



文章目录
Workflow & Agent
Anthropic发布的指南中将agent分为两种范式,一种是预定义工作路径的工作流,另一种是可以自主动态处理任务的agent。工作流包括提示链、路由、并行化、协调者-工作者、评估者-优化者五种设计模式。
工作流(workflow)和智能体(agent)的区别:工作流是通过预定义的代码路径编排LLM和工具的系统;agent则是LLM动态指导自己的工作流程和工具使用以完成任务的系统。
对于定义明确的任务,工作流提供可预测性和一致性,而当大模型需要处理大规模灵活性的决策任务时,构建agent是更好的选择。
构建模块:增强型LLM
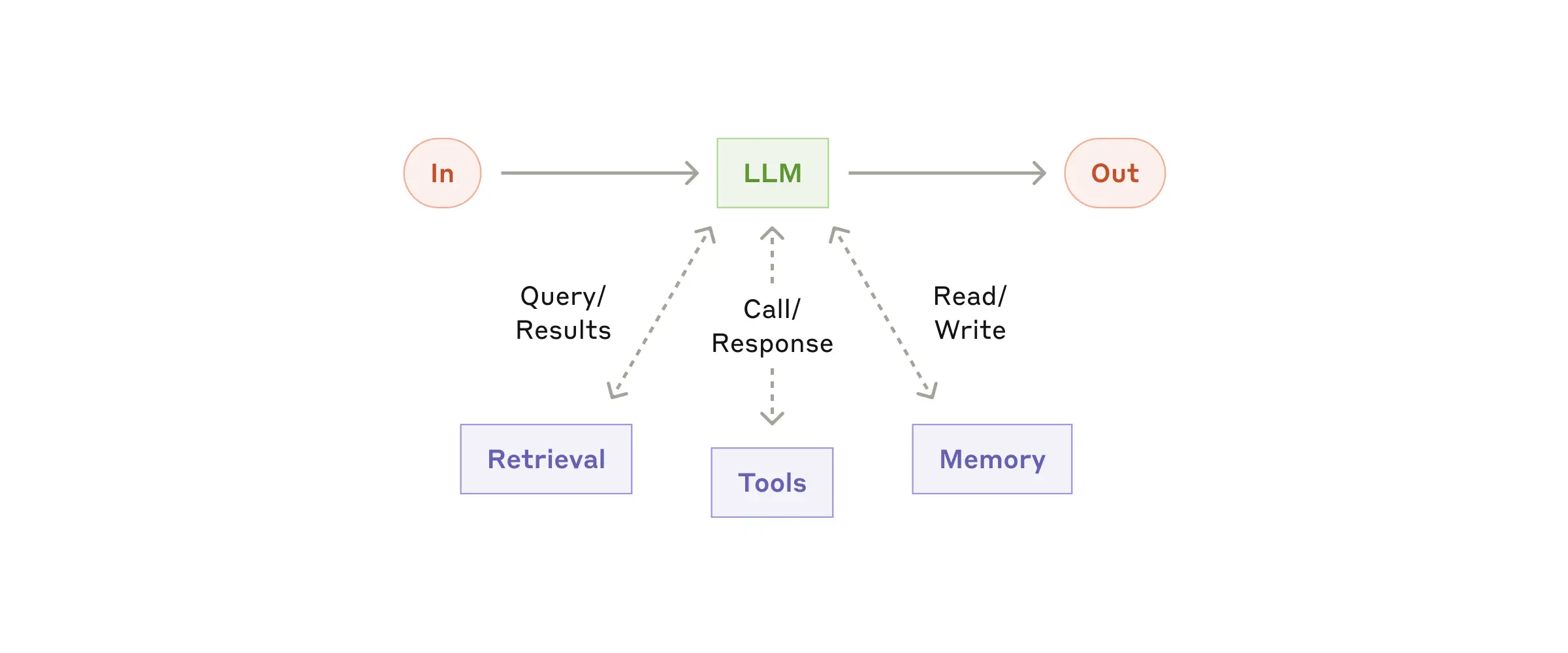
智能体的基本构建模块是添加检索、工具和记忆功能增强的LLM。生成搜索查询、调用合适的工具并确定要保留存储的信息;
工作流:提示链
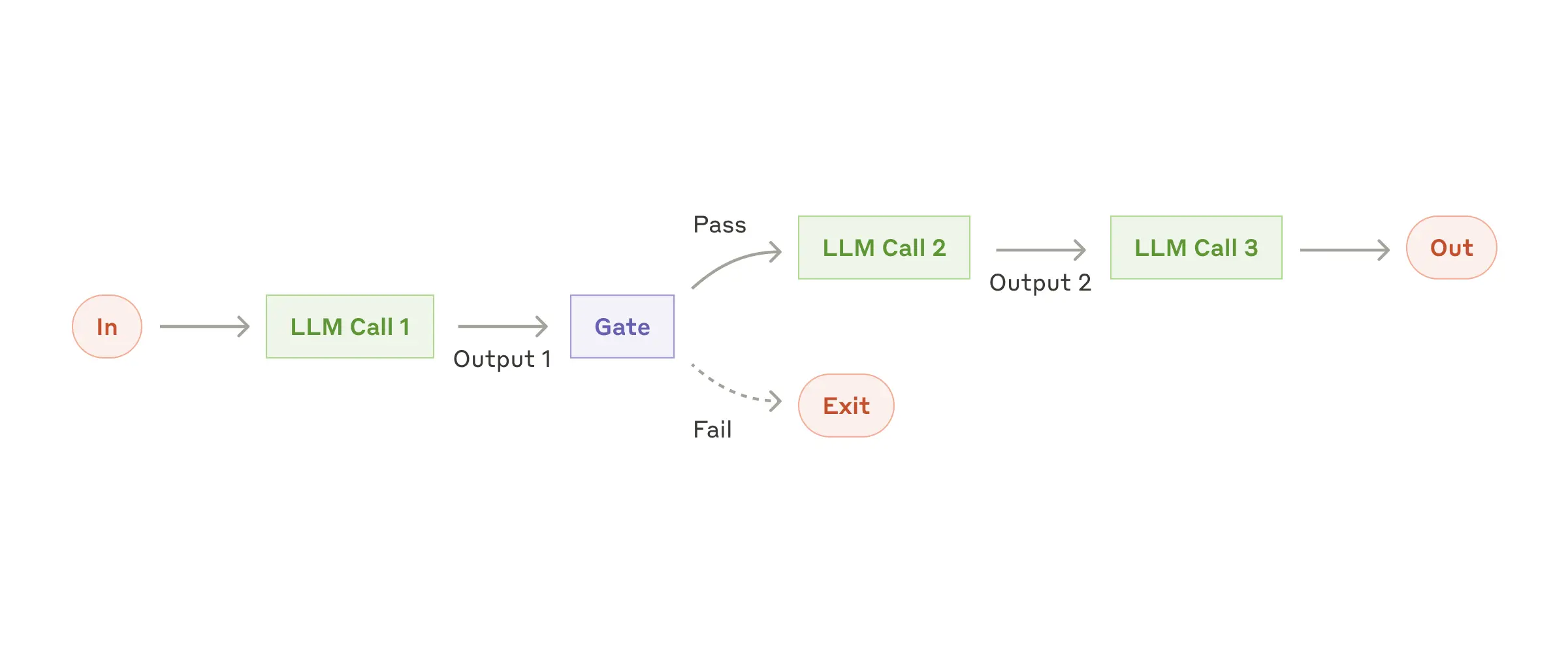
提示链式工作流(Prompting-chaining)将任务分解为一系列步骤,每一步都基于前一步的输出。可以在任何步骤中添加代码检查Gate(代码检查点),以确保步骤执行结果的正确性。
首先定义llm_call函数,封装调用LLM模型返回结果的流程:
from anthropic import Anthropic
import os
import re
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
def llm_call(prompt: str, system_prompt: str = "", model="claude-3-5-sonnet-20241022") -> str:
"""
Calls the model with the given prompt and returns the response.
Args:
prompt (str): The user prompt to send to the model.
system_prompt (str, optional): The system prompt to send to the model. Defaults to "".
model (str, optional): The model to use for the call. Defaults to "claude-3-5-sonnet-20241022".
Returns:
str: The response from the language model.
"""
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
messages = [{"role": "user", "content": prompt}]
response = client.messages.create(
model=model,
max_tokens=4096,
system=system_prompt,
messages=messages,
temperature=0.1,
)
return response.content[0].text
编写prompt-chaining,将任务分解为多个子任务:
from concurrent.futures import ThreadPoolExecutor
from typing import List, Dict, Callable
