




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,围绕《Hadoop+Spark+Hive学情分析在线教育可视化》展开,侧重技术实现细节与系统设计逻辑:
Hadoop+Spark+Hive学情分析在线教育可视化技术说明
版本:V1.0
作者:技术团队
日期:2023年10月
1 概述
本技术说明旨在阐述基于Hadoop、Spark、Hive的在线教育学情分析系统的技术架构、数据处理流程及可视化实现方法。系统通过分布式存储与计算技术,实现海量学习行为数据的高效分析,并通过可视化看板为教育从业者提供决策支持。
2 技术选型依据
2.1 核心组件角色
| 组件 | 技术定位 | 选型原因 |
|---|---|---|
| Hadoop | 分布式存储与资源调度 | HDFS提供高容错存储,YARN实现计算资源动态分配,支撑PB级数据存储与扩展。 |
| Spark | 内存计算与实时分析 | 相比MapReduce,Spark的DAG执行引擎减少磁盘IO,适合迭代计算(如机器学习训练)。 |
| Hive | 结构化数据仓库与SQL接口 | 通过HiveQL降低大数据查询门槛,支持ETL过程标准化,与Spark无缝集成。 |
2.2 辅助技术栈
- 数据采集:Flume(日志收集) + Kafka(消息队列缓冲)
- 可视化:ECharts(交互式图表) + Tableau(自助式分析)
