




【从零构建大模型】第四章从零构建GPT模型,生成内容
1.概述
本文总结《从零构建LLM》的笔记,加深对GPT的理解,gpt架构的理解。
作者写了做个文章在下面公众号(驾驭AI美未来、大模型生产力指南),目的是提升大模型、智能体的理解,提高大家生产力,欢迎关注、点赞。
录了个视频课程,欢迎学习。
【从零构建大模型】 视频课程讲解,一步步带你理解大模型底层原理
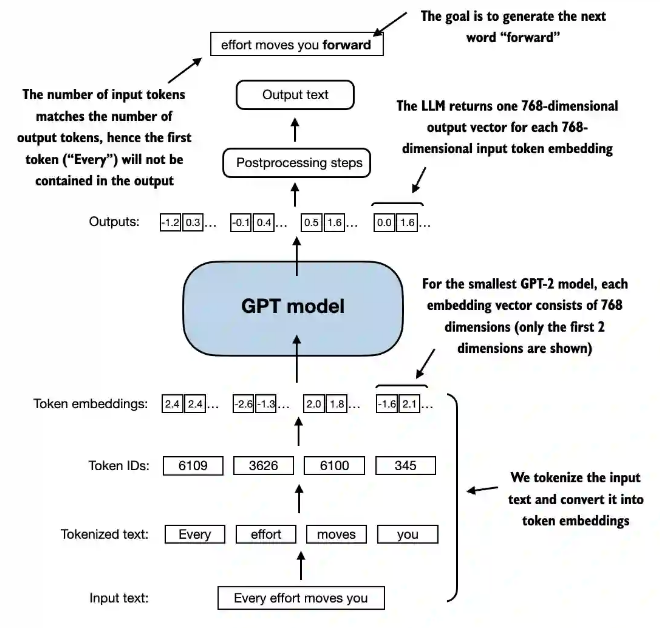
2. 构建GPT
2.1 构建gpt思路
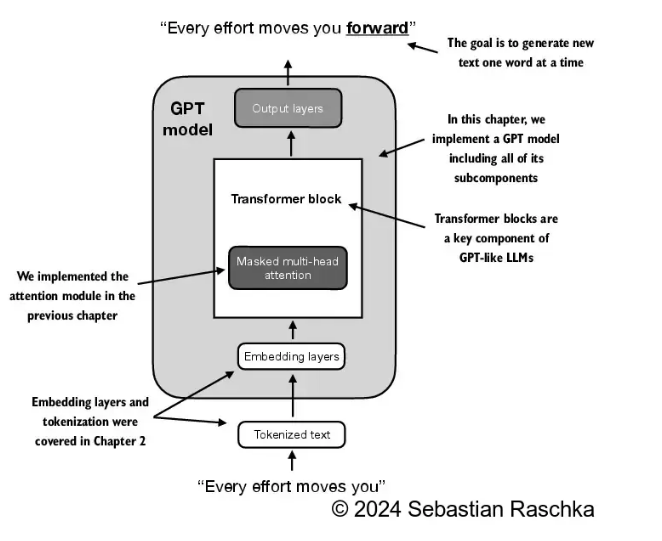
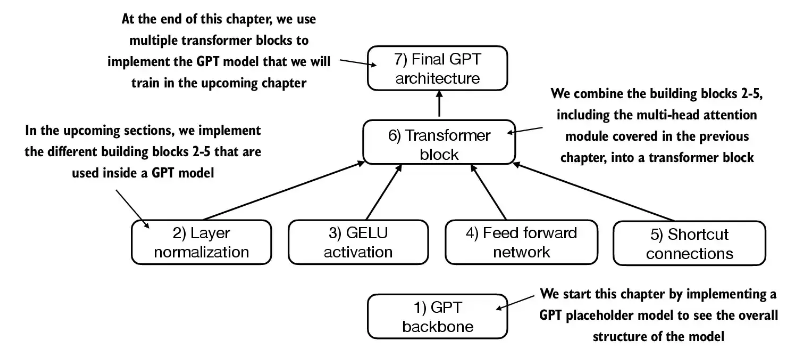
2.2 使用层归一化进行归一化激活
层归一化主要思想:调整整个神经网络的激活(输出),使其均值为0且方差为1。这样有助于快速收敛,并确保训练一致与可靠,避免梯度消失或梯度爆炸的问题。
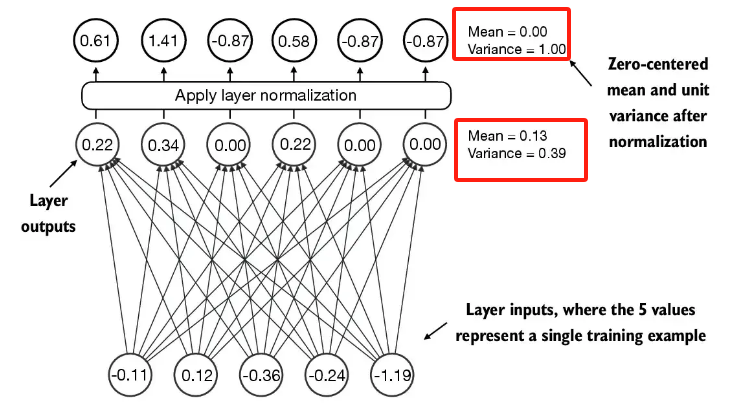
- 归一化代码
