




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python+Django全国气象可视化分析系统技术说明
一、系统背景与目标
随着全球气候变化加剧,极端天气事件频发,气象数据的实时性、准确性和可视化呈现对防灾减灾、农业生产、交通规划等领域至关重要。传统气象数据获取依赖专业机构发布,存在数据孤岛、更新滞后等问题,且可视化手段单一,难以满足多维度分析需求。本系统基于Python+Django框架,结合大数据处理与可视化技术,构建全国气象数据采集、存储、分析和可视化的一体化平台,旨在实现以下目标:
- 多源数据融合:整合中国气象局、NOAA、卫星遥感等数据源,覆盖温度、湿度、风速、降水量等核心气象要素。
- 高效处理能力:利用Hadoop分布式存储与Spark计算引擎,支持海量数据的高效处理与实时分析。
- 智能可视化展示:通过ECharts、Mapbox等工具实现动态图表、热力图、三维风场等多样化可视化效果。
- 用户友好交互:提供响应式Web界面,支持多终端访问,满足科研、政府决策和公众服务需求。
二、系统架构设计
系统采用分层架构,分为数据采集层、存储层、计算层、服务层和展示层,各层技术选型与功能如下:
1. 数据采集层
- 数据源:
- 权威机构API:中国气象局CMACast系统、NOAA全球气象数据接口。
- 卫星遥感数据:FY-4A气象卫星、MODIS遥感数据。
- 地面观测站:全国2424个国家级气象站实时数据。
- 第三方平台:Windy、OpenWeatherMap等开放数据。
- 采集工具:
- Python爬虫框架:Scrapy、BeautifulSoup实现多线程爬取,结合IP代理池应对反爬机制。