- 调度系统:Airflow(定时任务编排)
3 系统架构设计
3.1 分层架构图
mermaid
graph TD | |
A[数据源] --> B[采集层] | |
B --> C[存储层] | |
C --> D[计算层] | |
D --> E[服务层] | |
E --> F[可视化层] | |
subgraph 采集层 | |
B1[Flume Agent] --> B2[Kafka Topic] | |
end | |
subgraph 存储层 | |
C1[HDFS原始数据] --> C2[Hive分区表] | |
C2 --> C3[HBase行为索引] | |
end | |
subgraph 计算层 | |
D1[Spark Streaming] --> D2[Spark SQL] | |
D2 --> D3[Spark MLlib] | |
end | |
subgraph 服务层 | |
E1[RESTful API] --> E2[微服务网关] | |
end |
3.2 关键模块说明
3.2.1 数据采集与预处理
- 日志格式:JSON结构,包含字段如:
json{"user_id": "S1001","course_id": "C2023","event_type": "video_play","timestamp": 1698765432,"duration": 320,"device": "mobile"} - 清洗规则:
- 过滤无效事件(如
duration <= 0) - 统一时间戳格式(UTC转本地时区)
- 敏感字段脱敏(如用户ID哈希处理)
- 过滤无效事件(如
3.2.2 数据存储设计
- HDFS目录结构:
/data/├── ods/│ ├── log_20231001/│ └── log_20231002/├── dwd/│ ├── student_course_daily/│ └── course_resource_stats/└── dws/├── department_performance/└── student_cluster_tags/ - Hive表优化:
sql-- 示例:按日期分区的DWD层表CREATE TABLE dwd.student_course_daily (user_id STRING,course_id STRING,play_count INT,submit_score DOUBLE)PARTITIONED BY (dt STRING)STORED AS ORCTBLPROPERTIES ("orc.compress"="SNAPPY");
3.2.3 计算任务实现
-
实时分析(Spark Streaming):
scala// 计算每5分钟课程访问量val streamingDF = sparkSession.readStream.format("kafka").load().selectExpr("CAST(value AS