def chain(input: str, prompts: List[str]) -> str:
"""Chain multiple LLM calls sequentially, passing results between steps."""
result = input
for i, prompt in enumerate(prompts, 1):
print(f"\nStep {i}:")
result = llm_call(f"{prompt}\nInput: {result}")
print(result)
return result
-
应用场景示例:
- LLM生成营销文案,然后翻译成不同的语言;
- LLM先编写文档的大纲,检查大纲是否满足特定要求后,再根据大纲生成文档内容。
-
代码示例:
以使用LLM提取结构化数据为例:
data_processing_steps = [
"""Extract only the numerical values and their associated metrics from the text.
Format each as 'value: metric' on a new line.
Example format:
92: customer satisfaction
45%: revenue growth""",
"""Convert all numerical values to percentages where possible.
If not a percentage or points, convert to decimal (e.g., 92 points -> 92%).
Keep one number per line.
Example format:
92%: customer satisfaction
45%: revenue growth""",
"""Sort all lines in descending order by numerical value.
Keep the format 'value: metric' on each line.
Example:
92%: customer satisfaction
87%: employee satisfaction""",
"""Format the sorted data as a markdown table with columns:
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |"""
]
report = """
Q3 Performance Summary:
Our customer satisfaction score rose to 92 points this quarter.
Revenue grew by 45% compared to last year.
Market share is now at 23% in our primary market.
Customer churn decreased to 5% from 8%.
New user acquisition cost is $43 per user.
Product adoption rate increased to 78%.
Employee satisfaction is at 87 points.
Operating margin improved to 34%.
