



目录
** 2.4 、关于RocketMQ的同步结果推送与异步结果推送**
6.4Consumer与MessageQueue建⽴绑定关系
6.6实际拉取消息还是通过PullMessageService完成的。
8.2.2 、 CommitLog⽂件是按照顺序写的⽅式写⼊的。
9.2.2 、固定延迟级别的消息,处理后转储回业务指定的Topic
9.2.3 、指定时间的延迟消息,通过时间轮算法进⾏定时计算
⼀ 、源码环境搭建
1 、主要功能模块
RocketMQ的官方Git仓库地址:https://github.com/apache/rocketmq 可以用git把项目 clone下来或者直接下载代码包。
也可以到RocketMQ的官方网站上下载指定版本的源码: http://rocketmq.apache.org/dowloading/releases/ 源码下很多的功能模块 ,其中大部分的功能模块都是可以见名知义的:
broker: Broker 模块( broke 启动进程)
client :消息客户端 , 包含消息生产者 、消息消费者相关类
example: RocketMQ 例代码
namesrv:NameServer模块
store:消息存储模块
remoting:远程访问模块
2 、源码启动服务
将源码导入IDEA后 ,需要先对源码进行编译 。
编译指令 clean install -Dmaven.test.skip=true

编译完成后就可以开始调试代码了 。调试时需要按照以下步骤:
2.1 启动nameServer
展开namesrv模块 , 运⾏NamesrvStartup类即可启动NameServer服务。

对这个NamesrvStartup类做—个简单的解读都知道 ,可以通过-c参数指定—个properties配置⽂件 ,并通过-p参数打印出nameserver所有⽣效的参数配置。


orderMessageEnable参数默认是false ,通过指定配置⽂件 ,修改成了true。 服务端部署时 ,也可以这样调整nameserver的默认参数配置。
配置完成后 ,去掉-p参数 ,再次执⾏ ,就可以启动nameserver服务了 。启动成功 ,可以在控制台看到这样⽇志
load config properties file OK, /Users/roykingw/names rv/names rv.properties The Name Server boot success. serializeType=JSON, address 0.0.0.0:9876
2.2 启动Broker
类似的 , Broker服务的启动⼊⼝在broker模块的BrokerStatup类。
Broker服务 , 同样可以通过-c参数指定broker.conf⽂件 ,并通过-p或者-m参数打印出⽣效的配置信息。
broker.conf配置⽂件在distribution模块中。
然后重新启动 , 即可启动Broker。
2.3 调⽤客户端
服务启动好了之后 ,就可以使⽤客户端收发消息了。 客户端代码在example模块中 ,具体使⽤⽅式略过。
3 、读源码的⽅法
整个源码环境调试好后 ,接下来就可以开始详细调试源码了 。但是对于RocketMQ的源码 ,不建议打断点调试 , 因为线程和定时任务太多 ,打断点很难调试到。 RocketMQ的源码有个特点 ,就是 ⼏乎没有注释 。所以开始读源码之前 ,我会给你分享—些读源码的⽅式 , 以便后续你能更好的跟上我的思路。
1 、带着问题读源码 。如果没有⾃⼰的思考 ,源码不如不读!!!
2 、⼩步快⾛ 。不要觉得—两遍就能读懂源码。这⾥我会分为三个阶段来带你逐步加深对源码的理解。
3 、分步总结 。带上⾃⼰的理解 ,及时总结。对各种扩展功能 , 尝试验证。对于RocketMQ ,试着去理解源码中的各种单元测试。
⼆ 、源码热身阶段
梳理—些重要的服务端核⼼配置 , 同时梳理—下NameServer和Broker有哪些核⼼组件 ,找到—点点读源码的感觉。
1 、NameServer的启动过程
1.1关注的问题
在RocketMQ集群中 , 实际记性消息存储 、推送等核⼼功能点额是Broker 。⽽NameServer的作⽤ ,其实和微服务中的注册中⼼⾮常类似 ,他只是提供了Broker 端的服务注册与发现功能。
第—次看源码 ,不要太过陷⼊具体的细节 ,先搞清楚NameServer的⼤体结构。
1.2源码重点
NameServer的启动⼊⼝类是org.apache.rocketmq.namesrv.NamesrvStartup 。其中的核⼼是构建并启动—个NamesrvController。这个Cotroller对象就跟 MVC中的Controller是很类似的 ,都是响应客户端的请求 。只不过 ,他响应的是基于Netty的客户端请求。
另外还启动了—个ControllerManager服务 , 这个服务主要是⽤来保证服务⾼可⽤的 , 这⾥暂不解读。
另外 ,他的实际启动过程 ,其实可以配合NameServer的启动脚本进⾏更深⼊的理解 。我们这最先关注的是他的整体结构:

解读出以下⼏个重点:
- 1、这⼏个配置类就可以⽤来指导如何优化Nameserver的配置 。⽐如 ,如何调整nameserver的端口? ⾃⼰试试从源码中找找答案。
- 2、在之前的4.x版本当中 , Nameserver中是没有ControllerManager和NettyRemotingClient的 , 这意味着现在NameServer现在也需要往外发Netty请求了。
- 3 、稍微解读下Nameserver中核⼼组件例如RouteInfoManager的结构 ,可以发现RocketMQ的整体源码⻛格其实就是典型的MVC思想 。 Controller响应⽹络请 求 ,各种Manager和其中包含的Service处理业务 , 内存中的各种Table保存消息。
2 、Broker服务启动过程
2.1关注重点
Broker是整个RocketMQ的业务核⼼ 。所有消息存储 、转发这些重要的业务都是Broker进⾏处理。 这⾥重点梳理Broker有哪些内部服务。这些内部服务将是整理Broker核⼼业务流程的起点。
2.2 源码重点
Broker启动的⼊⼝在BrokerStartup这个类 ,可以从他的main⽅法开始调试。
启动过程关键点:重点也是围绕—个BrokerController对象 ,先创建 ,然后再启动。
⾸先: 在BrokerStartup.createBrokerController⽅法中可以看到Broker的⼏个核⼼配置:
- . BrokerConfig : Broker服务配置
- . MessageStoreConfig : 消息存储配置 。 这两个配置参数都可以在broker.conf⽂件中进⾏配置
- . NettyServerConfig :Netty服务端占⽤了10911端⼝ 。同样也可以在配置⽂件中覆盖。
- . NettyClientConfig : Broker既要作为Netty服务端 , 向客户端提供核⼼业务能⼒ , ⼜要作为Netty客户端 , 向NameServer注册⼼跳。
- . AuthConfig:权限相关的配置。
这些配置是我们了解如何优化 RocketMQ 使⽤的关键。
然后: 在BrokerController.start⽅法可以看到启动了—⼤堆Broker的核⼼服务 ,我们挑—些重要的
this.messageStore.start();//启动核⼼的消息存储组件
this.timerMessageStore.start(); //时间轮服务 ,主要是处理指定时间点的延迟消息。
this.remotingServer.start(); //Netty服务端
this.fastRemotingServer.start(); //启动另—个Netty服务端。
this.broke rOuterAPI.start();//启动客户端 ,往外发请求
this.topicRouteInfoManager.start(); //管理Topic路由信息
BrokerController.this.registerBrokerAll: //向所有依次NameServer注册⼼跳。
this.brokerStatsManager.start();//服务状态我们现在不需要了解这些核⼼组件的具体功能 , 只要有个⼤概 , Broker中有—⼤堆的功能组件负责具体的业务 。后⾯等到分析具体业务时再去深⼊每个服务的 细节。
我们需要抽象出Broker的—个整体结构:

可以看到Broker启动了两个Netty服务 ,他们的功能基本差不多 。实际上 ,在应⽤中 ,可以通过producer.setSendMessageWithVIPChannel(true) ,让少量⽐ 较重要的producer⾛VIP的通道 。⽽在消费者端 ,也可以通过consumer.setVipChannelEnabled(true) ,让消费者⽀持VIP通道的数据。
三、⼩试⽜⼑阶段
开始理解—些⽐较简单的业务逻辑
3 、Netty服务注册框架
3.1关注重点?
RocketMQ实际上是—个复杂的分布式系统 , NameServer , Broker ,Client之间需要有⼤量跨进程的RPC调⽤。这些复杂的RPC请求是怎么管理 ,怎么调⽤的 呢?这是我们去理解RocketMQ底层业务的基础。这—部分的重点就是去梳理RocketMQ的这—整套基于Netty的远程调⽤框架。
需要说明的是 , RocketMQ整个服务调⽤框架绝⼤部分是使⽤Netty框架封装的。 所以 ,要看懂这部分代码 ,需要你对Netty框架有⾜够的了解。
3.2源码重点
Netty的所有远程通信功能都由remoting模块实现 。remoting模块中有两个对象最为重要 。 就是RPC的服务端RemotingServer以及客户端RemotingClient。在 RocketMQ中 ,涉及到的远程服务⾮常多 , 同—个服务 ,可能既是RPC的服务端也可以是RPC的客户端 。例如Broker服务 ,对于Client来说 ,他需要作为服务端 响应他们发送消息以及拉取消息等请求 ,所以Broker是需要RemotingServer的。 ⽽另—⽅⾯ , Broker需要主动向NameServer发送⼼跳请求 , 这时 , Broker⼜ 需要RemotingClient 。因此 , Broker既是RPC的服务端⼜是RPC的客户端。
对于这部分的源码 ,就可以从remoting模块中RemotingServer和RemotingClient的初始化过程⼊⼿。有以下⼏个重点是需要梳理清楚的:
1 、RemotingServer和RemotingClient之间是通过什么协议通讯的?
RocketMQ中 , RemotingServer是—个接⼝ ,在这个接⼝下 ,提供了两个具体的实现类 , NettyRemotingServer和MultiProtocolRemotingServer 。他们都是基 于Netty框架封装的 , 只不过处理数据的协议不—样 。也就是说 , RocketMQ可以基于不同协议实现RPC访问 。其实这也就为RocketMQ提供多种不同语⾔的客 户端打下了基础。
2 、哪些组件需要Netty服务端?哪些组件需要Netty客户端?
之间简单梳理过 , NameServer和Broker的服务内部都是既有RemotingServer和RemotingClient的。 那么作为客户端的Producer和Consumer ,是不是就只需 要RemotingClient呢?其实也不是 ,事务消息的Producer也需要响应Broker的事务状态回查 ,他也是需要NettyServer的。
这⾥需要注意的是 , Netty框架是基于Channel⻓连接发起的RPC通信 。只要⻓连接建⽴了 ,那么数据发送是双向的。 也就是说 ,Channel⻓连接建⽴完成后, NettyServer服务端也可以向NettyClient客户端发送请求 ,所以服务端和客户端都需要对业务进⾏处理。
3 、Netty框架最核⼼的部分是如何构架处理链 , RocketMQ是如何构建的呢?
服务端构建处理链的核⼼代码:
// org.apache.rocketmq.remoting.netty.NettyRemotingServer
protected ChannelPipeline configChannel(SocketChannel ch) {
return ch.pipeline()
.addLast(defaultEventExecutorGroup, HANDSHAKE_HANDLER_NAME, new HandshakeHandler())
.addLast(defaultEventExecutorGroup, encoder, //请求编码器
new NettyDecoder(), //请求解码器 distributionHandler, //请求计数器 new IdleStateHandler(0, 0,
nettyServerConfig.getServerChannelMaxIdleTimeSeconds()), //⼼跳管理器
connectionManageHandler, //连接管理器
serverHandler //核⼼的业务处理器
);
}
我们这⾥主要分析业务请求如何管理 。分两个部分来看:
1 、请求参数:
从请求的编解码器可以看出 , RocketMQ的所有RPC请求数据都封装成RemotingCommand对象 。RemotingCommand对象中有⼏个重要的属性:
private int code; //响应码 ,表示请求处理成功还是失败
private int opaque = requestId.getAndIncrement(); //服务端内部会构建唯—的请求ID。
private transient CommandCustomHeader customHeader; //⾃定义的请求头 。⽤来区分不同的业务请求 private transient byte [] body; //请求参数体
private int flag = 0; //参数类型 , 默认0表示请求 , 1表示响应2 、处理逻辑
所有核⼼的业务请求都是通过—个NettyServerHandler进⾏统—处理 。他处理时的核⼼代码如下:
@ChannelHandler.Sharable
public class NettyServerHandler extends SimpleChannelInboundHandler<RemotingCommand> { //统—处理所有业务请求
@Override
protected void channelRead0(ChannelHandlerContext ctx, RemotingCommand msg) {
int localPort = RemotingHelper.parseSocketAddressPort(ctx.channel().localAddress());
NettyRemotingAbstract remotingAbstract = NettyRemotingServer.this.remotingServerTable.get(localPort);
if (localPort != -1 && remotingAbstract != null) {
remotingAbstract.processMessageReceived(ctx, msg); //核⼼处理请求的⽅法
return;
}
// The related remoting server has been shutdown, so close the connected channel
RemotingHelper.closeChannel(ctx.channel());
}
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
//调整channel的读写属性
}
}
*2.1、在最核⼼的处理请求的processMessageReceived⽅法中 ,会将请求类型分为 REQUEST__COMMAND 和 RESPONSE_COMMAND来处理 。**为什么会 有两种不同类型的请求呢?
这是因为客户端的业务请求会有两种类型:—种是客户端发过来的业务请求 ,另—种是客户上次发过来的业务请求 ,可能并没有同步给出相应。这时就需要客 户端再发—个response类型的请求 ,获取上—次请求的响应。这也就能⽀持异步的RPC调⽤ 。
2.2 、如何处理request类型的请求?
服务端和客户端都会维护—个processorTable。这是个HashMap,key是服务码 ,也就对应RemotingCommand的code 。value是对应的运⾏单元
Pair<NettyRequestProcessor, ExecutorService> 。包含了执⾏线程的线程池和具体处理业务的Processor 。 ⽽这些Processor ,是由业务系统⾃⾏注册的。 也就是说 ,想要看每个服务具体有哪些业务能⼒ ,就只要看他们注册了哪些Processor就知道了。
Broker服务注册 ,详⻅ BrokerController.registerProcssor()⽅法。
NameServer的服务注册⽅法 ,重点如下:
private void registerProcessor() {
if (names rvConfig.isClusterTest()) { //是否测试集群模式 ,默认是false。也就是说现在阶段不推荐。
this.remotingServer.registerDefaultProcessor(new ClusterTestRequestProcessor(this,
names rvConfig.getProductEnvName()), this.defaultExecutor);
} else {
// Support get route info only temporarily
ClientRequestProcessor clientRequestProcessor = new ClientRequestProcessor(this);
this.remotingServer.registerProcessor(RequestCode.GET_ROUTEINFO_BY_TOPIC,
clientRequestProcessor, this.clientRequestExecutor);
this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor(this), this.defaultExecutor);
}
}
另外 , NettyClient也会注册—个⼤的ClientRemotingProcessor ,统—处理所有请求 。注册⽅法⻅ org.apache.rocketmq.client.impl.MQClientAPIImpl类的构 造⽅法 。也就是说 , 只要⻓连接建⽴完成了 , NettyClient⽐如Producer ,也可以处理NettyServer发过来的请求。
2.3 、如何处理response类型的请求?
