




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型房价预测系统技术说明
——基于深度学习与自然语言处理的房地产估值平台
一、项目背景与目标
房地产市场的价格受地理位置、经济指标、政策、社区环境等多维度因素影响,传统估值方法(如市场比较法、收益法)依赖人工经验,难以处理非结构化数据(如新闻、社交媒体情绪)。本系统结合Django(Web框架)与LLM(大语言模型,如GPT-4、Llama 2),构建一个智能化房价预测平台,实现:
- 多模态数据融合:整合结构化数据(历史成交价、房屋特征)与非结构化数据(新闻、政策文本、用户评论)。
- 动态预测模型:利用LLM提取文本中的关键信息,结合时序模型(如LSTM)预测未来房价趋势。
- 个性化推荐:根据用户需求(如预算、区域偏好)推荐房源并生成估值报告。
- 实时风险预警:当预测价格偏离预期阈值时触发提醒(如政策变动、市场波动)。
二、技术架构设计
系统采用前后端分离架构,核心组件如下:
1. 整体架构图
1┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐
2│ 前端(Vue/ │ ←→ │ Django后端 │ ←→ │ LLM服务层 │ ←→ │ 数据源 │
3│ React) │ │(API服务) │ │(文本处理/ │ │(爬虫/政府 │
4│(用户交互) │ └───────────────┘ │ 特征提取) │ │ 开放数据) │
5└───────────────┘ └───────────────┘ └───────────────┘
6 ↑ ↑
7┌───────────────┐ ┌───────────────┐
8│ 数据库(MySQL │ │ 缓存(Redis) │
9│ /PostgreSQL) │ └───────────────┘
10└───────────────┘2. 核心组件选型
| 组件 | 角色 | 技术选型理由 |
|---|---|---|
| Django | 后端框架 | 快速开发RESTful API,内置ORM、用户认证,适合中大型项目。 |