- 定时任务:Celery调度爬虫任务,支持增量更新与全量刷新。
2. 数据存储层
- 分布式存储:
- HDFS:存储原始气象数据文件(如CSV、JSON格式),支持高吞吐量访问。
- MongoDB:存储非结构化数据(如卫星云图、雷达基数据),支持灵活查询。
- 关系型数据库:
- MySQL:存储清洗后的结构化数据(如温度、湿度等),通过索引优化查询性能。
3. 计算层
- 大数据处理:
- Spark SQL:对HDFS中的气象数据进行批量清洗、聚合和特征工程(如计算日均温、最大风速)。
- Dask:并行处理超大规模数据集,支持动态任务调度。
- 机器学习:
- Scikit-learn:构建随机森林、XGBoost模型,用于降水概率预测、极端天气分类。
- TensorFlow/PyTorch:训练LSTM网络,实现未来72小时风速时序预测(RMSE<3mm)。
4. 服务层
- 后端框架:
- Django REST Framework:提供RESTful API接口,支持用户认证、权限管理和数据查询。
- Celery:异步处理耗时任务(如模型推理、数据导出)。
- 缓存机制:
- Redis:缓存热门城市的气象统计结果(如北京今日温度范围),降低数据库压力。
5. 展示层
- 前端技术:
- Vue.js:构建响应式界面,实现动态数据绑定与组件化开发。
- ECharts.js:绘制折线图(温度趋势)、柱状图(降水量分布)、热力图(气温空间分布)。
- Mapbox GL JS:生成交互式地理地图,叠加风场矢量图、台风路径三维模拟。
- 交互功能:
- 时间轴控制:用户可拖动时间滑块查看历史数据。
- 图层叠加:支持多气象要素(如温度+降水)同屏对比。
