




 本文探讨了半监督回归中的伪标签策略,强调了在回归任务中量化置信度的重要性。文章介绍了COREG和MSSRA的置信度方法,并提及了不确定性在评估模型性能中的应用。此外,文中还提到了一致性正则在分类中的成功应用,但在回归领域的研究较少。
本文探讨了半监督回归中的伪标签策略,强调了在回归任务中量化置信度的重要性。文章介绍了COREG和MSSRA的置信度方法,并提及了不确定性在评估模型性能中的应用。此外,文中还提到了一致性正则在分类中的成功应用,但在回归领域的研究较少。
Note:本博客更多是关于自己的感悟,没有翻阅文件详细查证,如果存在错误,也请提出指正。
1. 半监督回归
相比于半监督分类,半监督回归相对冷门。回归和分类之间有着难以逾越的天谴,预测精度。分类中的类别是可数的,有限的;而在回归中可以认为类别是无限的(可以通过离散化将回归任务转化成分类任务,但是这样回归精度就会极具下降)。BEL 试图打破分类与回归之间的天谴,参见。Deep Imbalanced Regression 认为回归任务中同样存在不平衡的问题。其实,这一点在半监督语境下的回归任务中更加突出。
半监督回归则是想要利用无标记数据来提升模型性能。一种简单且有效的方法是打伪标签。值得注意的是,半监督分类中的伪标签包含的噪声更小。可以考虑在一个猫狗分类的任务中,随机标记一个伪标签都有百分之五十的概率标记正确。而在一个预测西瓜甜度,假设范围是 [ 0 , 1 ] [0, 1] [0,1], 很难预测一个一摸一样的标签。
正是因为伪标签很难预测正确,所以需要一个量化置信度的策略。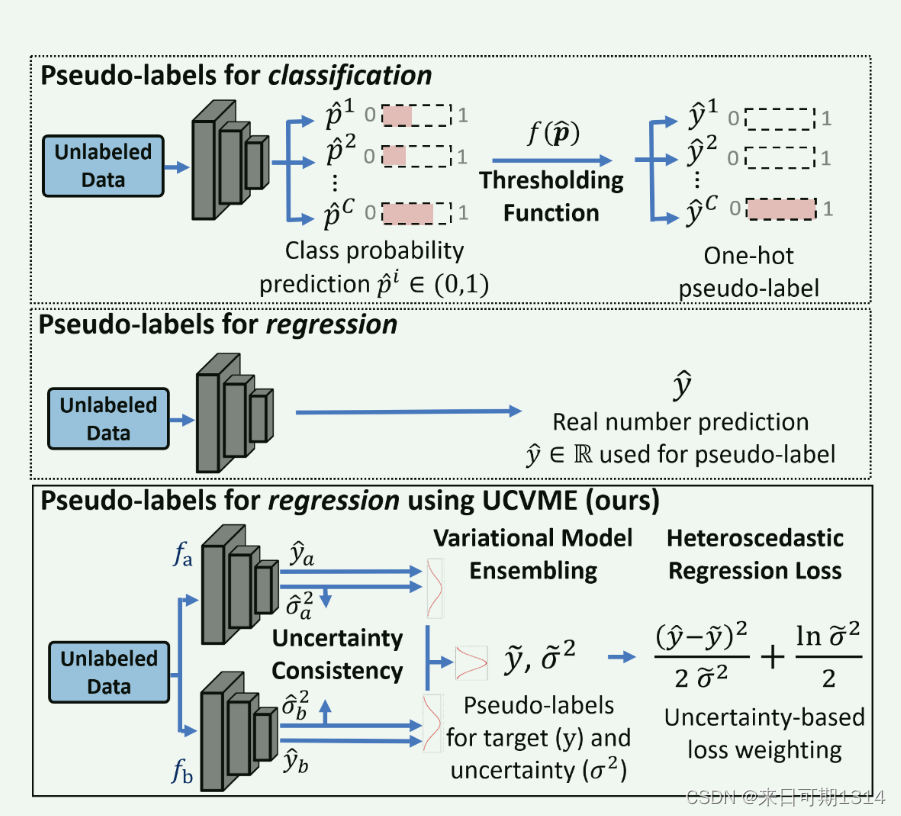 图1. 伪标签策略在分类和回归任务中的差异图。来自《Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks》
图1. 伪标签策略在分类和回归任务中的差异图。来自《Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks》
目前的工作中提出的是启发式策略,即不能证明这样一定是对的,但是感觉是对的。
COREG 提供了一个量化置信度,
δ x u = ∑ x i ∈ Ω u ( ( y i − h ( x i ) ) 2 − ( y i − h ′ ( x i ) ) 2 ) \delta_{\mathbf{x}_u} = \sum_{\mathbf{x}_i \in \Omega_u}((y_i-h(\mathbf{x}_i))^2-(y_i - h'(\mathbf{x}_i))^2) δxu=xi∈Ωu∑((yi</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