"""
print("\nInput text:")
print(report)
formatted_result = chain(report, data_processing_steps)
print(formatted_result)
工作流:路由
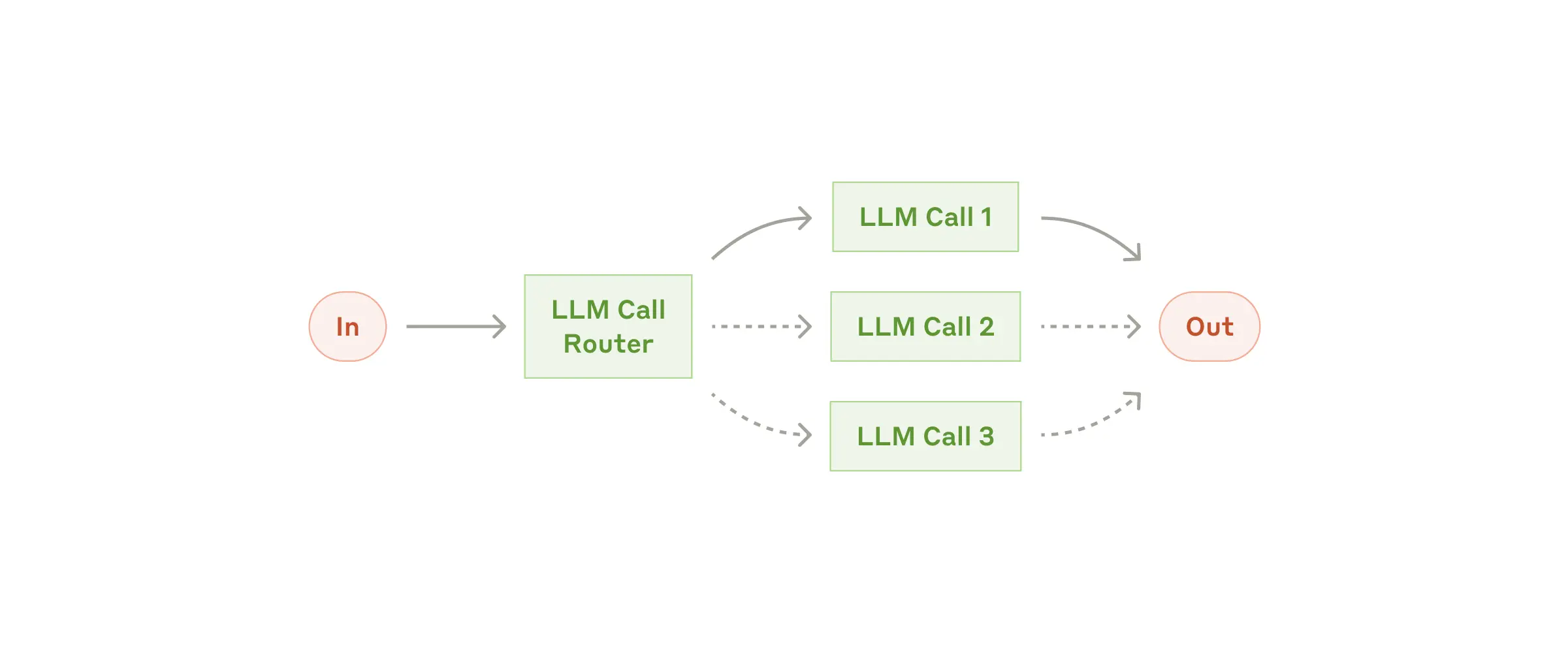
路由(Routing)对输入进行分类并将其定向到专门的后续任务。路由适合需要将一个复杂的任务分解为多个不同类别的子任务的场景。复杂任务通过路由分发后使用LLM或合适的传统算法模型处理任务。
def extract_xml(text: str, tag: str) -> str:
"""
Extracts the content of the specified XML tag from the given text. Used for parsing structured responses
Args:
text (str): The text containing the XML.
tag (str): The XML tag to extract content from.
Returns:
str: The content of the specified XML tag, or an empty string if the tag is not found.
"""
match = re.search(f'<{tag}>(.*?)</{tag}>', text, re.DOTALL)
return match.group(1) if match else ""
def route(input: str, routes: Dict[str, str]) -> str:
"""Route input to specialized prompt using content classification."""
# First determine appropriate route using LLM with chain-of-thought
print(f"\nAvailable routes: {list(routes.keys())}")
selector_prompt = f"""
Analyze the input and select the most appropriate support team from these options: {list(routes.keys())}
First explain your reasoning, then provide your selection in this XML format:
<reasoning>
Brief explanation of why this ticket should be routed to a specific team.
Consider key terms, user intent, and urgency level.
</reasoning>
<selection>
The chosen team name
</selection>
Input: {input}""".strip()
route_response = llm_call(selector_prompt)
reasoning = extract_xml(route_response, 'reasoning')
route_key = extract_xml(route_response, 'selection').strip().lower()
print("Routing Analysis:")
print(reasoning)
print(f"\nSelected route: {route_key}")
# Process input with selected specialized prompt
selected_prompt = routes[route_key]
return llm_call(f"{selected_prompt}\nInput: {input}")
- 应用场景示例:将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导到不同的下游工作流程、提示词和工具调用处理。
- 代码示例
以订票任务为例,将该任务拆分成三个子任务:
support_routes = {
"billing": """You are a billing support specialist. Follow these guidelines:
1. Always start with "Billing Support Response:"
2. First acknowledge the specific billing issue
3. Explain any charges or discrepancies clearly
4. List concrete next steps with timeline
5. End with payment options if relevant
Keep responses professional but friendly.
Input: """,
"technical": """You are a technical support engineer. Follow these guidelines:
1. Always start with "Technical Support Response:"
2. List exact steps to resolve the issue
3. Include system requirements if relevant
4. Provide workarounds for common problems
5. End with escalation path if needed
Use clear, numbered steps and technical details.
Input: """,
"account": """You are an account security specialist. Follow these guidelines:
1. Always start with "Account Support Response:"
2. Prioritize account security and verification
3. Provide clear steps for account recovery/changes
4. Include security tips and warnings
5. Set clear expectations for resolution time
Maintain a serious, security-focused tone.
Input: """,
"product": """You are a product specialist. Follow these guidelines:
1. Always start with "Product Support Response:"
2. Focus on feature education and best practices
3. Include specific examples of usage
4. Link to relevant documentation sections
5. Suggest related features that might help
Be educational and encouraging in tone.
Input: """
}
# Test with different support tickets
tickets = [
"""Subject: Can't access my account
Message: Hi, I've been trying to log in for the past hour but keep getting an 'invalid password' error.
I'm sure I'm using the right password. Can you help me regain access? This is urgent as I need to
submit a report by end of day.