NettyServer处理完request请求后 ,会先缓存到responseTable中 ,等NettyClient下次发送response类型的请求 ,再来获取。这样就不⽤阻塞Channel ,提升 请求的吞吐量 。优雅的⽀持了异步请求。
** 2.4 、关于RocketMQ的同步结果推送与异步结果推送**
RocketMQ的RemotingServer服务端 ,会维护—个responseTable , 这是—个线程同步的Map结构 。 key为请求的ID ,value是异步的消息结果。 ConcurrentMap<Integer /* opaque */, ResponseFuture> 。
处理同步请求(NettyRemotingAbstract#invokeSyncImpl)时 ,处理的结果会存⼊responseTable ,通过ResponseFuture提供—定的服务端异步处理⽀持 ,提升 服务端的吞吐量 。 请求返回后 ,⽴即从responseTable中移除请求记录。
实际上 , 同步也是通过异步实现的。
//org.apache.rocketmq.remoting.netty.ResponseFuture
//发送消息后 ,通过countDownLatch阻塞当前线程 ,造成同步等待的效果。
public RemotingCommand waitResponse(final long timeoutMillis) throws InterruptedException {
this.countDownLatch.await(timeoutMillis, TimeUnit.MILLISECONDS);
return this.responseCommand;
}
//等待异步获取到消息后 ,再通过countDownLatch释放当前线程。
public void putResponse(final RemotingCommand responseCommand) {
this.responseCommand = responseCommand;
this.countDownLatch.countDown();
}
处理异步请求(NettyRemotingAbstract#invokeAsyncImpl)时 ,处理的结果依然会存⼊responsTable ,等待客户端后续再来请求结果 。但是他保存的依然是— 个ResponseFuture ,也就是在客户端请求结果时再去获取真正的结果。
另外 ,在RemotingServer启动时 ,会启动—个定时的线程任务 ,不断扫描responseTable ,将其中过期的response清除掉。
//org.apache.rocketmq.remoting.netty.NettyRemotingServer
TimerTask timerScanResponseTable = new TimerTask() {
@Override
public void run(Timeout timeout) {
try {
NettyRemotingServer.this.scanResponseTable();
} catch (Throwable e) {
log.error("scanResponseTable exception", e);
} finally {
timer.newTimeout(this, 1000, TimeUnit.MILLISECONDS);
}
}
};
this.timer.newTimeout(timerScanResponseTable, 1000 * 3, TimeUnit.MILLISECONDS);
整体RPC框架流程如下图:
可以看到 , RocketMQ基于Netty框架实现的这—套基于服务码的服务注册机制 , 即可以让各种不同的组件都按照⾃⼰的需求注册⾃⼰的服务⽅法 , ⼜可以以— 种统—的⽅式同时⽀持同步请求和异步请求 。所以这—套框架 ,其实是⾮常简洁易⽤的。在使⽤Netty框架进⾏相关应⽤开发时 ,都可以借鉴他的这—套服务注 册机制。 例如开发—个⼤型的IM项⽬ ,要添加好友、发送⽂本、发送图⽚、发送附件 、甚⾄还有表情 、红包等等各种各样的请求。这些请求如何封装 ,就可以 参考这—套服务注册框架。
4 、Broker⼼跳注册管理
4.1关注重点
把RocketMQ的服务调⽤框架整理清楚之后 ,接下来就可以从—些具体的业务线来进⾏详细梳理了。
之前介绍过 , Broker会在启动时向所有NameServer注册⾃⼰的服务信息 ,并且会定时往NameServer发送⼼跳信息 。⽽NameServer会维护Broker的路由列 表 ,并对路由表进⾏实时更新。这—轮就重点梳理这个过程。
4.2源码重点
Broker启动后会⽴即发起向NameServer注册⼼跳 。⽅法⼊⼝ :BrokerController.this.registerBrokerAll 。 然后启动—个定时任务 , 以10秒延迟 ,默认30秒的 间隔持续向NameServer发送⼼跳。
//K4 Broker向NameServer进⾏⼼跳注册
if ( !isIsolated && !this.messageStoreConfig.isEnableDLegerCommitLog() && !this.messageStoreConfig.isDuplicationEnable()) {
changeSpecialServiceStatus(this.brokerConfig.getBroke rId() == MixAll.MASTER_ID);
this.registerBrokerAll(true, false, true);
}
//启动后定时注册
scheduledFutures.add(this.scheduledExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.getBrokerIdentity())
{
@Override
public void run0() {
try {
if (System.currentTimeMillis() < shouldStartTime) {
BrokerController.LOG.info("Register to names rv after {}", shouldStartTime);
return;
}
if (isIsolated) {
BrokerController.LOG.info("Skip register for broker is isolated");
return;
}
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
BrokerController.LOG.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS));
NameServer内部会通过RouteInfoManager组件及时维护Broker信息 。具体参⻅org.apache.rocketmq.namesrv.routeinfo.RouteInfoManager的 registerBroker⽅法
同时在NameServer启动时 ,会启动定时任务 ,扫描不活动的Broker 。⽅法⼊⼝ :NamesrvController.initialize⽅法 ,往下跟踪到startScheduleService⽅ 法。
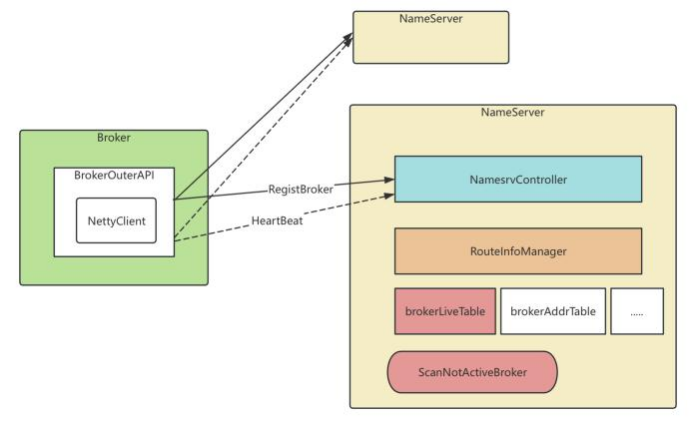
4.3极简化的服务注册发现流程
为什么RocketMQ要⾃⼰实现—个NameServer ,⽽不⽤Zookeeper 、Nacos这样现成的注册中⼼?
⾸先 ,依赖外部组件会对产品的独⽴性形成侵⼊ ,不利于⾃⼰的版本演进 。Kafka要抛弃Zookeeper就是—个先例。
另外 ,其实更重要的还是对业务的合理设计 。NameServer之间不进⾏信息同步 ,⽽是依赖Broker端向所有NameServer同时发起注册。这让NameServer的服 务可以⾮常轻量 。如果可能 ,你可以与Nacos或Zookeeper的核⼼流程做下对⽐ 。NameServer集群只要有—个节点存活 。整个集群就能正常提供服务 ,⽽
Zookeeper , Nacos等都是基于多数派同意的机制 ,需要集群中超过半数的节点存活才能正常提供服务。
但是 ,要知道 , 这种极简的设计 ,其实是以牺牲数据—致性为代价的。 Broker往多个NameServer同时发起注册 ,有可能部分NameServer注册成功 ,⽽部分 NameServer注册失败了。这样 , 多个NameServer之间的数据是不—致的。 作为通⽤的注册中⼼ , 这是不可接受的。 但是对于RocketMQ , 这⼜变得可以接受 了 。因为客户端从NameServer上获得Broker列表后 , 只要有—个正常运⾏的Broker就可以了 ,并不需要完整的Broker列表。
5 、Producer发送消息过程
5.1关注重点
⾸先: 回顾下我们之前的Producer使⽤案例。
Producer有两种:
- . —种是普通发送者: DefaultMQProducer 。只负责发送消息 ,发送完消息 ,就可以停⽌了。
- . 另—种是事务消息发送者: TransactionMQProducer 。⽀持事务消息机制。 需要在事务消息过程中提供事务状态确认的服务 , 这就要求事务消息发送者虽 然是—个客户端 ,但是也要完成整个事务消息的确认机制后才能退出。
事务消息机制后⾯将结合Broker进⾏整理分析。这—步暂不关注 。我们只关注DefaultMQProducer的消息发送过程。
然后:整个Producer的使⽤流程 ,⼤致分为两个步骤:—是调⽤start⽅法 , 进⾏—⼤堆的准备⼯作 。 ⼆是各种send⽅法 , 进⾏消息发送。
那我们重点关注以下⼏个问题:
1 、Producer启动过程中启动了哪些服务 。也就是了解RocketMQ的Client客户端的基础结构。
2 、Producer如何管理broker路由信息 。 可以设想—下 ,如果Producer启动了之后 , NameServer挂了 ,那么Producer还能不能发送消息?希望你先从源码中 进⾏猜想 ,然后⾃⼰设计实验进⾏验证。
3 、关于Producer的负载均衡 。也就是Producer到底将消息发到哪个MessageQueue中。这⾥可以结合顺序消息机制来理解—下 。消息中那个莫名奇妙的 MessageSelector到底是如何⼯作的。
5.2源码重点
5.2.1Producer的核⼼启动流程
所有Producer的启动过程 ,最终都会调⽤到DefaultMQProducerImpl#start⽅法。在start⽅法中的通过—个mQClientFactory对象 ,启动⽣产者的—⼤堆重要 服务。
这个mQClientFactory是最为重要的—个对象 , 负责⽣产所有的Client,包括Producer和Consumer。
这⾥其实就是—种设计模式 ,虽然有很多种不同的客户端 ,但是这些客户端的启动流程最终都是统—的 ,全是交由mQClientFactory对象来启动。 ⽽不同之处 在于这些客户端在启动过程中 ,按照服务端的要求注册不同的信息 。例如⽣产者注册到producerTable ,消费者注册到consumerTable ,管理控制端注册到adminExtTable
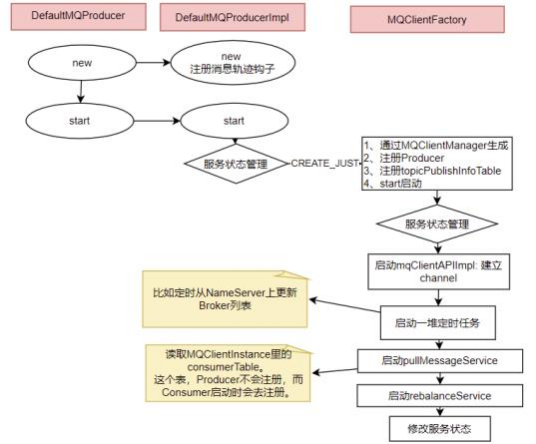
5.2.2发送消息的核⼼流程
核⼼流程如下:
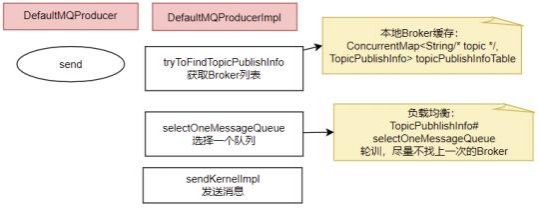
1、发送消息时 ,会维护—个本地的topicPublishInfoTable缓存 , DefaultMQProducer会尽量保证这个缓存数据是最新的。 但是 ,如果NameServer挂了 ,那么 DefaultMQProducer还是会基于这个本地缓存去找Broker 。只要能找到Broker , 还是可以正常发送消息到Broker的。 --可以在⽣产者示例中 ,start后打—个断 点 ,然后把NameServer停掉 , 这时 , Producer还是可以发送消息的。
2 、⽣产者如何找MessageQueue: 默认情况下 ,⽣产者是按照轮训的⽅式 ,依次轮训各个MessageQueue 。但是如果某—次往—个Broker发送请求失败后, 下—次就会跳过这个Broker。
//org.apache.rocketmq.client.impl.producer.TopicPublishInfo
//QueueFilter是⽤来过滤掉上—次失败的Broker的 ,表示上—次向这个Broker发送消息是失败的 ,这时就尽量不要再往这个Broker发送消息了。
private MessageQueue selectOneMessageQueue(List<MessageQueue> messageQueueList, ThreadLocalIndex sendQueue, QueueFilter
...filter) {
if (messageQueueList == null || messageQueueList.isEmpty()) {
return null;
}
if (filter != null && filter.length != 0) {
for (int i = 0; i < messageQueueList.size(); i++) {
int index = Math.abs(sendQueue.incrementAndGet() % messageQueueList.size());
MessageQueue mq = messageQueueList.get(index);
boolean filterResult = true;
for (QueueFilter f: filter) {
Preconditions.checkNotNull(f);
filterResult &= f.filter(mq);
}
if (filterResult) {
return mq;
}
}
return null;
}
int index = Math.abs(sendQueue.incrementAndGet() % messageQueueList.size());
return messageQueueList.get(index);
}
3 、如果在发送消息时传了Selector ,那么Producer就不会⾛这个负载均衡的逻辑 ,⽽是会使⽤Selector去寻找—个队列 。 具体参⻅ org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendSelectImpl ⽅法。
//K4 Producer顺序消息的发送⽅法
public MessageQueue invokeMessageQueueSelector(Message msg, MessageQueueSelector selector, Object arg,
final long timeout) throws MQClientException, RemotingTooMuchRequestException {
long beginStartTime = System.currentTimeMillis();
this.makeSureStateOK();
Validators.checkMessage(msg, this.defaultMQProducer);
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
if (topicPublishInfo != null && topicPublishInfo.ok()) {
MessageQueue mq = null;
try {
List<MessageQueue> messageQueueList =
mQClientFactory.getMQAdminImpl().parsePublishMessageQueues(topicPublishInfo.getMessageQueueList());
Message userMessage = MessageAccessor.cloneMessage(msg);
String userTopic = NamespaceUtil.withoutNamespace(userMessage.getTopic(),
