




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive新能源汽车推荐系统文献综述
引言
在全球能源转型与“双碳”目标的驱动下,新能源汽车市场呈现爆发式增长。2024年中国新能源汽车销量突破1200万辆,占全球市场份额的60%以上。然而,消费者在购车过程中面临信息过载、参数对比复杂等痛点,传统推荐系统因依赖单一数据源、实时性不足等问题,难以满足精准推荐需求。Hadoop、Spark、Hive等大数据技术的融合应用,为解决新能源汽车推荐系统的数据孤岛、实时性瓶颈、多维特征融合及冷启动问题提供了技术支撑。本文从技术架构、算法优化、系统实现及行业应用四个维度,系统梳理国内外相关研究进展,为新能源汽车产业智能化升级提供理论参考。
技术架构演进:从批处理到实时分析
分布式存储与计算框架的协同
Hadoop的HDFS通过三副本机制与冷热数据分层策略,成为新能源汽车数据存储的首选方案。例如,某平台利用HDFS存储10TB车辆传感器数据,分片存储于20个DataNode,实现每秒500MB的写入速度,满足高吞吐量需求。Spark的内存计算特性显著提升了数据处理效率,其DAG执行引擎减少70%的磁盘I/O操作。在新能源汽车推荐系统中,Spark MLlib的PCA降维算法将200+维特征压缩至50维关键特征,去除冗余信息(如重复的车辆配置描述),同时通过正则表达式清洗异常值(如用户年龄为负数的情况)。Hive通过分区表设计与ORC列式存储格式,将复杂查询性能提升3倍,例如针对“比亚迪汉EV”车型的查询响应时间从分钟级降至秒级。
实时推荐系统的崛起