- John""",
"""Subject: Unexpected charge on my card
Message: Hello, I just noticed a charge of $49.99 on my credit card from your company, but I thought
I was on the $29.99 plan. Can you explain this charge and adjust it if it's a mistake?
Thanks,
Sarah""",
"""Subject: How to export data?
Message: I need to export all my project data to Excel. I've looked through the docs but can't
figure out how to do a bulk export. Is this possible? If so, could you walk me through the steps?
Best regards,
Mike"""
]
print("Processing support tickets...\n")
for i, ticket in enumerate(tickets, 1):
print(f"\nTicket {i}:")
print("-" * 40)
print(ticket)
print("\nResponse:")
print("-" * 40)
response = route(ticket, support_routes)
print(response)
工作流:并行化(Parallelization)
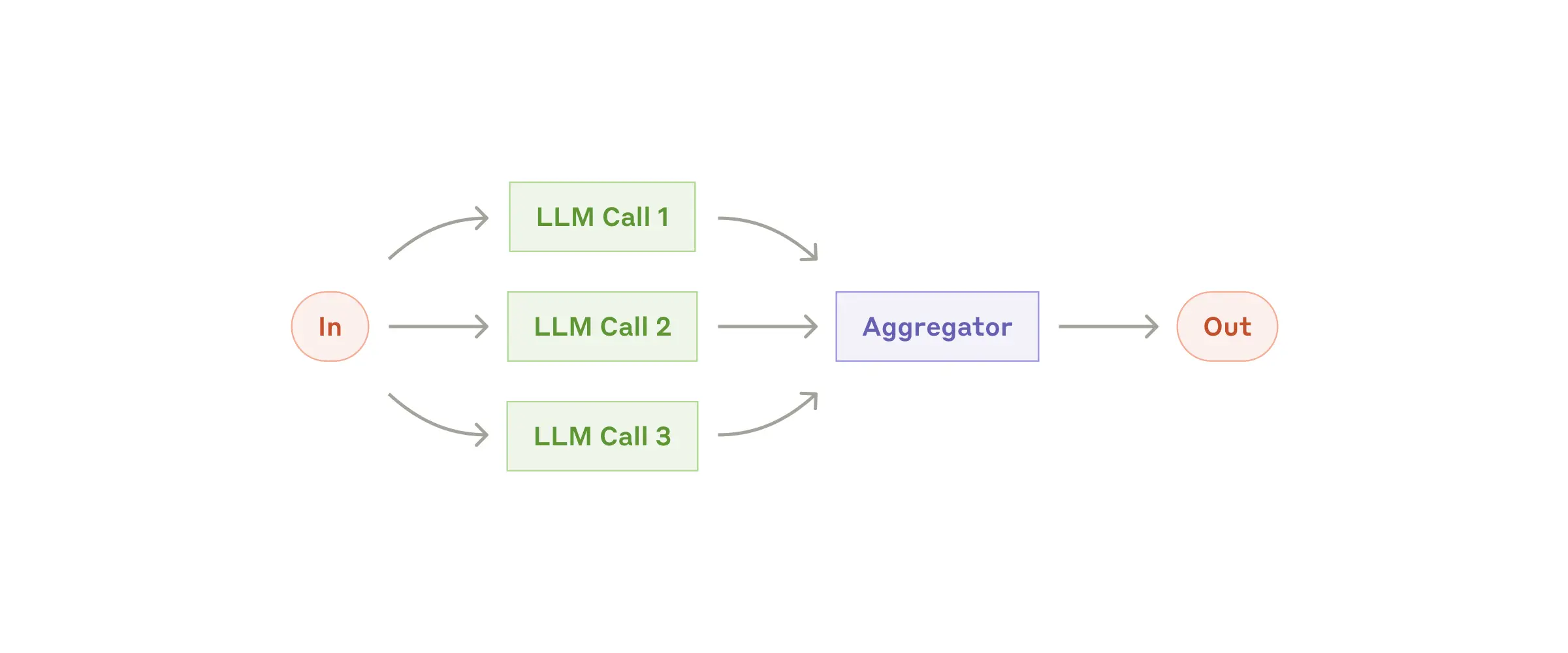
LLM有时可以并行化运行一项任务,并聚合多个输出为最终的结果。具体的,首先将任务分为多个独立的子任务,再多次运行同一任务以获得不同的输出。
- 适用情况:
- 将复杂任务分解成多个独立的小任务并行执行来提升速度;2)需要从不同视角出发解决问题;3)复杂任务中有多种需要考虑的因素,让每次LLM call去注意某个特定领域;
def parallel(prompt: str, inputs: List[str], n_workers: int = 3) -> List[str]:
"""Process multiple inputs concurrently with the same prompt."""
with ThreadPoolExecutor(max_workers=n_workers) as executor:
futures = [executor.submit(llm_call, f"{prompt}\nInput: {x}") for x in inputs]
return [f.result() for f in futures]
- 应用场景示例:
分片:1. 实施护栏。2. LLM自动化评估;
投票:1. 检查一段代码是否存在漏洞;2. 评估给定的内容是否恰当; - 代码示例
分析市场变化对消费者、员工、投资人和供应商等不同群体的影响:
stakeholders = [
"""Customers:
- Price sensitive
- Want better tech
- Environmental concerns""",
"""Employees:
- Job security worries
- Need new skills
- Want clear direction""",
"""Investors:
- Expect growth
- Want cost control
- Risk concerns""",
"""Suppliers:
- Capacity constraints
- Price pressures
- Tech transitions"""
]
impact_results = parallel(
"""Analyze how market changes will impact this stakeholder group.
Provide specific impacts and recommended actions.
