




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python深度学习垃圾邮件分类与检测系统技术说明
一、系统概述
本系统基于Python语言开发,采用深度学习技术构建垃圾邮件分类与检测模型,旨在高效、准确地识别垃圾邮件,降低用户受到恶意邮件干扰的风险。系统利用自然语言处理(NLP)技术对邮件文本进行特征提取和预处理,通过深度神经网络模型进行训练和分类,最终实现对垃圾邮件的自动识别和过滤。
二、技术架构
2.1 开发环境
- 编程语言:Python 3.x
- 深度学习框架:TensorFlow/Keras 或 PyTorch
- 数据处理库:NumPy、Pandas
- 文本处理库:NLTK、scikit-learn
- 其他工具:Jupyter Notebook(用于原型开发)、Flask/Django(可选,用于部署Web服务)
2.2 系统模块划分
- 数据采集与预处理模块
- 特征提取与向量化模块
- 深度学习模型构建与训练模块
- 模型评估与优化模块
- 预测与分类模块
- (可选)Web服务接口模块
三、详细技术实现
3.1 数据采集与预处理
数据来源
- 公开数据集:如SpamAssassin、Enron-Spam等
- 自定义数据集:通过爬虫或邮件服务器日志收集
数据清洗
- 去除HTML标签、特殊字符、停用词
- 统一大小写、拼写纠正(可选)
- 处理缺失值和异常值
数据标注
- 将邮件分为“垃圾邮件”(spam)和“正常邮件”(ham)两类
