



LLaMA Factory大模型多模态目标检测数据集制作与微调
1、图片数据收集与处理
数据来源:本项目的数据从魔搭社区数据集(原始数据约4万张)、飞桨数据集(原始数据约3万张)和 kaggle(原始数据约5万张)中获取,人工进行整理分类,包含愤怒、愤怒、平静、快乐、恐惧、悲伤、 惊讶、愤怒7种情绪,最后整理出约2.2万张人脸表情图片。

图片分类,总共有7个分类
2、图片转LLaMA Factory格式的json文件(我这里是在ubuntu系统转换,跟win系统一样,只是路径不一样)


3、转换完成,大模型数据集格式如图。
注:LLaMA Factory训练的时候图片也要用到,路径一定要对

配置LLaMA Factory数据集
打开dataset_info.json
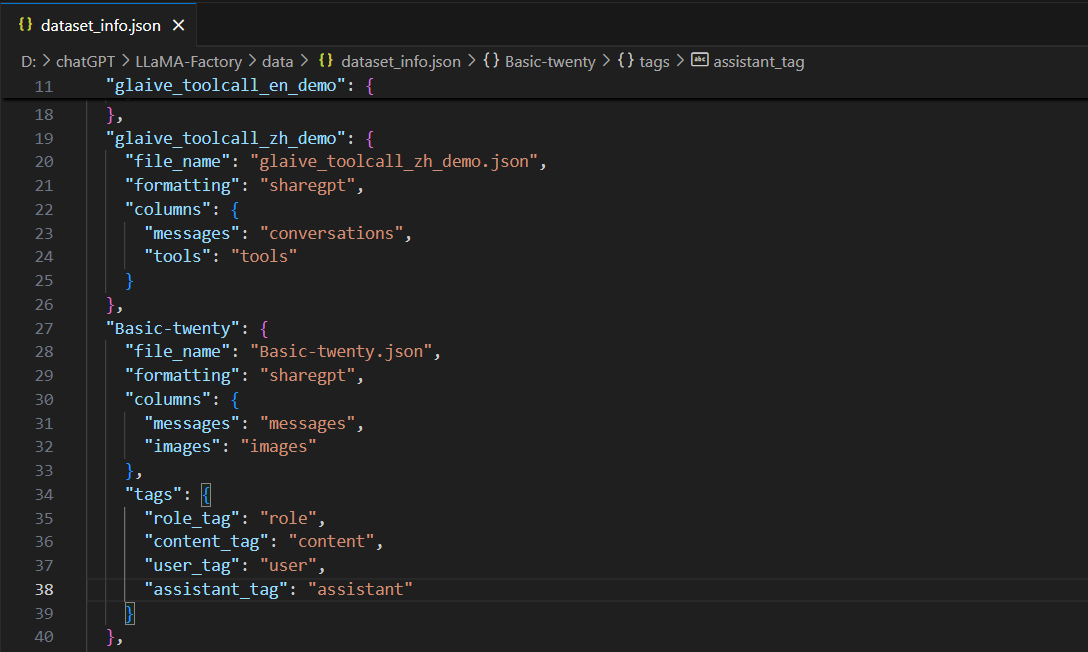
增加Basic-twenty.json
训练
注:大模型路径要对,数据集路径也要对
训练过程

















 9183
9183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