Format with clear sections and priorities.""",
stakeholders
)
for result in impact_results:
print(result)
工作流:协调者-工作者模式
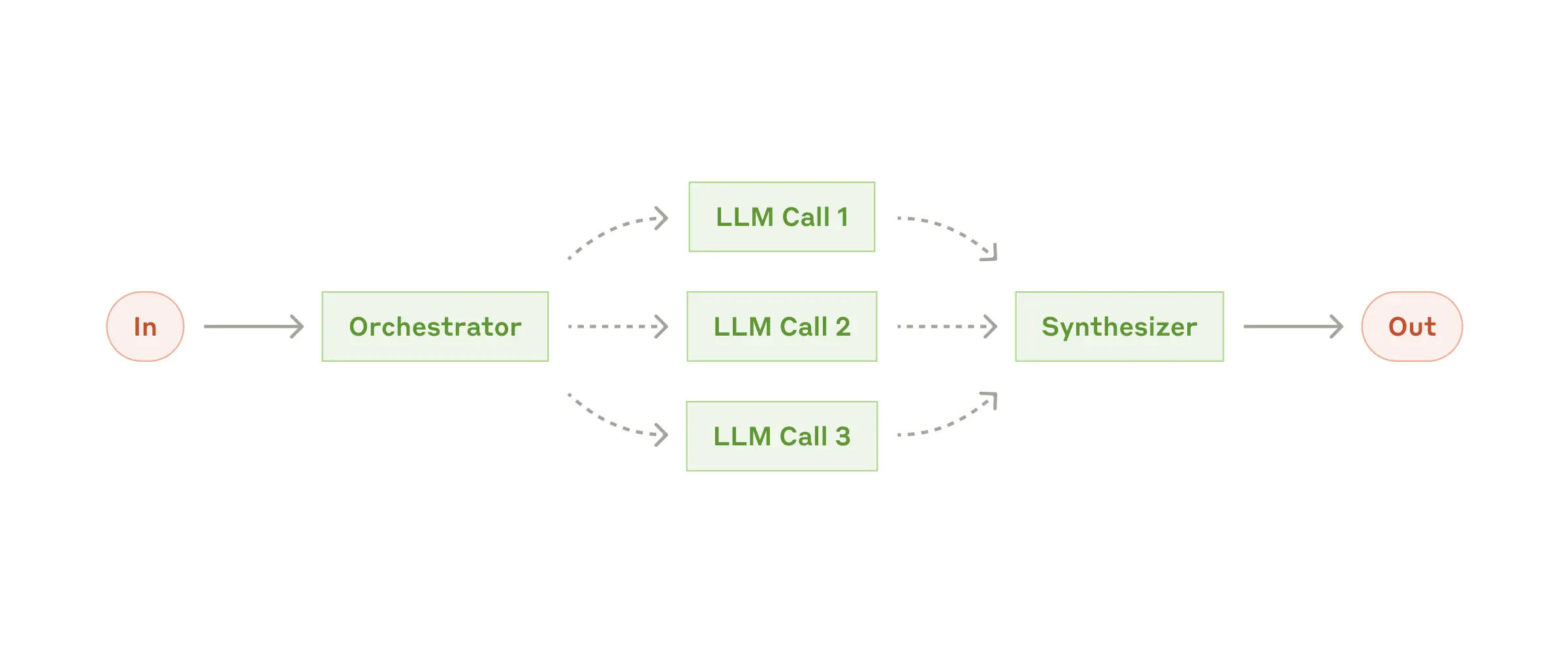
在 orchestrator-worker 工作流中,中央 LLM 会动态分解任务,将其委派给 worker LLM,并综合其结果。
- 适用情况
此工作流程适合于无法预测所需子任务的复杂任务。编排工作流与并行工作流在拓扑结构上类似,与并行工作流的区别在于灵活性,即子任务不是预先定义的,而是由编排器根据特定输入确定的。
首先分解任务,以字典结构返回:
from typing import Dict, List, Optional
from util import llm_call, extract_xml
def parse_tasks(tasks_xml: str) -> List[Dict]:
"""Parse XML tasks into a list of task dictionaries."""
tasks = []
current_task = {}
for line in tasks_xml.split('\n'):
line = line.strip()
if not line:
continue
if line.startswith("<task>"):
current_task = {}
elif line.startswith("<type>"):
current_task["type"] = line[6:-7].strip()
elif line.startswith("<description>"):
current_task["description"] = line[12:-13].strip()
elif line.startswith("</task>"):
if "description" in current_task:
if "type" not in current_task:
current_task["type"] = "default"
tasks.append(current_task)
return tasks
编排模型并行处理分解的任务:
class FlexibleOrchestrator:
"""Break down tasks and run them in parallel using worker LLMs."""
def __init__(
self,
orchestrator_prompt: str,
worker_prompt: str,
):
"""Initialize with prompt templates."""
self.orchestrator_prompt = orchestrator_prompt
self.worker_prompt = worker_prompt
def _format_prompt(self, template: str, **kwargs) -> str:
"""Format a prompt template with variables."""
try:
return template.format(**kwargs)
except KeyError as e:
raise ValueError(f"Missing required prompt variable: {e}")
def process(self, task: str, context: Optional[Dict] = None) -> Dict:
"""Process task by breaking it down and running subtasks in parallel."""
