







CVPR2019 All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation 所有关于结构:适应结构信息跨领域促进语义分割
0.摘要
在本文中,我们解决了用于语义分割任务的无监督域适应问题,我们试图在没有任何注释的情况下,将在带有地面真实标签的合成数据集上学习到的知识转移到真实世界的图像。与假设图像是最丰富的结构内容和决定性因素语义分割,能够很容易地跨域共享,我们提出一个域不变结构提取(DISE)框架解决图像域不变结构和特定于域的纹理表示,进一步实现了图像的跨域翻译和标签转移,提高了分割性能。大量的实验验证了我们提出的dis模型的有效性,并证明了其优于几种最先进的方法。
1.概述
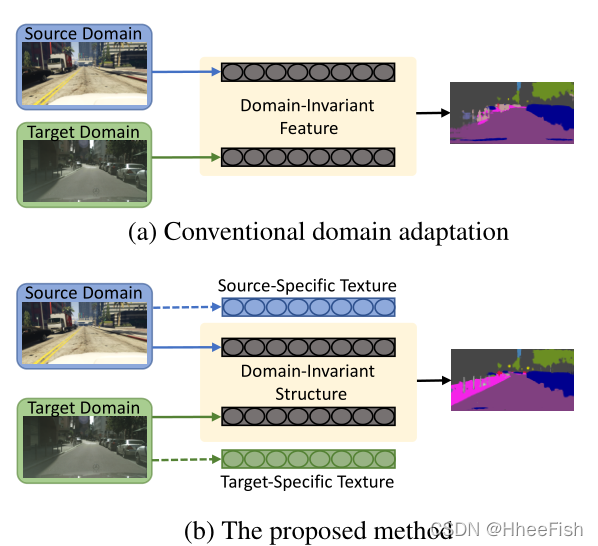
图1所示。比较传统的领域适应的语义分割和我们提出的方法。而不是使整个特征表示域不变,我们只对齐结构组件的分布跨域
语义分割是预测图像的像素级语义标签。它被认为是计算机视觉中最具挑战性的任务之一。由于近年来深度学习的复兴,我们看到了这一任务的巨大飞跃。全卷积网络(FCN)建立在预先训练的分类模型(如VGG[21]和ResNet[7])和反卷积层的基础上,自其诞生以来,人们提出了许多技术来推进语义分割,如扩大接受域[2,27]和更好地保存上下文信息[28],举几个例子。然而,这些方法很大程度上依赖于监督学习,因此需要昂贵的像素级注释。为了解决这个问题,一种解决方案是在合成数据上训练分割模型。当今的计算机图形技术能够合成高质量、逼真的虚拟场景图像。因此,可以基于这些合成图像建立一个有监督的语义分割数据集(例如GTA5[17]和SYNTHIA[18])。在渲染过程中,它们的像素级语义标签随时可用。然而,在合成数据集上训练的分割模型往往难以在真实世界场景中获得令人满意的性能,这是由于一种被称为领域转移的现象——即,合成图像和真实图像在低级纹理外观上仍然可以显示出相当大的差异。
因此,领域适应被提出,将知识从一个源领域(如合成图像)转移到另一个目标领域(如真实图像)。一种常见的方法是通过匹配其特征分布来学习跨域的域不变特征空间,其中已经探索了不同的匹配标准,例如最小化二阶统计量[23]和域对抗训练[6,8,25]。最近还有一项研究[24],直接在结构输出空间中引入分布对齐来完成语义分割任务。然而,这些方法都是由一个强烈的假设驱动的,即两个域的整个特征或输出空间可以很好地对齐(参见图1 (a)),从而产生一个对所讨论的任务也具有区别性的域不变表示。