| LLM(如Llama 2) | 自然语言处理 | 提取新闻、政策文本中的关键信息(如“限购政策”“利率调整”),生成影响房价的特征向量。 |
| TensorFlow/PyTorch | 时序预测 | 结合LLM输出的特征,用LSTM/Transformer预测房价趋势。 |
| MySQL | 关系型数据库 | 存储房屋特征、历史成交价、用户信息等结构化数据。 |
| Redis | 缓存与消息队列 | 缓存高频查询的预测结果,使用Celery实现异步任务(如爬取新闻、模型训练)。 |
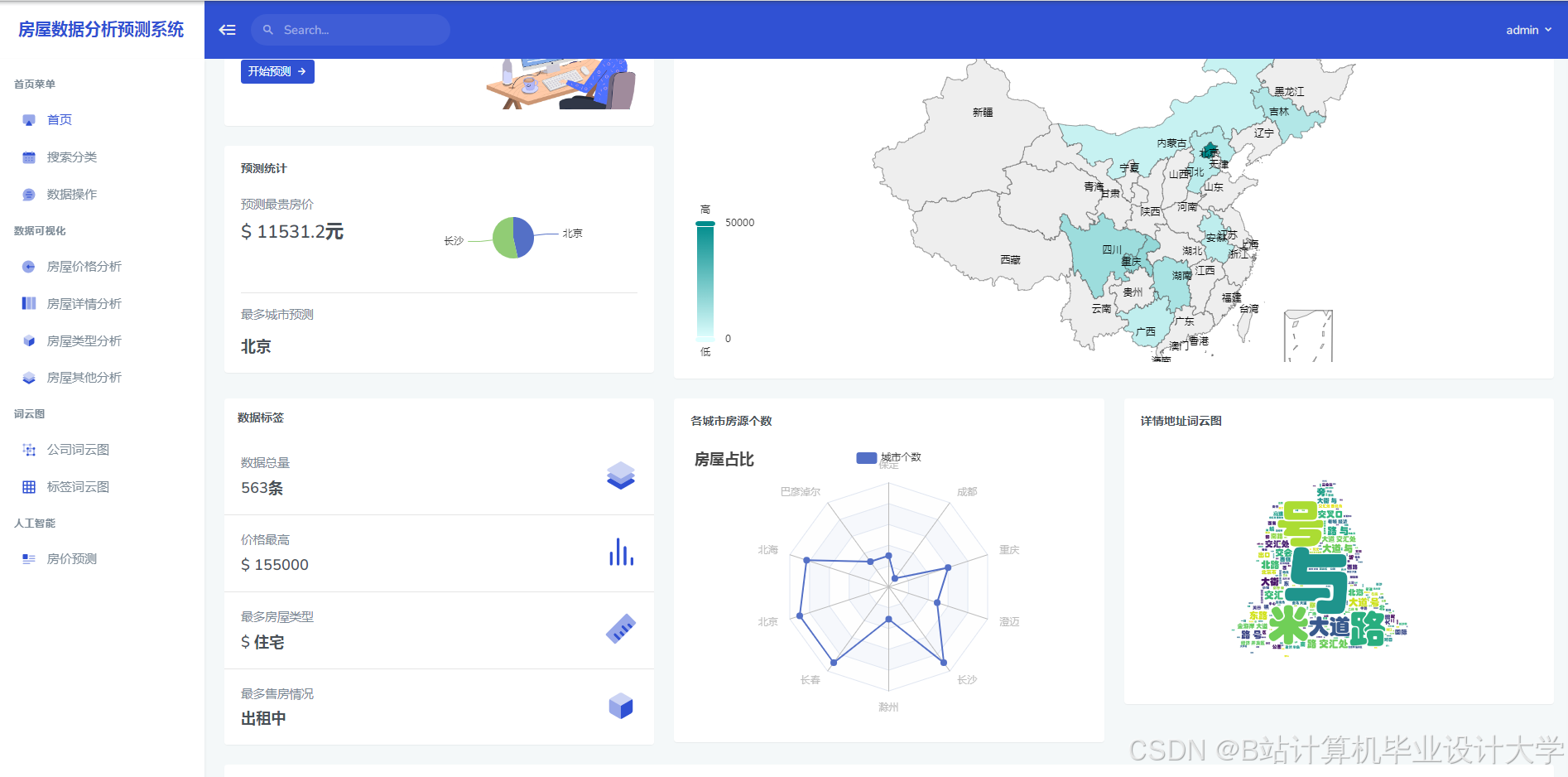
| ECharts | 数据可视化 | 前端展示房价历史趋势、预测结果与区域热力图。 |
三、核心功能实现
1. 数据采集与预处理
(1)数据源
- 结构化数据:
- 历史成交价:从政府开放平台(如北京住建委)或爬取房产网站(如链家、贝壳)。
- 房屋特征:面积、户型、楼层、装修、学区等(通过API或爬虫获取)。
- 非结构化数据:
- 新闻政策:爬取新华网、政府官网的房地产相关新闻。
- 用户评论:社交媒体(微博、知乎)中关于房价的讨论。
(2)数据预处理(Python示例)
python
1import pandas as pd
2from sklearn.preprocessing import MinMaxScaler
3import re
4from langchain.embeddings import HuggingFaceEmbeddings # 用于文本向量化
5
6# 结构化数据处理(房价与房屋特征)
7def preprocess_structured_data(df):
8 df['price_per_sqm'] = df['total_price'] / df['area'] # 计算单价
9 df['age'] = 2023 - df['build_year'] # 房龄
10 # 分类特征编码(如户型、装修)
11 df = pd.get_dummies(df, columns=['layout', 'decoration'], prefix=['layout', 'decoration'])