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
2.3 使用 GELU 激活函数实现前馈网络
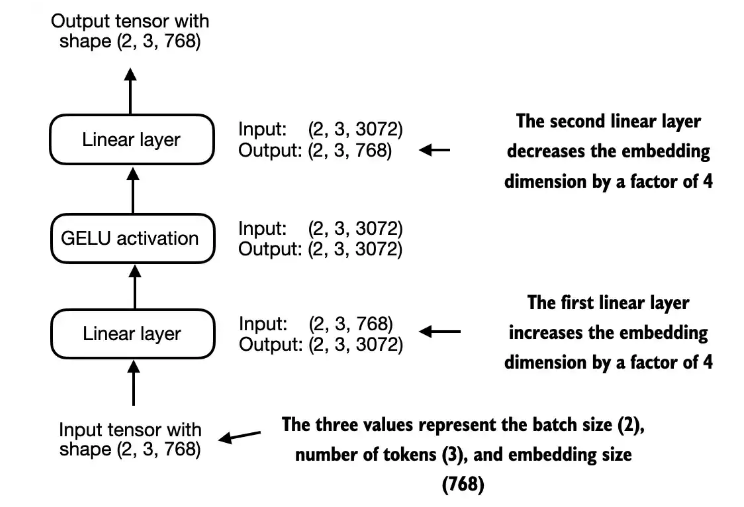
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg['emb_dim'], 4* cfg['emb_dim']),
GELU(),
nn.Linear(4 * cfg['emb_dim'], cfg['emb_dim'])
)
def forward(self, x):
return self.layers(x);
Implementing: 动词,译为 “实现”,在技术语境中特指将理论模型通过代码(如 Python+PyTorch/TensorFlow)构建为可运行的程序或模块。
feed forward network: 即 “前馈网络”,是神经网络的基础结构,信号仅从输入层向隐藏层、输出层单向传递,无反馈回路,常见如全连接神经网络(FCN),广泛用于分类、回归等任务。
