import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)print(s)
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])print(s)
从字典创建一个系列
#默认用键作为索引,当然也是可以指定的
data ={'a':0.,'b':1.,'c':2.}
s = pd.Series(data)print(s)
从列表创建一个系列
s = pd.Series([1,2,3,4,5],index =['a','b','c','d','e'])print(s)
从标量创建一个系列
s = pd.Series(5, index=[0,1,2,3])print(s)
系列数据的访问
通过索引访问:就跟数组一样,还支持切片
import pandas as pd
s = pd.Series([1,2,3,4,5],index =['a','b','c','d','e'])print s[0]print s[:3]#切片
通过标签检索:有点像字典
import pandas as pd
s = pd.Series([1,2,3,4,5],index =['a','b','c','d','e'])print s['a']print s[['a','c','d']]#检索多个
describe(include='all')函数是用来计算有关DataFrame列的统计信息的摘要,其中的 include 参数可以取值:
object - 汇总字符串列
number - 汇总数字列
all - 将所有列汇总在一起(不应将其作为列表值传递)
import pandas as pd
#Create a Dictionary of series
d ={'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack','Lee','David','Gasper','Betina','Andres']),'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}#Create a DataFrame
df = pd.DataFrame(d)
df.describe()
3、函数应用
表合理函数应用:pipe
import pandas as pd
import numpy as np
defadder(ele1,ele2):return ele1+ele2
df = pd.DataFrame(np.random.randint(1,10,size=(5,3)),columns=['col1','col2','col3'])
df = df.pipe(adder,100)
df
行或列函数应用:apply
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(1,10,size=(5,3)),columns=['col1','col2','col3'])
df = df.apply(lambda x: x.max()- x.min(),axis=1)
df
元素函数应用:applymap
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(1,10,size=(5,3)),columns=['col1','col2','col3'])#针对表格所有元素
df= df.applymap(lambda x:x*100)print(df)#只针对某一列
df= df['col1'].map(lambda x:x*100)print(df)
4、重建索引
重建索引有很多用途:
通过重建索引来重构表格
import pandas as pd
import numpy as np
N=20
df = pd.DataFrame({'A': pd.date_range(start='2016-01-01',periods=N,freq='D'),'x': np.linspace(0,stop=N-1,num=N),'y': np.random.rand(N),'C': np.random.choice(['Low','Medium','High'],N).tolist(),'D': np.random.normal(100,10, size=(N)).tolist()})#reindex the DataFrame
df_reindexed = df.reindex(index=[0,2,5], columns=['A','C','B'])print(df_reindexed)
重建索引与其他对象对齐
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3'])
df2 = pd.DataFrame(np.random.randn(7,3),columns=['col1','col2','col3'])
df1 = df1.reindex_like(df2)print(df1)
重建索引时的填充
reindex 是一个填充方法,可选参数如下:
pad/ffill - 向前填充值
bfill/backfill - 向后填充值
nearest - 从最近的索引值填充
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(6,3),columns=['col1','col2','col3'])