12 return df
13
14# 非结构化数据处理(新闻文本)
15def extract_text_features(texts):
16 embeddings_model = HuggingFaceEmbeddings(model_name="paraphrase-multilingual-MiniLM-L12-v2")
17 embeddings = embeddings_model.embed_documents(texts) # 生成文本向量
18 return embeddings
19
20# 示例:处理一条新闻
21news_text = "北京市发布新政:非京籍家庭购房社保年限由5年缩短至3年。"
22keywords = re.findall(r'购房|限购|利率|税费|社保', news_text) # 简单关键词提取
23features = extract_text_features([news_text]) # 生成向量2. 房价预测模型(LLM + LSTM)
(1)模型设计思路
- 文本特征提取:用LLM将新闻、政策文本转换为向量,捕捉市场情绪与政策影响。
- 时序预测:将文本向量与结构化数据(历史房价、房屋特征)拼接,输入LSTM预测未来价格。
- 多任务学习:同时预测价格绝对值与涨跌幅(提升模型鲁棒性)。
(2)代码实现(PyTorch示例)
python
1import torch
2import torch.nn as nn
3from torch.utils.data import Dataset, DataLoader
4
5class HousingDataset(Dataset):
6 def __init__(self, structured_data, text_embeddings):
7 self.structured = torch.FloatTensor(structured_data) # 结构化特征(房价、面积等)
8 self.text = torch.FloatTensor(text_embeddings) # 文本向量
9 self.labels = torch.FloatTensor(structured_data[:, 0]) # 假设第0列是目标价格
