




 本文详细介绍了在Tableau中如何进行数据分层和分组,包括视图标题分组、视图标记分组和维度字段分组的方法,以帮助用户更好地组织和分析数据。
本文详细介绍了在Tableau中如何进行数据分层和分组,包括视图标题分组、视图标记分组和维度字段分组的方法,以帮助用户更好地组织和分析数据。
在tableau中,数据分层与数据分组常用来对维度字段之间或者维度字段内部进行数据的重新组织。本节记录要点:
- 数据分层
- 数据分组
数据分层
数据分层是一种维度字段之间自上而下的组织形式,tableau中默认包含了一些特殊字段的分层结构,比如日期、地理角色。以日期字段为例,一个标准的日期字段有“年、月、日”三个时间值,如“2018-08-28”,tableau将该日期默认表现为“年-季-月-天”的分层结构。

尽管tableau内置了几种分层结构,但在实际应用中,仍然存在大量需要创建分层结构的场景,以便于数据分析时对数据进行上钻或下钻。创建数据分层结构的具体步骤如下。
1.在数据窗口的维度区域,选择需要创建分层结构的多个字段。

2.根据需要,对创建的分层结构字段名称进行重命名,并按照由大到小、由上至下的原则调整字段顺序。
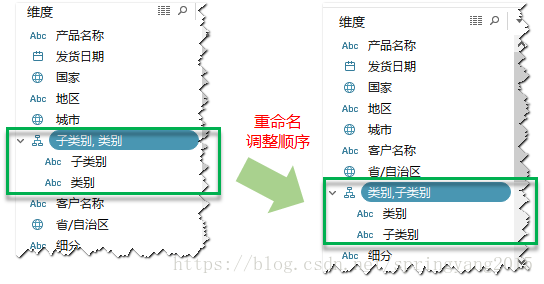