context = context or {}
# Step 1: Get orchestrator response
orchestrator_input = self._format_prompt(
self.orchestrator_prompt,
task=task,
**context
)
orchestrator_response = llm_call(orchestrator_input)
# Parse orchestrator response
analysis = extract_xml(orchestrator_response, "analysis")
tasks_xml = extract_xml(orchestrator_response, "tasks")
tasks = parse_tasks(tasks_xml)
print("\n=== ORCHESTRATOR OUTPUT ===")
print(f"\nANALYSIS:\n{analysis}")
print(f"\nTASKS:\n{tasks}")
# Step 2: Process each task
worker_results = []
for task_info in tasks:
worker_input = self._format_prompt(
self.worker_prompt,
original_task=task,
task_type=task_info['type'],
task_description=task_info['description'],
**context
)
worker_response = llm_call(worker_input)
result = extract_xml(worker_response, "response")
worker_results.append({
"type": task_info["type"],
"description": task_info["description"],
"result": result
})
print(f"\n=== WORKER RESULT ({task_info['type']}) ===\n{result}\n")
return {
"analysis": analysis,
"worker_results": worker_results,
}
- 应用场景示例
- 每次编程需要更改多个文件代码的大型APP项目;
- 涉及从多个来源收集和分析信息以查找可能的相关信息的搜索任务
- 代码示例
一次生成多个版本的营销内容(Marketing Variation Generation):
ORCHESTRATOR_PROMPT = """
Analyze this task and break it down into 2-3 distinct approaches:
Task: {task}
Return your response in this format:
<analysis>
Explain your understanding of the task and which variations would be valuable.
Focus on how each approach serves different aspects of the task.
</analysis>
<tasks>
<task>
<type>formal</type>
<description>Write a precise, technical version that emphasizes specifications</description>
</task>
<task>
<type>conversational</type>
<description>Write an engaging, friendly version that connects with readers</description>
</task>
</tasks>
"""
WORKER_PROMPT = """
Generate content based on:
Task: {original_task}
Style: {task_type}
Guidelines: {task_description}
Return your response in this format:
<response>
Your content here, maintaining the specified style and fully addressing requirements.
</response>
"""
orchestrator = FlexibleOrchestrator(
orchestrator_prompt=ORCHESTRATOR_PROMPT,
worker_prompt=WORKER_PROMPT,
)
results = orchestrator.process(
task="Write a product description for a new eco-friendly water bottle",
context={
"target_audience": "environmentally conscious millennials",
"key_features": ["plastic-free", "insulated", "lifetime warranty"]
}
)
工作流:评估者-优化者模式
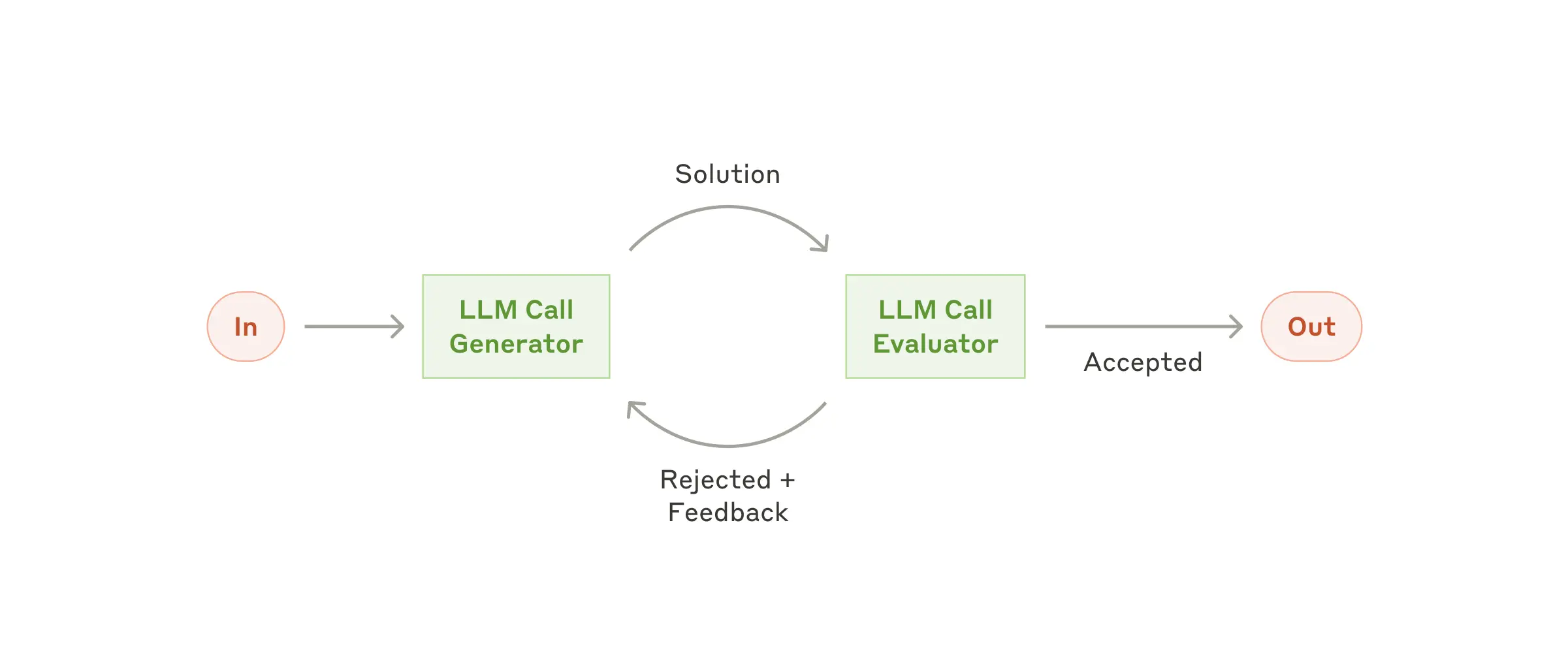
Evaluator-Optimizer工作流程中,一个LLM生成响应内容,另一个LLM提供评估和反馈。
- 适用情况
对大模型输出内容具备明确的评估标准;具有迭代优化的价值(Value from iterative refinement)。
定义Generator:
def generate(prompt: str, task: str, context: str = "") -> tuple[str, str]:
"""Generate and improve a solution based on feedback."""