10
11 def __len__(self):
12 return len(self.structured)
13
14 def __getitem__(self, idx):
15 return self.structured[idx], self.text[idx], self.labels[idx]
16
17class HybridModel(nn.Module):
18 def __init__(self, structured_dim, text_dim, hidden_size=64):
19 super().__init__()
20 self.lstm = nn.LSTM(input_size=structured_dim + text_dim, hidden_size=hidden_size, batch_first=True)
21 self.fc = nn.Linear(hidden_size, 1) # 预测价格
22
23 def forward(self, x_structured, x_text):
24 # 拼接结构化与文本特征
25 x = torch.cat([x_structured, x_text], dim=1)
26 # 假设输入是单时间步(若需时序预测,需调整输入形状为[batch, seq_len, features])
27 out, _ = self.lstm(x.unsqueeze(1)) # 添加seq_len维度
28 out = self.fc(out.squeeze(1))
29 return out
30
31# 训练流程
32model = HybridModel(structured_dim=10, text_dim=384) # 假设结构化特征10维,文本向量384维
33criterion = nn.MSELoss()
34optimizer = torch.optim.Adam(model.parameters())
35
36dataset = HousingDataset(structured_data, text_embeddings)
37dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
38
39for epoch in range(100):
40 for structured, text, labels in dataloader:
41 optimizer.zero_grad()
42 outputs = model(structured, text)
43 loss = criterion(outputs, labels.unsqueeze(1))
44 loss.backward()
45 optimizer.step()
46 print(f"Epoch {epoch}, Loss: {loss.item():.4f}")3. Django后端实现
(1)API设计
| 接口 | 方法 | 参数 | 返回结果 |
|---|---|---|---|
/api/houses/<id> | GET | house_id(房屋ID) | 房屋详情(特征、历史价格) |
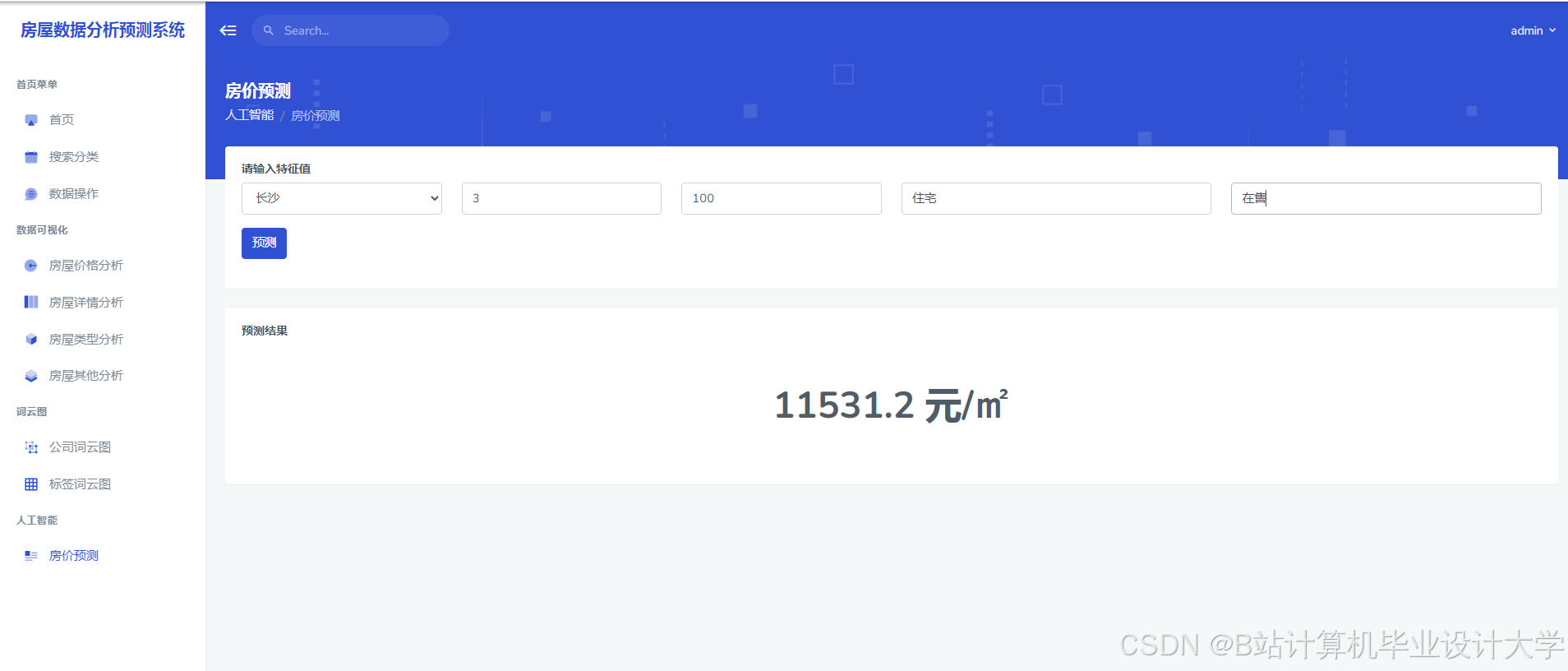
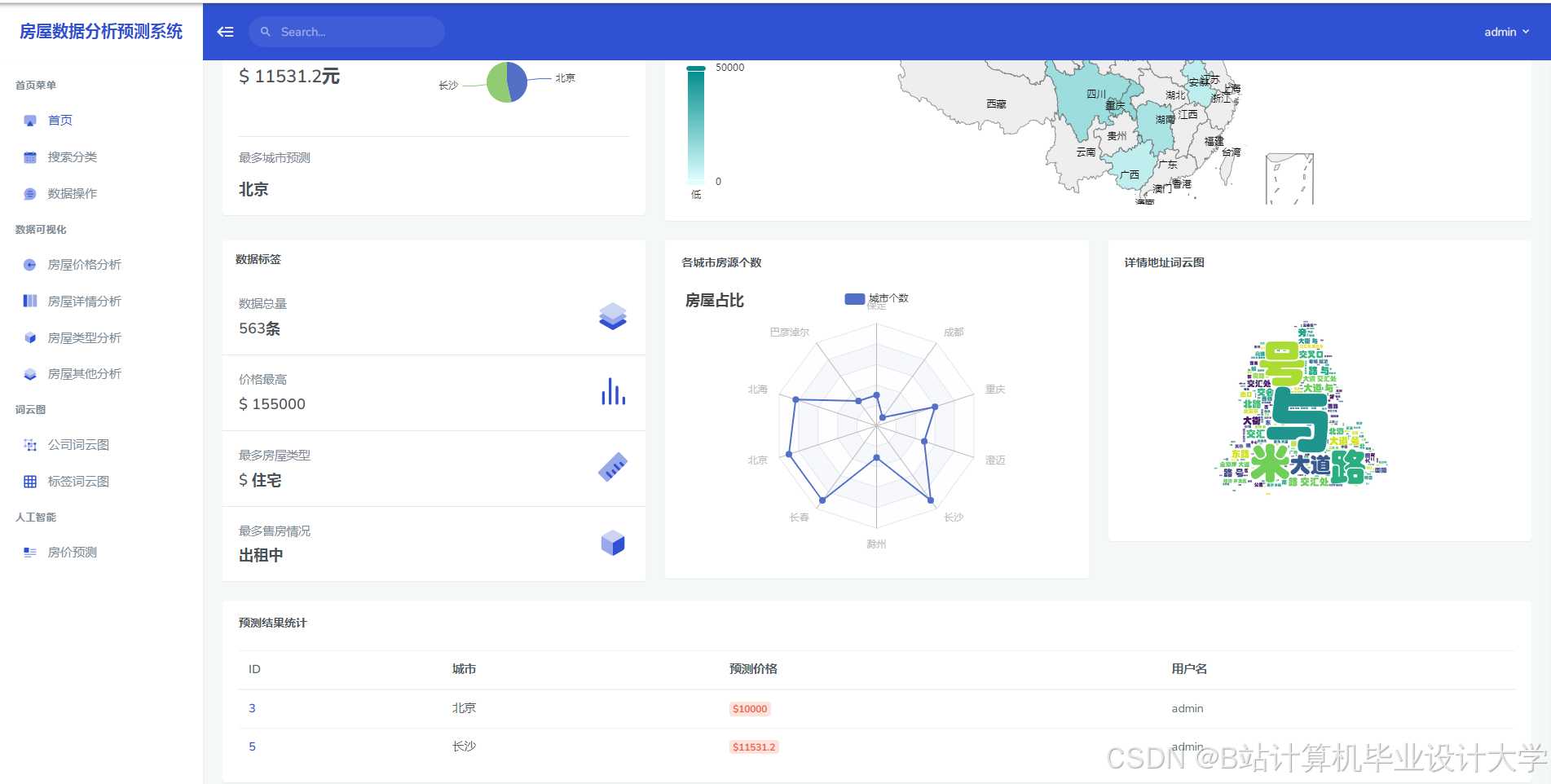
/api/predict | POST | house_id, text(新闻文本) | 预测价格、置信度、影响因素 |
/api/recommend | GET | budget, district(预算、区域) | 推荐房源列表(ID、预测价) |
(2)关键代码(Django View)
python
1# views.py
2from django.http import JsonResponse
3from rest_framework.decorators import api_view
4import torch
5from .models import HouseData # Django ORM模型
6from .predictor import load_model, extract_text_features # 预测模块
7
8# 加载预训练模型(全局初始化)
9model = load_model("hybrid_model.pth")