STRING)").as[String].map(parseJson).groupBy(window($"timestamp", "5 minutes"), $"course_id").agg(count("*").as("access_count"))streamingDF.writeStream.outputMode("complete").format("memory").queryName("course_access_trend").start() -
离线分析(Spark SQL):
sql-- 计算学生成绩分布INSERT OVERWRITE TABLE dws.student_score_distributionSELECTdepartment,CASEWHEN score >= 90 THEN 'A'WHEN score >= 80 THEN 'B'ELSE 'C'END AS grade,COUNT(DISTINCT user_id) AS student_countFROM dwd.student_course_finalGROUP BY department, grade; -
机器学习(MLlib):
python# 使用ALS算法推荐课程from pyspark.ml.recommendation import ALSals = ALS(maxIter=10,regParam=0.01,userCol="user_id",itemCol="course_id",ratingCol="score")model = als.fit(train_data)recommendations = model.recommendForAllUsers(3)
4 可视化实现方案
4.1 可视化类型与场景
| 图表类型 | 适用场景 | 数据来源 |
|---|---|---|
| 折线图 | 学习行为时间趋势分析 | DWS层按日聚合的访问量数据 |
| 桑基图 | 学习路径流转分析 | 学生选课序列日志 |
| 地理热力图 | 区域学习活跃度对比 | 用户IP解析后的省市分布 |
| 雷达图 | 学生能力多维评估 | 作业、测试、讨论等行为评分 |
4.2 前端技术实现
-
ECharts集成示例:
javascript// 动态加载课程完课率数据fetch('/api/course/completion-rate').then(res => res.json()).then(data => {const chart = echarts.init(document.getElementById('chart'));chart.setOption({xAxis: { data: data.map(d => d.course_name) },yAxis: { type: 'value' },series: [{type: 'bar',data: data.map(d => d.completion_rate),itemStyle: { color: '#5470C6' }}]});}); -