在本文中,我们提出了一个领域不变结构抽取(DISE)框架,以解决无监督的领域适应语义分割。我们假设图像的高级结构信息将是最有效的分割预测。因此,我们的DISE旨在通过学习将图像的领域不变结构信息与其领域特定纹理信息分离,发现一个领域不变结构特征,如图1 (b)所示。
我们的方法不同于之前类似的工作:
- 学习由明确的领域不变结构组件和领域特定纹理组件组成的图像表示,
- 使结构组件具有领域不变
- 允许跨领域的图像到图像的转换,这进一步允许标签转移,所有这些都在一个框架内实现。尽管DISE与域分离网络[1]和DRIT[13]有一些相似之处,但它强调的是结构和纹理信息的分离,以及跨域翻译图像并同时保持结构的能力,显然突出了它的新奇之处。在标准化数据集上进行的广泛实验证实了其优于几种最先进的基线。
2.相关工作
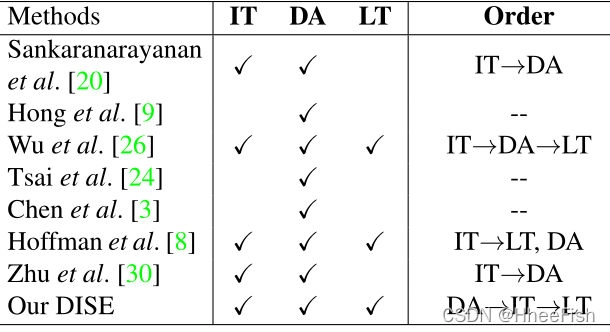
表1。在语义分割领域适应方面,已有研究采用了不同的策略。IT、DA、LT分别代表图像平移、分布对齐和标签传输。顺序表示这些策略应用的顺序。
与已有许多研究领域适应问题的图像分类相比,语义分割被认为是应用领域适应的更具挑战性的任务,因为它的输出是一个分割图,充满了高度结构化和上下文语义信息。我们在这里回顾了一些相关的工作,并根据三种广泛使用的策略进行分类:分布对齐,图像平移和标签转移。不同的作品对这些策略的选择和实施顺序可能有所不同,如表1所示。
首先,与图像分类中的域适应类似,在特征空间(如[9,20,26,30])或输出空间中,可以采用不同的标准来匹配跨域的分布。后者的代表性工作是由Tsai等人[24]提出的,其中对抗学习应用于分割映射,基于源和目标域之间的空间上下文相似性。然而,考虑到在某些应用中,合成图像和真实图像在外观(即纹理)上的实质性差异,假设两个域的整个特征或输出空间可以很好地对齐往往是不切实际的。
其次,最近在图像到图像的平移和风格转移方面的进展[10,12,29]促使源图像平移以获得目标图像的纹理外观,反之亦然。一方面,这种翻译过程允许分割模型使用翻译后的图像作为增强训练数据[8,26];另一方面,在图像平移过程中学习到的共同特征空间有助于学习领域不变的分割模型[20,30]。
最后,图像到图像的转换使标签从源域转移到目标域成为可能,为学习适用于目标域图像的模型提供了额外的监督信号[8,26]。然而,直接的图像转换可能对学习有害,因为有将源特定信息传递到目标域的风险。