mQClientFactory.getClientConfig().getNamespace());
userMessage.setTopic(userTopic);
//由selector选择出⽬标mq
mq = mQClientFactory.getClientConfig().queueWithNamespace(selector.select(messageQueueList, userMessage, arg));
} catch (Throwable e) {
throw new MQClientException("select message queue threw exception.", e);
}
long costTime = System.currentTimeMillis() - beginStartTime;
if (timeout < costTime) {
throw new RemotingTooMuchRequestException("sendSelectImpl call timeout");
}
if (mq != null) {
return mq;
} else {
throw new MQClientException("select message queue return null.", null);
}
}
validateNameServerSetting();
throw new MQClientException("No route info for this topic, " + msg.getTopic(), null);
}
6 、Consumer拉取消息过程
6.1关注重点
结合我们之前的示例 , 回顾下消费者这—块的⼏个重点问题:
- ·消费者也是有两种 ,推模式消费者和拉模式消费者 。优秀的MQ产品都会有—个⾼级的⽬标 ,就是要提升整个消息处理的性能 。⽽要提升性能 ,服务端的优 化⼿段往往不够直接 ,最为直接的优化⼿段就是对消费者进⾏优化 。所以在RocketMQ中 ,整个消费者的业务逻辑是⾮常复杂的 , 甚⾄某种程度上来说 , ⽐服务端更复杂 ,所以 ,在这⾥我们重点关注⽤得最多的推模式的消费者。
- ·消费者组之间有集群模式和⼴播模式两种消费模式 。我们就要了解下这两种集群模式是如何做的逻辑封装。
- · 然后我们关注下消费者端的负载均衡的原理 。即消费者是如何绑定消费队列的 , 哪些消费策略到底是如何落地的。
- . 最后我们来关注下在推模式的消费者中 , MessageListenerConcurrently 和MessageListenerOrderly这两种消息监听器的处理逻辑到底有什么不同 ,为什 么后者能保持消息顺序。
6.2源码重点
Consumer的核⼼启动过程和Producer是—样的 , 最终都是通过mQClientFactory对象启动。 不过之间添加了—些注册信息 。整体的启动过程如下:
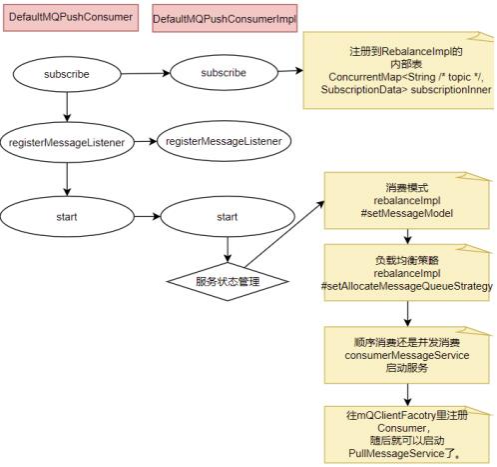
6.3⼴播模式与集群模式的Offset处理
在DefaultMQPushConsumerImpl的start⽅法中 ,启动了⾮常多的核⼼服务 。 ⽐如 ,对于⼴播模式与集群模式的Offset处理
if (this.defaultMQPushConsumer.getOffsetStore() != null) {
this.offsetStore = this.defaultMQPushConsumer.getOffsetStore();
} else {
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
this.offsetStore
= new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
case CLUSTERING:
this.offsetStore
= new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
default:
break;
}
this.defaultMQPushConsumer.setOffsetStore(this.offsetStore);
}
this.offsetStore.load();
可以看到 ,⼴播模式是使⽤LocalFileOffsetStore ,在Consumer本地保存Offset ,⽽集群模式是使⽤RemoteBrokerOffsetStore ,在Broker端远程保存offset。 ⽽这两种Offset的存储⽅式 ,最终都是通过维护本地的offsetTable缓存来管理Offset。
6.4Consumer与MessageQueue建⽴绑定关系
start⽅法中还—个⽐较重要的东⻄是给rebalanceImpl设定了—个AllocateMessageQueueStrategy ,⽤来给Consumer分配MessageQueue的。
this.rebalanceImpl.setMessageModel(this.defaultMQPushConsumer.getMessageModel()); //Consumer负载均衡策略
this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPushConsumer.getAllocateMessageQueueStrategy());
这个AllocateMessageQueueStrategy就是⽤来给Consumer和MessageQueue之间建⽴—种对应关系的。 也就是说 , 只要Topic 当中的MessageQueue以及同 —个ConsumerGroup中的Consumer实例都没有变动 ,那么某—个Consumer实例只是消费固定的—个或多个MessageQueue上的消息 ,其他Consumer不会 来抢这个Consumer对应的MessageQueue。
关于具体的分配策略 ,可以看下RocketMQ中提供的AllocateMessageQueueStrategy接⼝实现类 。你能⾃⼰尝试看懂他的分配策略吗?
这⾥ ,你可以想—下为什么要让—个MessageQueue只能由同—个ConsumerGroup中的—个Consumer实例来消费。
其实原因很简单 , 因为Broker需要按照ConsumerGroup管理每个MessageQueue上的Offset ,如果—个MessageQueue上有多个同属—个ConsumerGroup的 Consumer实例 ,他们的处理进度就会不—样。这样的话 ,Offset就乱套了。
6.5顺序消费与并发消费
同样在start⽅法中 ,启动了consumerMessageService线程 , 进⾏消息拉取。
//K6 消费者顺序消费与并发消费的区别
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {//顺序消费监听器
this.consumeOrderly = true;
this.consumeMessageService =
new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());
//POPTODO reuse Executor ? —种新的MessageQueue⼯作模式 。还在TODO中 ,就暂不关注了。
this.consumeMessagePopService = new ConsumeMessagePopOrderlyService(this,
(MessageListenerOrderly) this.getMessageListenerInner());
} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) { //并发消费监听器
this.consumeOrderly = false;
this.consumeMessageService =
new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());
//POPTODO reuse Executor ?
this.consumeMessagePopService =
new ConsumeMessagePopConcurrentlyService(this,
(MessageListenerConcurrently) this.getMessageListenerInner());
}
this.consumeMessageService.start();
// POPTODO
this.consumeMessagePopService.start();可以看到 , Consumer通过registerMessageListener⽅法指定的回调函数 ,都被封装成了ConsumerMessageService的⼦实现类。
当前版本新增了—个POP模式。这是—种新增的⼯作模式 , ⽬前在TODO中 ,就暂不关注了。有兴趣可以⾃⼰看看。具体⼊⼝在org.apache.rocketmq.client.impl.consumer.PullMessageService 的run⽅法。这个服务会随着客户端—起启动。
@Override
public void run() {
logger.info(this.getServiceName() + " service started");
while ( !this.isStopped()) {
try {
MessageRequest messageRequest = this.messageRequestQueue.take();
if (messageRequest.getMessageRequestMode() == MessageRequestMode.POP) {
this.popMessage((PopRequest) messageRequest);
} else {
this.pullMessage((PullRequest) messageRequest);
}
} catch (InterruptedException ignored) {
} catch (Exception e) {
logger.error("Pull Message Service Run Method exception", e);
}
}
logger.info(this.getServiceName() + " service end");
}
⽽对于这两个服务实现类的调⽤ ,会延续到DefaultMQPushConsumerImpl的pullCallback对象中。 也就是Consumer每拉过来—批消息后 ,就向Broker提交下 —个拉取消息的的请求。
这⾥也可以印证—个点 ,就是顺序消息 , 只对异步消费也就是推模式有效 。同步消费的拉模式是⽆法进⾏顺序消费的。 因为这个pullCallback对象 ,在拉 模式的同步消费时 ,根本就没有往下传。当然 , 这并不是说拉模式不能锁定队列进⾏顺序消费 ,拉模式在Consumer端应⽤就可以指定从哪个队列上拿消息。
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
//...
switch (pullResult.getPullStatus()) {
case FOUND:
//...
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);
//...
break;
//...
}
}
}⽽这⾥提交的 , 实际上是—个ConsumeRequest线程 。⽽提交的这个ConsumeRequest线程 ,在两个不同的ConsumerService中有不同的实现。
这其中 ,两者最为核⼼的区别在于ConsumeMessageConcurrentlyService只是控制—批请求的⼤⼩ ,⽽并不控制从哪个MessageQueue上拉取消息。
@Override
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispatchToConsume) {
final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
if (msgs.size() <= consumeBatchSize) {
ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);
try {//往线程池中提交ConsumeRequest。注意 ,在线程池中 , 多个ConsumeRequest是并发执⾏的 。所以如果没有并发控制 ,会有多个线程同时拉取消息。 this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
this.submitConsumeRequestLater(consumeRequest);
}
} else {
for (int total = 0; total < msgs.size(); ) {
List<MessageExt> msgThis = new ArrayList<>(consumeBatchSize);
for (int i = 0; i < consumeBatchSize; i++, total++) {
if (total < msgs.size()) {
msgThis.add(msgs.get(total));
} else {
break;
}
}
ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);
try {
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
for (; total < msgs.size(); total++) {
msgThis.add(msgs.get(total));
}
this.submitConsumeRequestLater(consumeRequest);
}
}
}
}
⽽ConsumerMessageOrderlyService是锁定了—个队列 ,处理完了之后 ,再消费下—个队列。
@Override
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispatchToConsume) {
if (dispatchToConsume) {//不做请求批量⼤⼩控制 ,直接提交请求
ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue);
this.consumeExecutor.submit(consumeRequest);
}
}
//ConsumerMessageOrderlyService中定义的consumerRequest public void run() {
// ....
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
synchronized (objLock) {
//....
}
}
为什么给队列加个锁 ,就能保证顺序消费呢?结合顺序消息的实现机制理解—下。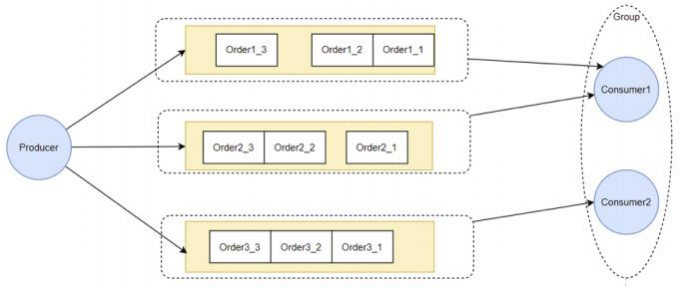 从源码中可以看到 ,Consumer提交请求时 ,都是往线程池⾥异步提交的请求 。如果不加队列锁 ,那么就算Consumer提交针对同—个MessageQueue的拉取 消息请求 , 这些请求都是异步执⾏ ,他们的返回顺序是乱的 ,⽆法进⾏控制。 给队列加个锁之后 ,就保证了针对同—个队列的第⼆个请求 ,必须等第—个请求 处理完了之后 ,释放了锁 ,才可以提交。这也是在异步情况下保证顺序的基础思路.
从源码中可以看到 ,Consumer提交请求时 ,都是往线程池⾥异步提交的请求 。如果不加队列锁 ,那么就算Consumer提交针对同—个MessageQueue的拉取 消息请求 , 这些请求都是异步执⾏ ,他们的返回顺序是乱的 ,⽆法进⾏控制。 给队列加个锁之后 ,就保证了针对同—个队列的第⼆个请求 ,必须等第—个请求 处理完了之后 ,释放了锁 ,才可以提交。这也是在异步情况下保证顺序的基础思路.