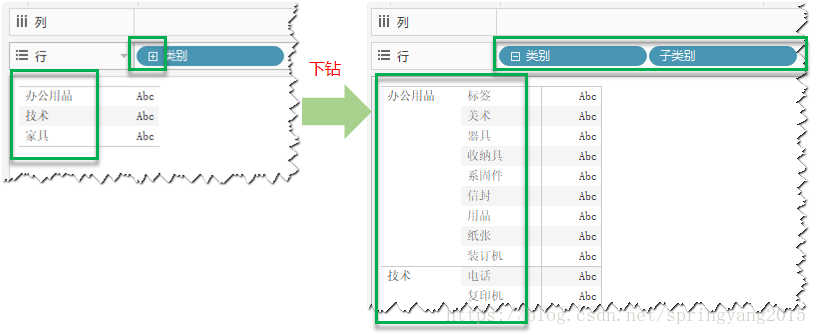
3.完成分层结构创建,并将创建的字段拖放到列行功能区,在视图中观察使用分层结构。
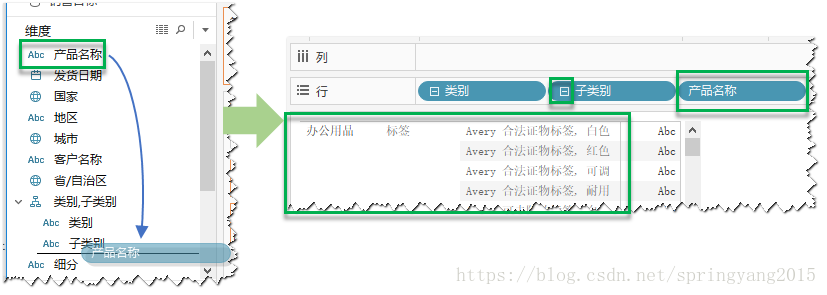
4.如果还要进一步扩展分层结构,只需在维度区域中,将待扩展的字段直接拖放到分层结构字段中,并选择好适合的位置即可。
数据分组
在tableau中,“组”是维度字段成员的组合。通过分组,可以对维度字段成员的重新组合。如,假设维度区域有一个“学科”字段,该字段有语文、数学、化学、物理、英语五个成员,可以通过分组,将数学、化学、物理分归为“理科”,这样就能够对理科情况进行分析。
在实际操作中,可以通过视图标题、视图标记、维度字段进行直接分组。
视图标题分组
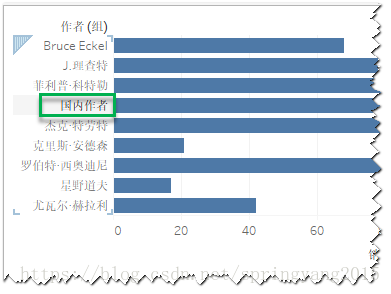
1.在视图中,直接在字段标题选中需要分在一组的维度成员,然后点击通过选择“组”选项,实现分组创建。这里,选中国内作者,将他们分在一组。
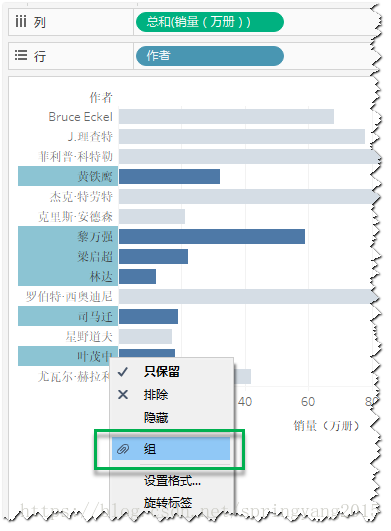
2.视图中默认的组名称是组成员的组合,可以对其重命名,以便更贴近所分的组的特点。这里,将分组名称重命名为“国内作者”。