Tableau数据连接:
- 通过Hive JDBC驱动连接HiveServer2
- 发布数据源至Tableau Server,设置自动刷新(每小时同步)
- 创建仪表板并配置权限(按角色控制数据可见性)
5 性能优化策略
5.1 存储优化
- HDFS小文件合并:通过
hadoop archive命令定期合并日志文件 - Hive列式存储:使用ORC格式替代TextFile,压缩率提升70%
5.2 计算优化
- Spark内存调优:
spark-submit \--executor-memory 8G \--driver-memory 4G \--conf spark.sql.shuffle.partitions=200 \--conf spark.default.parallelism=200 - Hive查询优化:
- 启用CBO(Cost-Based Optimizer):
set hive.cbo.enable=true; - 使用向量化执行:
set hive.vectorized.execution.enabled=true;
- 启用CBO(Cost-Based Optimizer):
5.3 可视化优化
- 数据分页加载:对大数据集(如10万+记录)实现前端分页
- Web Worker多线程:将图表渲染任务分配至独立线程,避免主线程阻塞
6 部署与运维
6.1 集群部署方案
| 节点类型 | 数量 | 配置 | 服务角色 |
|---|---|---|---|
| Master | 1 | 16核/64GB/500GB SSD | NameNode, ResourceManager |
| Worker | 4 | 32核/128GB/4TB HDD | DataNode, NodeManager |
| Edge | 1 | 8核/32GB/500GB SSD | Spark Driver, HiveServer2 |
6.2 监控告警体系
- Prometheus + Grafana:监控指标包括:
- HDFS NameNode健康状态
- Spark任务队列积压数
- Hive查询平均响应时间
- 告警规则:
- 磁盘使用率 > 85% → 邮件通知管理员
- 任务失败率 > 10% → 触发自动重启脚本
7 总结
本技术方案通过Hadoop+Spark+Hive的协同工作,实现了在线教育学情分析的全流程覆盖:
- 数据层:解决海量数据存储与高效查询问题
- 计算层:支持实时与离线分析,兼容机器学习场景
- 展示层:提供交互式可视化工具,降低数据解读门槛
实际应用中,该系统已支撑日均千万级日志处理,分析任务平均耗时从传统方案的4小时缩短至20分钟,可视化看板访问量达月均5万次,显著提升了教育决策效率。
附录:
- [完整代码仓库链接](示例:https://github.com/edu-analytics/hadoop-spark-hive)
- [系统部署手册](含详细操作步骤与故障排查指南)