df2 = pd.DataFrame(np.random.randn(2,3),columns=['col1','col2','col3'])# 默认用NAN填充所有print df2.reindex_like(df1)# 用前面的最后数据只填充一行print("--------------------------------------")print df2.reindex_like(df1,method='ffill',limit=1)
重命名行列标签
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(6,3),columns=['col1','col2','col3'])print(df1)print("------------------------------------")print(df1.rename(columns={'col1':'c1','col2':'c2'},index ={0:'apple',1:'banana',2:'durian'}))
三、pandas 迭代和排序
1、迭代:iteritems、iterrows、itertuples
按列迭代
import pandas as pd
import numpy as np
N=20
df = pd.DataFrame({'A': pd.date_range(start='2016-01-01',periods=N,freq='D'),'x': np.linspace(0,stop=N-1,num=N),'y': np.random.rand(N),'C': np.random.choice(['Low','Medium','High'],N).tolist(),'D': np.random.normal(100,10, size=(N)).tolist()})# 默认是遍历列名for col in df:print(col)
df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3'])print(df)print("--------------------")for key,value in df.iteritems():print(key,value)print("-----")
按行迭代
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,3),columns =['col1','col2','col3'])print(df)print("-------------------------")for row_index,row in df.iterrows():print(rowindex,row)print("---------")#每一行返回一个产生一个命名元组的迭代器
df = pd.DataFrame(np.random.randn(4,3),columns =['col1','col2','col3'])for row in df.itertuples():print(row)
2、排序
按标签排序:sort_index
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],columns =['col2','col1'])print(unsorted_df)print("-------------------------")
sorted_df=unsorted_df.sort_index(ascending=True)# ascending 指定升序排列print(sorted_df)
按列排列:sort_index
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],columns =['col2','col1'])print(unsorted_df)
sorted_df=unsorted_df.sort_index(axis=1)#默认是0,就是根据行标签排序print(sorted_df)
按值排序:sort_values
其中 kind 指定的是算法,本来有三个可选的值,但是 mergesort 是比较稳定的算法
先根据 col1 排序,再根据 col2 排序
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame({'col1':[2,1,1,1],'col2':[1,3,2,4]})print(unsorted_df)
sorted_df = unsorted_df.sort_values(by=['col1','col2'],kind='mergesort')print(sorted_df)
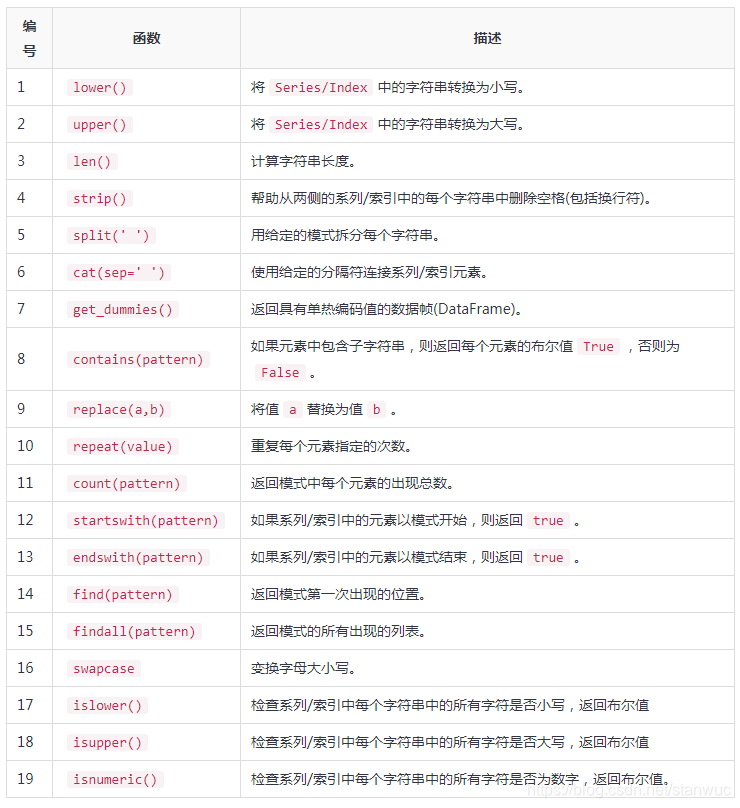
四、字符串操作 | 选项设置 | 索引访问数据
1、字符串操作
操作示例
s = pd.Series(['Tom','William Rick','John','Alber@t', np.nan,'1234','SteveMinsu'])print(s.str.lower())





 本文深入讲解Pandas库的三种核心数据结构:Series、DataFrame和Panel的创建与操作方法,涵盖描述性统计、函数应用、索引重建及迭代排序等功能,适合希望提升数据处理技能的开发者。
本文深入讲解Pandas库的三种核心数据结构:Series、DataFrame和Panel的创建与操作方法,涵盖描述性统计、函数应用、索引重建及迭代排序等功能,适合希望提升数据处理技能的开发者。

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