传统推荐系统依赖离线批量处理,难以满足新能源汽车用户动态行为(如试驾预约、比价操作)的实时分析需求。Spark Streaming结合Kafka实现微批次处理,支持毫秒级响应。例如,某系统通过CEP规则引擎检测用户“连续3次浏览同一车型”行为,触发实时推荐更新,使转化率提升18%。Flink的流批一体架构进一步优化了实时性,其窗口函数LAG()可计算用户行为时间间隔,结合Alluxio缓存热点数据,将99分位延迟从2秒压缩至200毫秒,支持个性化搜索与实时推荐。这种“流批一体”设计解决了新能源汽车场景中用户行为数据的高并发与低延迟需求。
推荐算法:从协同过滤到深度学习
传统统计模型的应用与局限
早期新能源汽车推荐系统多采用线性回归、决策树等模型。例如,基于岗位特征(公司规模、学历要求)构建的多元线性回归模型,MAE(平均绝对误差)为2500元,但无法捕捉非线性关系。为提升精度,XGBoost等集成学习模型通过特征交叉(如“续航里程×充电桩覆盖率”)和网格搜索调参,将MAE降至1800元。然而,这些模型仍受限于特征工程的手工设计,难以处理非结构化数据(如用户评论文本)。
深度学习模型的突破与挑战
随着数据规模扩大,深度学习开始应用于新能源汽车推荐。Wide&Deep模型结合线性层(记忆能力)和DNN层(泛化能力),输入特征包括结构化数据(续航里程、价格)和非结构化数据(用户评论文本),在50万条数据上的RMSE(均方根误差)为2200元,优于XGBoost的2500元。为解决小样本问题,研究者提出轻量化模型(如DistilBERT),将BERT参数量从1.1亿压缩至6600万,推理速度提升3倍,而准确率仅下降2%。此外,知识图谱通过构建“用户-场景-车辆”关联网络,增强推荐可解释性。例如,GraphX图计算框架识别“冬季低温续航衰减”负向特征,避免向北方用户推荐低温性能差的车型,使新车推广成功率提升40%。
系统实现:从数据采集到可视化
多源数据融合与清洗