GELU activations: 全称 “Gaussian Error Linear Units”,译为 “高斯误差线性单元”,是一种常用的激活函数,公式近似为 GELU(x) = 0.5 * x * [1 + tanh(√(2/π) * (x + 0.044715x³))],相比 ReLU 等函数更符合生物神经元的激活特性,在 Transformer、BERT 等模型中被广泛采用,能提升模型训练稳定性与泛化能力。
- 矩阵升维->降维 效果图
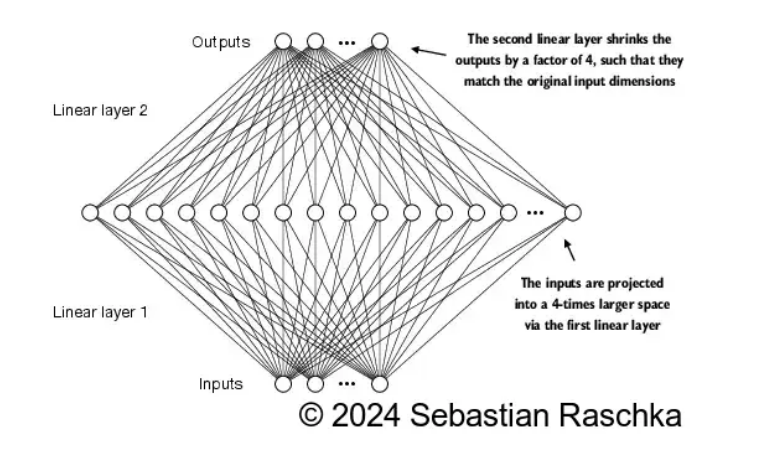
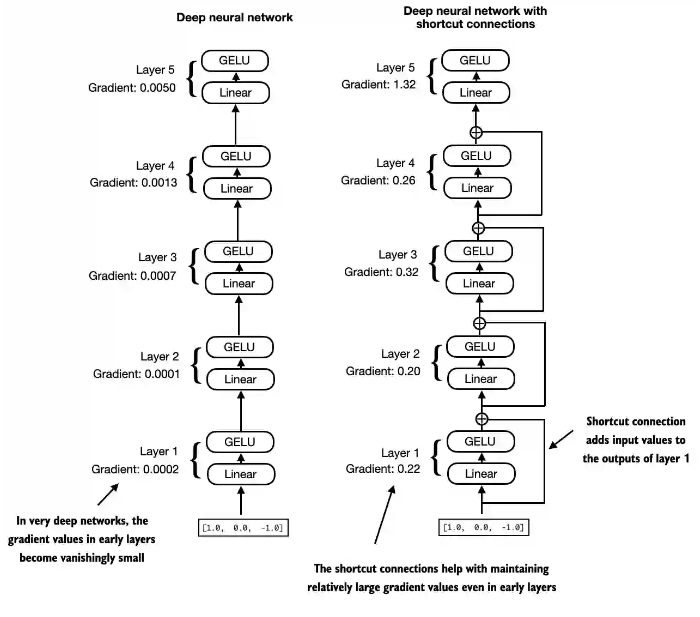
2.4 shotcut 快捷链接
用于解决梯度消失的问题
2.5 transformer block¶
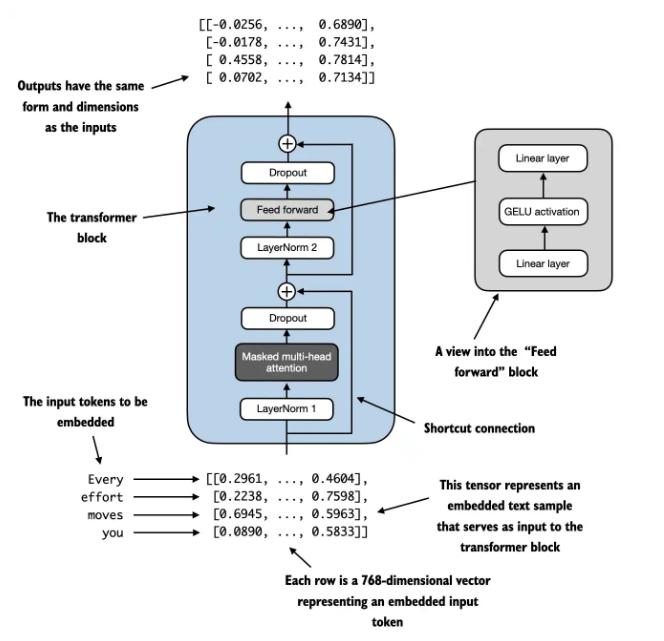
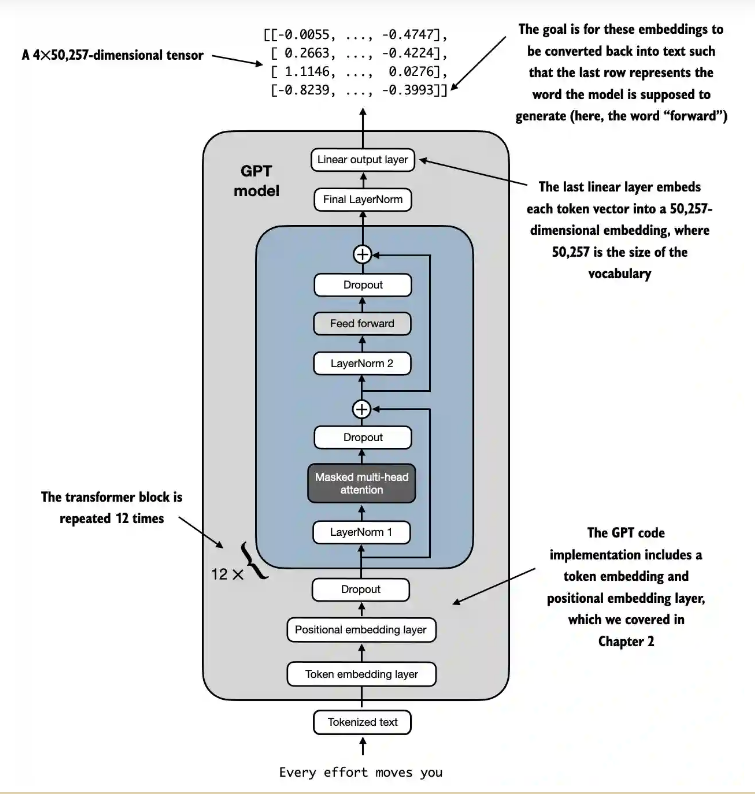
2.6 gpt 总结构



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