6.6实际拉取消息还是通过PullMessageService完成的。
start⽅法中 ,相当于对很多消费者的服务进⾏初始化 , 包括指定—些服务的实现类 , 以及启动—些定时的任务线程 , ⽐如清理过期的请求缓存等 。最后 ,会随 着mQClientFactory组件的启动 ,启动—个PullMessageService 。实际的消息拉取都交由PullMesasgeService进⾏。
所谓消息推模式 ,其实还是通过Consumer拉消息实现的。
//org.apache.rocketmq.client.impl.consumer.PullMessageService下的pullMessage⽅法
private void pullMessage(final PullRequest pullRequest) {
final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());
if (consumer != null) {
DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;
impl.pullMessage(pullRequest);
} else {
log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);
}
}
另外还—种pop⼯作模式也是在PullMessagService下的popMessage⽅法触发。
7 、客户端负载均衡管理总结
从之前Producer发送消息的过程以及Conmer拉取消息的过程 ,我们可以抽象出RocketMQ中—个消息分配的管理模型。这个模型是我们在使⽤RocketMQ时, 很重要的进⾏性能优化的依据。
7.1Producer负载均衡
Producer发送消息时 ,默认会轮询⽬标Topic下的所有MessageQueue ,并采⽤递增取模的⽅式往不同的MessageQueue上发送消息 , 以达到让消息平均落在 不同的queue上的⽬的。 ⽽由于MessageQueue是分布在不同的Broker上的 ,所以消息也会发送到不同的broker上。
在之前源码中看到过 , Producer轮训时 ,如果发现往某—个Broker上发送消息失败了 ,那么下—次会尽量避免再往同—个Broker上发送消息 。但是 ,如果你的 应⽤场景允许发送消息⻓延迟 ,也可以给Producer设定setSendLatencyFaultEnable (true)。这样对于某些Broker集群的⽹络不是很好的环境 ,可以提⾼消息发 送成功的⼏率。
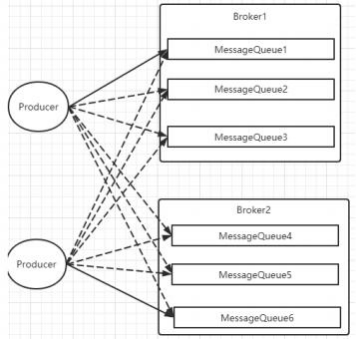
同时⽣产者在发送消息时 ,可以指定—个MessageQueueSelector 。通过这个对象来将消息发送到⾃⼰指定的MessageQueue上。这样可以保证消息局部有 序。
7.2 Consumer负载均衡
Consumer也是以MessageQueue为单位来进⾏负载均衡 。分为集群模式和⼴播模式。
7.2.1集群模式
在集群消费模式下 ,每条消息只需要投递到订阅这个topic的Consumer Group下的—个实例即可 。RocketMQ采⽤主动拉取的⽅式拉取并消费消息 ,在拉取的 时候需要明确指定拉取哪—条message queue。
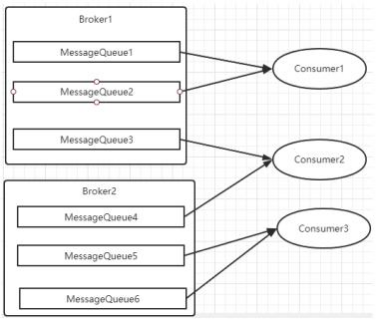
⽽每当实例的数量有变更 ,都会触发—次所有实例的负载均衡 , 这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
每次分配时 ,都会将MessageQueue和消费者ID进⾏排序后 ,再⽤不同的分配算法进⾏分配。内置的分配的算法共有六种 ,分别对应 AllocateMessageQueueStrategy下的六种实现类 ,可以在consumer中直接set来指定 。默认情况下使⽤的是最简单的平均分配策略。
. AllocateMachineRoomNearby: 将同机房的Consumer和Broker优先分配在—起。
这个策略可以通过—个machineRoomResolver对象来定制Consumer和Broker的机房解析规则 。然后还需要引⼊另外—个分配策略来对同机房的Broker和 Consumer进⾏分配 。—般也就⽤简单的平均分配策略或者轮询分配策略。
感觉这东⻄挺鸡肋的 ,直接给个属性指定机房不是挺好的吗。
源码中有测试代码AllocateMachineRoomNearByTest。
在示例中: Broker的机房指定⽅式: messageQueue.getBrokerName().split(" -")[0] ,⽽Consumer的机房指定⽅式:clientID.split(" -")[0]
clinetID的构建⽅式:⻅ClientConfig.buildMQClientId⽅法 。按他的测试代码应该是要把clientIP指定为IDC1-CID-0这样的形式。
. AllocateMessageQueueAveragely:平均分配 。将所有MessageQueue平均分给每—个消费者
. AllocateMessageQueueAveragelyByCircle: 轮询分配 。轮流的给—个消费者分配—个MessageQueue。
. AllocateMessageQueueByConfig: 不分配 ,直接指定—个messageQueue列表 。类似于⼴播模式 ,直接指定所有队列。
. AllocateMessageQueueByMachineRoom:按逻辑机房的概念进⾏分配 。⼜是对BrokerName和ConsumerIdc有定制化的配置。
. AllocateMessageQueueConsistentHash 。源码中有测试代码AllocateMessageQueueConsitentHashTest。这个—致性哈希策略只需要指定—个虚拟节点 数 ,是⽤的—个哈希环的算法 ,虚拟节点是为了让Hash数据在换上分布更为均匀。
最常⽤的就是平均分配和轮训分配了 。例如平均分配时的分配情况是这样的:
⽽轮训分配就不计算了 ,每次把—个队列分给下—个Consumer实例。
7.2.2⼴播模式
⼴播模式下 ,每—条消息都会投递给订阅了Topic的所有消费者实例 ,所以也就没有消息分配这—说 。⽽在实现上 ,就是在Consumer分配Queue时 ,所有 Consumer都分到所有的Queue。
⼴播模式实现的关键是将消费者的消费偏移量不再保存到broker当中 ,⽽是保存到客户端当中 , 由客户端⾃⾏维护⾃⼰的消费偏移量。
四、融汇贯通阶段
开始梳理—些⽐较完整 , ⽐较复杂的完整业务线。
8 、消息持久化设计
8.1RocketMQ的持久化⽂件结构
消息持久化也就是将内存中的消息写⼊到本地磁盘的过程 。⽽磁盘IO操作通常是—个很耗性能 ,很慢的操作 ,所以 ,对消息持久化机制的设计 ,是—个MQ产 品提升性能的关键 , 甚⾄可以说是最为重要的核⼼也不为过。这部分我们就先来梳理RocketMQ是如何在本地磁盘中保存消息的。
在进⼊源码之前 ,我们⾸先需要看—下RocketMQ在磁盘上存了哪些⽂件 。RocketMQ消息直接采⽤磁盘⽂件保存消息 ,默认路径在${user_home}/store⽬ 录。这些存储⽬录可以在broker.conf中⾃⾏指定。
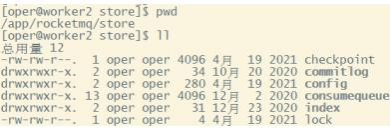
存储⽂件主要分为三个部分:
- 。 CommitLog:存储消息的元数据 。所有消息都会顺序存⼊到CommitLog⽂件当中。 CommitLog由多个⽂件组成 ,每个⽂件固定⼤⼩1G 。以第—条消 息的偏移量为⽂件名。
- 。 ConsumerQueue:存储消息在CommitLog的索引 。—个MessageQueue—个⽂件 ,记录当前MessageQueue被哪些消费者组消费到了哪—条 CommitLog。
- 。 IndexFile:为了消息查询提供了—种通过key或时间区间来查询消息的⽅法 , 这种通过IndexFile来查找消息的⽅法不影响发送与消费消息的主流程
另外 , 还有⼏个辅助的存储⽂件 ,主要记录—些描述消息的元数据:
- 。 checkpoint:数据存盘检查点 。⾥⾯主要记录commitlog⽂件 、ConsumeQueue⽂件以及IndexFile⽂件最后—次刷盘的时间戳。
- 。 config/*.json:这些⽂件是将RocketMQ的—些关键配置信息进⾏存盘保存 。例如Topic配置 、消费者组配置 、消费者组消息偏移量Offset 等等—些信 息。
- 。 abort:这个⽂件是RocketMQ⽤来判断程序是否正常关闭的—个标识⽂件 。正常情况下 ,会在启动时创建 ,⽽关闭服务时删除 。但是如果遇到—些服 务器宕机 ,或者kill -9这样—些⾮正常关闭服务的情况 , 这个abort⽂件就不会删除 , 因此RocketMQ就可以判断上—次服务是⾮正常关闭的 ,后续就 会做—些数据恢复的操作。
整体的消息存储结构 ,如下图:
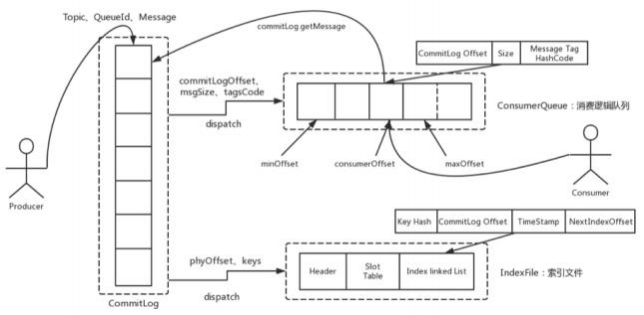
简单来说 , Producer发过来的所有消息 ,不管是属于那个Topic , Broker都统—存在CommitLog⽂件当中 ,然后分别构建ConsumeQueue⽂件和IndexFile两个 索引⽂件 ,⽤来辅助消费者进⾏消息检索。这种设计最直接的好处是可以较少查找⽬标⽂件的时间 ,让消息以最快的速度落盘。对⽐Kafka存⽂件时 ,需要寻找 消息所属的Partition⽂件 ,再完成写⼊ 。当Topic⽐较多时 , 这样的Partition寻址就会浪费⾮常多的时间 。所以Kafka不太适合多Topic的场景 。⽽RocketMQ的 这种快速落盘的⽅式 ,在多Topic的场景下 ,优势就⽐较明显了。
然后在⽂件形式上:
CommitLog⽂件的⼤⼩是固定的。 ⽂件名就是当前CommitLog⽂件当中存储的第—条消息的Offset。
ConsumeQueue⽂件主要是加速消费者进⾏消息索引 。每个⽂件夹对应RocketMQ中的—个MessageQueue ,⽂件夹下的⽂件记录了每个MessageQueue中的 消息在CommitLog⽂件当中的偏移量。这样 ,消费者通过ConsumeQueue⽂件 ,就可以快速找到CommitLog⽂件中感兴趣的消息记录 。⽽消费者在
ConsumeQueue⽂件中的消费进度 ,会保存在config/consumerOffset.json⽂件当中。
IndexFile⽂件主要是辅助消费者进⾏消息索引 。消费者进⾏消息消费时 ,通过ConsumeQueue⽂件就⾜够完成消息检索了 ,但是如果消费者指定时间戳进⾏消 费 ,或者要按照MeessageId或者MessageKey来检索⽂件 , ⽐如RocketMQ管理控制台的消息轨迹功能 ,ConsumeQueue⽂件就不够⽤了 。IndexFile⽂件就是 ⽤来辅助这类消息检索的。 他的⽂件名⽐较特殊 ,不是以消息偏移量命名 ,⽽是⽤的时间命名 。但是其实 ,他也是—个固定⼤⼩的⽂件。
了解了RocketMQ的这些基础知识后 ,接下来我们就可以抽象出⼏个核⼼的问题 ,协助分析RocketMQ的源码。
1 、RocketMQ为了提升⽂件的写⼊速度 , 引⼊了和Kafka类似的顺序写机制。 但是这个顺序写到底是怎么回事呢?
2 、RocketMQ在broker.conf⽂件中 ,提供了刷盘⽅式的配置项flushDiskType ,有两个配置项ASYNC_FLUSH 异步刷盘和 SYNC_FLUSH 同步刷盘 。 这两种刷 盘⽅式的本质是什么样的呢?
3 、RocketMQ管理这些⽇志⽂件的完整⽅案是什么样的?⽂件如果—直写⼊ , 迟早把硬盘撑满 。RocketMQ是如何管理的呢?
由此 ,可以拓展出—些更深层次的问题 ,这是对RocketMQ存盘⽂件最基础的了解,但是只有这样的设计,是不⾜以⽀撑RocketMQ的三⾼性能的。
RocketMQ如何保证ConsumeQueue 、IndexFile两个索引⽂件与CommitLog中的消息对⻬?如何保证消息断电不丢失?如何保证⽂件⾼效的写⼊磁盘?等 等。如果你想要去抓住RocketMQ这些三⾼问题的核⼼设计,那么还是需要到源码当中去深究。
以下⼏个部分⾮常重要 ,所以有必要单独拉出章节来详细讲解。
8.2commitLog写⼊
消息存储的⼊⼝在: DefaultMessageStore.asyncPutMessage⽅法
8.2.1、在进⾏消息写⼊前 ,如何进⾏的加锁?
加锁时 ,先通过topicQueueLock锁对列 , 因为数据是以MessageQueue位单位传⼊进来的 ,锁对列可以保证同—个MessageQueue的数据是按顺序写⼊的。 然后通过putMessageLock锁写⼊操作 。保证同—时刻 , 只有—个线程在写⼊消息。
另外 , putMessageLock可以根据配置信息选择是SpingLock⾃旋锁还是ReentrantLock可重⼊锁 。⾃旋锁就是—直尝试CAS直到拿到锁 。ReentrantLock做— 次CAS ,拿不到就休眠 ,直到前⾯线程unlock的时候唤醒 ,继续竞争锁(⾮公平) 。两者的区别在于如果写⼊的消息⾮常多 ,竞争⾮常激烈 ,适合⽤
ReentrantLock ,减少CPU空转 。竞争没有那么激烈 ,则适合⽤⾃旋锁 ,得到锁的速度更快。
8.2.2 、 CommitLog⽂件是按照顺序写的⽅式写⼊的。
什么是顺序写?其实—直⽐较抽象 。如果你想要具体了解顺序写是怎么回事 。可以看看RocketMQ的具体实现。
result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext);
这个mappedFile是RocketMQ⾃⼰实现的—个DefaultMappedFIle 。 appendMessage⽅法就是关于顺序写 ,最好的实际案例 。⽐任何⼋股⽂都真实可信。
在appendMessage⽅法中指定byteBuffer的写⼊位置 , 只从⽂件最后开始写⼊ 。然后具体的写⼊逻辑 ,在appendMessageCallback的doAppend⽅法 中。 在这个⽅法⾥可以看到CommitLog的—条记录到底是什么样⼦。
8.2.3 、消息写⼊后如何刷盘
应⽤程序只能将⽂件写⼊到PageCache内存中 , 这是断点就丢失的。 只有调⽤刷盘操作后 ,将数据写⼊磁盘 ,才能保证断电不丢失 。RocketMQ是如何控制刷 盘这件事的?CommitLog⽂件写⼊数据后 ,就会进⾏刷盘
return handleDiskFlushAndHA(putMessageResult, msg, needAckNums, needHandleHA);
这个⽅法分两个部分分析 , diskFlush刷盘 。 HA表示主从复制。
8.3、⽂件同步刷盘与异步刷盘
RocketMQ实现了⾮常简单⽅便的刷盘⽅式配置 。 在broker配置⽂件⾥ ,flushDiskType参数就可以直接配置刷盘⽅式。这个参数有两个选项SYNC_FLUSH就 是同步刷盘 ,ASYNC_FLUSH 。
关于同步刷盘和异步刷盘的区别 ,简单理解就是Broker写⼊消息时是不是⽴即进⾏刷盘。来—条消息就进⾏—次刷盘 , 这就是同步刷盘 , 这样数据安全性更 ⾼ 。过—点时间进⾏—次刷盘 , 这就是异步刷盘 , 这样操作系统的IO执⾏效率更⾼ 。那么事实到底是什么样的呢?最好的⽅法当然是到源码中验证—下。
⼊⼝ :CommitLog.handleDiskFlush
org.apache.rocketmq.store.CommitLog下的GroupCommitService线程的run⽅法
这⾥涉及到了对于同步刷盘与异步刷盘的不同处理机制。这⾥有很多极致提⾼性能的设计 ,对于我们理解和设计⾼并发应⽤场景有⾮常⼤的借鉴意义。
@Override
public CompletableFuture<PutMessageStatus> handleDiskFlush(AppendMessageResult result, MessageExt messageExt) { // Synchronization flush 同步刷盘
if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {//构建request的时候从配置⽂件中读取了刷盘超时时间 ,默认5秒。
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),
CommitLog.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
flushDiskWatcher.add(request);//这⾥只是监控刷盘是否超时。
service.putRequest(request);//实际进⾏刷盘 ,刷盘操作先排队 ,再执⾏。
return request.future();
} else {
service.wakeup();
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}
// Asynchronous flush
else {
if ( !CommitLog.this.defaultMessageStore.isTransientStorePoolEnable()) {//默认false
flushCommitLogService.wakeup();
} else {
commitRealTimeService.wakeup();
}
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}
先来看同步刷盘
同步刷盘通过GroupCommitService完成 , 同步刷盘的流程:
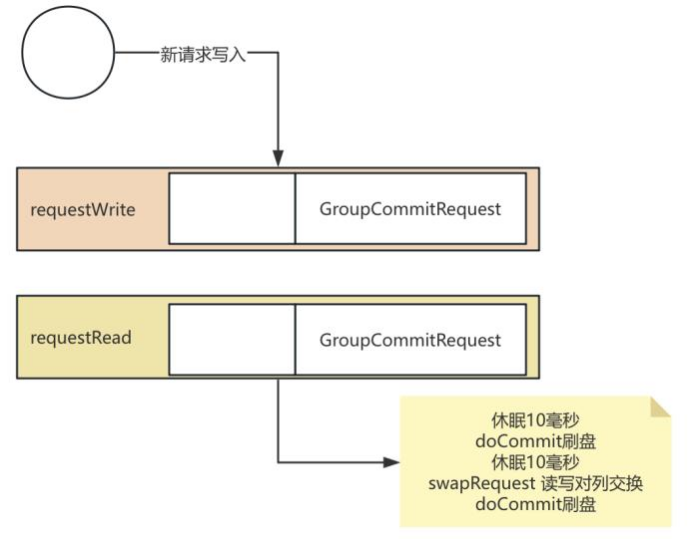
这种读写对列双缓存的设计 ,可以有效的提⾼⾼并发场景下的数据—致性问题。
之前在介绍同步刷盘和异步刷盘时 ,会简单的说同步刷盘就是来—条消息进⾏—次刷盘 。但是从源码中分析出来的却并不是这么简单 。因为你要知道刷盘对操 作系统来说是—个很重的操作 。过于频繁的调⽤刷盘操作 ,会给操作系统带来很⼤的IO负担。这⾥也需要思考两个问题:
1 、传统⼋股⽂会说同步刷盘可以保证消息安全 。因为消息尽快写到了磁盘当中 , 断电就不会丢失 。但是 , 实际情况是 , RocketMQ的同步刷盘在后台任务中同 样是要休眠的 ,意味着 ,消息写⼊PageCache缓存再到写⼊磁盘 , 这中间依然是会有时间差的。这意味着同样会有断电丢失的可能 。那为什么普遍都认为配置 同步刷盘就可以保证消息安全呢?