- 可采用半监督学习或主动学习策略减少人工标注成本
3.2 特征提取与向量化
词袋模型(Bag of Words)
python
1from sklearn.feature_extraction.text import CountVectorizer
2vectorizer = CountVectorizer(max_features=5000)
3X = vectorizer.fit_transform(emails_text)TF-IDF(词频-逆文档频率)
python
1from sklearn.feature_extraction.text import TfidfVectorizer
2tfidf = TfidfVectorizer(max_features=5000, ngram_range=(1,2))
3X = tfidf.fit_transform(emails_text)词嵌入(Word Embedding)
- 使用预训练模型(如GloVe、Word2Vec)或训练自定义词向量
- 通过平均词向量或使用Doc2Vec生成文档向量
3.3 深度学习模型构建
基础模型:多层感知机(MLP)
python
1from tensorflow.keras.models import Sequential
2from tensorflow.keras.layers import Dense, Dropout
3
4model = Sequential([
5 Dense(128, activation='relu', input_shape=(input_dim,)),
6 Dropout(0.5),
7 Dense(64, activation='relu'),
8 Dense(1, activation='sigmoid')
9])
10model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])进阶模型:卷积神经网络(CNN)
python
1from tensorflow.keras.layers import Conv1D, GlobalMaxPooling1D
2
3model = Sequential([
4 Embedding(vocab_size, 100, input_length=max_len),
5 Conv1D(128, 5, activation='relu'),
6 GlobalMaxPooling1D(),
7 Dense(64, activation='relu'),
8 Dense(1, activation='sigmoid')
9])高级模型:循环神经网络(RNN)及其变体(LSTM/GRU)
python
1from tensorflow.keras.layers import LSTM, Bidirectional
2
3model = Sequential([
4 Embedding(vocab_size, 100, input_length=max_len),