运行截图
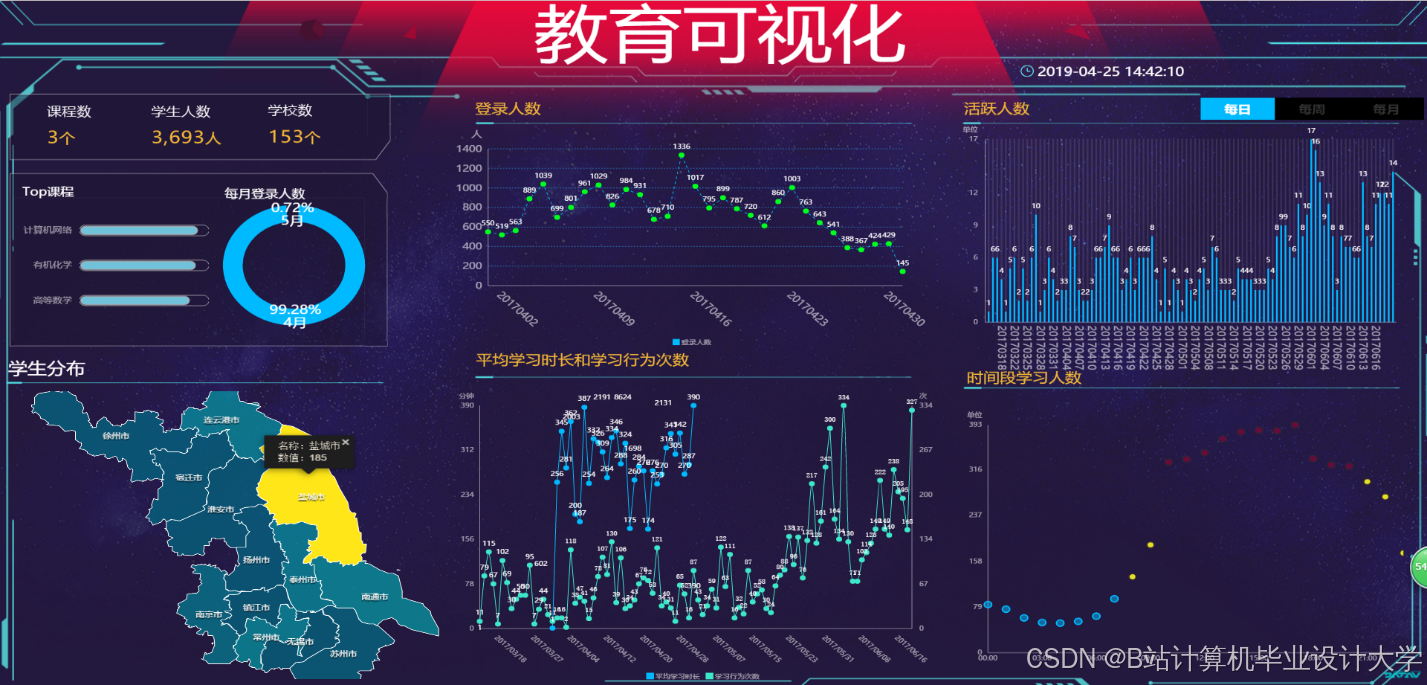
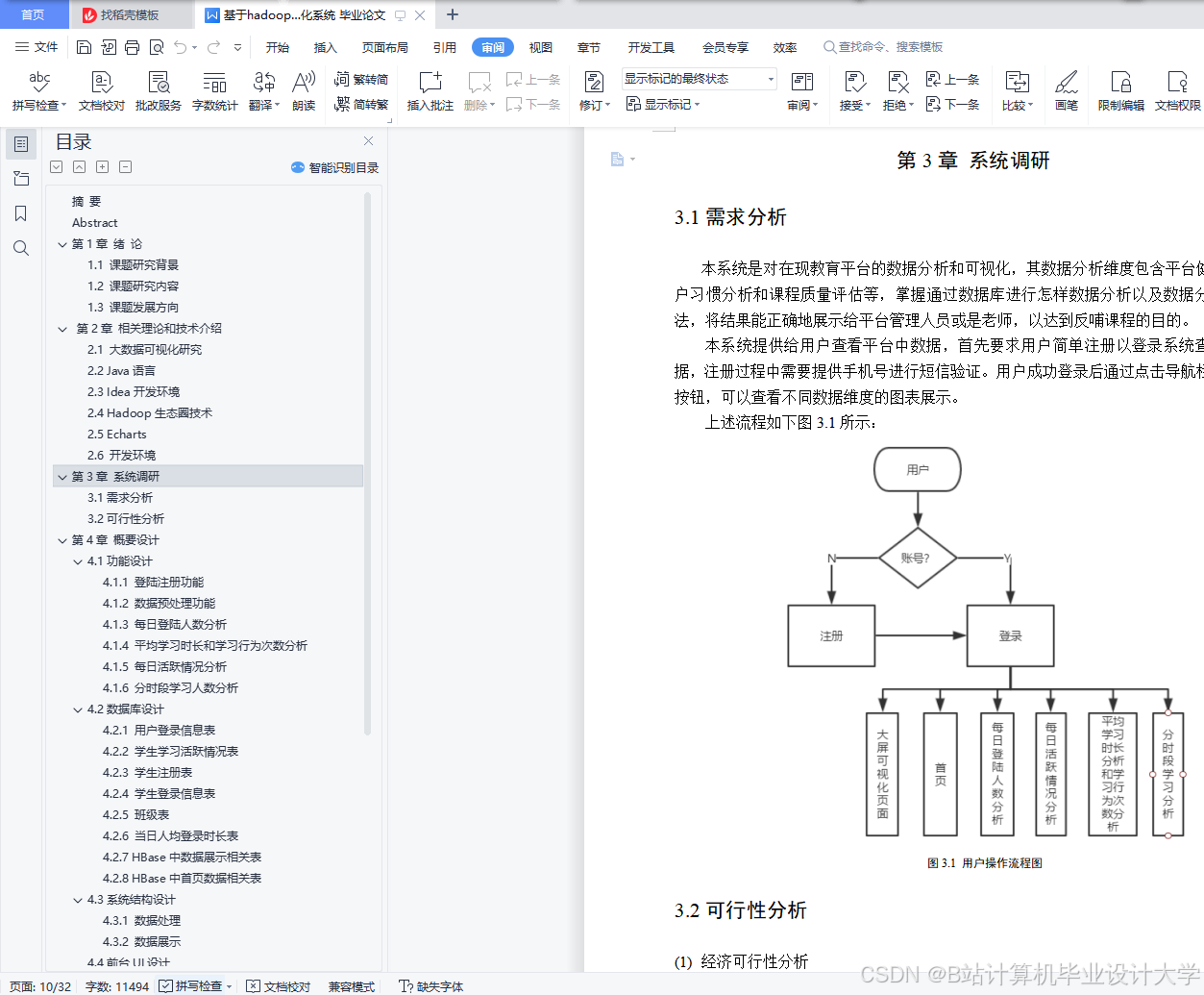
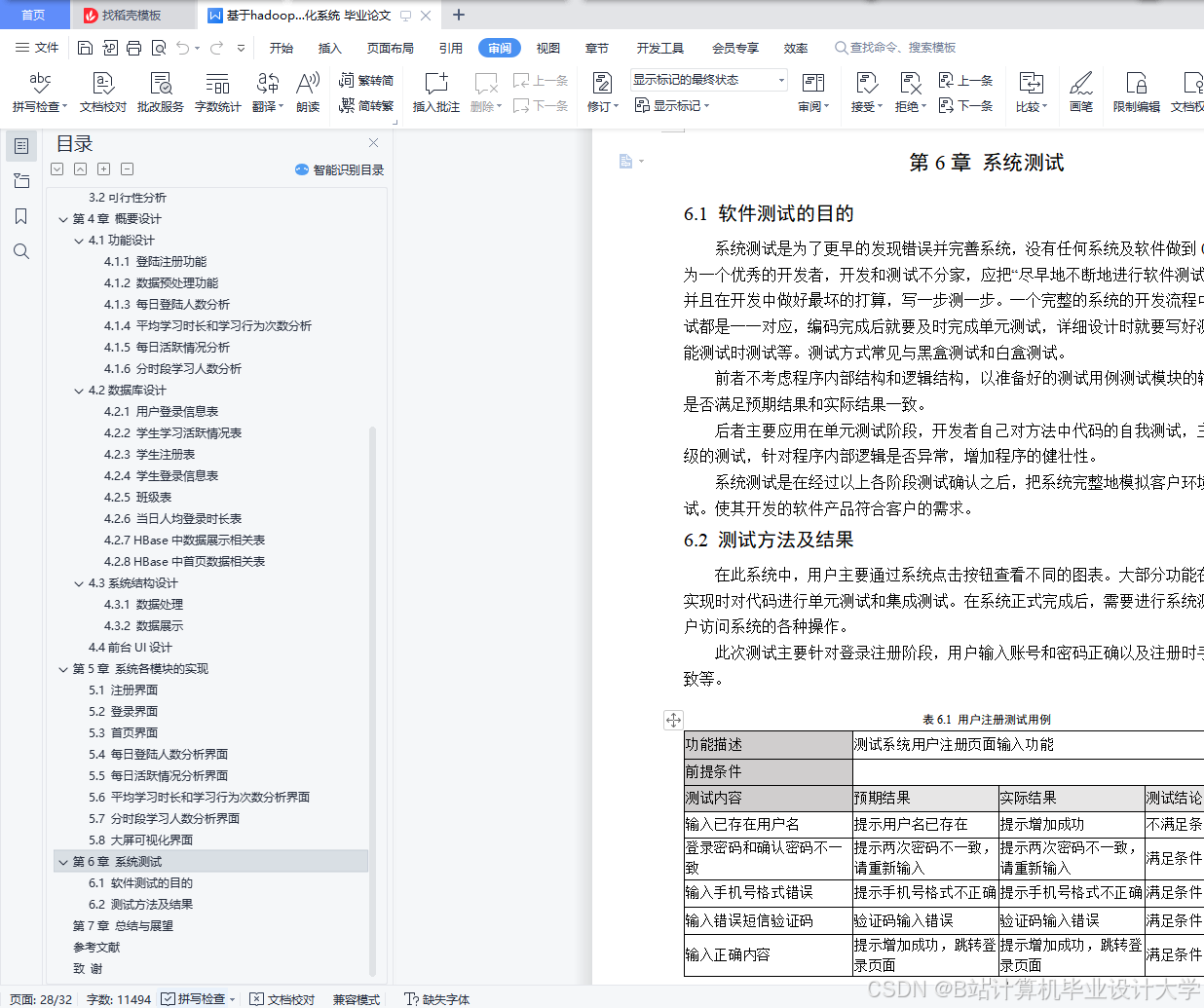
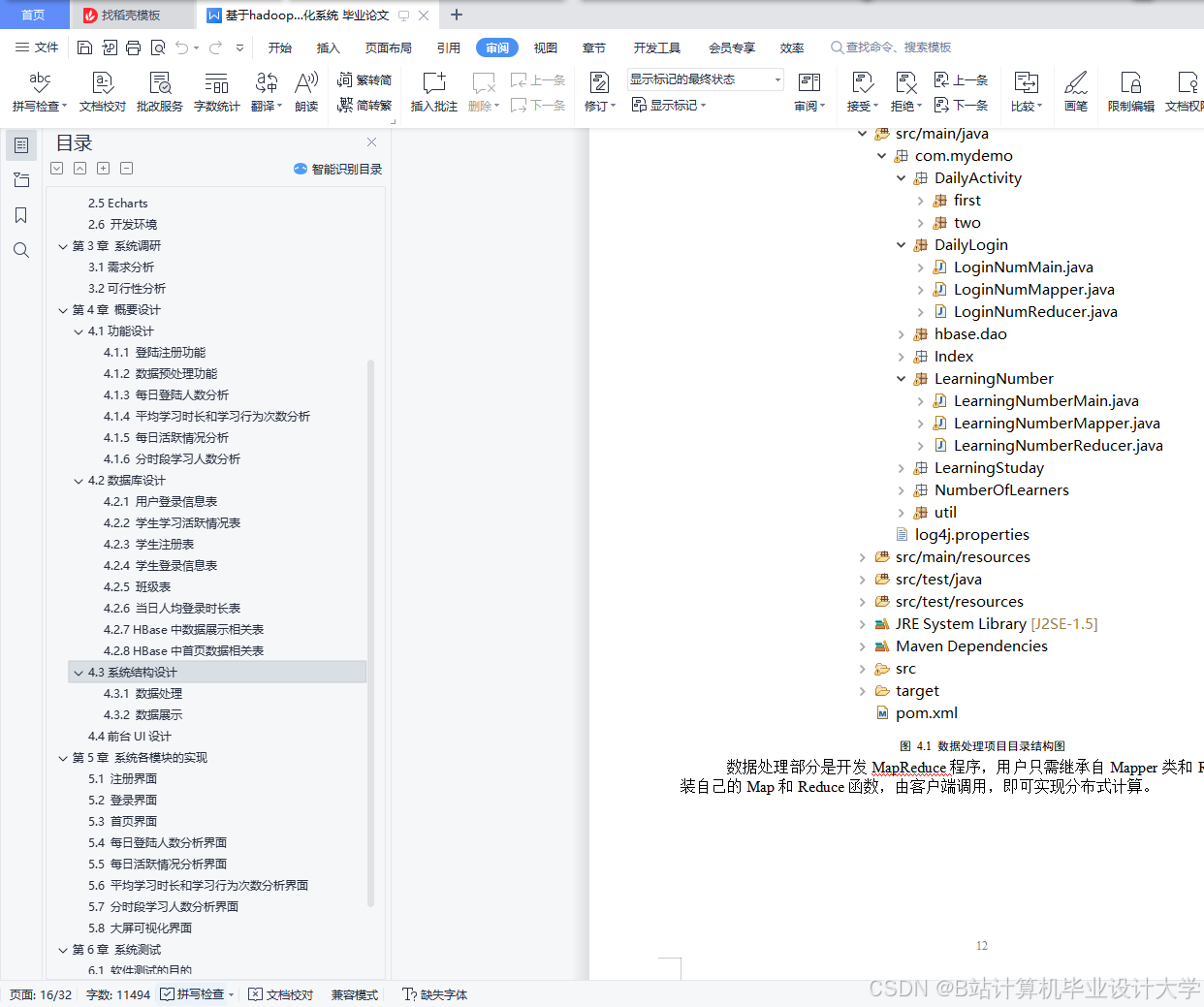
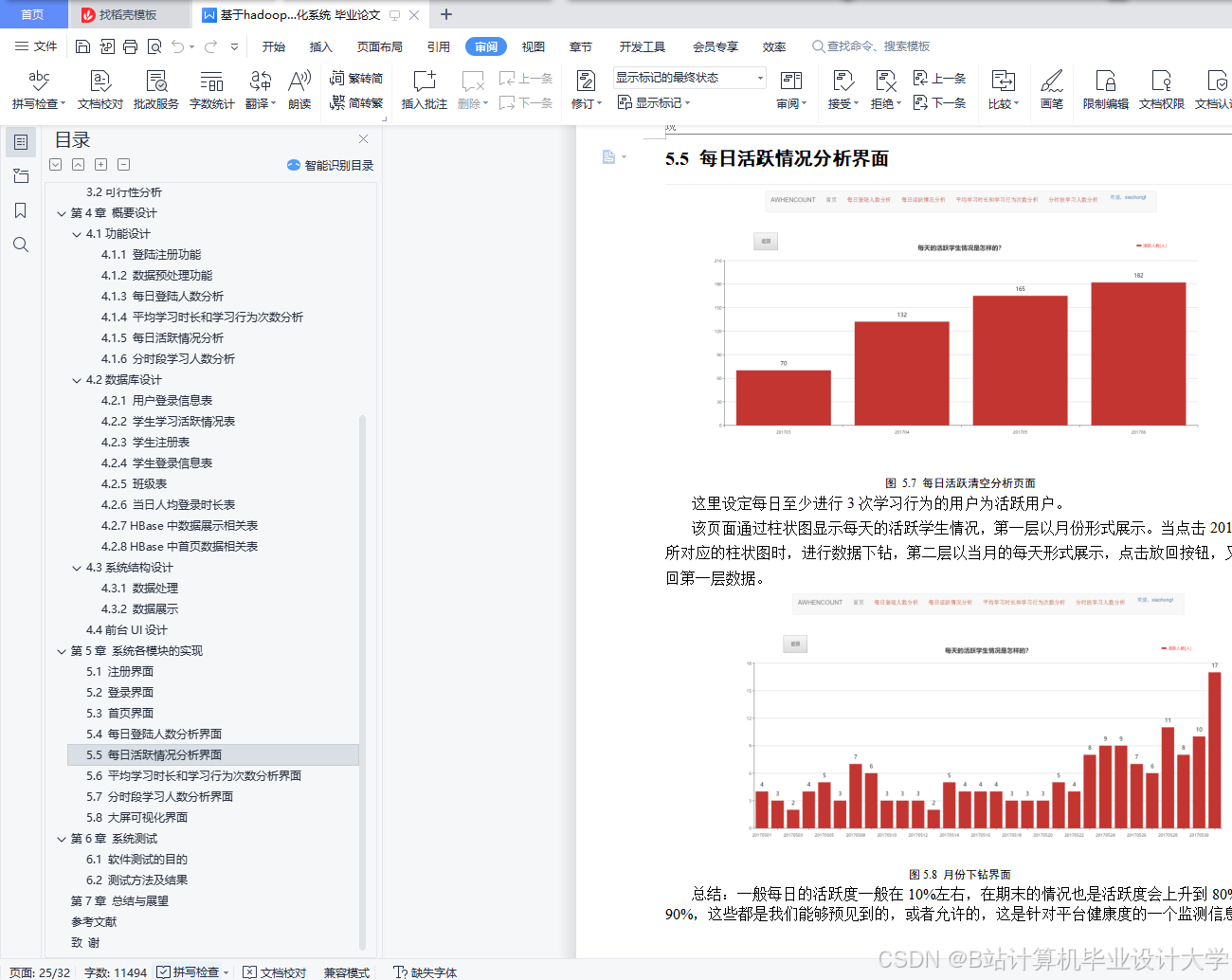
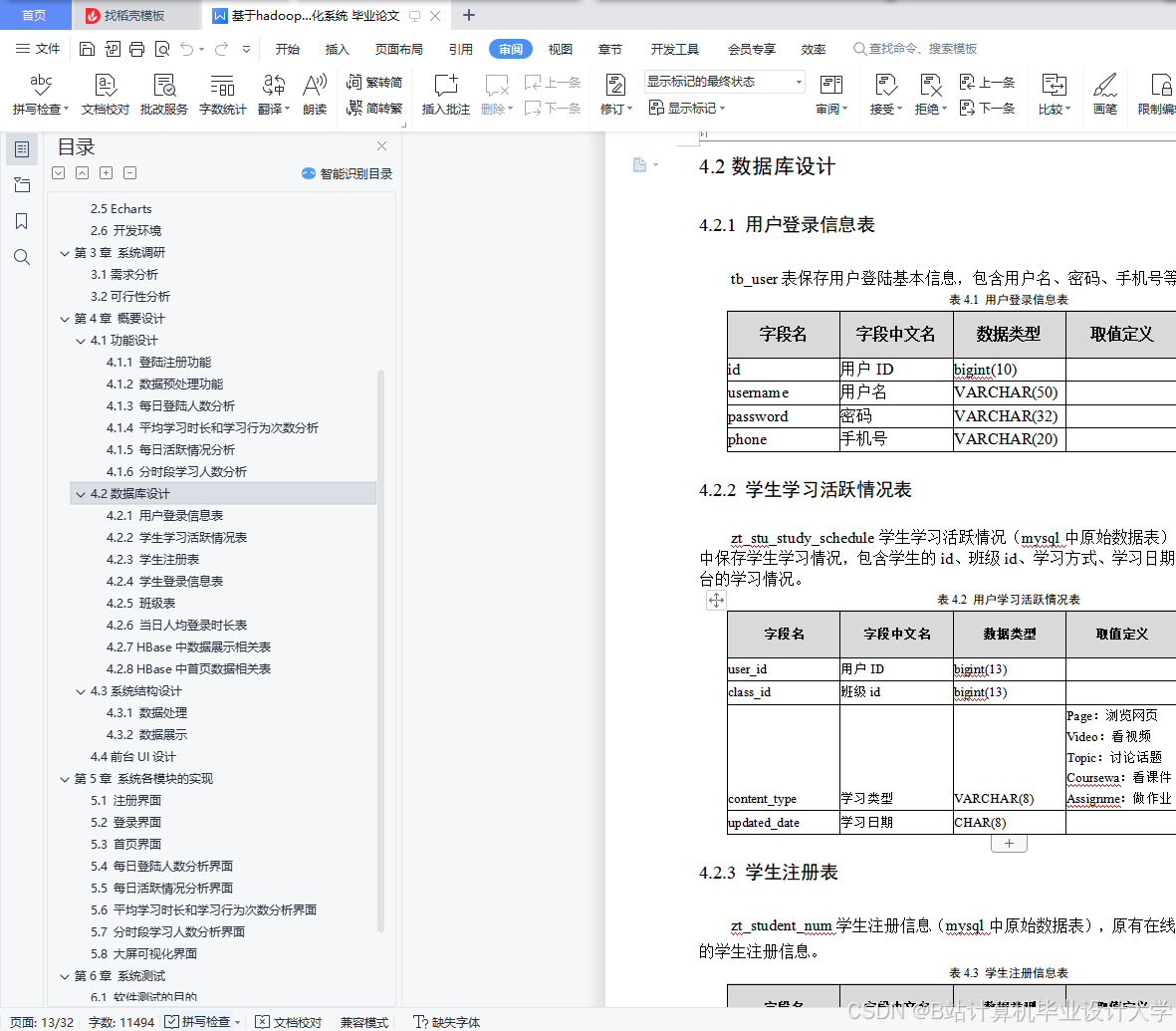
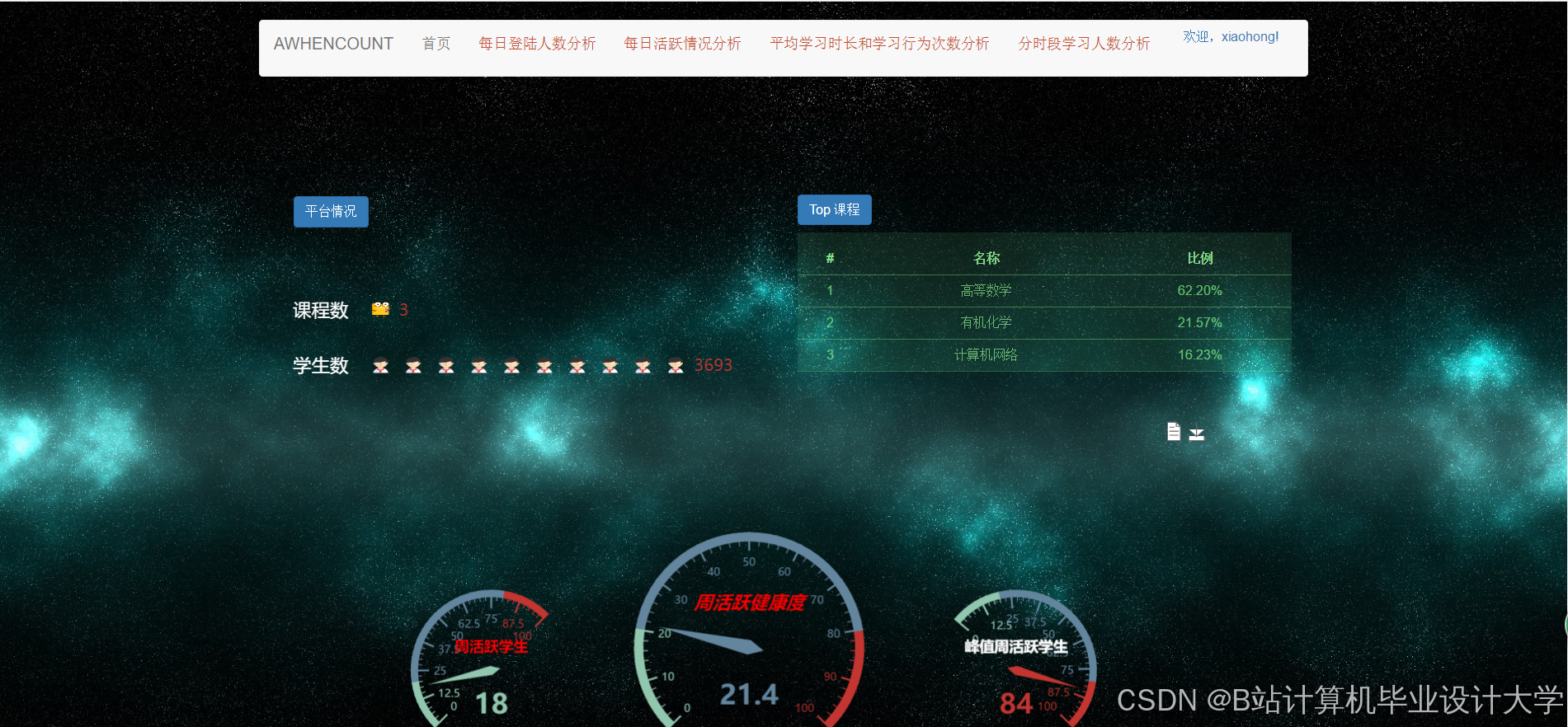

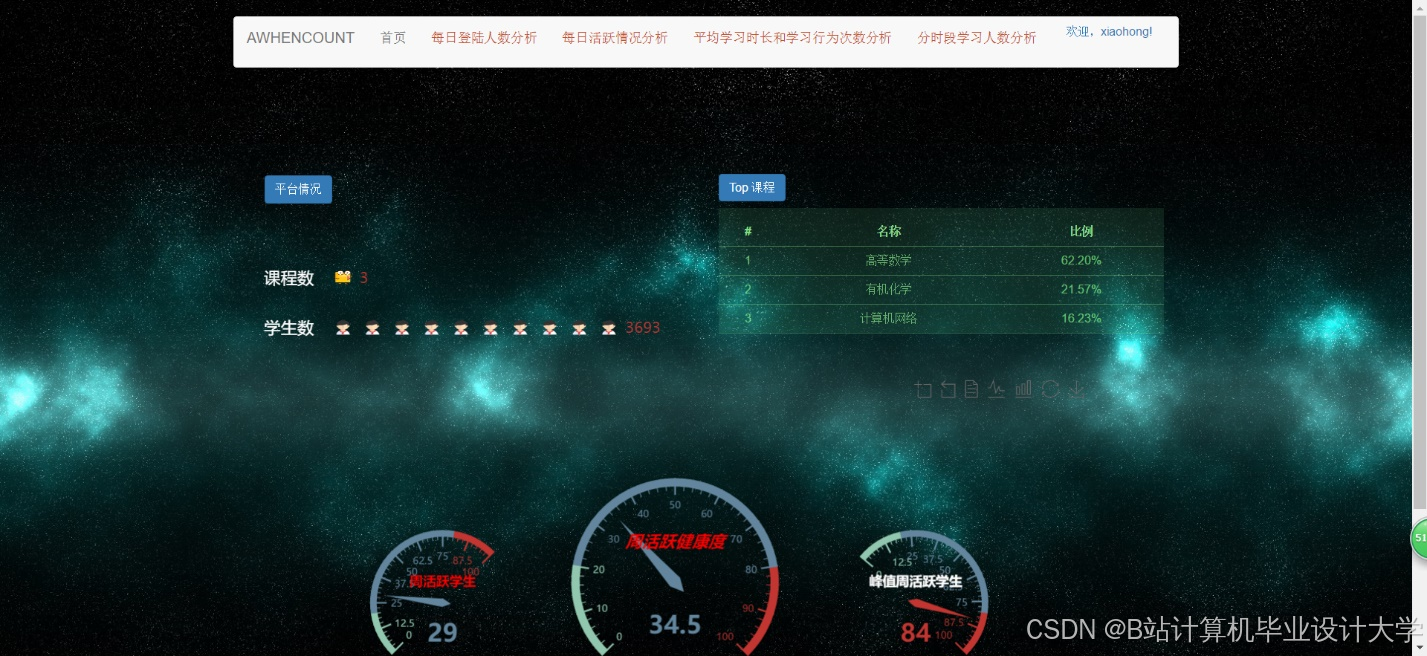
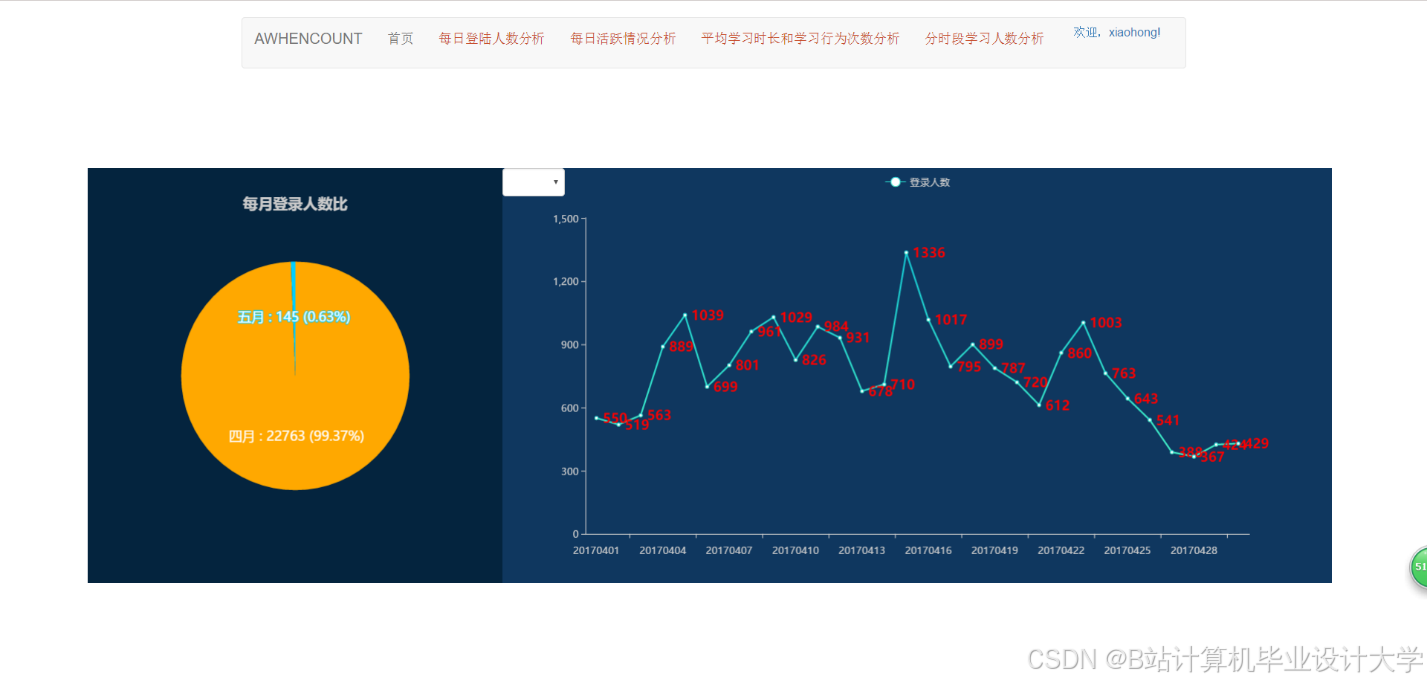
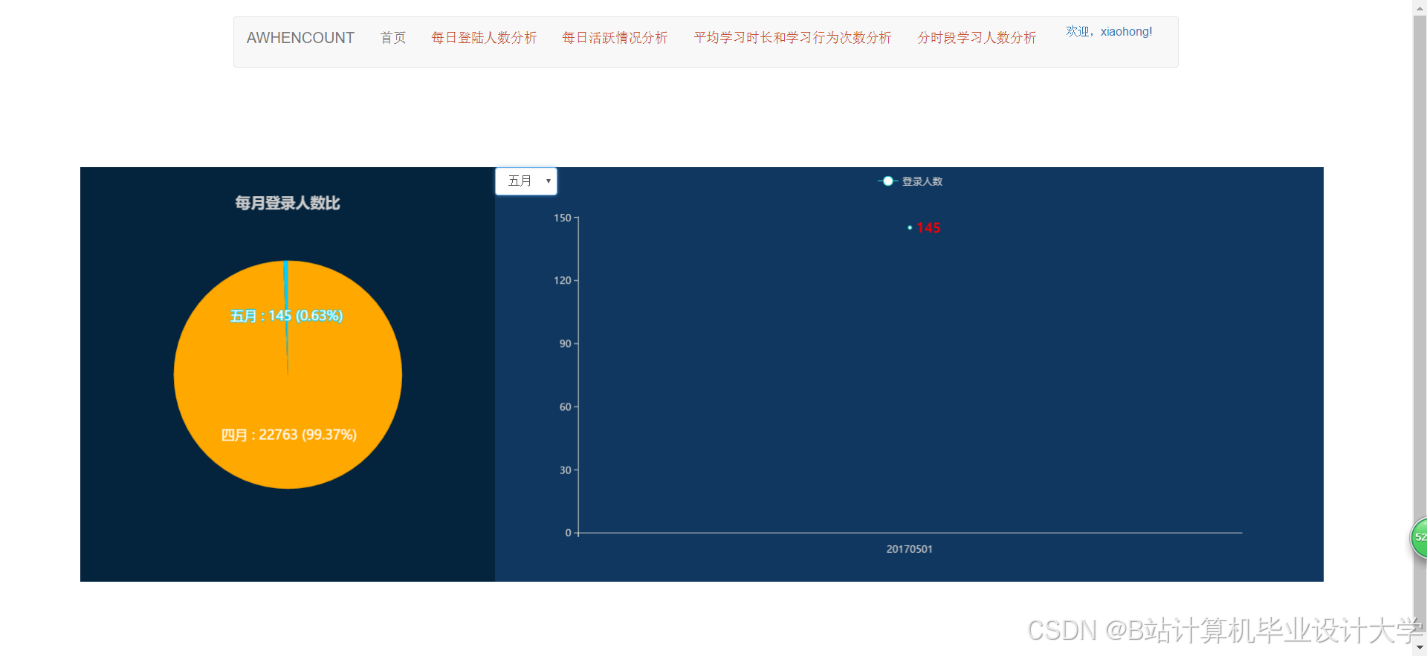
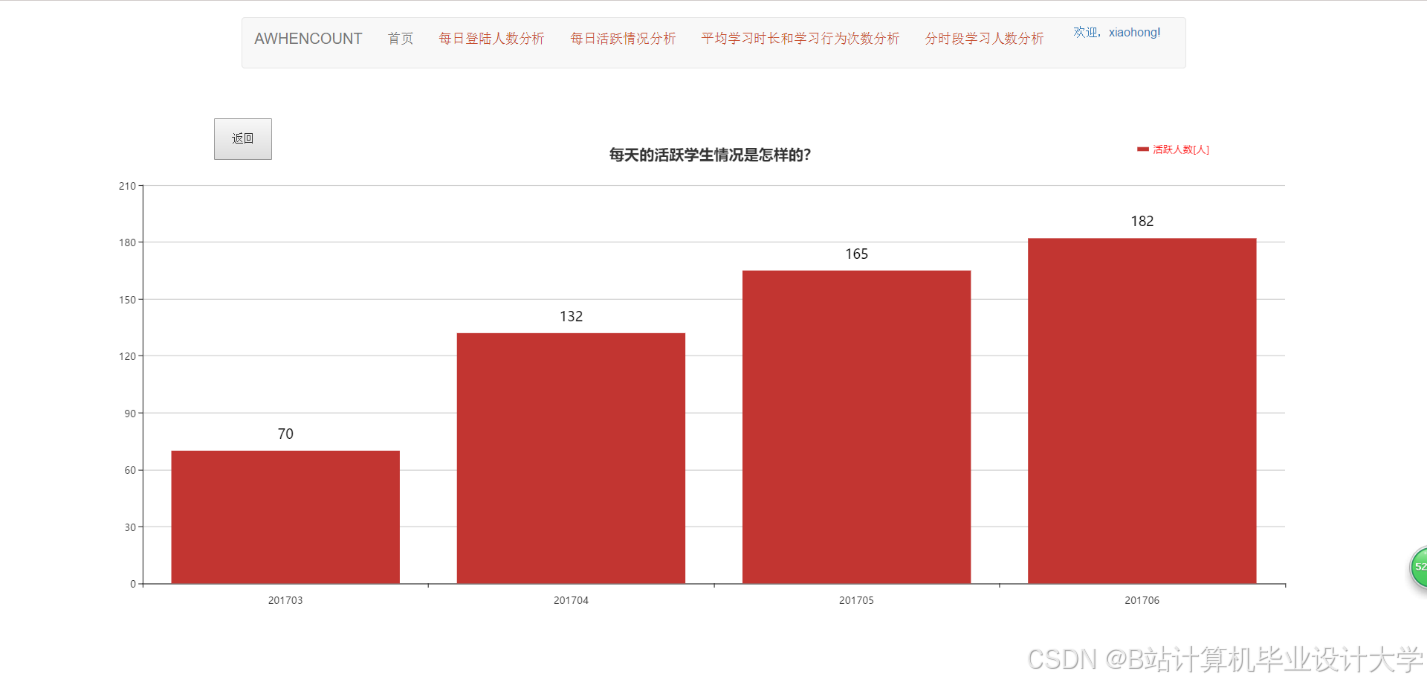
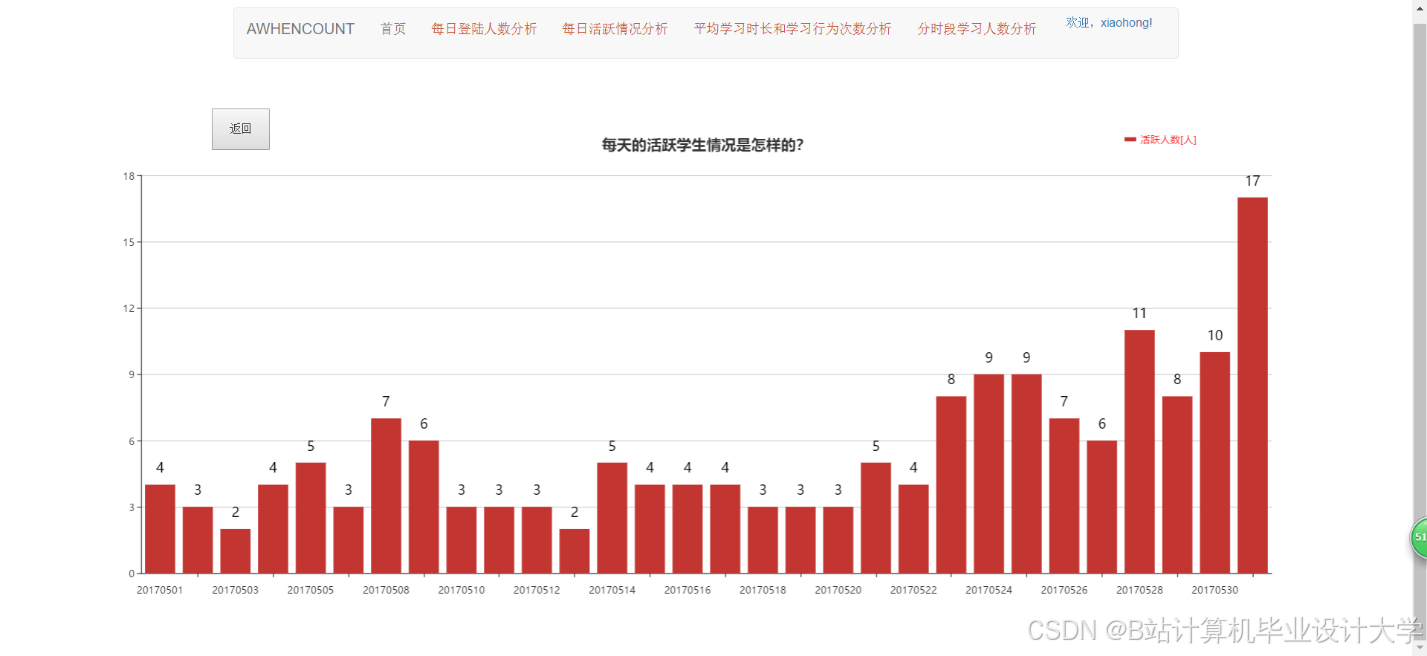
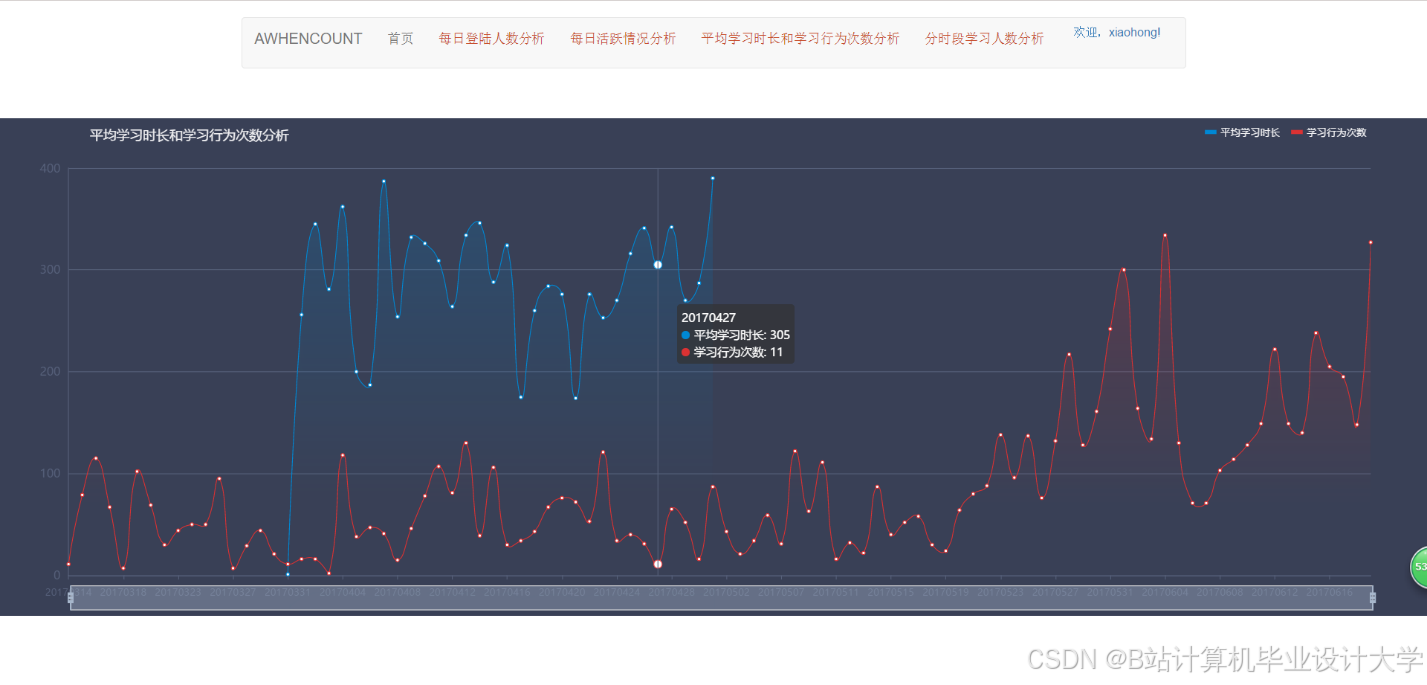
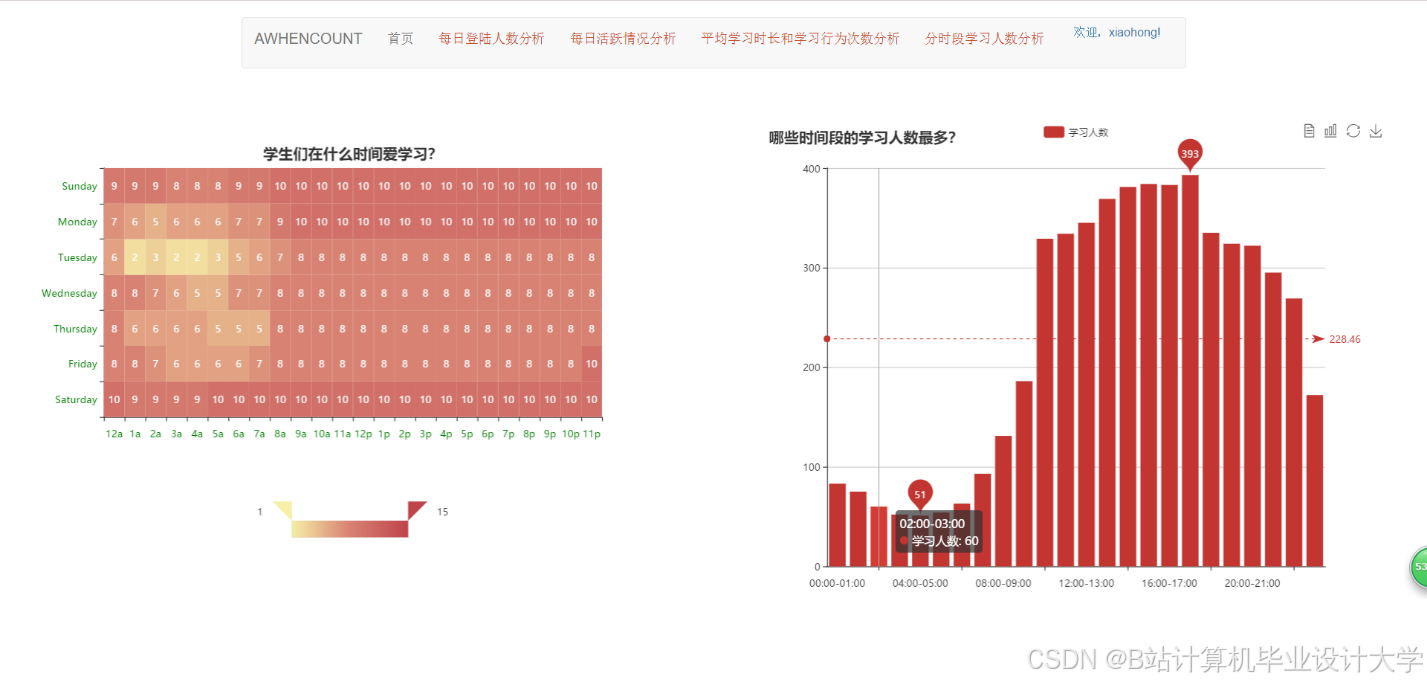
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