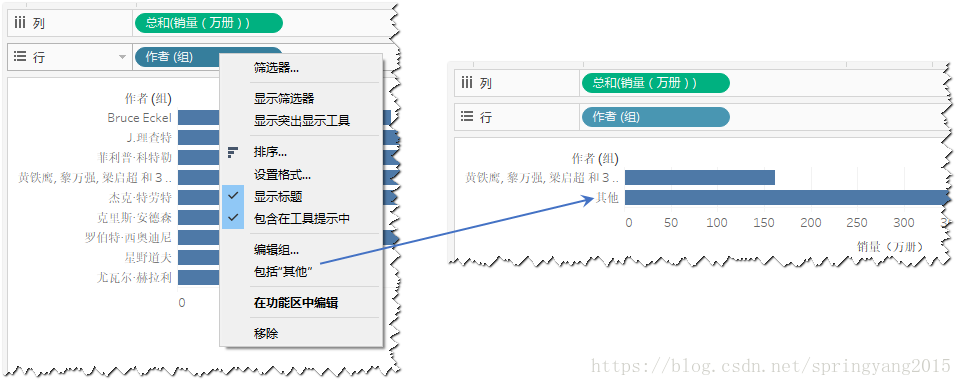
3.在“列行”功能区的分组字段上,通过右键菜单中的“包括 ‘其他’”选项,可以将未分组成员合并为“其他”,将他们视作一个整体进行分析。
视图标记分组
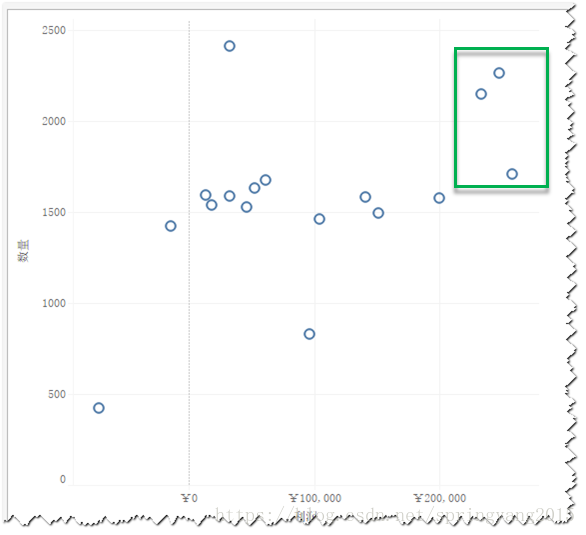
1.直接在视图标记中选中需要分在一组的成员,通过右键菜单创建分组。这里,建立维度为“子类别”,度量为“数量”和“利润”的散点图,并将价格低、销量低的子类别分为一组。
2.创建分组后,tableau默认将没有被选中的成员归为“其他”组,并与创建的分组用颜色进行了区分。同样,也可以根据需要对组名称进行重命名。
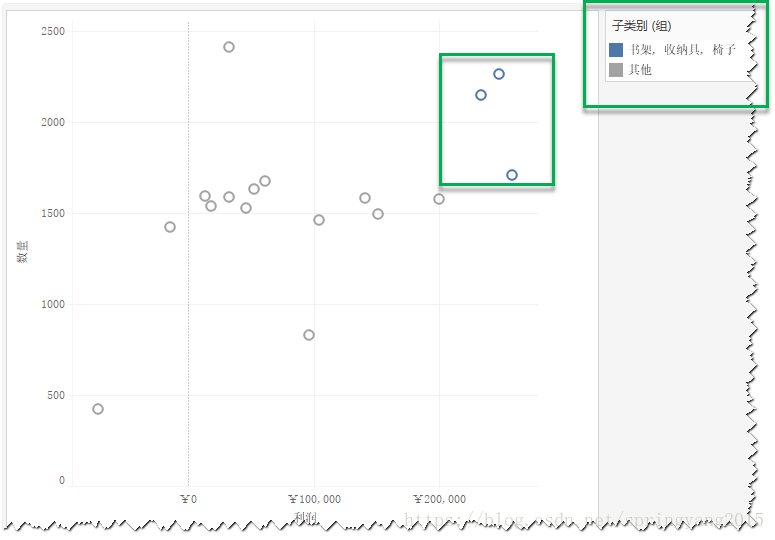
3.如果视图具有多个维度,如上面视图在已有的“子类别”维度基础上,再增加一个“地区”维度,那么选中视图标记并进行分组的时候,会有三个选项供选择,分别是“所有维度”、“地区”和“子类别”。
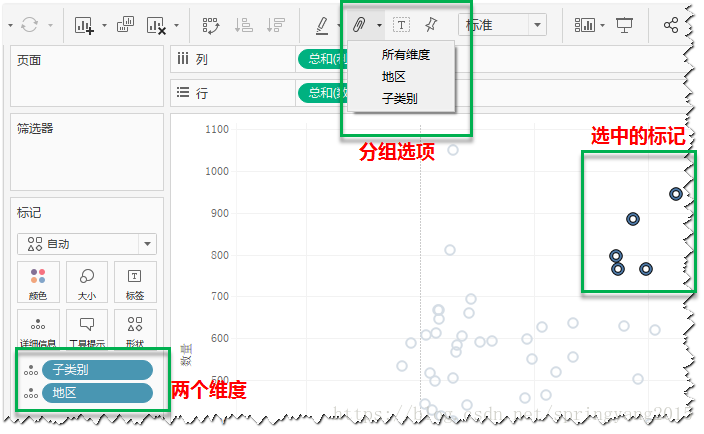
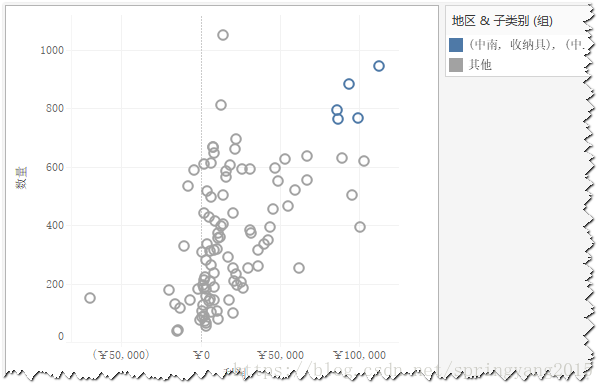
4.如果选择“所有维度”,则被选中的5个标记将分在一组,其余标记将被分在“其他”组。