- 区域选择放大:点击地图区域查看局部细节。
三、核心功能实现
1. 数据采集与清洗
以爬取中国天气网历史数据为例,使用Scrapy框架实现多城市批量采集:
python
1import scrapy
2from items import WeatherItem
3
4class WeatherSpider(scrapy.Spider):
5 name = 'weather_spider'
6 start_urls = ['https://www.weather.com/history/']
7
8 def parse(self, response):
9 for city in ['beijing', 'shanghai', 'guangzhou']:
10 date = '2025-12-19'
11 url = f"{self.start_urls[0]}{city}/{date.replace('-', '/')}"
12 yield scrapy.Request(url, callback=self.parse_detail, meta={'city': city})
13
14 def parse_detail(self, response):
15 item = WeatherItem()
16 item['city'] = response.meta['city']
17 item['date'] = '2025-12-19'
18 item['temperature'] = response.css('.temp::text').get()
19 item['wind'] = response.css('.wind::text').get()
20 yield item清洗流程包括:
- 异常值检测:使用3σ原则剔除温度、风速等超出合理范围的数据。
- 缺失值填补:采用KNN插值法填充缺失的降水量记录。
- 数据标准化:将温度单位统一为摄氏度,风速单位转换为米/秒。
2. 气象数据分析
(1)时间序列分析
使用Spark SQL计算某城市2020-2025年温度统计量:
python
1from pyspark.sql import SparkSession
2from pyspark.sql.functions import avg, max, min
3
4spark = SparkSession.builder.appName("WeatherAnalysis").getOrCreate()
5df = spark.read.jdbc(url="jdbc:mysql://localhost:3306/weather_db",
6 table="weather_data",
7 properties={"user": "root", "password": "password"})
8
9result = df.filter(df.city == "北京") \
10 .groupBy("date") \
11 .agg(avg("temperature").alias("avg_temp"),
12 max("temperature").alias("max_temp"),
13 min("temperature").alias("min_temp")) \
14 .orderBy("date")
15result.show()(2)空间插值分析
基于Kriging算法生成全国气温热力图:
python
1import numpy as np