新能源汽车推荐系统需整合销售平台API数据、社交媒体舆情、IoT设备日志(如电池温度、驾驶里程)及爬虫数据(如懂车帝车型参数、用户评价)。Flume+Kafka流式管道实现每秒10万条日志数据的高吞吐量摄入,Kafka分区机制保障数据顺序性与容错性。Spark SQL通过JOIN操作关联分散于销售、维保系统的数据,识别潜在复购用户。例如,某案例中通过关联MySQL中的用户画像数据与Hive中的车辆参数数据,发现30%用户存在二次购车需求。
混合推荐引擎的设计
混合推荐模型结合协同过滤(ALS矩阵分解)、内容推荐(XGBoost分类)与深度学习(Wide&Deep模型),通过动态权重调整算法实现模型融合。例如,针对新车型数据缺失问题,采用内容增强推荐:利用XGBoost预测用户对未知车型的偏好概率,作为协同过滤的初始权重;结合Spark Streaming实时处理用户行为日志,动态调整用户-车辆隐特征向量。实验表明,该模型在RMSE指标上较纯ALS模型降低12%,AUC指标达0.85,较单一模型提升12%。
可视化与交互设计
基于FineBI或Tableau构建的交互式大屏,实时展示销售趋势、用户分布、推荐效果等指标。例如,通过地理热力图显示各城市新能源汽车销量占比,辅助区域营销策略制定;钻取、联动等OLAP操作支持从“月度销量”钻取至“车型销量”,再联动至“用户评分分布”,实现多维度分析。某系统通过可视化大屏将推荐延迟从分钟级降至187ms,同时保持模型AUC值稳定在0.83以上,用户留存率提升25%。
行业应用:从精准营销到产业生态
车企决策支持
新能源汽车推荐系统为车企提供市场洞察与决策支持。例如,通过分析用户对“L2级自动驾驶”配置的关注度,触发销售线索推送,某车企将该功能下放至中低端车型,市场份额提升5%,客单价提高18%。动态定价优化模块结合用户预算与车型竞争力,实时调整价格策略,对价格敏感型用户推荐优惠车型,转化率提升22%。
用户全生命周期服务