5 Bidirectional(LSTM(64, return_sequences=True)),
6 Bidirectional(LSTM(32)),
7 Dense(1, activation='sigmoid')
8])预训练模型迁移学习(如BERT)
python
1from transformers import BertTokenizer, TFBertForSequenceClassification
2
3tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
4model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)3.4 模型训练与优化
训练配置
- 批量大小(Batch Size):32/64
- 学习率(Learning Rate):1e-4 ~ 1e-3
- 训练轮次(Epochs):10~50(配合早停法)
优化技巧
- 学习率调度(Learning Rate Scheduling)
- 早停法(Early Stopping)
- 正则化(L1/L2、Dropout)
- 数据增强(同义词替换、随机插入/删除)
3.5 模型评估
评估指标
- 准确率(Accuracy)
- 精确率(Precision)、召回率(Recall)、F1-Score
- ROC曲线与AUC值
- 混淆矩阵
交叉验证
python
1from sklearn.model_selection import cross_val_score
2scores = cross_val_score(model, X_train, y_train, cv=5, scoring='f1')3.6 预测与分类
python
1def predict_spam(email_text, model, vectorizer):
2 processed_text = preprocess_text(email_text) # 自定义预处理函数
3 vectorized = vectorizer.transform([processed_text])
4 prediction = model.predict(vectorized)[0][0]
5 return "spam" if prediction > 0.5 else "ham"四、系统部署(可选)
4.1 Flask Web服务示例
python
1from flask import Flask, request, jsonify
2app = Flask(__name__)
3
4@app.route('/predict', methods=['POST'])
5def predict():
6 data = request.json
7 email_text = data['text']
8 result = predict_spam(email_text, model, vectorizer)
9 return jsonify({'result': result})
10
11if __name__ == '__main__':