2from scipy.interpolate import griddata
3import matplotlib.pyplot as plt
4
5# 假设已获取全国气象站坐标(lon, lat)和温度数据(temp)
6points = np.array([[116.4, 39.9], [121.5, 31.2], ...]) # 经纬度
7values = np.array([15.2, 18.7, ...]) # 温度
8grid_x, grid_y = np.mgrid[70:135:0.5, 15:55:0.5] # 生成网格
9grid_z = griddata(points, values, (grid_x, grid_y), method='cubic')
10
11plt.contourf(grid_x, grid_y, grid_z, levels=20, cmap='jet')
12plt.colorbar(label='Temperature (°C)')
13plt.title("National Temperature Heatmap")
14plt.show()3. 可视化展示
(1)动态折线图
使用ECharts展示北京2025年温度趋势:
javascript
1// 前端Vue组件中调用API获取数据
2axios.get('/api/weather/trend?city=北京&start=2025-01-01&end=2025-12-31')
3 .then(response => {
4 const chart = echarts.init(document.getElementById('temp-chart'));
5 chart.setOption({
6 xAxis: { type: 'category', data: response.data.dates },
7 yAxis: { type: 'value', name: 'Temperature (°C)' },
8 series: [{
9 data: response.data.temps,
10 type: 'line',
11 smooth: true
12 }]
13 });
14 });(2)三维风场模拟
结合Three.js与Mapbox实现台风路径三维可视化:
javascript
1// 加载台风轨迹数据(经度、纬度、风速、高度)
2const typhoonData = [
3 { lon: 120.5, lat: 20.0, speed: 30, height: 0 },
4 { lon: 121.0, lat: 21.5, speed: 45, height: 1000 },
5 // ...
6];
7
8// 创建3D场景
9const scene = new THREE.Scene();
10const camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 0.1, 1000);
11const renderer = new THREE.WebGLRenderer();
12renderer.setSize(window.innerWidth, window.innerHeight);
13document.body.appendChild(renderer.domElement);
14
15// 添加风场箭头(使用ConeGeometry表示风向)