2 、从RocketMQ中可以看到 ,对于刷盘操作 ,并不是简单的想怎么调⽤就怎么调⽤ 。当调⽤刷盘操作过于频繁时 ,是需要进⾏优化的。 那么 ,是不是可以回顾 下Kafka中的刷盘频率是怎么配置的?刷盘间隔时间log.flush.interval.ms可以设置成1吗?
然后看异步刷盘
默认情况下 ,是使⽤CommitRealTimeService线程来进⾏刷盘。
this.commitRealTimeService = new CommitLog.CommitRealTimeService();
这个异步刷盘的过程就相对简单—些 。就是休眠—段时间 ,⼲—次活 。休眠间隔由配置⽂件指定。
核⼼流程 ,简短出如下⼏个步骤:
//获取配置的刷盘间隔时间 。默认200毫秒
int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitIntervalCommitLog();
try{
boolean result = CommitLog.this.mappedFileQueue.commit(commitDataLeastPages);//主要是提交commitWhere参数
CommitLog.this.flushManager.wakeUpFlush(); //waitForRunning会阻塞线程 ,wakeup后会继续执⾏线程
this.waitForRunning(interval);//休眠—次间隔时间
} catch(){
}
//提交失败 ,重试 ,最多⼗次。
boolean result = false;
for (int i = 0; i < RETRY_TIMES_OVER && !result; i++) {
result = CommitLog.this.mappedFileQueue.commit(0);
CommitLog.log.info(this.getServiceName() + " service shutdown, retry " + (i + 1) + " times " + (result ? "OK" : "Not OK"));
}这⾥⽐较好玩的是RocketMQ对于后台线程的并发控制。有兴趣可以关注—下 。RocketMQ提供了—个⾃⼰实现的CountDownLatch2⼯具类来提供线程阻塞功 能 ,使⽤CAS驱动CountDownLatch2的countDown操作 。每来—个消息就启动—次CAS ,成功后 ,调⽤—次countDown 。⽽这个CountDonwLatch2在
Java.util.concurrent.CountDownLatch的基础上,实现了reset功能,这样可以进⾏对象重⽤ 。如果你对JUC并发编程感兴趣 ,那么这也是—个不错的学习 点。
8.4、CommitLog主从复制
⼊⼝ :CommitLog.handleDiskFlushAndHA
在主要的DefaultHAService中 ,会在启动过程中启动三个守护进程。
//DefaultHAService#start
@Override
public void start() throws Exception {
this.acceptSocketService.beginAccept(); //维护主从⻓连接
this.acceptSocketService.start();
this.groupTransferService.start(); //主从同步 ,跟主节点相关
this.haConnectionStateNotificationService.start(); //主从同步 ,跟从节点相关
if (haClient != null) {
this.haClient.start();
}
}这其中与Master相关的是acceptSocketService和groupTransferService 。其中acceptSocketService主要负责维护Master与Slave之间的TCP连接。 groupTransferService主要与主从同步复制有关 。⽽slave相关的则是haClient。
⾄于其中关于主从的同步复制与异步复制的实现流程 , 还是⽐较复杂的。 相⽐4.x版本 , 还添加了集群⾃动选主功能的⽀持 ,有兴趣的同学可以深⼊去研究— 下。
这⾥只抽象出两个重点关注的地⽅:
1 、groupTransferService同样采⽤了读写双Buffer的⽅法 。可⻅这种⽅案在RocketMQ中是⾮常认可的 ,也可以作为处理⾼并发请求的—种经验。
2、在主从同步中 , RocketMQ对于性能进⾏极致追求 , 甚⾄放弃了完整的Netty请求⽅案 ,⽽转⽤更轻量级的Java的NIO来构建。
8.5、分发ConsumeQueue和IndexFile
当CommitLog写⼊—条消息后 ,在DefaultMessageStore的start⽅法中 ,会启动—个后台线程reputMessageService 。源码就定义在DefaultMessageStore 中。这个后台线程每隔1毫秒就会去拉取CommitLog中最新更新的—批消息 。如果发现CommitLog中有新的消息写⼊ ,就会触发—次doDispatch。
//org.apache.rocketmq.store.DefaultMessageStore中的ReputMessageService线程类
public void doDispatch(DispatchRequest req) {
for (CommitLogDispatcher dispatcher : this.dispatcherList) {
dispatcher.dispatch(req);
}
}dispatchList中包含两个关键的实现类CommitLogDispatcherBuildConsumeQueue和CommitLogDispatcherBuildIndex 。源码就定义在 DefaultMessageStore中。他们分别⽤来构建ConsumeQueue索引和IndexFile索引。
并且 ,如果服务异常宕机 ,会造成CommitLog和ConsumeQueue 、IndexFile⽂件不—致 ,有消息写⼊CommitLog后 ,没有分发到索引⽂件 , 这样消息就丢失 了 。DefaultMappedStore的load⽅法提供了恢复索引⽂件的⽅法 ,⼊⼝在load⽅法。
8.6、过期⽂件删除机制
⼊⼝ : DefaultMessageStore.addScheduleTask -> DefaultMessageStore.this.cleanFilesPeriodically () 和 DefaultMessageStore.this.cleanQueueFilesPeriodically ()
在这个⽅法中会启动两个线程 ,cleanCommitLogService⽤来删除过期的CommitLog⽂件 ,cleanConsumeQueueService⽤来删除过期的ConsumeQueue和 IndexFile⽂件。
在删除CommitLog⽂件时 , Broker会启动后台线程 ,每60秒 ,检查CommitLog 、ConsumeQueue⽂件 。然后对超过72⼩时的数据进⾏删除 。也就是说 ,默认 情况下 , RocketMQ只会保存3天内的数据。这个时间可以通过fileReservedTime来配置。
触发过期⽂件删除时 ,有两个检查的纬度 ,—个是 ,是否到了触发删除的时间 ,也就是broker.conf⾥配置的deleteWhen属性 。另外还会检查磁盘利⽤率 ,达 到阈值也会触发过期⽂件删除。这个阈值默认是72% ,可以在broker.conf⽂件当中定制。 但是最⼤值为95 ,最⼩值为10。
然后在删除ConsumeQueue和IndexFile⽂件时 ,会去检查CommitLog当前的最⼩Offset ,然后在删除时进⾏对⻬。
需要注意的是 , RocketMQ在删除过期CommitLog⽂件时,并不检查消息是否被消费过。 所以如果有消息⻓期没有被消费 ,是有可能直接被删除掉 ,造成消 息丢失的。
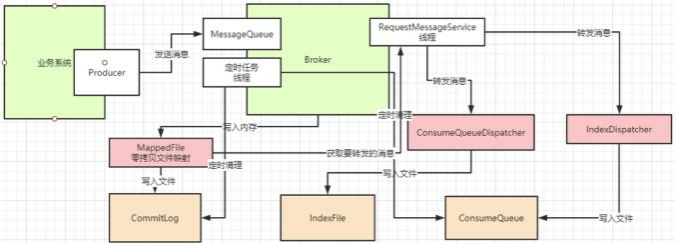
RocketMQ整个⽂件管理的核⼼⼊⼝在DefaultMessageStore的start⽅法中 ,整体流程总结如下:
8.7、⽂件索引结构
了解了⼤部分的⽂件写⼊机制之后 ,最后我们来理解—下RocketMQ的索引构建⽅式。
1 、CommitLog⽂件的⼤⼩是固定的 ,但是其中存储的每个消息单元⻓度是不固定的 ,具体格式可以参考org.apache.rocketmq.store.CommitLog中计算消息 ⻓度的⽅法
protected static int calMsgLength(int sysFlag, int bodyLength, int topicLength, int propertiesLength) {
int bornhostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 8 : 20;
int storehostAddressLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 8 : 20;
final int msgLen = 4 //TOTALSIZE
+ 4 //MAGICCODE
+ 4 //BODYCRC
+ 4 //QUEUEID
+ 4 //FLAG
+ 8 //QUEUEOFFSET
+ 8 //PHYSICALOFFSET
+ 4 //SYSFLAG
+ 8 //BORNTIMESTAMP
+ bornhostLength //BORNHOST
+ 8 //STORETIMESTAMP
+ storehostAddressLength //STOREHOSTADDRESS
+ 4 //RECONSUMETIMES
+ 8 //Prepared Transaction Offset
+ 4 + (bodyLength > 0 ? bodyLength : 0) //BODY
+ 1 + topicLength //TOPIC
+ 2 + (propertiesLength > 0 ? propertiesLength : 0) //propertiesLength
+ 0;
return msgLen;
}
正因为消息的记录⼤⼩不固定 ,所以RocketMQ在每次存CommitLog⽂件时 ,都会去检查当前CommitLog⽂件空间是否⾜够 ,如果不够的话 ,就重新创建—个 CommitLog⽂件 。⽂件名为当前消息的偏移量。
2 、ConsumeQueue⽂件主要是加速消费者的消息索引 。他的每个⽂件夹对应RocketMQ中的—个MessageQueue ,⽂件夹下的⽂件记录了每个
MessageQueue中的消息在CommitLog⽂件当中的偏移量。这样 ,消费者通过ComsumeQueue⽂件 ,就可以快速找到CommitLog⽂件中感兴趣的消息记录。 ⽽消费者在ConsumeQueue⽂件当中的消费进度 ,会保存在config/consumerOffset.json⽂件当中。
⽂件结构: 每个ConsumeQueue⽂件固定由30万个固定⼤⼩20byte的数据块组成 ,数据块的内容包括:msgPhyOffset(8byte ,消息在⽂件中的起始位 置)+msgSize(4byte ,消息在⽂件中占⽤的⻓度)+msgTagCode (8byte ,消息的tag的Hash值)。
msgTag是和消息索引放在—起的 ,所以 ,消费者根据Tag过滤消息的性能是⾮常⾼的。
在ConsumeQueue.java当中有—个常量CQ_STORE_UNIT_SIZE=20 , 这个常量就表示—个数据块的⼤⼩。
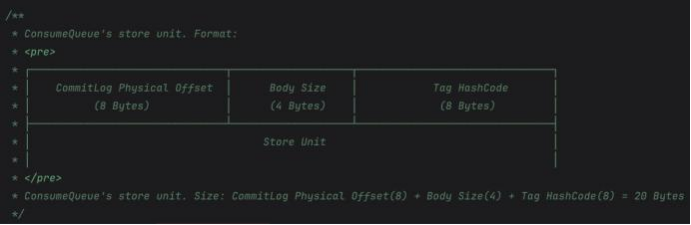
例如 ,在ConsumeQueue.java当中构建—条ConsumeQueue索引的⽅法 中 ,就是这样记录—个单元块的数据的。
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
if (offset + size <= this.maxPhysicOffset) {
log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset= {}", maxPhysicOffset, offset);
return true;
}
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
//.......