12 app.run(host='0.0.0.0', port=5000)4.2 定时任务集成
- 通过Cron或APScheduler定期更新模型
- 集成到邮件服务器(如Postfix)的过滤流程
五、性能优化方向
- 模型轻量化:使用知识蒸馏、模型剪枝等技术减少参数量
- 实时性优化:ONNX Runtime加速推理
- 多模态检测:结合邮件头、附件特征
- 对抗样本防御:增强模型鲁棒性
六、总结
本系统通过深度学习技术实现了高精度的垃圾邮件分类,具有以下优势:
- 自动特征学习,减少人工规则依赖
- 支持端到端训练与部署
- 可扩展性强,易于集成到现有邮件系统
未来可进一步探索:
- 联邦学习保护用户隐私
- 跨语言垃圾邮件检测
- 结合用户行为分析的个性化过滤
附录:完整代码示例与数据集链接可参考GitHub仓库:[示例链接](需实际补充)
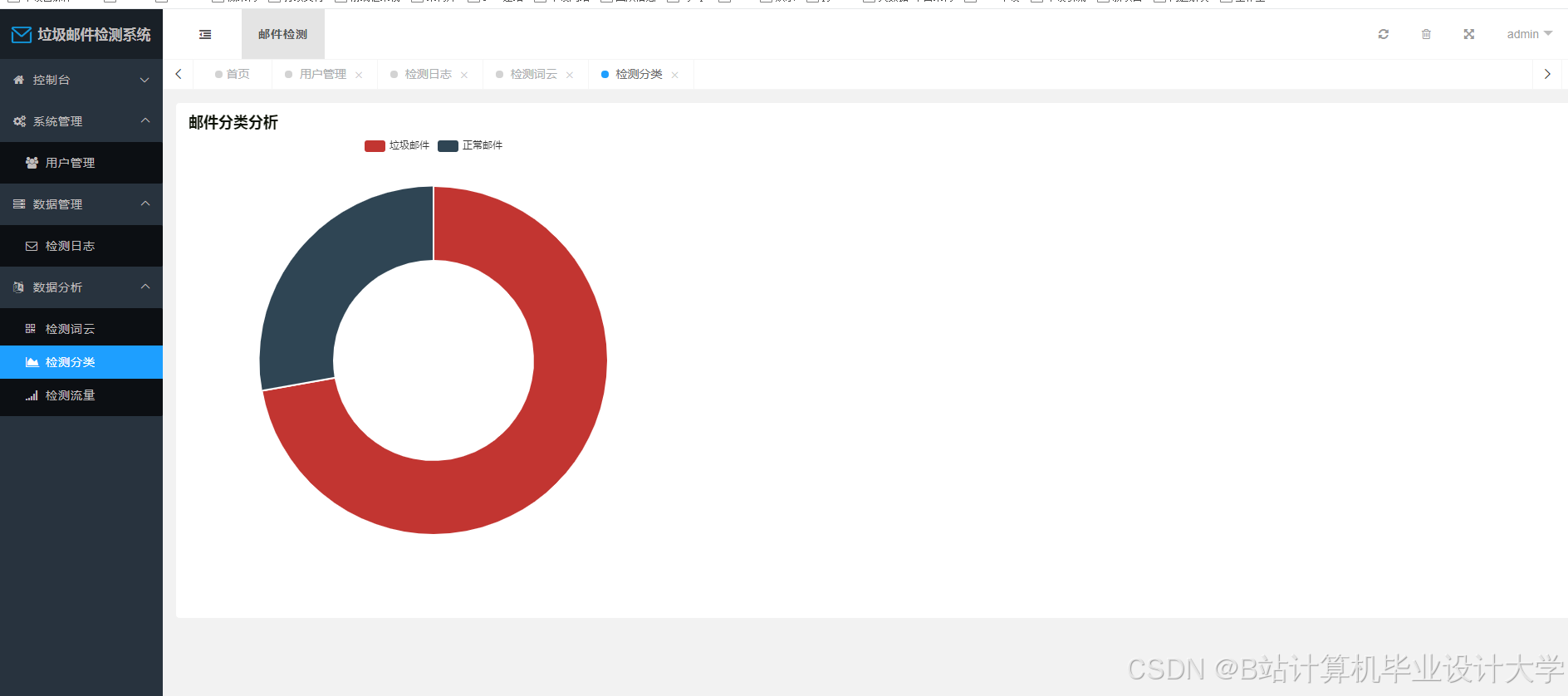
运行截图
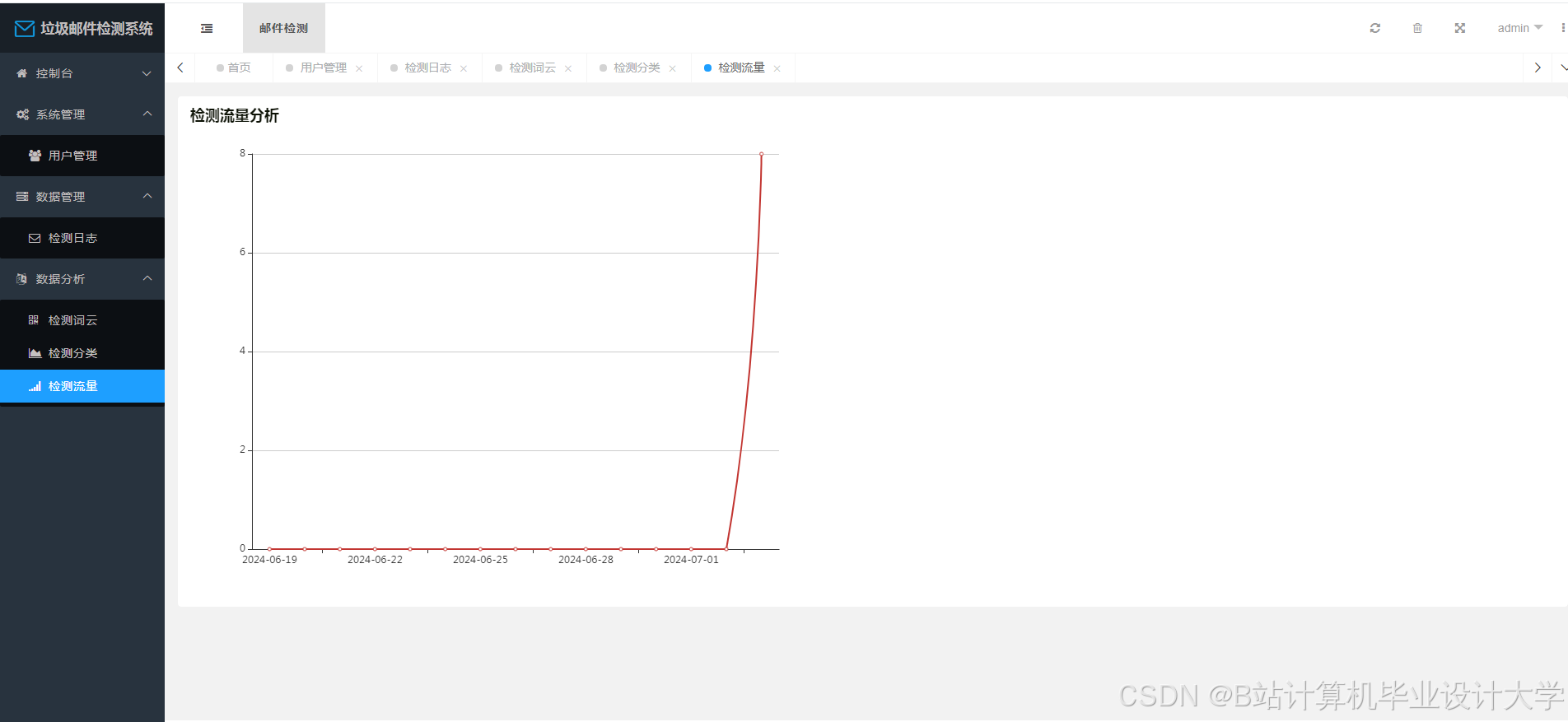

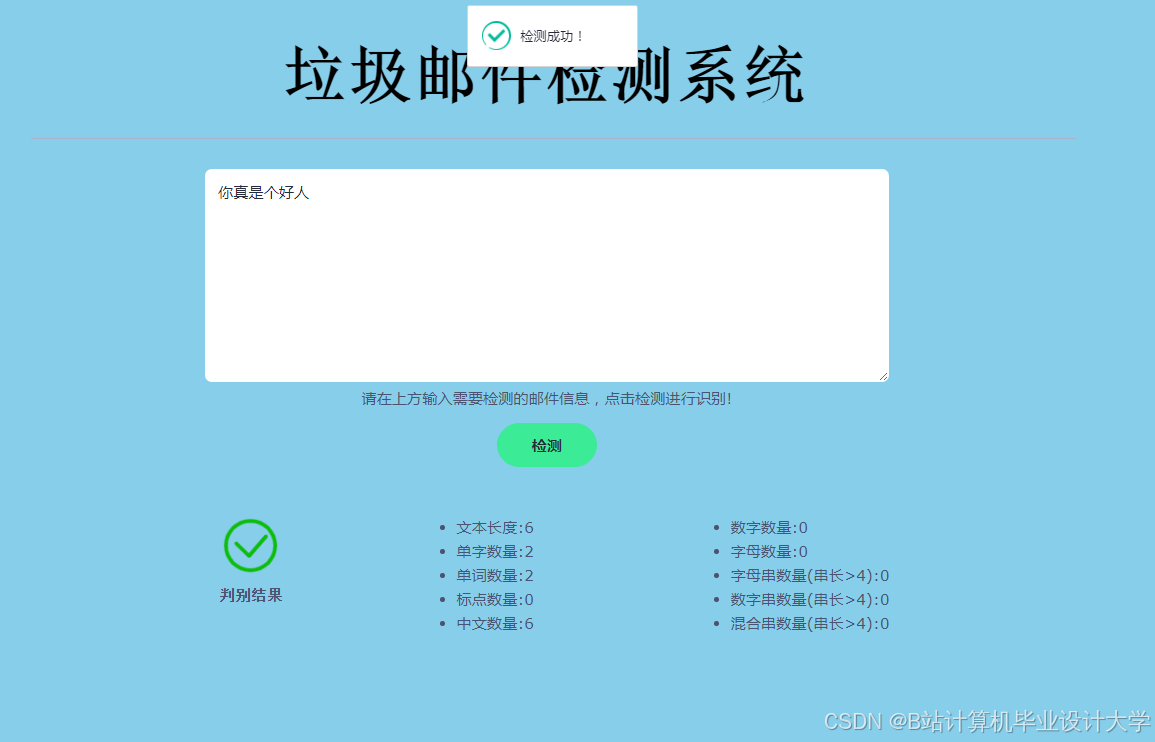

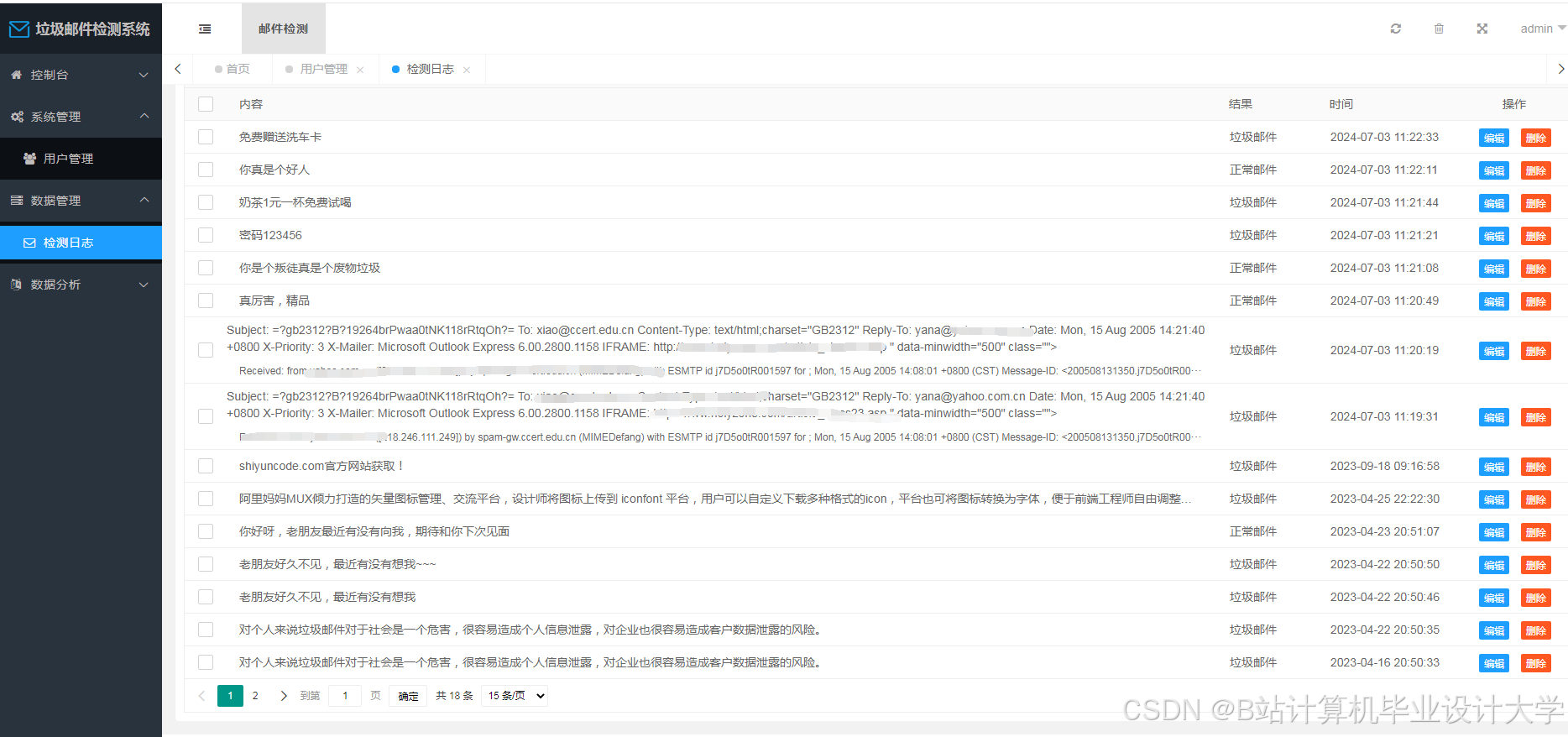
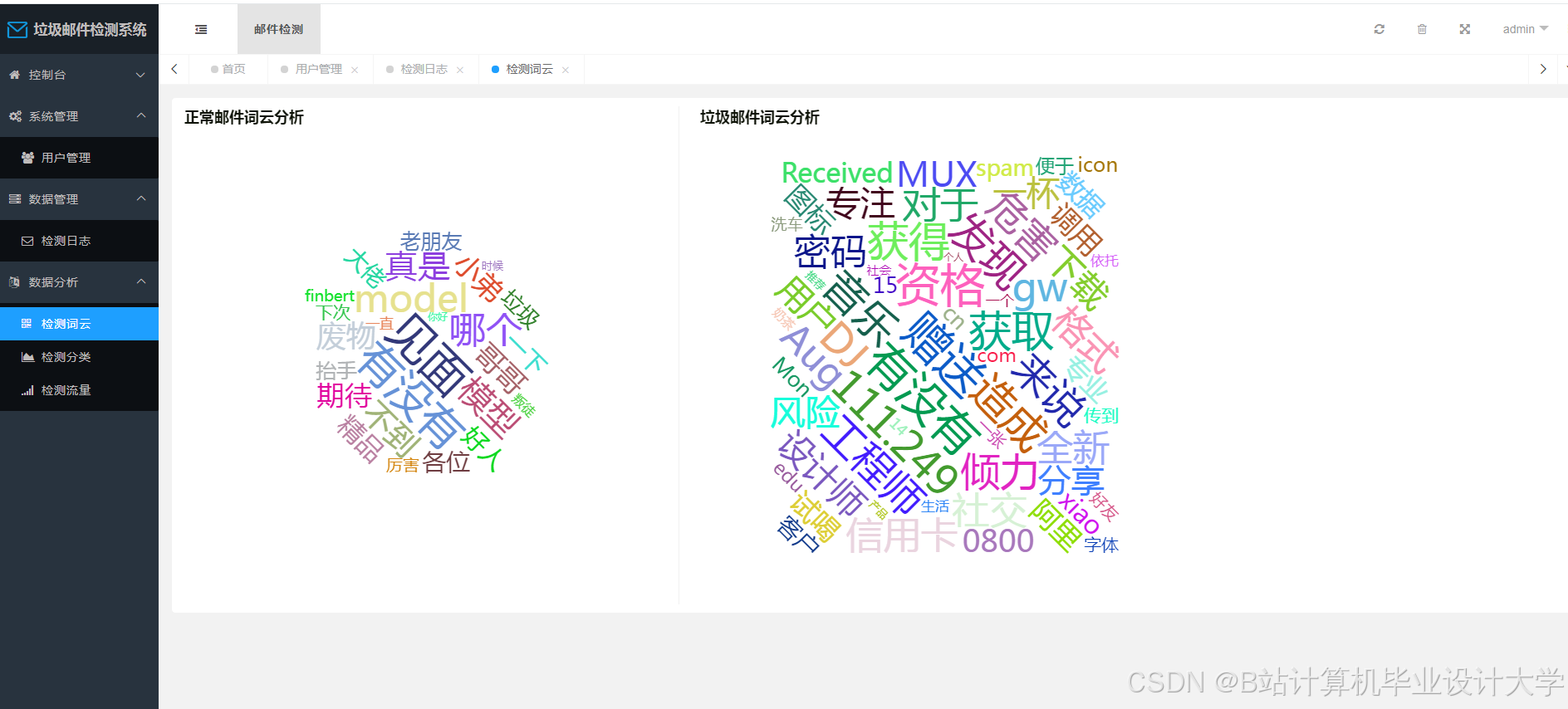
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