我们提出的DISE使用了所有这三种策略,但在几个重要方面与之前的工作有所不同。我们假设图像的高级结构信息对其语义分割来说是最重要的信息。因此,DISE是通过一组公共和私有编码器将图像的高级、领域不变的结构信息与其低级、领域特定的纹理信息分离开来。
3.方法
在本文中,我们提出了一个域不变结构抽取(DISE)框架来解决无监督域适应语义分割的问题。强调明确地规范化公共和私有编码器以捕获结构和纹理信息,以及将图像从一个域转换到另一个域以进行标签传输的能力,突出了我们的方法的新颖之处。下面给出了dis的正式处理。我们首先概述它的框架。接下来,我们将详细介绍所使用的损失函数,然后描述实现细节。
3.1.领域不变的结构提取
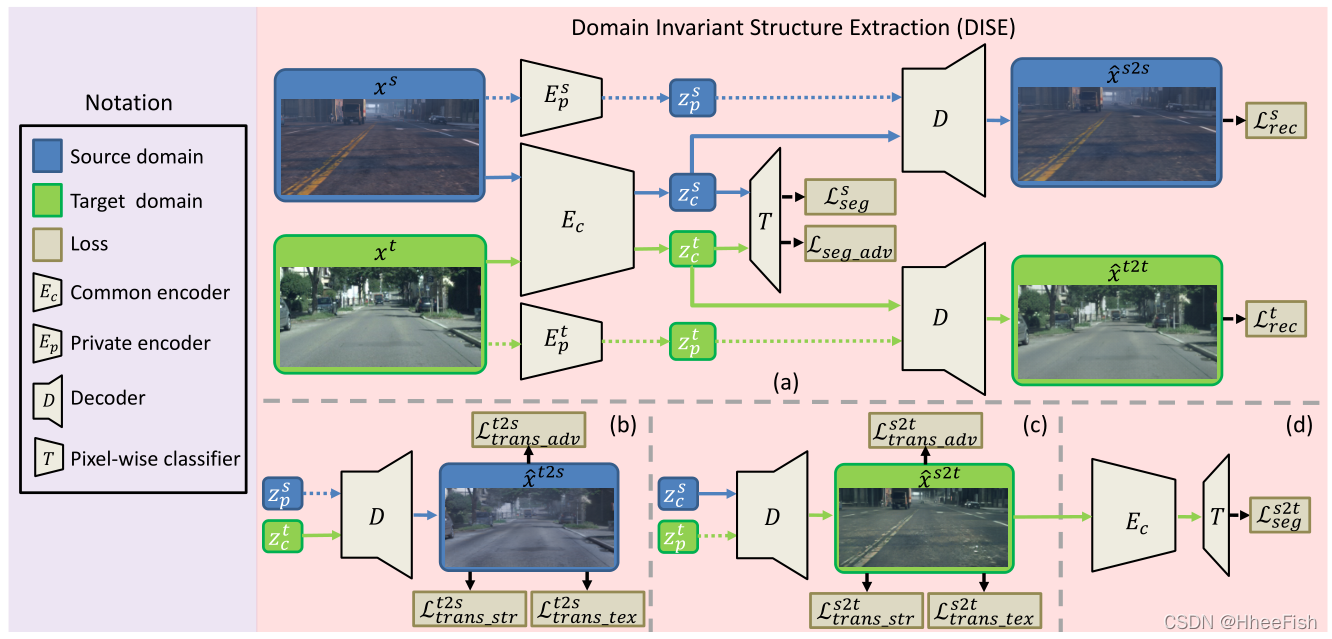
图2。概述了提出的用于语义分割的领域不变结构提取(DISE)框架。DISE框架由跨域共享的公共编码器Ec、两个特定于域的专用编码器Esp、Etp、像素分类器T和共享解码器D组成。它将图像、源域或目标域编码为特定于域的纹理组件zp和域不变结构组件zc,如(a)部分所示。通过这种分离,它可以将一个域中的图像xs(分别为xt)的结构内容与xt(分别为xs)的纹理外观相结合,将一个域中的图像xs(分别为xt)转换为另一个域中的图像xˆs2t(分别为xˆt2s),如(b)和(c)部分所示。这进一步实现了地面真相标签从源域到目标域的传输,如第(d)部分所示
DISE的目的是学习由领域不变结构组件和领域特定纹理组件组成的图像表示。设访问Ns个带注释的源域图像Xs = {(xsi, ysi)}Nsi=1,每个图像xsi∈R^H×W ×3^ 具有对象类别的高H、宽W和C类像素标签 ysi∈{0,1}^H×W ×C^,Nt个未注释的目标图像 Xt = {xti}Nti=1。如图2 (a)所示,在DISE中有五个子网络,即跨域共享的公共编码器Ec、特定域的私有编码器Esp、Etp、共享解码器D和像素分类器T。它们分别由θc、θsp、θtp、θd和θt参数化。
给定一个源域图像xs作为输入,公共编码器Ec产生zsc = Ec(xs;θc)表征其域不变的高级结构信息,而源特定的私有编码器Esp生成zsp &
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