full_prompt = f"{prompt}\n{context}\nTask: {task}" if context else f"{prompt}\nTask: {task}"
response = llm_call(full_prompt)
thoughts = extract_xml(response, "thoughts")
result = extract_xml(response, "response")
print("\n=== GENERATION START ===")
print(f"Thoughts:\n{thoughts}\n")
print(f"Generated:\n{result}")
print("=== GENERATION END ===\n")
return thoughts, result
定义Evaluator:
def evaluate(prompt: str, content: str, task: str) -> tuple[str, str]:
"""Evaluate if a solution meets requirements."""
full_prompt = f"{prompt}\nOriginal task: {task}\nContent to evaluate: {content}"
response = llm_call(full_prompt)
evaluation = extract_xml(response, "evaluation")
feedback = extract_xml(response, "feedback")
print("=== EVALUATION START ===")
print(f"Status: {evaluation}")
print(f"Feedback: {feedback}")
print("=== EVALUATION END ===\n")
return evaluation, feedback
循环调用生成器-评估器来迭代优化LLM的输出:
def loop(task: str, evaluator_prompt: str, generator_prompt: str) -> tuple[str, list[dict]]:
"""Keep generating and evaluating until requirements are met."""
memory = []
chain_of_thought = []
thoughts, result = generate(generator_prompt, task)
memory.append(result)
chain_of_thought.append({"thoughts": thoughts, "result": result})
while True:
evaluation, feedback = evaluate(evaluator_prompt, result, task)
if evaluation == "PASS":
return result, chain_of_thought
context = "\n".join([
"Previous attempts:",
*[f"- {m}" for m in memory],
f"\nFeedback: {feedback}"
])
thoughts, result = generate(generator_prompt, task, context)
memory.append(result)
chain_of_thought.append({"thoughts": thoughts, "result": result})
- 应用示例
- 文学翻译,翻译家LLM提供翻译,评论者LLM提供对翻译结果的评估;
- 复杂的搜索任务,需要多轮搜素和分析以收集全面的信息,其中评估者决定是否需要进一步搜索。
以迭代优化编程结果为例,编写提示词:
evaluator_prompt = """
