input = 256
ffn_num_hiddens = 512
num_heads = 8
num_layers = 6
dropout = 0.1
encoder = TransformerEncoder(vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout)
decoder = TransformerDecoder(vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout)
# 初始化编码器和解码器的状态
enc_outputs = encoder(src, None)
state = decoder.init_state(enc_outputs, None)
# 训练循环
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略 padding token
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=0.001)
for epoch in range(10):
optimizer.zero_grad()
dec_input = tgt[:-1] # 目标句子右移一位
dec_output, _ = decoder(dec_input, state)
output_dim = dec_output.shape[-1]
dec_output = dec_output.reshape(-1, output_dim) # 展平输出
tgt = tgt[1:].reshape(-1) # 展平目标
loss = criterion(dec_output, tgt)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
# 测试循环
encoder.eval()
decoder.eval()
with torch.no_grad():
enc_outputs = encoder(src, None)
state = decoder.init_state(enc_outputs, None)
dec_input = torch.tensor([[1]]) # <BOS>
dec_output, _ = decoder(dec_input, state)
output_dim = dec_output.shape[-1]
dec_output = dec_output.reshape(-1, output_dim) # 展平输出
pred = dec_output.argmax(1)
print(pred)
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