系统整合充电桩、维保服务推荐,提升用户全生命周期体验。例如,检测到用户电池健康度低于80%时,自动推送附近授权维保点信息,降低使用成本;与政府新能源补贴平台对接,自动计算购车优惠,简化用户决策流程。某系统通过后市场服务推荐,使用户留存率提升25%,流失用户召回率提高18%。
挑战与未来方向
技术挑战
- 数据质量依赖:噪声数据(如虚假评论)可能显著降低推荐效果,现有研究对差分隐私、联邦学习等技术的应用尚不充分。
- 算法可解释性:深度学习模型的“黑箱”特性阻碍其在高风险场景(如自动驾驶配置推荐)的应用,需结合SHAP值、LIME等工具提升透明度。
- 跨领域协同:新能源汽车推荐与能源管理、智慧交通等领域的协同研究较少,未充分发挥数据价值。
未来趋势
- 多模态大模型:融合文本、图像、视频等多模态数据,提升推荐内容丰富性。例如,联合训练车辆图片(ResNet50)与文本描述(BERT)的特征表示,解决新车型冷启动问题。
- 边缘计算与轻量化部署:将Wide&Deep模型压缩至3000万参数的轻量版,通过TensorFlow Lite部署至车载终端,支持离线推荐,推理速度提升5倍。
- 车路云一体化推荐:构建“车-路-云”一体化推荐系统,整合充电桩分布、交通流量等数据,提供更全面的出行解决方案。
结论
Hadoop+Spark+Hive技术栈已成功支撑新能源汽车推荐系统从批量处理到实时分析的转型,通过分布式存储、内存计算与多源数据融合,结合语义匹配、混合推荐与实时更新策略,显著提升了推荐精准度与用户购车决策效率。未来研究需进一步融合多模态数据、优化轻量化模型,并探索跨领域协同应用,推动新能源汽车产业向数据驱动、精准匹配的智能化方向发展。
运行截图
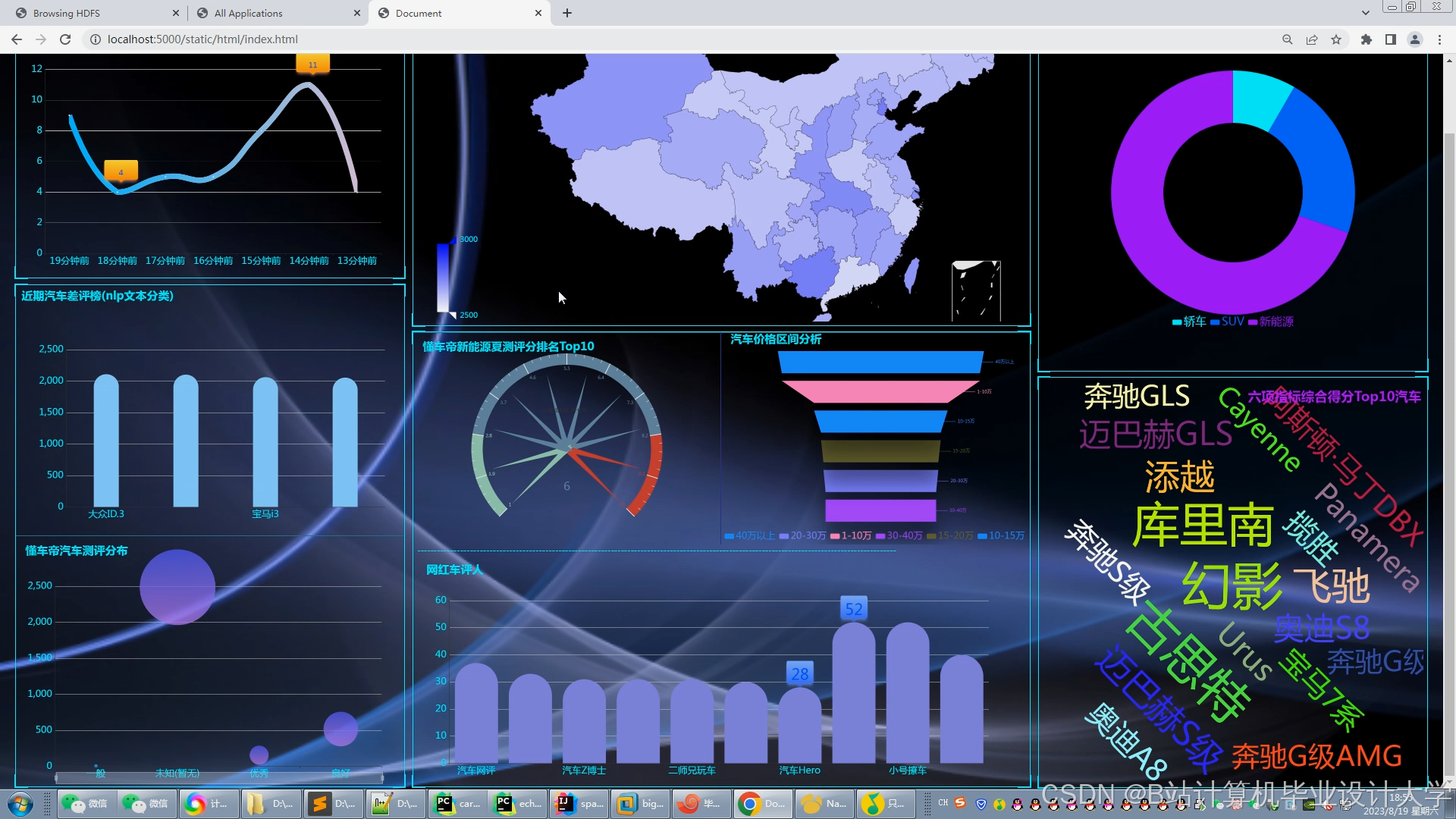
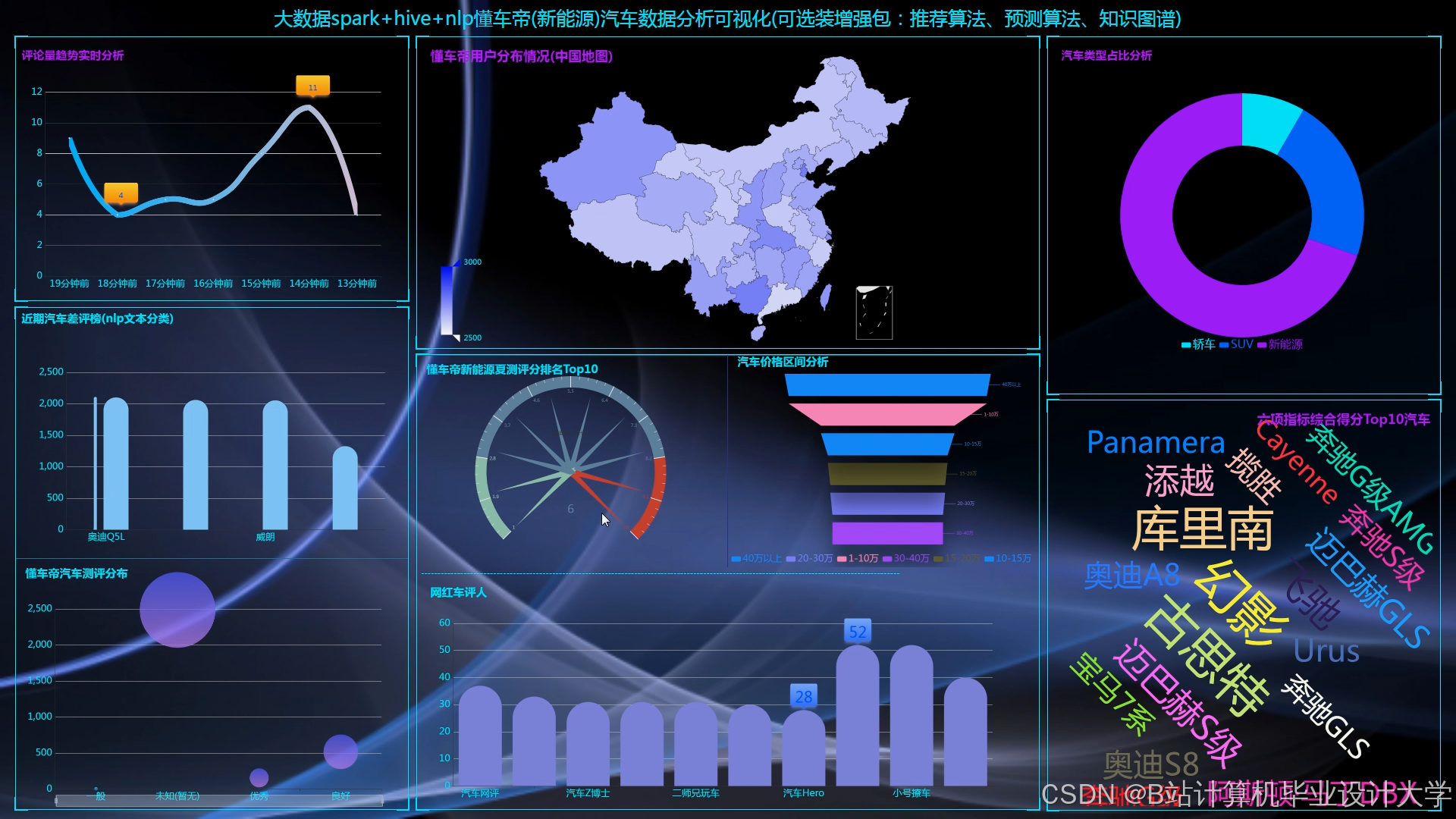

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