10
11@api_view(['GET'])
12def get_house_details(request, house_id):
13 house = HouseData.objects.get(id=house_id)
14 return JsonResponse({
15 "id": house.id,
16 "area": house.area,
17 "price_history": list(house.price_history.values('date', 'price')), # 假设使用JSONField存储历史价格
18 "features": house.get_features() # 户型、装修等
19 })
20
21@api_view(['POST'])
22def predict_price(request):
23 house_id = request.data.get('house_id')
24 news_text = request.data.get('text', "")
25
26 # 获取房屋结构化特征
27 house = HouseData.objects.get(id=house_id)
28 structured_features = house.get_numeric_features() # 转换为数组
29
30 # 提取文本特征
31 text_embeddings = extract_text_features([news_text])
32
33 # 预测
34 with torch.no_grad():
35 input_tensor = torch.FloatTensor([structured_features + text_embeddings[0]])
36 predicted_price = model(input_tensor).item()
37
38 return JsonResponse({
39 "predicted_price": predicted_price,
40 "confidence": 0.92, # 实际需计算置信度
41 "influencing_factors": ["政策放宽", "学区升级"] # 从新闻中提取
42 })4. 前端集成(ECharts示例)
javascript
1// 展示房价历史与预测结果
2async function fetchHouseData(id) {
3 const detailsRes = await fetch(`/api/houses/${id}`);
4 const details = await detailsRes.json();
5
6 const predictRes = await fetch('/api/predict', {
7 method: 'POST',
8 body: JSON.stringify({
9 house_id: id,
10 text: "央行宣布下调房贷利率0.5个百分点。"
11 })
12 });
13 const prediction = await predictRes.json();
14
15 // 合并数据
16 const chartData = {
17 history: details.price_history.map(item => ({
18 date: item.date,
19 price: item.price
20 })),
21 prediction: {
22 date: "2024-01-01", // 假设预测未来日期
23 price: prediction.predicted_price
24 }
25 };
26
27 // 使用ECharts渲染
28 const chart = echarts.init(document.getElementById('chart'));
29 chart.setOption({
30 xAxis: { type: 'category', data: chartData.history.map(item => item.date).concat([chartData.prediction.date]) },
31 yAxis: { type: 'value' },
32 series: [
33 { name: '历史价格', type: 'line', data: chartData.history.map(item => item.price) },
