






理解注意力机制:
注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制
标注:1、假设任意两个词向量的乘机表示其相似性
1、transformer整体流程:
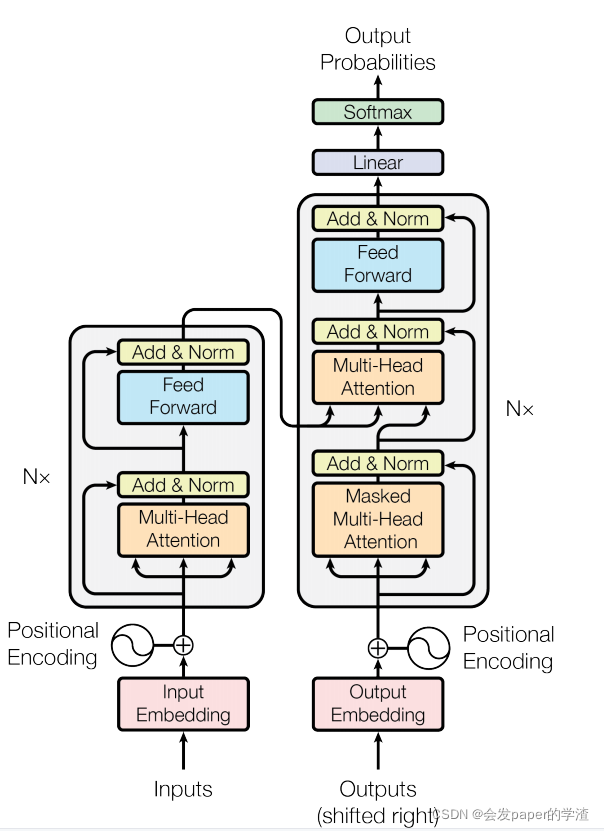
2、dot-product attention以及分别对应的在encoding和decoding中对应的内容:
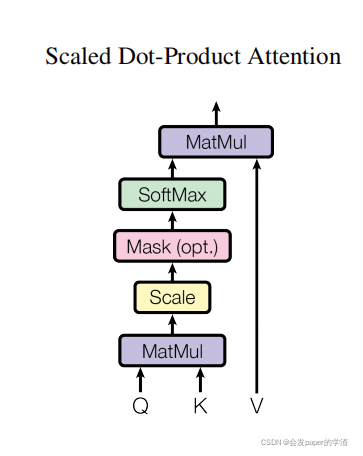
对应的公式为:
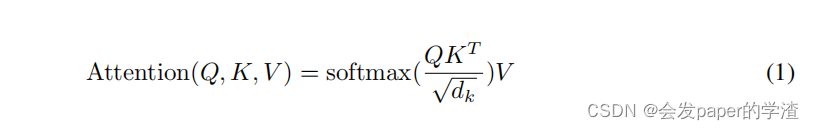
1、 对于encoding部分来说,Q、K、V都是输入的序列向量矩阵,比如,输入 我爱你,则三个对应的都是对每一个字进行enbedding后的序列矩阵A;而对应就是value值对应的权重,可以称之为输入词的重要性权重
2、对于decoding来说,第一步时,设置一个默认开始内容,后面内容(假设最长长度用n全部遮罩处理后最为output)作为decoding的输入
3、multi-head attention阶段,将output进行的多头self-attention和encoding的self-attention统一起来concat,作为全连接的输入。
4、最后通过softmax,概率预测下一步最可能的词是哪一个。
5、位置信息attention补充,将positional信息进行encoding编码,然后将信息合并到词enbedding信息中
6、 关于推进中引入attention的一点思考,勿喷。同时生成用户画像特征向量embedding模型,商品特征向量embedding模型,以及推荐模型。
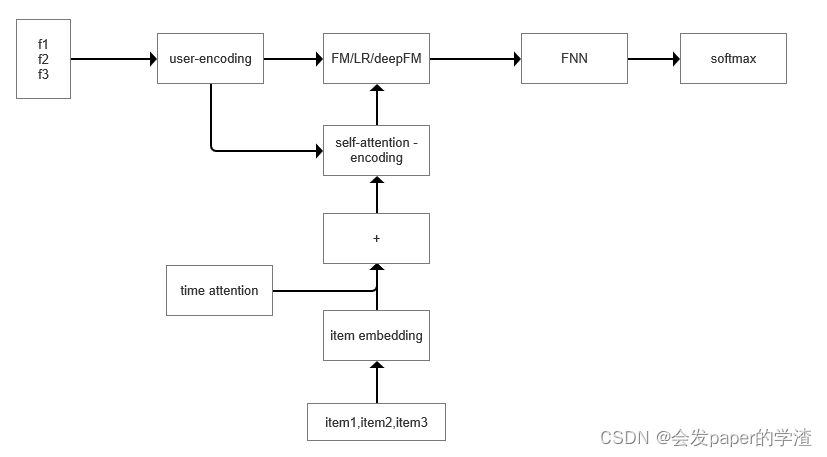
参考文章:
关于LLM为啥使用decoder-only架构:为什么现在的LLM都是Decoder-only的架构? - 科学空间|Scientific Spaces
google对transformer的说明:理解语言的 Transformer 模型 | TensorFlow Core


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











