







摘要
NEON 指令可执行并行数据处理,NEON是一种SIMD架构的协处理器, 简单来说就是将多个操作数打包在大型寄存器中、在一条指令下同时操作多个操作数的指令集
一、简介
1. SISD
Single instruction single data ---SISD, 即每条指令处理一条数据。
exam: add r1, r6
2. SIMD
Single instruction multiple data(vector mode)--SIMD Single instruction multiple data(packeddata mode)---SIMD 即每条指令处理vector或者packed数据。
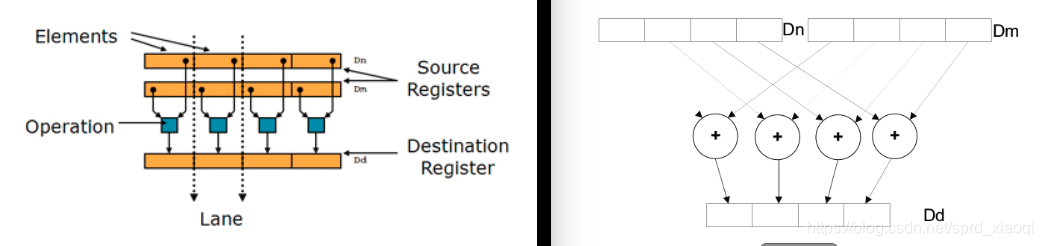
二、使用方式
1. intrinsics 内联
简单 易维护和移植。
效率相对较低 不必考虑超出寄存器使用数量。
2. assemble汇编
复杂 移植较难。
效率高 寄存器必须人工合理分。
三、数据类型操作函数
1. 数据类型
格式: type size X num_t
type:数据类型,int、uint、float
size:每个元素的数据长度,整型长度为8、16、32、64,浮点型为32。
num:元素个数,在NEON中,每个寄存器都是64位或者128位,即size与num的乘积必须为64或128。

如: uint32x4_t为由4个32位无符号整型组成的128位寄存器
结构体举例 : uint16x4x2_t reg1; 使用: reg.val[0] = 1; reg.val[1] = 2;
2. 操作函数
指令的一般格式为:v op dt_type
v:NEON函数的标记符;
op:操作,add、sub、and等;
dt:表示所操作寄存器等长度,当寄存器为64位,dt为空;当寄存器为128位,dt为q;
如果源向量和目标向量长度一致都为128位,dt为q。
如果目标向量长度比源数向量长度大,且源向量长度都为 64 位、目标向量长度为 128 位,dt为 l。
如果多个源向量长度不一致且都不大于目标向量长度(一个源向量长度为 64 位,另一个为 128 位,目标向量长度为 128 位),dt为 w。
type:对应数据类型的缩写,比如u8(uint8)、s16(int16)、f32(float32)
uint8x16_t vaddq_u8(uint 8x16_t __a, uint8x16_t __b);
3. 编写流程
A. 定义Neon向量
B. 读取数据
C. 处理数据
D. 回写数据
四、优化例子
1. arrary相加
假设数组的长度是4的倍数,int32x4_t单词加载4个数据,运算完成后,回写dst。
// C version
void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
}
// NEON version
void add_float_neon1(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}2. 官方exam
vget_low_u32: VGET_LOW returns the lower half of the 128-bit input vector. The output is a 64-bit vector that has half the number of elements as the input vector.
vget_lane_u32: Moving results back to normal C variables
void add_arr0()
{
unsigned int acc=0;
for (i=0; i<8;i+=1)
{
acc+ = array[i]; // a + b + c + d + e + f + g + h
}
}
void add_arr1()
{
unsigned int acc1 = 0;
unsigned int acc2 = 0;
unsigned int acc3 = 0;
unsigned int acc4 = 0;
for (int i = 0; i < 8; i+=4)
{
acc1+ = array[i]; // (a, e)
acc2+ = array[i+1]; // (b, f)
acc3+ = array[i+2]; // (c, g)
acc4+ = array[i+3]; // (d, h)
}
acc1 += acc2; // (a + e) + (b + f)
acc3+ = acc4; // (c + g) + (d + h)
acc1+ = acc3; // ((a + e) + (b + f))+((c + g) + (d + h))
return acc1;
}
uint32_t vector_add_of_n(uint32_t* ptr, uint32_t items)
{
uint32_t result,* i;
uint32x2_t vec64a, vec64b;
uint32x4_t vec128 = vdupq_n_u32(0); // clear accumulators
for (i = ptr; i<(ptr+(items/4)); i+=4)
{
uint32x4_t temp128 = vld1q_u32(i); // load four 32-bit values
vec128 = vaddq_u32(vec128, temp128); // add 128-bit vectors
}
vec64a = vget_low_u32(vec128); // split 128-bit vector
vec64b = vget_high_u32(vec128); // into two 64-bit vectors
vec64a = vadd_u32 (vec64a, vec64b); // add 64-bit vectors together
result = vget_lane_u32(vec64a, 0); // extract lanes and
result += vget_lane_u32(vec64a, 1); // add together scalars
return result;
}
总结
noen的入门简介

















 5783
5783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