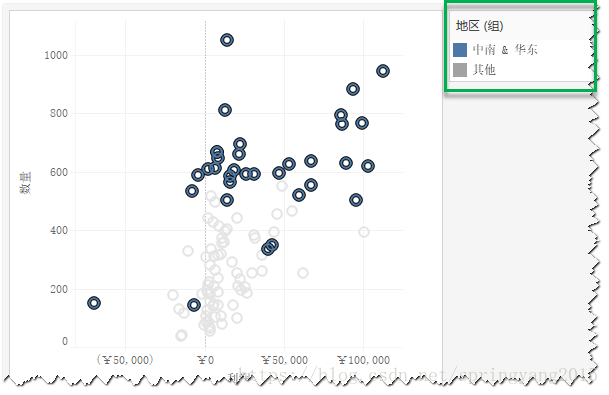
5.如果选择“地区”,则符合5个标记所涉及地区(华东和中南)的所有标记都将分在一组,其余标记将被分在“其他”组。
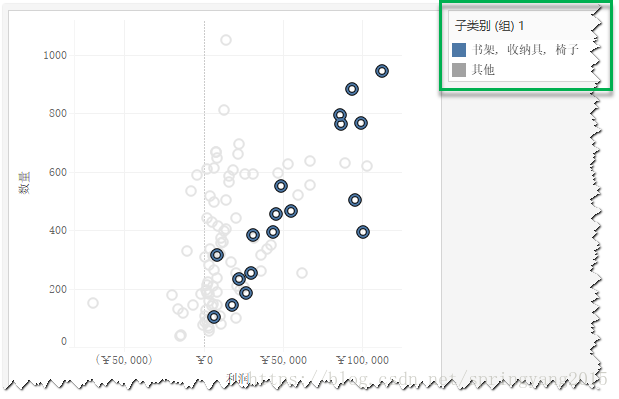
6.如果选择“子类别”,则符合5个标记所涉及子类别(书架、收纳具和椅子)的所有标记都将分在一组,其余标记将被分在“其他”组。
维度字段分组
在数据窗口的维度区域,在选择创建分组的字段上,通过右键菜单进入分组界面,并在该界面中选择相应的维度字段成员进行分组和重命名。如果字段中的成员较多,并且需要对该字段成员创建多个分组,这种方式分组会更有效。
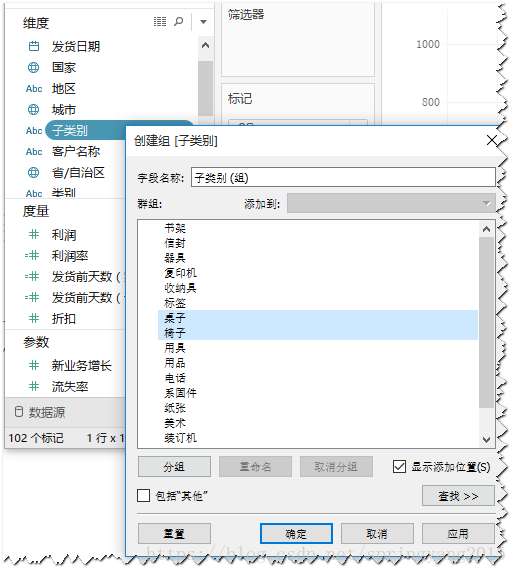
分组是重组维度字段成员的常用方式之一,不论通过何种方式创建组,在数据窗口的维度区域,都会添加一个新的组字段,该字段可以向其他维度字段一样使用,比如拖放到“列行”功能区、“标记”卡、“筛选器”卡等。但分组结果不能用于计算,即“组”不能出现在公式中。



















 961
961





 到【灌水乐园】发言
到【灌水乐园】发言