Evaluate this following code implementation for:
1. code correctness
2. time complexity
3. style and best practices
You should be evaluating only and not attemping to solve the task.
Only output "PASS" if all criteria are met and you have no further suggestions for improvements.
Output your evaluation concisely in the following format.
<evaluation>PASS, NEEDS_IMPROVEMENT, or FAIL</evaluation>
<feedback>
What needs improvement and why.
</feedback>
"""
generator_prompt = """
Your goal is to complete the task based on <user input>. If there are feedback
from your previous generations, you should reflect on them to improve your solution
Output your answer concisely in the following format:
<thoughts>
[Your understanding of the task and feedback and how you plan to improve]
</thoughts>
<response>
[Your code implementation here]
</response>
"""
# 以编写栈结构代码的任务为例
task = """
<user input>
Implement a Stack with:
1. push(x)
2. pop()
3. getMin()
All operations should be O(1).
</user input>
"""
loop(task, evaluator_prompt, generator_prompt)
智能体
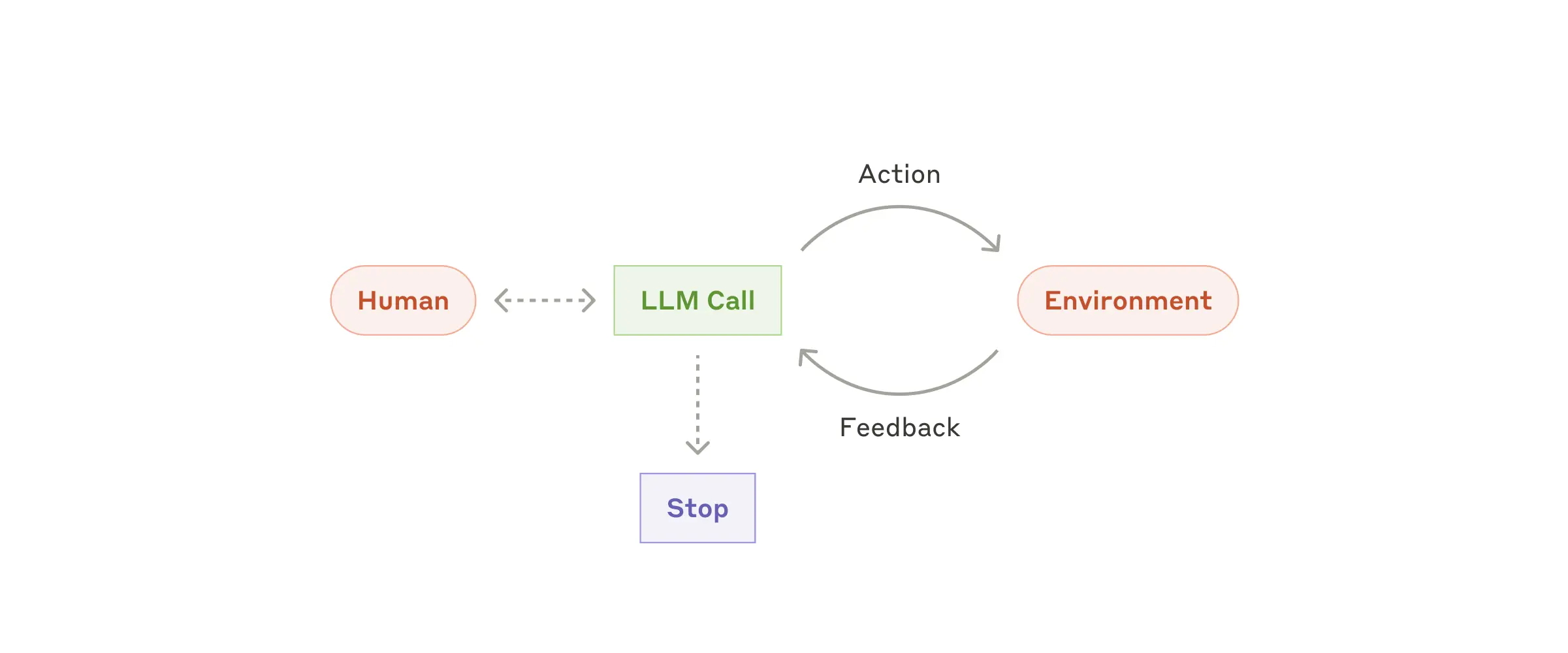
智能体在工业生产环境中为LLM提供理解复杂输入、参与推理和规划、可靠的使用工具以及从故障中恢复等能力。
- 适用情况
智能体可用于工作步骤和路径难以预测的开放式问题(open-ended problem) - 应用场景
- Coding agent解决SWE-bench任务;
- computer use agent自动操作电脑
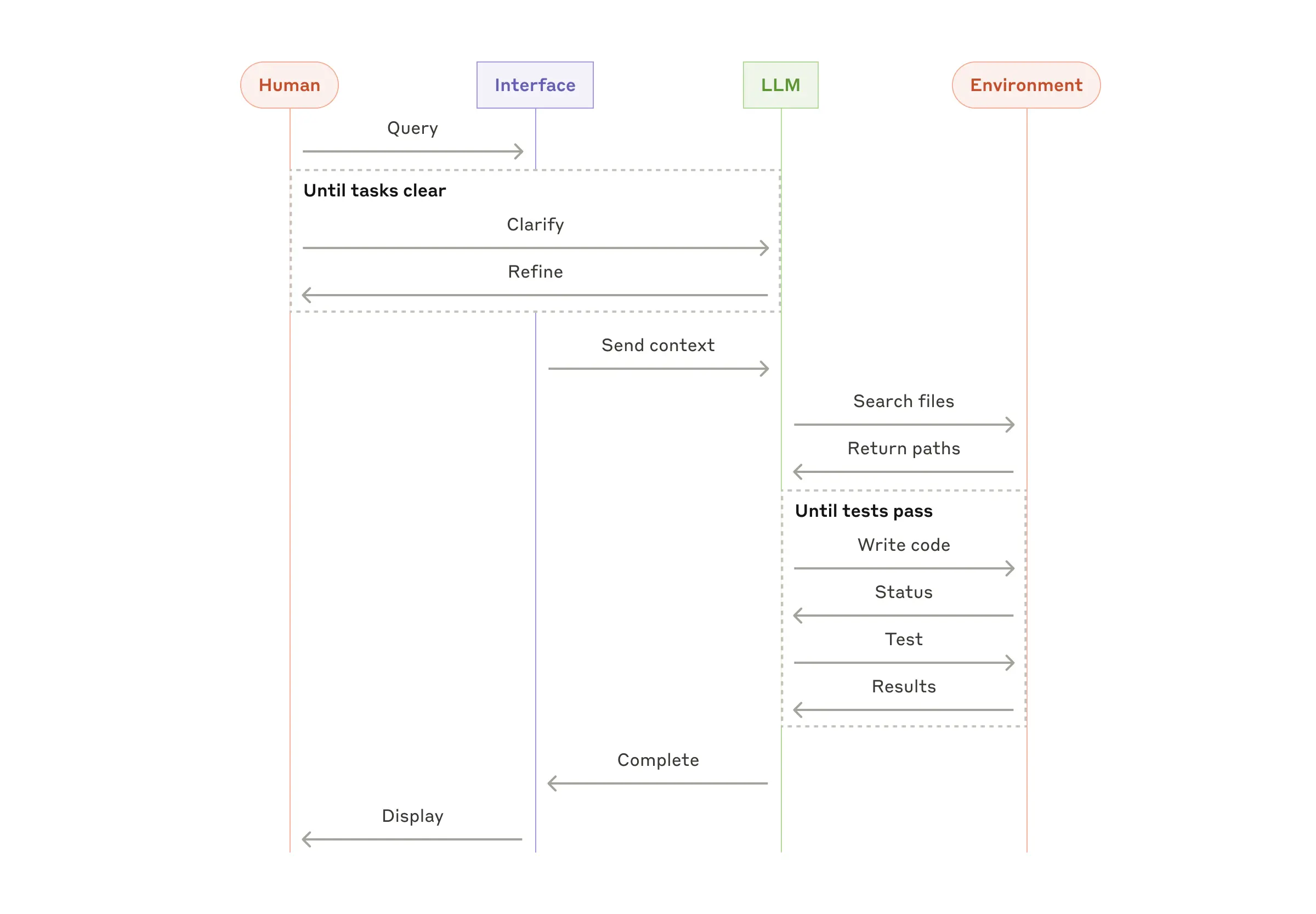
总结
2024年agent出现了非常多的框架,但是大多数其实是workflow,Anthropic的这份指南总结了agent和workflow的常见模式和适用场景,特别是prompt的分层编写技巧,值得一读。
参考资料
[1] https://www.anthropic.com/research/building-effective-agents
[2] https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents/
[3] https://www.langchain.com/langgraph
[4] LLM Powered Autonomous Agents: https://lilianweng.github.io/posts/2023-06-23-agent/



















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