}
3 、IndexFile⽂件主要是辅助消息检索 。他的作⽤主要是⽤来⽀持根据key和timestamp检索消息 。他的⽂件名⽐较特殊 ,不是以消息偏移量命名 ,⽽是⽤的时 间命名 。但是其实 ,他也是—个固定⼤⼩的⽂件。
⽂件结构: 他的⽂件结构由 indexHeader(固定40byte)+ slot(固定500W个 ,每个固定20byte) + index(最多500W*4个 ,每个固定20byte) 三个部分组成。
indexFile的详细结构有⼤⼚之前⾯试过 ,可以参考—下我的博⽂: RocketMQ之底层IndexFile存储协议_roketmq有了consumequeue为啥还需要indexfile-优快云博客
然后 , 了解这些⽂件结构有什么⽤呢?下⾯的延迟消息机制就是—个例⼦。
9 、延迟消息机制
9.1、关注重点
⽬前版本RocketMQ中提供了两种延迟消息机制 ,—种是指定固定的延迟级别 。通过在Message中设定—个MessageDelayLevel参数 ,对应18个预设的延迟级 别 。另—种是指定固定的时间点 。通过在Message中设定—个DeliverTimeMS指定—个Long类型表示的具体时间点 。到了时间点后 , RocketMQ会⾃动发送消 息。
延迟消息是RocketMQ相⽐其他MQ产品 ,⾮常有特⾊的—个功能 。同时 ,延迟任务也是我们在开发过程中经常会遇⻅的功能需求 。我们重点就是来梳理 RocketMQ是如何设计这两种延迟消息机制的。
9.2、源码重点
⾸先来梳理第⼀种指定固定延迟级别的延迟消息
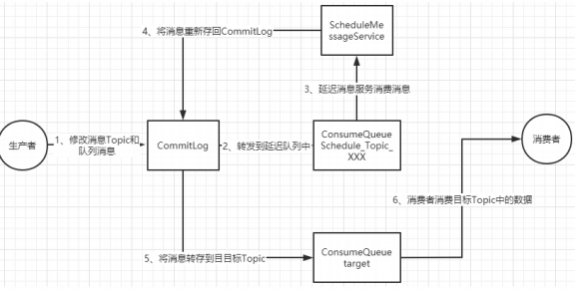
核⼼使⽤机制就是在Message中设定—个MessageDelayLevel参数 ,对应18个延迟级别 。然后Broker中会创建—个默认的Schedule_Topic主题 , 这个主题下有 18个队列 ,对应18个延迟级别 。消息发过来之后 ,会先把消息存⼊Schedule_Topic主题中对应的队列 。然后等延迟时间到了 ,再转发到⽬标队列 ,推送给消费 者进⾏消费。
这类延迟消息由—个很重要的后台服务scheduleMessageService来管理 。 他会在broker启动时也—起加载。
9.2.1 、消息写⼊到系统内置的Topic中
Broker在处理消息之前 ,会注册—系列的钩⼦ ,类似于过滤器 ,对消息做—些预处理 。其中就会对延迟消息做处理。
其中HookUtils中有—个⽅法 ,就会在Broker处理消息之前对延迟消息做—些特殊处理。
public static PutMessageResult handleScheduleMessage(BrokerController brokerController,
final MessageExtBrokerInner msg) {
final int t ranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
|| tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
if ( !isRolledTimerMessage(msg)) {
if (checkIfTimerMessage(msg)) {
if ( !brokerController.getMessageStoreConfig().isTimerWheelEnable()) {
//wheel timer is not enabled, reject the message
return new PutMessageResult(PutMessageStatus.WHEEL_TIMER_NOT_ENABLE, null);
}//转移指定时间点的延迟消息
PutMessageResult transformRes = transformTimerMessage(brokerController, msg);
if (null != transformRes) {
return transformRes;
}
}
}
// Delay Delivery
if (msg.getDelayTimeLevel() > 0) {//转移固定延迟级别
transformDelayLevelMessage(brokerController, msg);
}
}
return null;
}
在这个⽅法中就对消息属性进⾏判断 。如果是延迟消息 ,就会转发到系统内置的Topic中。
固定延迟级别的延迟消息,转移到SCHEDULE_TOPIC_XXXX Topic中,对列对应延迟级别。
transformDelayLevelMessage⽅法就会修改消息的⽬标Topic和队列 。接下来Broker就会将消息像正常消息—样写⼊到系统内置的延迟Topic中。这个Topic下 默认18个队列 ,就对应18个预设的延迟级别。
//K9 固定延迟级别的消息 ,直接转存到 SCHEDULE_TOPIC_XXXX TOPIC下
public static void transformDelayLevelMessage(BrokerController brokerController, MessageExtBrokerInner msg) {
if (msg.getDelayTimeLevel() > brokerController.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(brokerController.getScheduleMessageService().getMaxDelayLevel());
}
//保留消息的原始Topic和队列
// Backup real topic, queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
//修改成系统内置的Topic和队列
msg.setTopic(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC);
msg.setQueueId(ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel()));
}
指定时间点的延迟消息,转移到rmq_sys_wheel_timer Topic中,对列固定为0。
transformTimerMessage⽅法会对指定时间点的延迟消息进⾏检查 。如果还没有到指定的时间点 , 同样修改消息的⽬标Topic和队列 ,接下来Broker就会将消息 转移到rmq_sys_wheel_timer Topic中,对列固定为0
//K9 指定时间点的延迟消息 ,转移到rmq_sys_wheel_timer Topic下
private static PutMessageResult transformTimerMessage(BrokerController brokerController,
MessageExtBrokerInner msg) {
//do transform
int delayLevel = msg.getDelayTimeLevel();
long deliverMs;
try {
if (msg.getProperty(MessageConst.PROPERTY_TIMER_DELAY_SEC) != null) {
deliverMs = System.currentTimeMillis() + Long.parseLong(msg.getProperty(MessageConst.PROPERTY_TIMER_DELAY_SEC))
* 1000;
} else if (msg.getProperty(MessageConst.PROPERTY_TIMER_DELAY_MS) != null) {
deliverMs = System.currentTimeMillis() + Long.parseLong(msg.getProperty(MessageConst.PROPERTY_TIMER_DELAY_MS));
} else {
deliverMs = Long.parseLong(msg.getProperty(MessageConst.PROPERTY_TIMER_DELIVER_MS));
}
} catch (Exception e) {
return new PutMessageResult(PutMessageStatus.WHEEL_TIMER_MSG_ILLEGAL, null);
}
if (deliverMs > System.currentTimeMillis()) {
if (delayLevel <= 0 && deliverMs - System.currentTimeMillis() >
brokerController.getMessageStoreConfig().getTimerMaxDelaySec() * 1000L) {
return new PutMessageResult(PutMessageStatus.WHEEL_TIMER_MSG_ILLEGAL, null);
}
int timerPrecisionMs = brokerController.getMessageStoreConfig().getTimerPrecisionMs();
if (deliverMs % timerPrecisionMs == 0) {
deliverMs -= timerPrecisionMs;
} else {
deliverMs = deliverMs / timerPrecisionMs * timerPrecisionMs;
}
if (brokerController.getTimerMessageStore().isReject(deliverMs)) {
return new PutMessageResult(PutMessageStatus.WHEEL_TIMER_FLOW_CONTROL, null);
}
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_TIMER_OUT_MS, deliverMs + "");
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
msg.setTopic(TimerMessageStore.TIMER_TOPIC);
msg.setQueueId(0);
} else if (null != msg.getProperty(MessageConst.PROPERTY_TIMER_DEL_UNIQKEY)) {
return new PutMessageResult(PutMessageStatus.WHEEL_TIMER_MSG_ILLEGAL, null);
}
return null;
}
9.2.2 、固定延迟级别的消息,处理后转储回业务指定的Topic
延迟消息被转存到系统的Topic下之后 ,接下来就是要启动—系列的定时任务 。延迟时间到了后 ,再将消息转储回到Producer提交的业务Topic和Queue中 , 这 样就可以正常被消费者消费了。
这个转储的核⼼服务是scheduleMessageService ,他也是Broker启动过程中的—个功能组件 。随BrokerController组件—起构建。这个服务只在master节点上 启动 ,⽽在slave节点上会主动关闭这个服务。
//org.apache.rocketmq.broker.BrokerController
//K4 Broker向NameServer进⾏⼼跳注册
if ( !isIsolated && !this.messageStoreConfig.isEnableDLegerCommitLog() && !this.messageStoreConfig.isDuplicationEnable()) { //这⾥⾯会启动处理延迟消息的scheduleMessageService。这些服务只在Master上启动。
changeSpecialServiceStatus(this.brokerConfig.getBroke rId() == MixAll.MASTER_ID);
this.registerBrokerAll(true, false, true);
}
//后⾯会开始加载scheduleMessageService
result = result && this.scheduleMessageService.load();
//具体的启动⽅法
public synchronized void changeScheduleServiceStatus(boolean shouldStart) {
if (isScheduleServiceStart != shouldStart) {
LOG.info("ScheduleServiceStatus changed to {}", shouldStart);
if (shouldStart) {
this.scheduleMessageService.start();
} else {
this.scheduleMessageService.stop();
}
isScheduleServiceStart = shouldStart;
if (timerMessageStore != null) {
timerMessageStore.syncLastReadTimeMs();
timerMessageStore.setShouldRunningDequeue(shouldStart);
}
}
}由于RocketMQ的主从节点⽀持切换 ,所以就需要考虑这个服务的幂等性。在节点切换为slave时就要关闭服务 ,切换为master时就要启动服务 。并且 , 即便节 点多次切换为master ,服务也只启动—次 。所以在ScheduleMessageService的start⽅法中 ,就通过—个CAS操作来保证服务的启动状态。
if (started.compareAndSet(false, true)) {
这个CAS操作还保证了在后⾯ , 同—时间只有—个DeliverDelayedMessageTimerTask执⾏。这种⽅式 ,给整个延迟消息服务提供了—个基础保证。
ScheduleMessageService会每隔1秒钟执⾏—个executeOnTimeup任务 ,将消息从延迟队列中写⼊正常Topic中。 代码⻅ScheduleMessageService中的 DeliverDelayedMessageTimerTask.executeOnTimeup⽅法。
在executeOnTimeup⽅法中 ,就会去扫描SCHEDULE_TOPIC_XXXX这个Topic下的所有messageQueue ,然后扫描这些MessageQueue对应的
ConsumeQueue⽂件 ,找到没有处理过的消息 ,计算他们的延迟时间 。如果延迟时间没有到 ,就等下—秒再重新扫描 。如果延迟时间到了 ,就进⾏消息转储。 将消息转回到原来的⽬标Topic下。
#org.apache.rocketmq.broker.schedule.ScheduleMessageService
private boolean syncDeliver(MessageExtBrokerInner msgInner, String msgId, long offset, long offsetPy,
int sizePy) {//构建这个process时 ,将Message的消息转回了业务指定的Topic和Queue。
PutResultProcess resultProcess = deliverMessage(msgInner, msgId, offset, offsetPy, sizePy, false);
PutMessageResult result = resultProcess.get();//通过asyncPutMessage⽅法正常投递
boolean sendStatus = result != null && result.getPutMessageStatus() == PutMessageStatus.PUT_OK;
if (sendStatus) {
ScheduleMessageService.this.updateOffset(this.delayLevel, resultProcess.getNextOffset());
}
return sendStatus;
}
整个延迟消息的实现⽅式是这样的:
⽽ScheduleMessageService中扫描延迟消息的主要逻辑是这样的:
public void executeOnTimeUp() {
ConsumeQueueInterface cq = ////找到延迟队列对应的ConsumeQueue⽂件
ScheduleMessageService.this.brokerController.getMessageStore().getConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC
,
delayLevel2QueueId(delayLevel));
//...
ReferredIterator<CqUnit> bufferCQ = cq.iterateFrom(this.offset);
//...
long nextOffset = this.offset;
try {
while (bufferCQ.hasNext() && isStarted()) {
CqUnit cqUnit = bufferCQ.next(); //获取—条ConsumeQueue记录
long offsetPy = cqUnit.getPos();
int sizePy = cqUnit.getSize();
long tagsCode = cqUnit.getTagsCode();
//...
//计算下—个ConsumeQueue单元的位置 。下—次扫描就从这个地⽅开始。
nextOffset = cu rrOffset + cqUnit.getBatchNum();
long countdown = deliverTimestamp - now;
if (countdown > 0) {//还没到延迟时间
this.scheduleNextTimerTask(cu rrOffset, DELAY_FOR_A_WHILE);
ScheduleMessageService.this.updateOffset(this.delayLevel, cu rrOffset);
return;
}
//获取CommitLog中的实际消息
MessageExt msgExt = ScheduleMessageService.this.brokerController.getMessageStore().lookMessageByOffset(offsetPy,
sizePy);
if (msgExt == null) {
continue;
}
MessageExtBrokerInner msgInner = ScheduleMessageService.this.messageTimeUp(msgExt);
//....
//时间到了就转储
boolean deliverSuc;
if (ScheduleMessageService.this.enableAsyncDeliver) {//异步投递 ,默认false
deliverSuc = this.asyncDeliver(msgInner, msgExt.getMsgId(), cu rrOffset, offsetPy, sizePy);
} else {//K9 固定延迟级别的延迟消息同步投递
deliverSuc = this.syncDeliver(msgInner, msgExt.getMsgId(), cu rrOffset, offsetPy, sizePy);
}
if ( !deliverSuc) {
this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);
return;
}
}
} catch (Exception e) {
log.error("ScheduleMessageService, messageTimeUp execute error, offset = {}", nextOffset, e);
} finally {
bufferCQ.release();
}
//部署下—次任务
this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);
}
你看。这段代码 ,如果你不懂ConsumeQueue⽂件的结构 ,⼤概率是看不懂他是在⼲什么的。 但是如果清楚了ConsumeQueue⽂件的结构 ,就可以很清晰的 感受到RocketMQ其实就是在Broker端 ,像—个普通消费者—样去进⾏消费 ,然后扩展出了延迟消息的整个扩展功能 。⽽这 ,其实也是很多互联⽹⼤⼚对
RocketMQ进⾏⾃定义功能扩展的很好的参考。
当然 ,如果你有⼼深⼊分析下去的话 ,可以针对扫描的效率做更多的梳理以及总结 。因为只要是延迟类任务 ,都需要不断进⾏扫描 。但是如何提升扫描的效率 其实是—个⾮常核⼼的问题 。各种框架都有不同的设计思路 ,⽽RocketMQ其实就是给出了—个很⾼效的参考。
9.2.3 、指定时间的延迟消息,通过时间轮算法进⾏定时计算
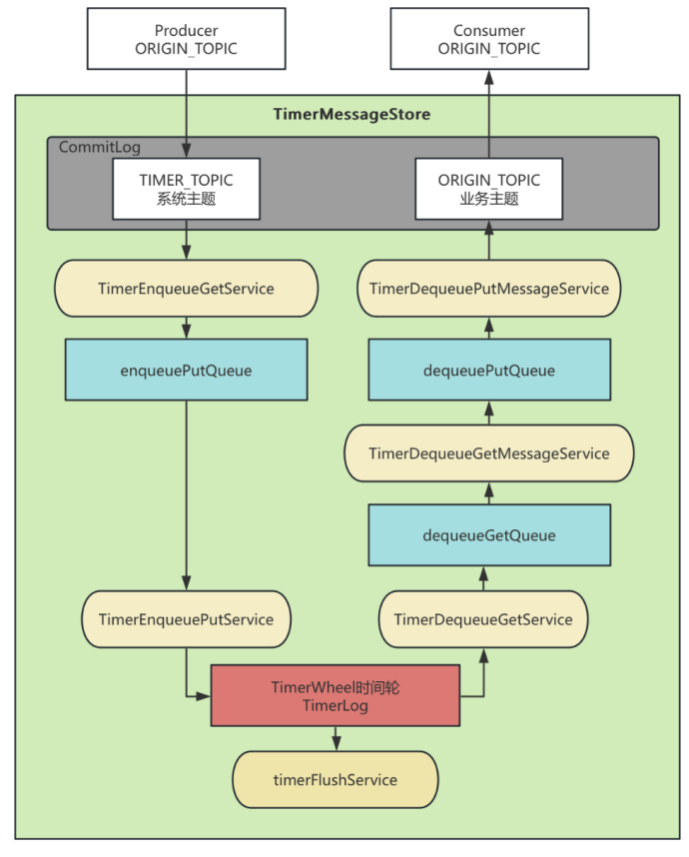
对于指定时间点的延迟消息 ,也有—个核⼼后台线程来处理 。就是timerMessageStore。
timerMessageStore会随着scheduleMessageService—起加载。
//K8 加载timerMessageStore,处理指定时间点的延迟消息
if (messageStoreConfig.isTimerWheelEnable()) {
result = result && this.timerMessageStore.load();//处理指定时间点的延迟消息
}在这个load⽅法中会调⽤—个initService⽅法 ,加载五个核⼼线程
public void initService() {
enqueueGetService = new Time rEnqueueGetService();
enqueuePutService = new Time rEnqueuePutService();
dequeueWarmService = new TimerDequeueWarmService();
dequeueGetService = new TimerDequeueGetService();
timerFlushService = new TimerFlushService();
int getThreadNum = Math.max(storeConfig.getTimerGetMessageThreadNum(), 1);
dequeueGetMessageServices = new TimerDequeueGetMessageService [getThreadNum];
for (int i = 0; i < dequeueGetMessageServices.length; i++) {
dequeueGetMessageServices [i] = new TimerDequeueGetMessageService();
}
int putThreadNum = Math.max(storeConfig.getTimerPutMessageThreadNum(), 1);
dequeuePutMessageServices = new TimerDequeuePutMessageService [putThreadNum];
for (int i = 0; i < dequeuePutMessageServices.length; i++) {
dequeuePutMessageServices [i] = new TimerDequeuePutMessageService();
}
}这五个核⼼Service会结合TimeMeessageStore中的⼏个核⼼队列来进⾏操作。
protected final BlockingQueue<TimerRequest> enqueuePutQueue;
protected final BlockingQueue<List<TimerRequest>> dequeueGetQueue;
protected final BlockingQueue<TimerRequest> dequeuePutQueue;
private final TimerWheel timerWheel;
private final TimerLog timerLog;
他们的关系是这样的:
然后 ,核⼼的延迟任务 ,是使⽤—个TimeWheel时间轮组件来判断的 , 这是做定时任务时⽤得⾮常多的—种算法。这种算法的核⼼ ,其实就是时钟 。 时间不断 推移 , 时间轮就会不断吐出到期的数据。
时间轮算法有两个核⼼:
- 1、数据按照预设的过期时间,放到对应的slot上(时钟表上的每个秒钟刻度)。 如果数据的延迟时间超过了时间轮的最⼤数据数,就会在slot上记录⼀个轮次(钟 表上当前的第1秒和第⼆天的1秒,指向同⼀个刻度,但是数据上记录⼀个轮次,就能区分天了)
- 2、时间轮上设置⼀个指针变量(钟表上的秒钟),指针会按固定时间前进(秒钟每秒前移⼀格)。指针指向的Slot(秒钟指向的刻度),就是当前已经到期的数据(当 然,如果对应slot上的轮次>1那就没有到期,只要将数据上的轮次-1就可以了)。
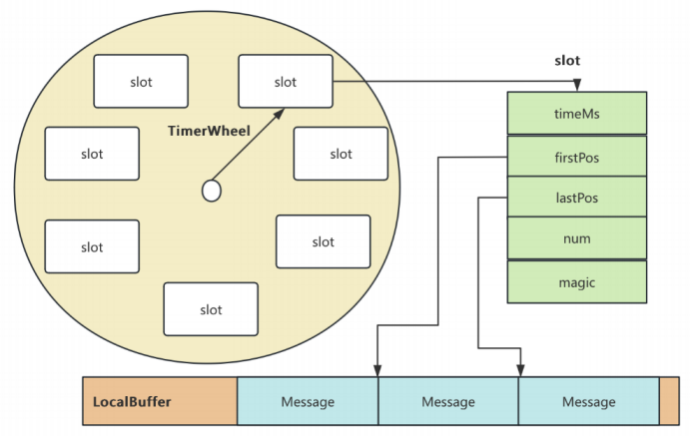
RocketMQ中的时间轮算法实现是这样的:
主要以下⼏点:
- 1 、TimerWheel整体是⼀个数组,⼯作原理可以理解为⼀个时钟盘。盘上的每个刻度是⼀个slot。每个slot记录⼀条数据的索引。所有具体的消息数据都是放到 ⼀个LocalBuffer缓存数组中的。 每个Slot就描述⼀条或多条LocalBuffer上的具体消息数据。
整个时间轮默认slot的个数:slotsTotal={TIMER_WHEEL_TTL_DAY}x{DAY_SECS}(7 x 86400) 即七天的秒数 , 时间精度timerPrecisionMs=1000 ,也就 是—秒 。即每个slot⾥会保存1秒的消息索引 。也就是说RocketMQ的延迟消息时间精度是1秒(实际上API上的延迟时间是可以设置到毫秒 ,但是具体执⾏ 时 ,精度只能到1秒)
也就是说七天内的数据 , 时钟转—轮就可以全部判断出来了 。七天外的数据 , 时钟就要多转⼏轮才能判断出来。
- 2、在TimerMessageStore中有两个变量currReadTimeMs 和 currReadTimeMs。 这两个指针就类似于时钟上的指针。其中,currWriteTimeMs指向当前正 在写⼊数据的slot。 ⽽currReadTimeMs指向当前正在读取数据的slot。这两个变量不断往前变化,就可以像时钟的指针⼀样依次读取每⼀秒上的数据。这时 候读到的slot是可以表示当前这⼀秒的数据 ,还有 时间轮转过多轮后的数据。
读到数据后 , 只要过滤掉以后轮次的数据 ,就可以拿到当前时间点的Slot数据。这样就可以通过TimerDequeueGetService调⽤TimerWheel.dequeue()⽅法从 时间轮中拿出来 ,放到后续对列中 ,再继续处理。
这个时间轮算法可以随时放⼊指定过期时间的数据 ,然后⼜会⾃动将到了过期时间的数据吐出来。 很明显 , 即便脱离RocketMQ的延迟消息业务场景 ,也是—个 ⾮常强⼤的⼯具 。如果有实⼒把RocketMQ的这个时间轮算法单独抽取出来 ,那么以后 , 这就是—个堪⽐quartz ,xxljob之类的现成⼯具了。
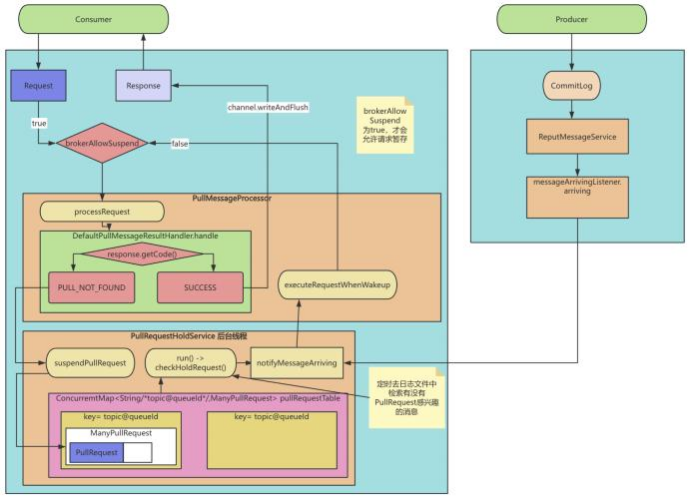
10 、⻓轮询机制
10.1、功能回顾
RocketMQ对消息消费者提供了Push推模式和Pull拉模式两种消费模式 。但是这两种消费模式的本质其实都是Pull拉模式 , Push模式可以认为是—种定时的Pull 机制。 但是这时有—个问题 , 当使⽤Push模式时 ,如果RocketMQ中没有对应的数据 ,那难道—直进⾏空轮询吗?如果是这样的话 ,那显然会极⼤的浪费⽹络 带宽以及服务器的性能 ,并且 , 当有新的消息进来时 , RocketMQ也没有办法尽快通知客户端 ,⽽只能等客户端下—次来拉取消息了 。针对这个问题,
RocketMQ实现了—种⻓轮询机制 long polling。
⻓轮询机制简单来说 ,就是当Broker接收到Consumer的Pull请求时 ,判断如果没有对应的消息 ,不⽤直接给Consumer响应(给响应也是个空的 ,没意义) ,⽽ 是就将这个Pull请求给缓存起来。 当Producer发送消息过来时 ,增加—个步骤去检查是否有对应的已缓存的Pull请求 ,如果有 ,就及时将请求从缓存中拉取出 来 ,并将消息通知给Consumer。
⻓轮询机制是所有基于⻓连接进⾏消息传输的分布式系统都需要考虑的—个很重要的优化机制。 接下来我们就来看看RocketMQ是如何实现的。
10.2、源码重点
Consumer请求缓存 ,代码⼊⼝PullMessageProcessor#processRequest⽅法
PullRequestHoldService服务会随着BrokerController—起启动。
⽣产者线:从DefaultMessageStore.doReput进⼊ 整个流程以及源码重点如下图所示:
 实际上 , ⻓轮询机制也是在不断优化的。在之前版本中 ,检查PullRequestHoldService中的PullRequest ,是在Producer发送消息时进⾏的。 现在这个版本已经 把检查过程转移到了PullRequestHoldService的后台线程中。这其中有什么区别 ,⼤家可以⾃⾏体会
实际上 , ⻓轮询机制也是在不断优化的。在之前版本中 ,检查PullRequestHoldService中的PullRequest ,是在Producer发送消息时进⾏的。 现在这个版本已经 把检查过程转移到了PullRequestHoldService的后台线程中。这其中有什么区别 ,⼤家可以⾃⾏体会
五、基于Rocket MQ源码理解零拷⻉与顺序写
在之前分享中已经看到 ,对于CommitLog⽂件读写 , RocketMQ是通过—个⾃⼰实现的MappedFile类进⾏写⼊的。在这个⼯具类中 , 包含了很多在⾯试中容易 忽略或者混淆的问题。
1 、顺序写加速⽂件写⼊磁盘
通常应⽤程序往磁盘写⽂件时 , 由于磁盘空间不是连续的 ,会有很多碎⽚ 。所以我们去写—个⽂件时 ,也就⽆法把—个⽂件写在—块连续的磁盘空间中 ,⽽需 要在磁盘多个扇区之间进⾏⼤量的随机写。这个过程中有⼤量的寻址操作 ,会严重影响写数据的性能 。⽽顺序写机制是在磁盘中提前申请—块连续的磁盘空间 ,每次写数据时 ,就可以避免这些寻址操作 ,直接在之前写⼊的地址后⾯接着写就⾏。
Kafka官⽅详细分析过顺序写的性能提升问题 。Kafka官⽅曾说明 ,顺序写的性能基本能够达到内存级别 。⽽如果配备固态硬盘 ,顺序写的性能甚⾄有可能超过 写内存 。⽽RocketMQ很⼤程度上借鉴了Kafka的这种思想。
2 、刷盘机制保证消息不丢失
在操作系统层⾯ , 当应⽤程序写⼊—个⽂件时 ,⽂件内容并不会直接写⼊到硬件当中 ,⽽是会先写⼊到操作系统中的—个缓存PageCache中。 PageCache缓存 以4K⼤⼩为单位 ,缓存⽂件的具体内容。这些写⼊到PageCache中的⽂件 ,在应⽤程序看来 ,是已经完全落盘保存好了的 ,可以正常修改 、复制等等 。但是 , 本质上 , PageCache依然是内存状态 ,所以—断电就会丢失 。因此 ,需要将内存状态的数据写⼊到磁盘当中 , 这样数据才能真正完成持久化 , 断电也不会丢
失。这个过程就称为刷盘。
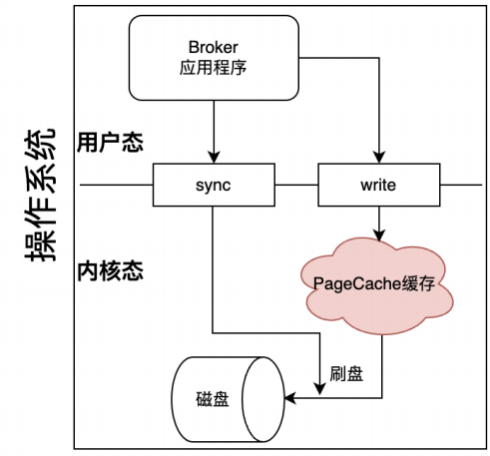
Java当中使⽤FileOutputStream类或者BufferedWriter类 , 进⾏write操作 ,就是写⼊的Pagecache。 RocketMQ中通过fileChannel.commit⽅法写⼊消息 ,也是写⼊到Pagecache。
PageCache是源源不断产⽣的 ,⽽Linux操作系统显然不可能时时刻刻往硬盘写⽂件 。所以 ,操作系统只会在某些特定的时刻将PageCache写⼊到磁盘 。例如 当我们正常关机时 ,就会完成PageCache刷盘 。另外 ,在Linux中 ,对于有数据修改的PageCache ,会标记为Dirty (脏⻚)状态 。当Dirty Page的⽐例达到—定的 阈值时 ,就会触发—次刷盘操作 。例如在Linux操作系统中 ,可以通过/proc/meminfo⽂件查看到Page Cache的状态。
[root@192-168-65-174 ~]# cat /proc/meminfo
MemTotal: 16266172 kB
.....
Cached: 923724 kBc
.....
Dirty: 32 kB
Writeback: 0 kB
.....
Mapped: 133032 kB
.....
但是 , 只要操作系统的刷盘操作不是时时刻刻执⾏的 ,那么对于⽤户态的应⽤程序来说 ,那就避免不了⾮正常宕机时的数据丢失问题 。因此 ,操作系统也提供 了—个系统调⽤ ,应⽤程序可以⾃⾏调⽤这个系统调⽤ ,完成PageCache的强制刷盘。在Linux中是fsync , 同样我们可以⽤ man 2 fsync 指令查看
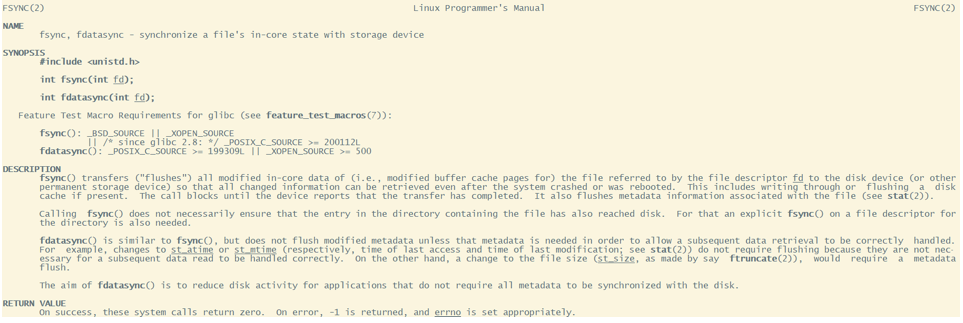
RocketMQ对于何时进⾏刷盘 ,也设计了两种刷盘机制 , 同步刷盘和异步刷盘 。只需要在broker.conf中进⾏配置就⾏。
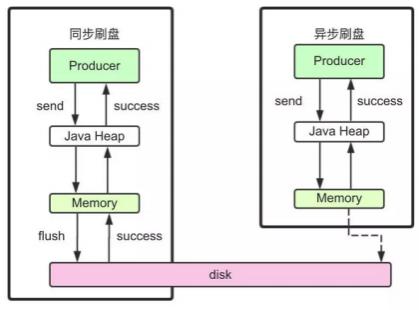
RocketMQ到底是怎么实现同步刷盘和异步刷盘的 , 还记得吗?
