import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Bidirectional, LSTM, Dense, Dropout, Attention
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# ======================
# 数据预处理函数
# ======================
def preprocess_data(file_path, max_len=100):
"""加载并预处理分子序列数据"""
df = pd.read_csv(file_path)
# 提取输入和目标分子序列
input_seqs = df['input_molecule'].astype(str).tolist()
target_seqs = df['target_molecule'].astype(str).tolist()
# 创建字符级tokenizer
tokenizer = Tokenizer(char_level=True, lower=False)
tokenizer.fit_on_texts(input_seqs + target_seqs)
# 序列转换为整数
input_sequences = tokenizer.texts_to_sequences(input_seqs)
target_sequences = tokenizer.texts_to_sequences(target_seqs)
# 填充序列
input_padded = pad_sequences(input_sequences, maxlen=max_len, padding='post')
target_padded = pad_sequences(target_sequences, maxlen=max_len, padding='post')
# 创建目标序列的one-hot编码
vocab_size = len(tokenizer.word_index) + 1
target_one_hot = tf.keras.utils.to_categorical(target_padded, num_classes=vocab_size)
return input_padded, target_padded, target_one_hot, tokenizer, vocab_size
# ======================
# 模型构建函数
# ======================
def build_molecule_generator(vocab_size, embedding_dim=256, hidden_units=512, dropout_rate=0.3):
"""构建包含4层双向LSTM的分子生成模型"""
# 输入层
inputs = Input(shape=(None,))
# 嵌入层
x = Embedding(input_dim=vocab_size, output_dim=embedding_dim)(inputs)
# 4层双向LSTM
x = Bidirectional(LSTM(hidden_units, return_sequences=True))(x)
x = Dropout(dropout_rate)(x)
for _ in range(3): # 额外3层
x = Bidirectional(LSTM(hidden_units, return_sequences=True))(x)
x = Dropout(dropout_rate)(x)
# 注意力机制
context_vector = Attention()([x, x])
# 输出层
outputs = Dense(vocab_size, activation='softmax')(context_vector)
# 构建模型
model = Model(inputs, outputs)
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
# ======================
# 自定义回调函数 - 记录每个epoch的训练指标
# ======================
class TrainingHistory(tf.keras.callbacks.Callback):
def __init__(self):
super(TrainingHistory, self).__init__()
self.steps = [] # 记录步数
self.accuracies = [] # 记录准确率
self.losses = [] # 记录损失
self.val_accuracies = [] # 记录验证准确率
self.val_losses = [] # 记录验证损失
self.current_step = 0
def on_epoch_end(self, epoch, logs=None):
"""在每个epoch结束时记录指标"""
logs = logs or {}
self.accuracies.append(logs.get('accuracy'))
self.losses.append(logs.get('loss'))
self.val_accuracies.append(logs.get('val_accuracy'))
self.val_losses.append(logs.get('val_loss'))
# 计算当前步数(每个epoch的步数)
steps_per_epoch = len(X_train) // BATCH_SIZE
self.current_step += steps_per_epoch
self.steps.append(self.current_step)
# ======================
# 可视化函数
# ======================
def plot_training_history(history):
"""绘制训练步数与准确率曲线"""
plt.figure(figsize=(12, 8))
# 训练和验证准确率
plt.subplot(2, 1, 1)
plt.plot(history.steps, history.accuracies, 'b-', label='Training Accuracy')
plt.plot(history.steps, history.val_accuracies, 'r-', label='Validation Accuracy')
plt.title('Training Steps vs Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Training Steps')
plt.legend()
plt.grid(True)
# 训练和验证损失
plt.subplot(2, 1, 2)
plt.plot(history.steps, history.losses, 'b-', label='Training Loss')
plt.plot(history.steps, history.val_losses, 'r-', label='Validation Loss')
plt.title('Training Steps vs Loss')
plt.ylabel('Loss')
plt.xlabel('Training Steps')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('training_history.png')
plt.show()
# ======================
# 主程序流程
# ======================
# 参数配置 - 根据要求修改
EMBEDDING_DIM = 256
HIDDEN_UNITS = 512
DROPOUT_RATE = 0.3
BATCH_SIZE = 128 # 修改为128
EPOCHS = 100 # 修改为100
MAX_SEQ_LENGTH = 100
# 1. 加载和预处理数据
train_path = r"C:\Users\12648\Desktop\molecular_pairs_training_set.csv"
val_path = r"C:\Users\12648\Desktop\molecular_pairs_validation_set.csv"
test_path = r"C:\Users\12648\Desktop\molecular_pairs_test_set.csv"
print("加载和预处理数据...")
X_train, y_train, y_train_one_hot, tokenizer, vocab_size = preprocess_data(train_path, MAX_SEQ_LENGTH)
X_val, y_val, y_val_one_hot, _, _ = preprocess_data(val_path, MAX_SEQ_LENGTH)
# 2. 构建模型
print("构建模型...")
model = build_molecule_generator(
vocab_size=vocab_size,
embedding_dim=EMBEDDING_DIM,
hidden_units=HIDDEN_UNITS,
dropout_rate=DROPOUT_RATE
)
model.summary()
# 3. 训练配置
training_history = TrainingHistory()
callbacks = [
EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True),
ModelCheckpoint('best_model.keras', save_best_only=True),
training_history # 添加自定义回调记录训练历史
]
# 4. 训练模型
print(f"开始训练,批次大小={BATCH_SIZE}, 训练轮数={EPOCHS}...")
history = model.fit(
X_train, y_train_one_hot,
validation_data=(X_val, y_val_one_hot),
batch_size=BATCH_SIZE,
epochs=EPOCHS,
callbacks=callbacks,
verbose=1
)
# 5. 绘制训练步数与准确率曲线
print("绘制训练曲线...")
plot_training_history(training_history)
# 6. 测试集评估
print("评估测试集...")
X_test, y_test, y_test_one_hot, _, _ = preprocess_data(test_path, MAX_SEQ_LENGTH)
test_loss, test_acc = model.evaluate(X_test, y_test_one_hot, batch_size=BATCH_SIZE)
print(f"\n测试集评估结果:")
print(f"测试损失: {test_loss:.4f}")
print(f"测试准确率: {test_acc:.4f}")
# 7. 保存最终模型
model.save('molecule_generator_model_final.keras')
print("最终模型已保存")
在此代码的基础上,增加采样功能,在模型训练结束后,使用优化后的模型进行了模拟采样,共进行8000次采样,确保每一次采样得到的都是有效的(满足smiles号的编码规则,满足价键规则)无重复的分子并且采样分子不与原始数据分子一致,并最终输出含8000个采样分子的smiles号的csv文件,
最新发布





 文章讨论了softmax函数在处理大或小数值时可能出现的上溢和下溢问题,以及如何利用softmax的冗余性和tf.math.log_softmax来解决这些问题。在深度学习中,这些问题可能影响模型的可靠性和交叉熵损失计算的准确性。tf.keras.losses.SparseCategoricalCrossentropy的from_logits参数是一个应对策略,它将激活函数移到损失函数内部,减少数值溢出的影响。
文章讨论了softmax函数在处理大或小数值时可能出现的上溢和下溢问题,以及如何利用softmax的冗余性和tf.math.log_softmax来解决这些问题。在深度学习中,这些问题可能影响模型的可靠性和交叉熵损失计算的准确性。tf.keras.losses.SparseCategoricalCrossentropy的from_logits参数是一个应对策略,它将激活函数移到损失函数内部,减少数值溢出的影响。
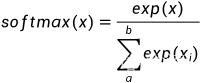
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3839
3839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











