







 本文深入探讨了Transformer模型在计算机视觉领域的应用,从基础的自注意力机制、监督预训练,到视觉任务中的单头或多头注意力、目标检测与图像分割,以及生成和多模态任务。文章梳理了各种Transformer变体在不同任务中的优缺点,强调了卷积与Transformer的互补性,并对未来研究方向进行了展望。
本文深入探讨了Transformer模型在计算机视觉领域的应用,从基础的自注意力机制、监督预训练,到视觉任务中的单头或多头注意力、目标检测与图像分割,以及生成和多模态任务。文章梳理了各种Transformer变体在不同任务中的优缺点,强调了卷积与Transformer的互补性,并对未来研究方向进行了展望。
Transformers in Vision: A Survey
原论文下载地址:Transformers in Vision: A Survey
0.摘要
本综述旨在提供计算机视觉学科中transformer模型的全面概述。我们首先介绍transformer成功背后的基本概念,即自我注意、大规模的预训练和双向特征编码。然后,我们涵盖了transformer在视觉中的广泛应用,包括流行的识别任务(例如,图像分类,目标检测,动作识别和分割),生成建模,多模态任务(例如,视觉问题回答,视觉推理和视觉基础),视频处理(例如,活动识别,视频预测)、低水平视觉(如图像超分辨率、图像增强和彩色化)和3D分析(如点云分类和分割)。我们比较了流行技术在建筑设计方面的各自优势和局限性以及它们的实验价值。最后,对开放的研究方向和未来可能的工作进行了分析。
1.概述
Transformer模型(Attention is all you need)
语言任务中:文本分类、机器翻译和问答
- BERT(来自transformer的双向编码器表示)(BERT: Pretraining of deep bidirectional transformers for language understanding)
- GPTv1-3(生成预训练transformer)(Improving language understanding by generative pre-training)(Language models are unsupervised multitask learners)(Language models are few-shot learners)
- RoBERTa(Robustly Optimized BERTPre-training)
- T5(Text-to-Text Transfer Transformer)
视觉数据遵循典型的结构(例如,空间和时间一致性),因此需要新颖的网络设计和训练方案。因此,Transformer模型及其变体已成功用于图像识别、目标检测、分割、图像超分辨率、视频理解、图像生成、文本图像合成和视觉问答,以及其他几个用例.
Transformer架构基于一种自我注意机制,该机制学习序列元素之间的关系。与递归处理序列元素且只能处理短期上下文的递归网络不同,转换器可以处理完整序列,从而学习长期关系。尽管注意模型在前馈网络和递归网络( feed-forward and recurrent networks)中都得到了广泛的应用,但Transformer完全基于注意机制,并且有一个独特的实现(即多头注意)为并行化而优化。这些模型的一个重要特征是可扩展到高复杂性模型和大规模数据集。Transformer与其他一些备选方案(如硬注意])相比,硬注意本质上是随机的,需要对注意位置进行蒙特卡罗抽样。由于Transformers与卷积和循环Transformers相比,假定对问题结构的先验知识最少,因此通常使用大规模(未标记)数据集上的前置任务对Transformer进行预训练
pretext tasks 通常被翻译作“前置任务”或“代理任务”, 有时也用“surrogate task”代替。
pretext task 通常是指这样一类任务,该任务不是目标任务,但是通过执行该任务可以有助于模型更好的执行目标任务。其本质可以是一种迁移学习:让网络先在其他任务上训练,使模型学到一定的语义知识,再用模型执行目标任务。这里提到的其他任务就是pretext task。
这样的预训练避免了昂贵的手动注释,因此,编码高度表达和概括的表示,为给定数据集中存在的实体之间的丰富关系建模。然后,以有监督的方式对所学习的表示在下游任务上进行微调,以获得有利的结果。
本文全面概述了为计算机视觉应用开发的Transformer模型。我们开发了网络设计空间的分类法,并强调了现有方法的主要优点和缺点。其他文献综述主要集中在NLP领域或涵盖基于注意的一般方法。通过关注视觉Transformer这一新兴领域,我们根据自我注意的内在特征和调查任务,综合整理了最近的研究方法。我们首先介绍了Transformer网络的基本概念,然后详细介绍了最新的视觉Transformer的细节。在可能的情况下,我们将NLP领域中使用的Transformer与针对视觉问题开发的Transformer进行比较,以展示主要的新奇之处和有趣的特定领域见解。最近的方法表明,**卷积运算可以完全被基于注意力的Transformer模块所取代,并且在单一设计中也被联合使用,以鼓励两组互补运算之间的共生。**这项调查最后详述了开放性研究问题,并对未来可能的工作进行了展望。
2.基础
两个关键思想:
- 第一个是自注意力机制(Self-Attention),它允许捕获序列元素之间的“长期”依赖关系,而传统的循环模型发现编码这种关系很困难。
- 第二个关键思想是以(自我)监督的方式对大型(未)标记语料库进行预训练,然后使用小型标记数据集对目标任务进行微调
2.1.自注意力机制
2.1.1.基本自注意力机制
给定一系列项目,自注意力机制评估一个项目与其他项目的相关性(例如,在一个句子中哪些单词可能组合在一起)。自我注意机制是Transformers不可分割的组成部分,它明确地为结构化预测任务建模序列中所有实体之间的交互。基本上,自注意力层通过聚合来自完整输入序列的全局信息来更新序列的每个项目。
对于给定的序列X=(x1 ,x2 ,……,xn )∈Rn×d ,d代表每个实体的维度,自注意的目标是通过根据全局上下文信息对每个实体进行编码来捕获所有元素之间的相互作用。这是通过定义三个可学习的权重矩阵来实现的:
查询矩阵WQ ∈Rn×dq ,关键字矩阵WK ∈Rn×dk ,值矩阵WV ∈Rn×dv
输入序列X首先投影到这些权重矩阵上,以获得Q=XWQ,K=XWKand V=XWV
输出Z=sofmax(QKT/dq 1/2)
对于序列中的给定实体,自注意基本上计算查询与所有键的点积,然后使用softmax运算符对点积进行规范化,以获得注意分数。然后,每个实体成为序列中所有实体的加权和,其中权重由注意分数给出(图2和图3,左上排方框)。
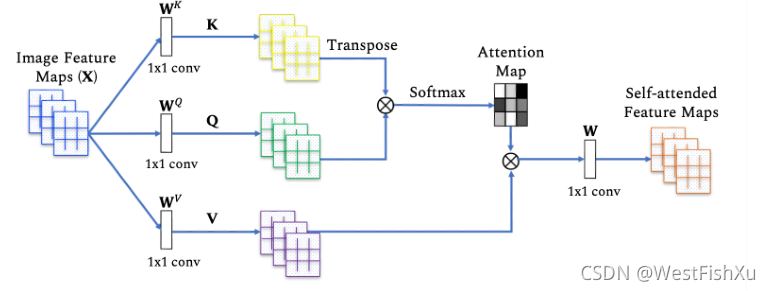
图2:在视觉领域中使用的示例自我注意块。给定图像特征的输入序列,计算三元组(键、查询、值),然后进行注意力计算,并应用它重新加权值。这里显示了一个单头,最后应用输出投影(W)以获得与输入尺寸相同的输出特征。
2.1.2.带掩膜的自注意力
标准的自我注意层关注所有实体,带掩膜的自注意力解码器中使用的自我注意块被屏蔽,以防止关注后续的未来实体。这只需使用掩膜M∈Rn×n进行元素相乘运算即可完成,M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4378
4378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