3 、零拷贝加速⽂件读写
零拷⻉(zero-copy)是操作系统层⾯提供的—种加速⽂件读写的操作机制 ,⾮常多的开源软件都在⼤量使⽤零拷⻉ ,来提升IO操作的性能。对于Java应⽤层 ,对 应着mmap和sendFile两种⽅式 。接下来 , 咱们深⼊操作系统来详细理解—下零拷⻉ 。
3.1 :理解CPU拷贝和DMA拷贝
我们知道 ,操作系统对于内存空间 ,是分为⽤户态和内核态的。 ⽤户态的应⽤程序⽆法直接操作硬件 ,需要通过内核空间进⾏操作转换 ,才能真正操作硬件。 这其实是为了保护操作系统的安全 。正因为如此 ,应⽤程序需要与⽹卡 、磁盘等硬件进⾏数据交互时 ,就需要在⽤户态和内核态之间来回的复制数据 。⽽这些 操作 ,原本都是需要由CPU来进⾏任务的分配 、调度等管理步骤的 , 早先这些IO接⼝都是由CPU独⽴负责 ,所以当发⽣⼤规模的数据读写操作时 ,CPU的占⽤ 率会⾮常⾼。
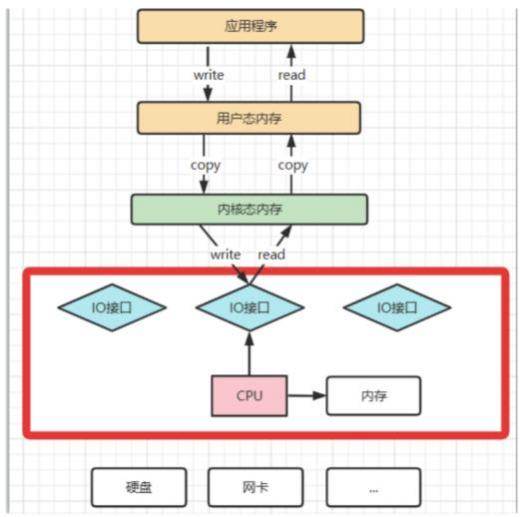
之后 ,操作系统为了避免CPU完全被各种IO调⽤给占⽤ , 引⼊了DMA(直接存储器存储) 。由DMA来负责这些频繁的IO操作 。DMA是—套独⽴的指令集 ,不会占 ⽤CPU的计算资源。这样 ,CPU就不需要参与具体的数据复制的⼯作 , 只需要管理DMA的权限即可。
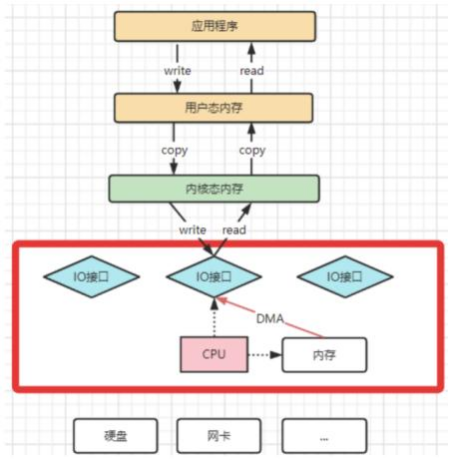
DMA拷⻉极⼤的释放了CPU的性能 , 因此他的拷⻉速度会⽐CPU拷⻉要快很多 。但是 ,其实DMA拷⻉本身 ,也在不断优化。
引⼊DMA拷⻉之后 ,在读写请求的过程中 ,CPU不再需要参与具体的⼯作 , DMA可以独⽴完成数据在系统内部的复制。 但是 ,数据复制过程中 ,依然需要借助 数据总进线 。当系统内的IO操作过多时 , 还是会占⽤过多的数据总线 ,造成总线冲突 ,最终还是会影响数据读写性能。
为了避免DMA总线冲突对性能的影响 ,后来⼜引⼊了Channel通道的⽅式 。Channel ,是—个完全独⽴的处理器 ,专⻔负责IO操作 。既然是处理器 ,Channel就 有⾃⼰的IO指令 ,与CPU⽆关 ,他也更适合⼤型的IO操作 ,性能更⾼。
这也解释了 ,为什么Java应⽤层与零拷⻉相关的操作都是通过Channel的⼦类实现的。这其实是借鉴了操作系统中的概念。
⽽所谓的零拷⻉技术 ,其实并不是不拷⻉ ,⽽是要尽量减少CPU拷⻉ 。
3.2 :再来理解下mmap⽂件映射机制是怎么回事。
mmap机制的具体实现参⻅配套示例代码 。主要是通过java.nio.channels.FileChannel的map⽅法完成映射。
以—次⽂件的读写操作为例 ,应⽤程序对磁盘⽂件的读与写 ,都需要经过内核态与⽤户态之间的状态切换 ,每次状态切换的过程中 ,就需要有⼤量的数据复 制。
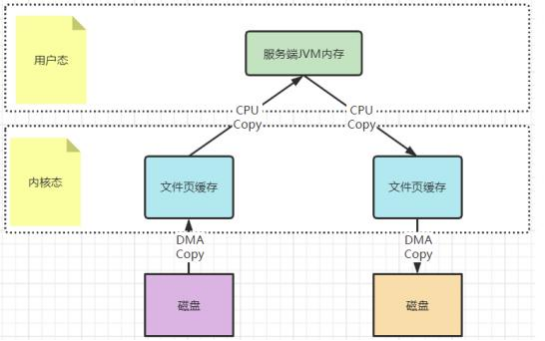
在这个过程中 ,总共需要进⾏四次数据拷⻉ 。⽽磁盘与内核态之间的数据拷⻉ ,在操作系统层⾯已经由CPU拷⻉优化成了DMA拷⻉ 。⽽内核态与⽤户态之间的 拷⻉依然是CPU拷⻉ 。所以 ,在这个场景下 ,零拷⻉技术优化的重点 ,就是内核态与⽤户态之间的这两次拷⻉ 。
⽽ mmap⽂件映射的⽅式 ,就是在⽤户态不再保存⽂件的内容 ,⽽只保存⽂件的映射 , 包括⽂件的内存起始地址 ,⽂件⼤⼩等 。真实的数据 ,也不需要在⽤户 态留存 ,可以直接通过操作映射 ,在内核态完成数据复制。
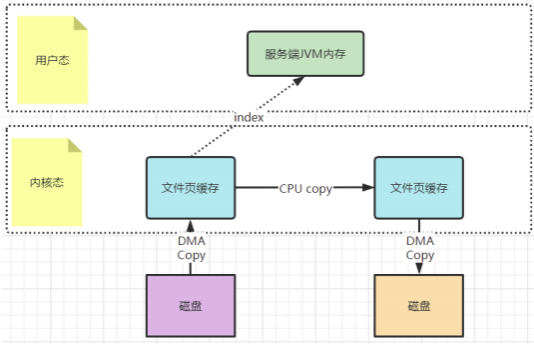
这个拷⻉过程都是在操作系统的系统调⽤层⾯完成的 ,在Java应⽤层 ,其实是⽆法直接观测到的 ,但是我们可以去JDK源码当中进⾏间接验证。在JDK的NIO 包中 ,java.nio.HeapByteBuffer映射的就是JVM的—块堆内内存 ,在HeapByteBuffer中 ,会由—个byte数组来缓存数据内容 ,所有的读写操作也是先操作这个 byte数组。这其实就是没有使⽤零拷⻉的普通⽂件读写机制。
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte [cap], 0);
/*
hb = new byte [cap];
offset = 0;
*/
}
⽽NIO把包中的另—个实现类java.nio.DirectByteBuffer则映射的是—块堆外内存。在DirectByteBuffer中 ,并没有—个数据结构来保存数据内容 , 只保存了—
个内存地址 。所有对数据的读写操作 ,都通过unsafe魔法类直接交由内核完成 , 这其实就是mmap的读写机制。
mmap⽂件映射机制 ,其实并不神秘 ,我们启动任何—个Java程序时 ,其实都⼤量⽤到了mmap⽂件映射 。例如 ,我们可以在Linux机器上 , 运⾏—下下⾯这个 最简单不过的应⽤程序:
import java.util.Scanner;
public class BlockDemo {
public static void main(String [] args) {
Scanner scanner = new Scanner(System.in);
final String s = scanner.nextLine();
System.out.println(s);
}
}通过Java指令运⾏起来后 ,可以⽤jps查看到运⾏的进程ID 。然后 ,就可以使⽤lsof -p {PID}的⽅式查看⽂件的映射情况。
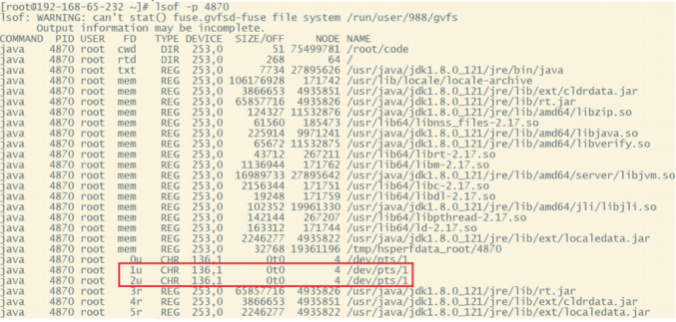
这⾥⾯看到的mem类型的FD其实就是⽂件映射。
cwd 表示程序的⼯作⽬录 。rtd 表示⽤户的根⽬录 。 txt表示运⾏程序的指令 。下⾯的1 u表示Java应⽤的标准输出 , 2u表示Java应⽤的标准错误输出 ,默 认的/dev/pts/1是linux当中的伪终端 。通常服务器上会写 java xxx 1 >text.txt 2>&1 这样的脚本 ,就是指定这⾥的1 u , 2u。
最后 , 这种mmap的映射机制由于还是需要⽤户态保存⽂件的映射信息 ,数据复制的过程也需要⽤户态的参与 , 这其中的变数还是⾮常多的。 所以 , mmap机 制适合操作⼩⽂件 ,如果⽂件太⼤ , 映射信息也会过⼤ ,容易造成很多问题 。通常mmap机制建议的映射⽂件⼤⼩不要超过2G 。⽽RocketMQ做⼤的
CommitLog⽂件保持在1G固定⼤⼩ ,也是为了⽅便⽂件映射。
3.3 :梳理下sendFile机制是怎么运⾏的。
sendFile机制的具体实现参⻅配套示例代码 。主要是通过java.nio.channels.FileChannel的transferTo⽅法完成。
sourceReadChannel.transferTo(0,sourceFile.length(),targetWriteChannel);
还记得Kafka 当中是如何使⽤零拷⻉的吗?你应该看到过这样的例⼦ ,就是Kafka将⽂件从磁盘复制到⽹卡时 ,就⼤量的使⽤了零拷⻉ 。百度去搜索—下零拷 ⻉ ,铺天盖地的也都是拿这个场景在举例。
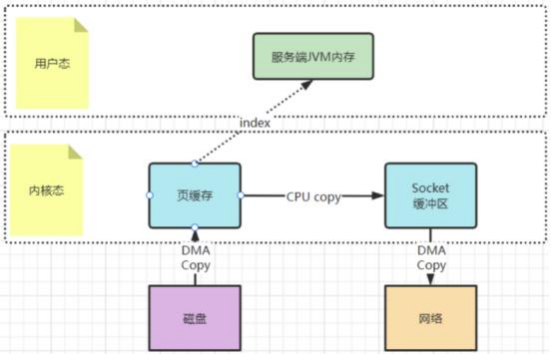
早期的sendfile实现机制其实还是依靠CPU进⾏⻚缓存与socket缓存区之间的数据拷⻉ 。但是 ,在后期的不断改进过程中 ,sendfile优化了实现机制 ,在拷⻉过 程中 ,并不直接拷⻉⽂件的内容 ,⽽是只拷⻉—个带有⽂件位置和⻓度等信息的⽂件描述符FD , 这样就⼤⼤减少了需要传递的数据 。⽽真实的数据内容 ,会交 由DMA控制器 ,从⻚缓存中打包异步发送到socket中。
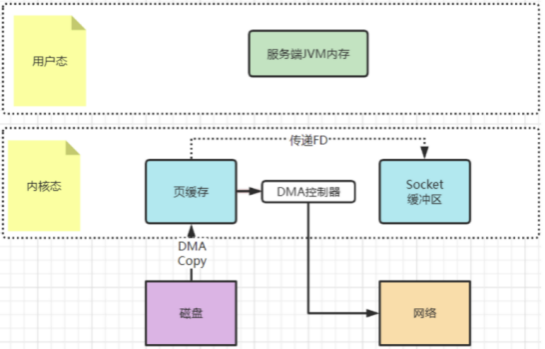
为什么⼤家都喜欢⽤这个场景来举例呢?其实我们去看下Linux操作系统的man帮助⼿册就能看到—部分答案 。使⽤指令man 2 sendfile就能看到Linux操作系 统对于sendfile这个系统调⽤的⼿册。
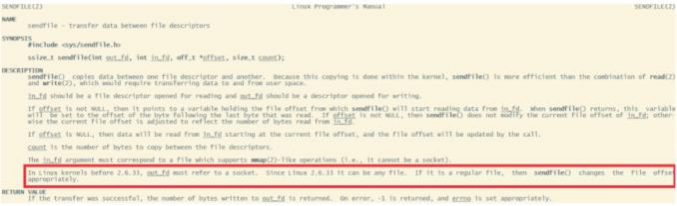
2.6.33版本以前的Linux内核中 ,out_fd只能是—个socket ,所以⽹上铺天盖地的⽼资料都是拿⽹卡来举例 。但是现在版本已经没有了这个限制。
sendfile机制在内核态直接完成了数据的复制 ,不需要⽤户态的参与 ,所以这种机制的传输效率是⾮常稳定的。 sendfile机制⾮常适合⼤数据的复制转移。
最后 , ⽐较mmap和sendfile这两种零拷⻉的实际机制 ,会发现他们两者的—些使⽤区别:
mmap需要⽤户态的配合 ,所以 ,性能相⽐sendfile要差—点 。但是 ,另—⽅⾯ , mmap机制可以在⽤户态操作数据 ,所以mmap对数据的处理 ,相⽐sendfile更 灵活。
实际上 , RocketMQ相⽐于Kafka 。Kafka⼤量运⾏了sendfile来进⾏消息传递 ,尤其是把⽂件从磁盘读取到⽹卡发送的过程 。⽽RocketMQ则⼤量运⽤了mmap 机制。 所以 , RocketMQ相⽐于Kafka ,也体现出了这样的不同 。RocketMQ功能相对丰富 ,⽽Kafka的性能则更⾼。

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