16typhoonData.forEach(point => {
17 const arrow = new THREE.Mesh(
18 new THREE.ConeGeometry(0.5, 2, 8),
19 new THREE.MeshBasicMaterial({ color: 0xff0000 })
20 );
21 arrow.position.set(point.lon, point.height / 1000, -point.lat);
22 arrow.rotation.set(0, Math.atan2(point.speed, 10), 0);
23 scene.add(arrow);
24});
25
26// 渲染循环
27function animate() {
28 requestAnimationFrame(animate);
29 renderer.render(scene, camera);
30}
31animate();四、系统部署与优化
1. 部署环境
- 容器化部署:使用Docker打包Django应用、MySQL数据库和Celery worker,通过Kubernetes实现集群管理。
- 负载均衡:Nginx反向代理分发请求,支持横向扩展。
- 监控告警:Prometheus+Grafana监控系统资源使用率,设置阈值告警。
2. 性能优化
- 数据库优化:
- 为高频查询字段(如城市、日期)创建索引。
- 使用读写分离,主库负责写入,从库处理查询。
- 缓存策略:
- Redis缓存热门城市的气象统计结果,TTL设置为1小时。
- 对静态资源(如JS/CSS文件)启用浏览器缓存。
- 异步处理:
- 将模型推理、数据导出等耗时任务交给Celery异步执行,避免阻塞主线程。
五、应用场景与价值
- 气象灾害预警:基于雷达回波和降水预测模型,提前24小时发布暴雨预警。
- 农业气象服务:结合积温、日照时数等参数,为作物生长模型提供数据支持。
- 城市气候评估:分析热岛效应,为城市通风廊道设计提供依据。
- 公众服务:通过移动端适配,为用户提供实时天气查询和出行建议。
六、总结与展望
本系统通过整合Python生态中的大数据处理、机器学习和可视化工具,结合Django框架的快速开发能力,构建了全国气象数据的高效分析平台。未来可进一步探索以下方向:
- 多模态融合:联合卫星云图(CNN识别)、雷达基数据(张量处理)与地面观测数据,提升短临降水预报准确率。
- 联邦学习:在保护数据隐私的前提下,实现跨机构气象模型协作训练。
- 边缘计算:基于5G和物联网,部署微型气象传感器网络,实现超密集时空数据流的实时处理。
运行截图
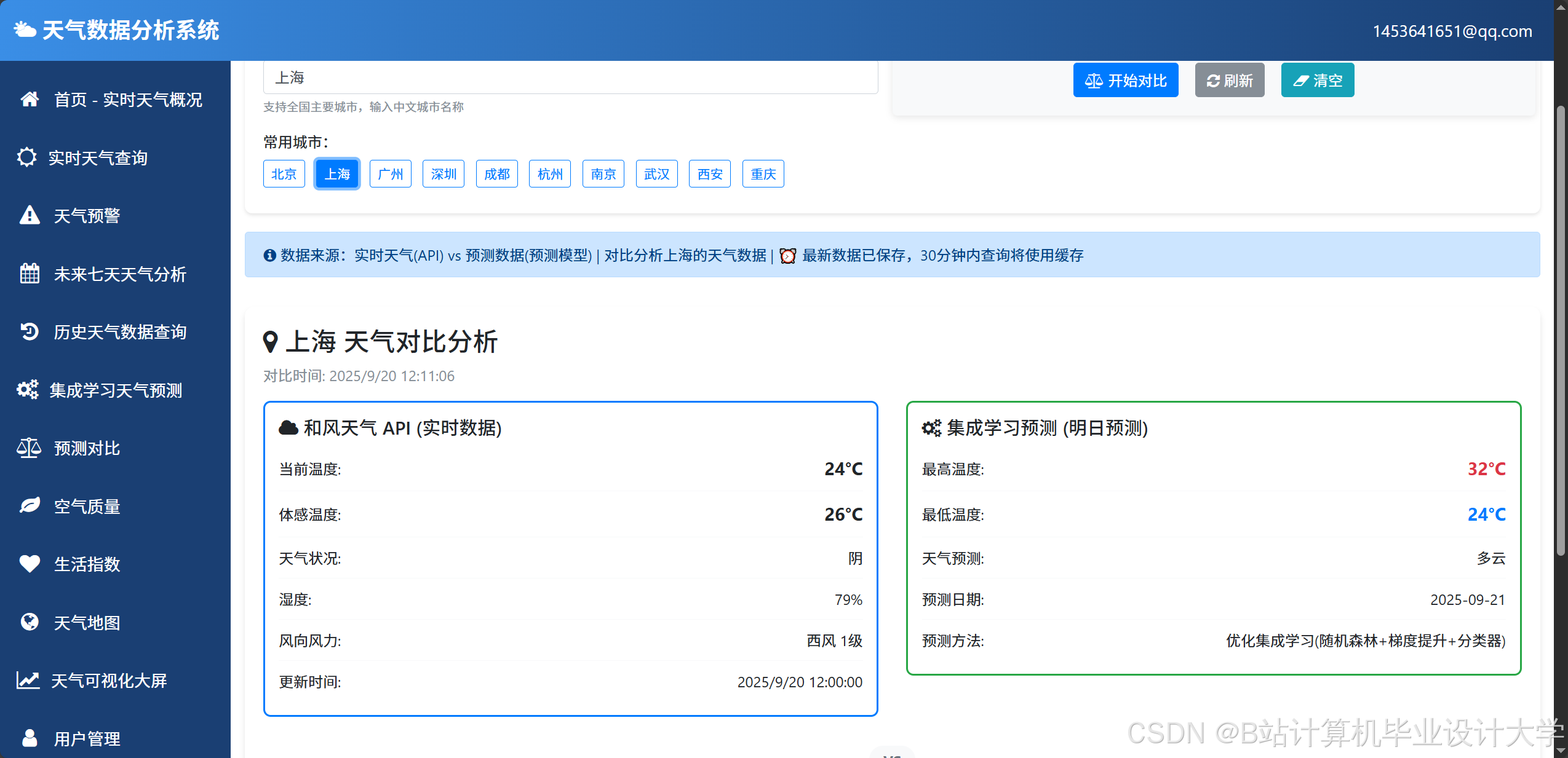
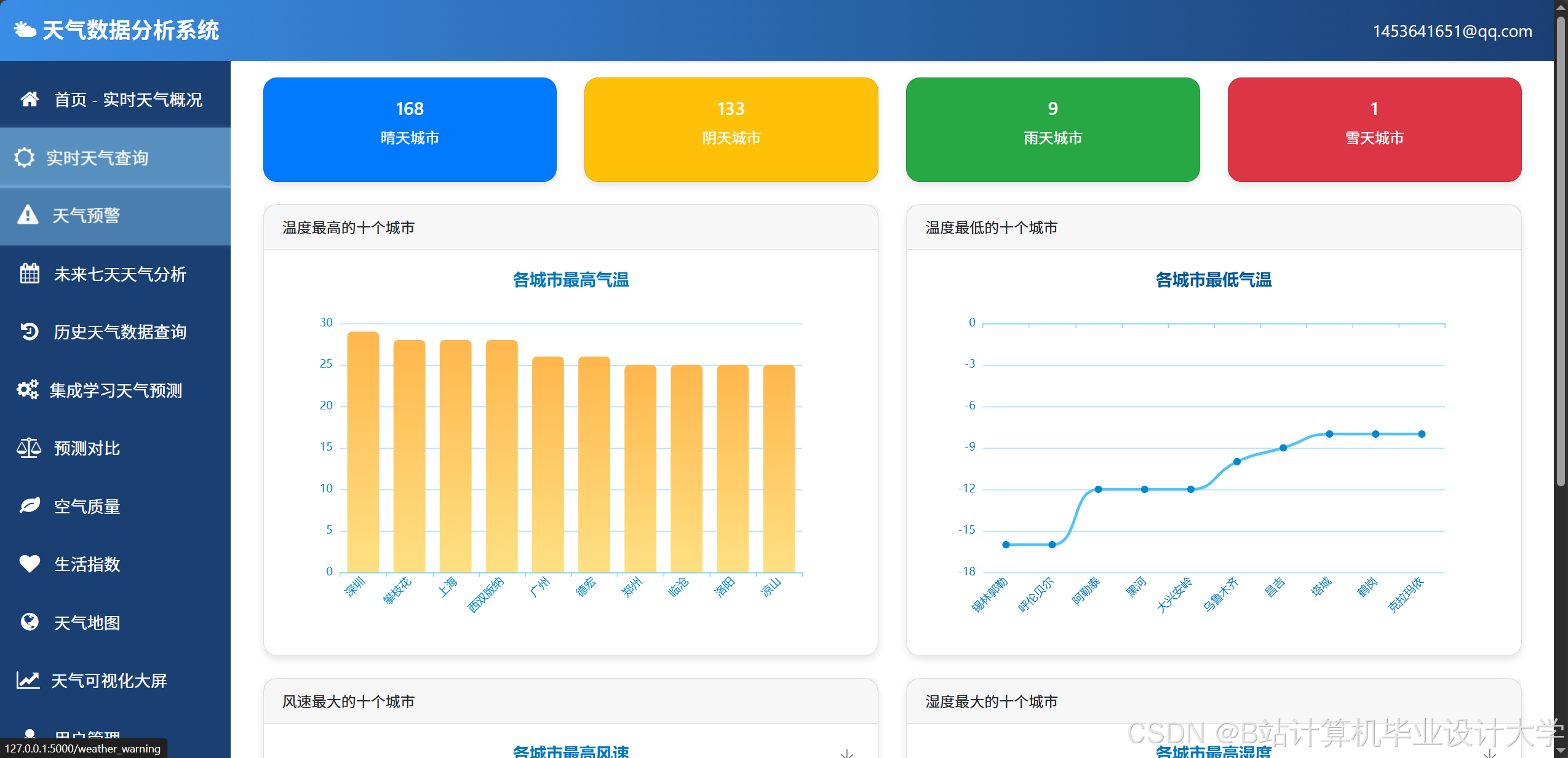
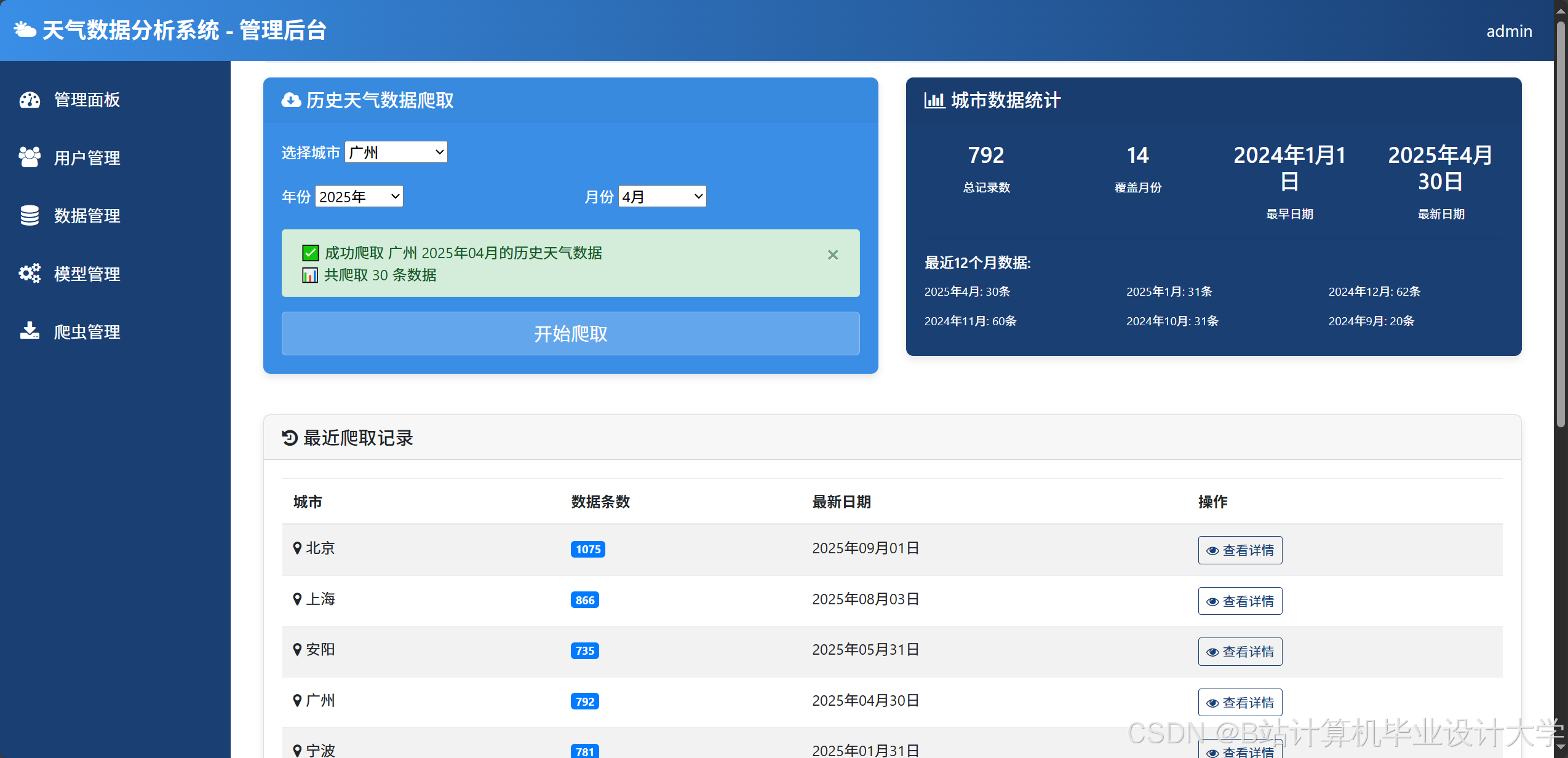
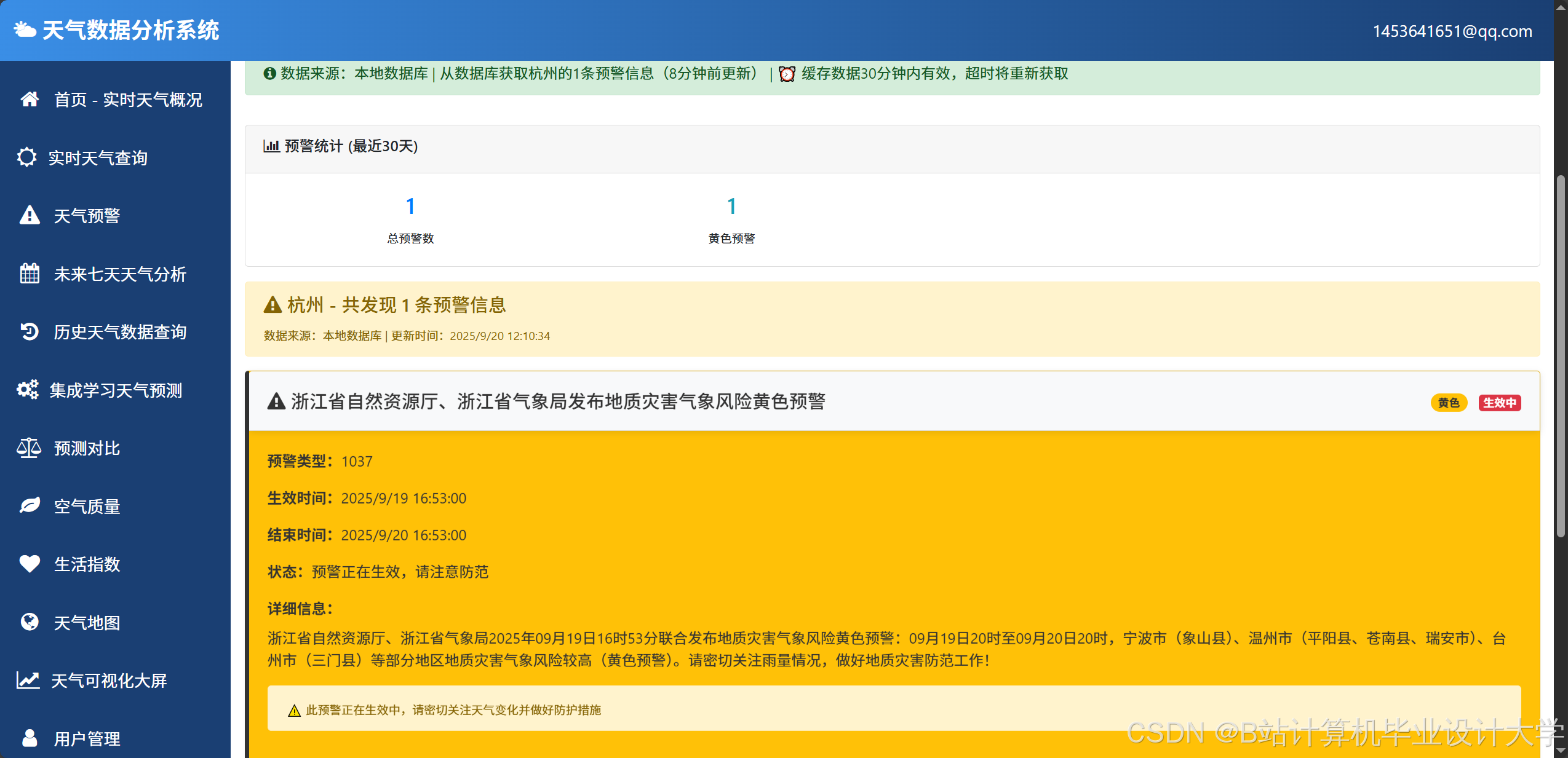
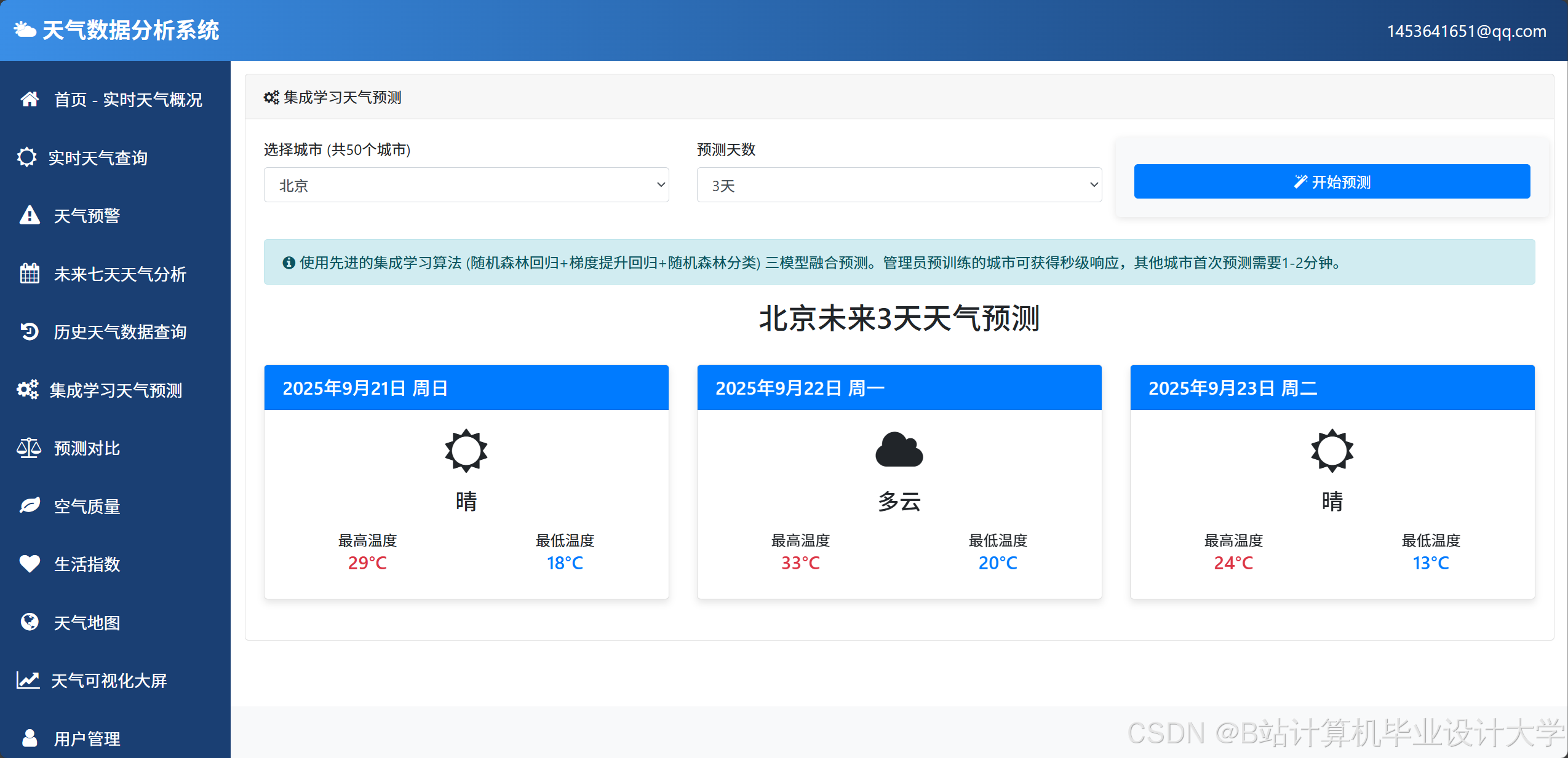
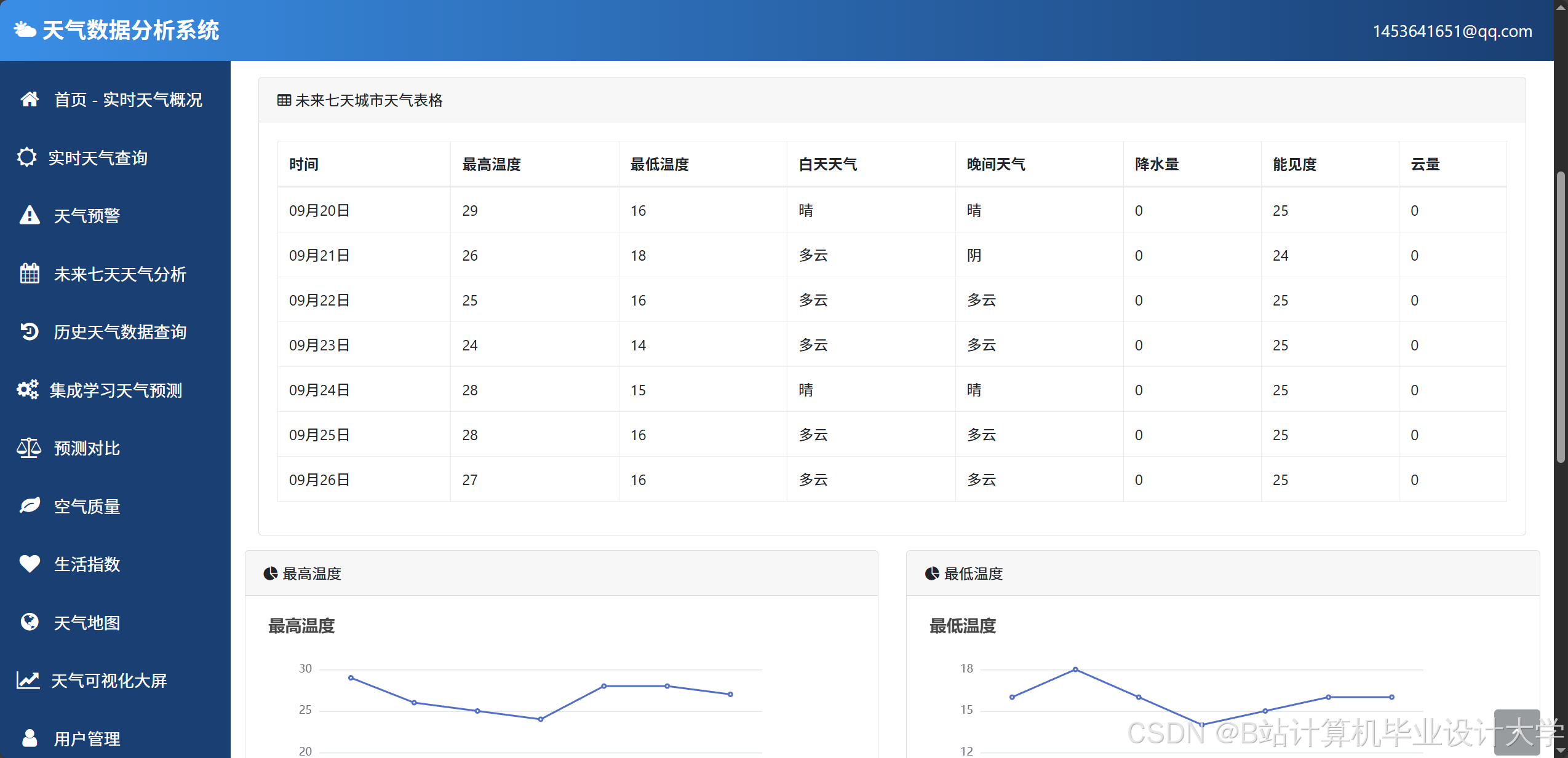
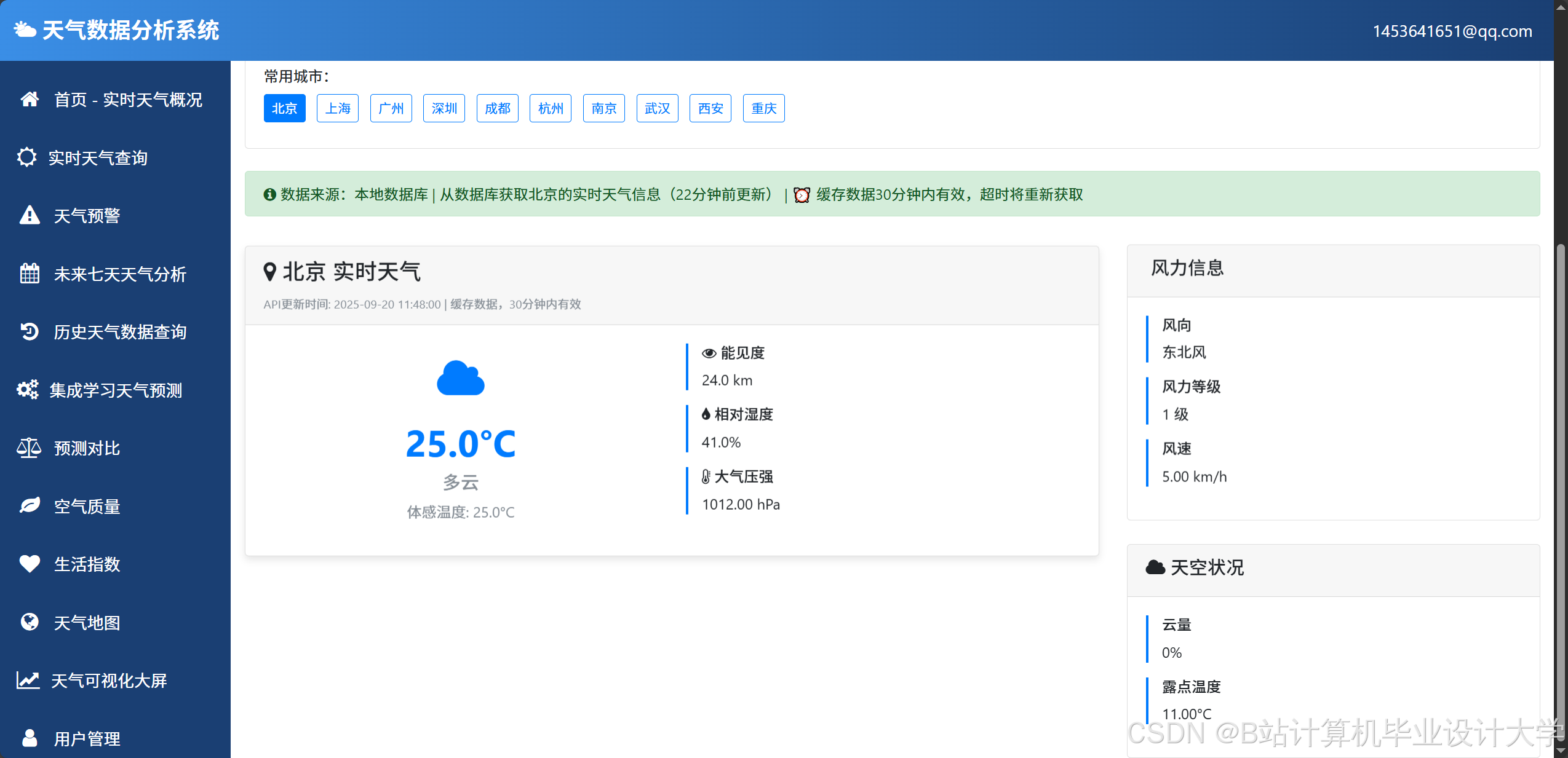
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