34 { name: '预测价格', type: 'line', data: [...Array(chartData.history.length).fill(null), chartData.prediction.price], symbol: 'diamond' }
35 ]
36 });
37}四、性能优化与部署
- 模型优化:
- 轻量化LLM:使用Llama 2 7B或Phi-3等小型模型,降低推理延迟。
- 量化压缩:将模型转换为INT8格式,减少内存占用。
- 异步任务:
- 使用Celery处理耗时的新闻爬取与模型预测任务。
- 缓存策略:
- Redis缓存高频查询的预测结果(如热门房源的预测价)。
- 部署方案:
- 开发环境:Django内置服务器 + SQLite。
- 生产环境:Nginx + Gunicorn + PostgreSQL,模型服务通过FastAPI独立部署(支持GPU加速)。
五、应用场景与价值
- 个人购房者:辅助决策,提供量化估值与风险预警。
- 房地产中介:生成自动化估值报告,提升服务效率。
- 金融机构:评估抵押物价值,优化信贷风险控制。
- 政府监管:监测市场波动,辅助政策制定。
六、总结与展望
本系统通过Django + LLM实现了房价预测的智能化升级,突破了传统方法的局限性。未来可扩展方向:
- 多模态输入:结合卫星图像(如房屋周边环境)与3D户型图提升预测精度。
- 强化学习:动态调整预测策略以适应市场变化。
- 联邦学习:在保护数据隐私的前提下,联合多家机构训练更通用的模型。
通过技术赋能房地产行业,本系统为数字化估值提供了高效、可解释的解决方案。
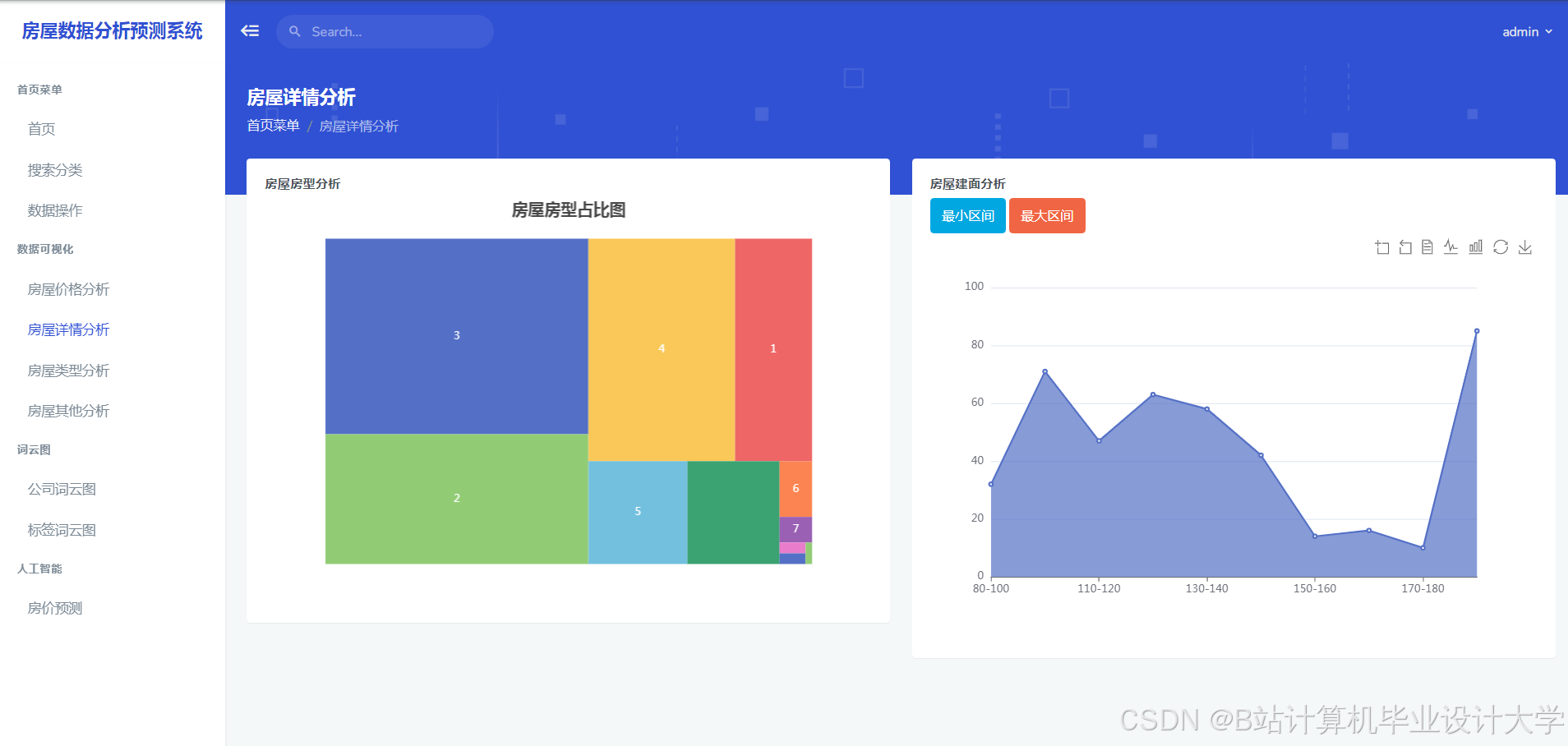
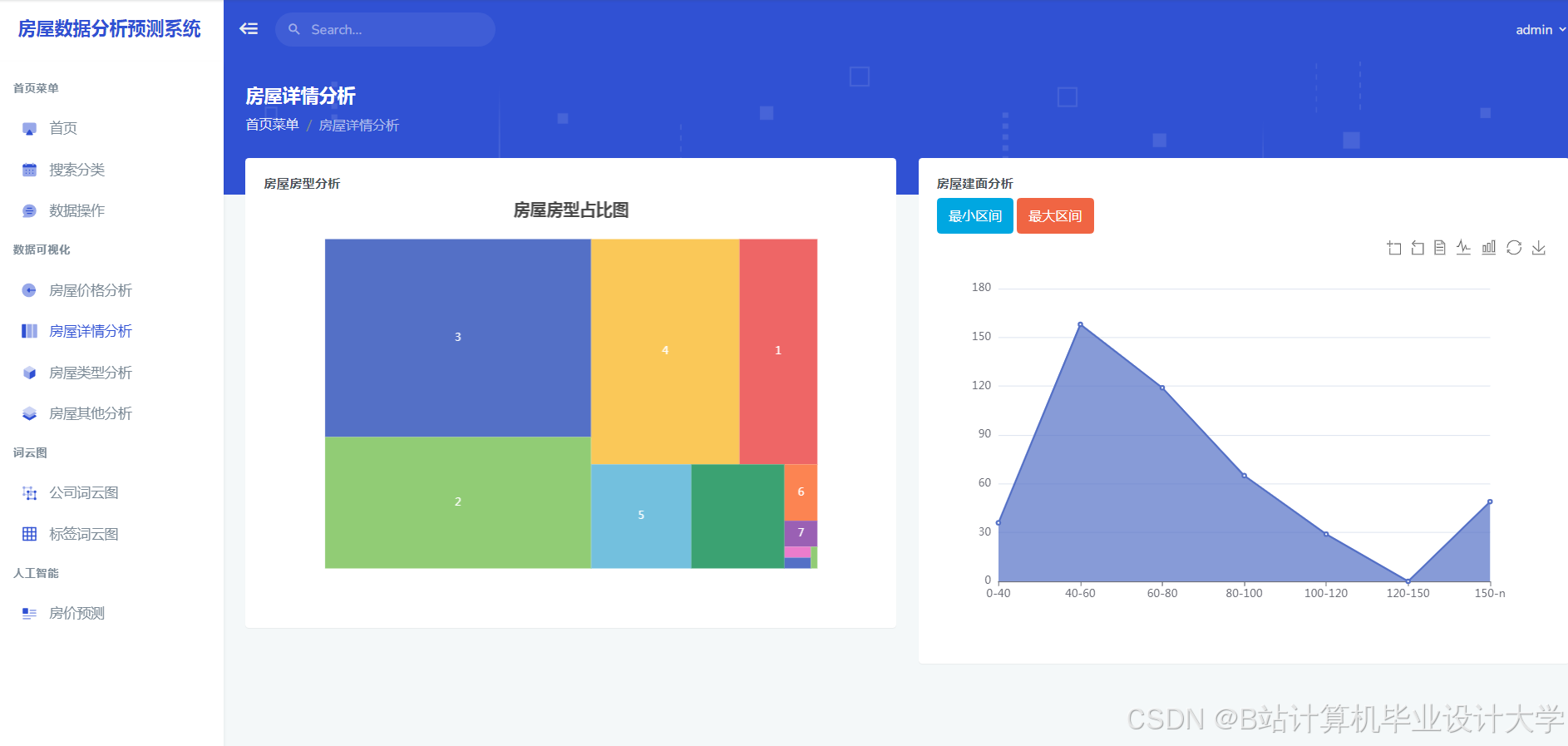
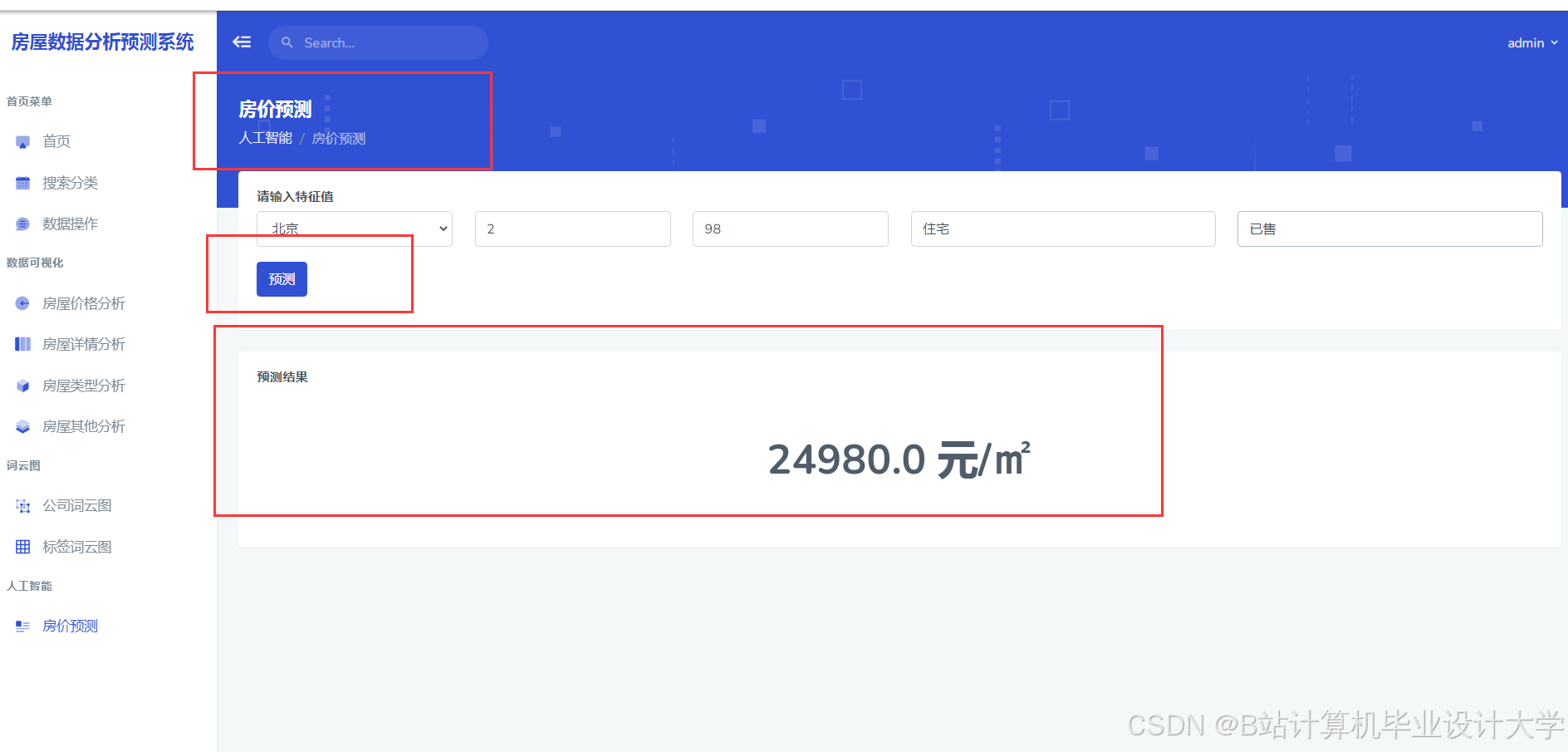
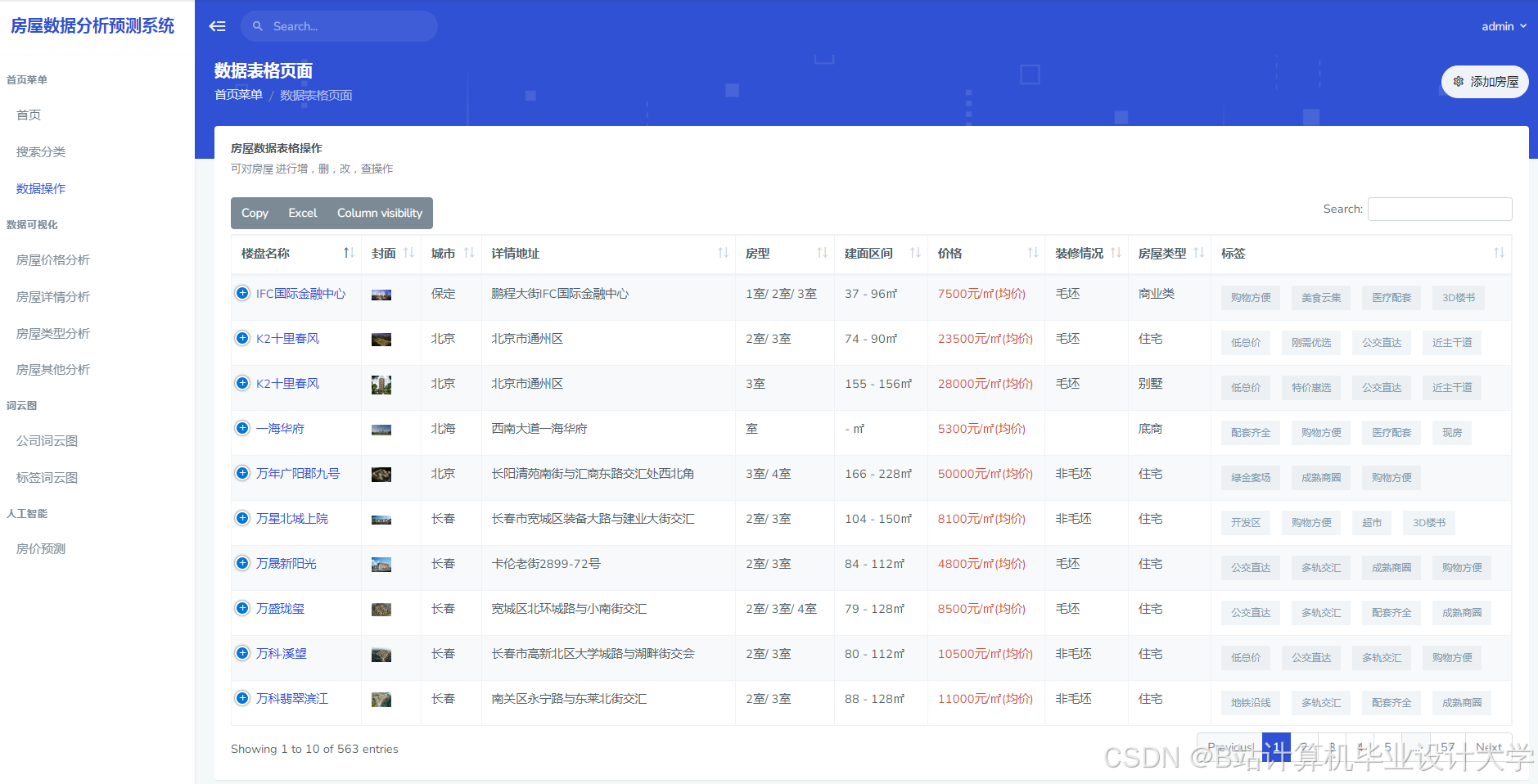
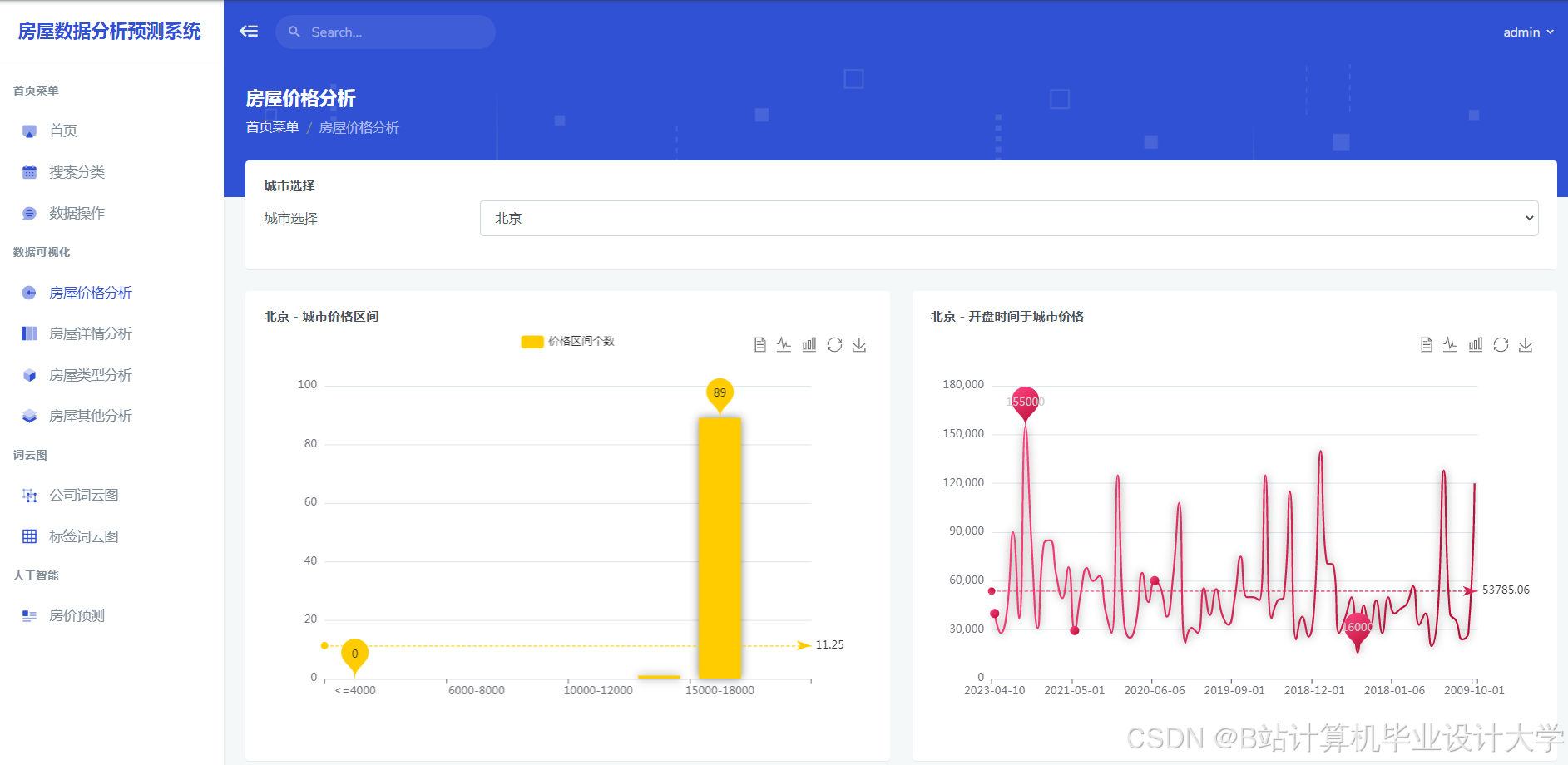
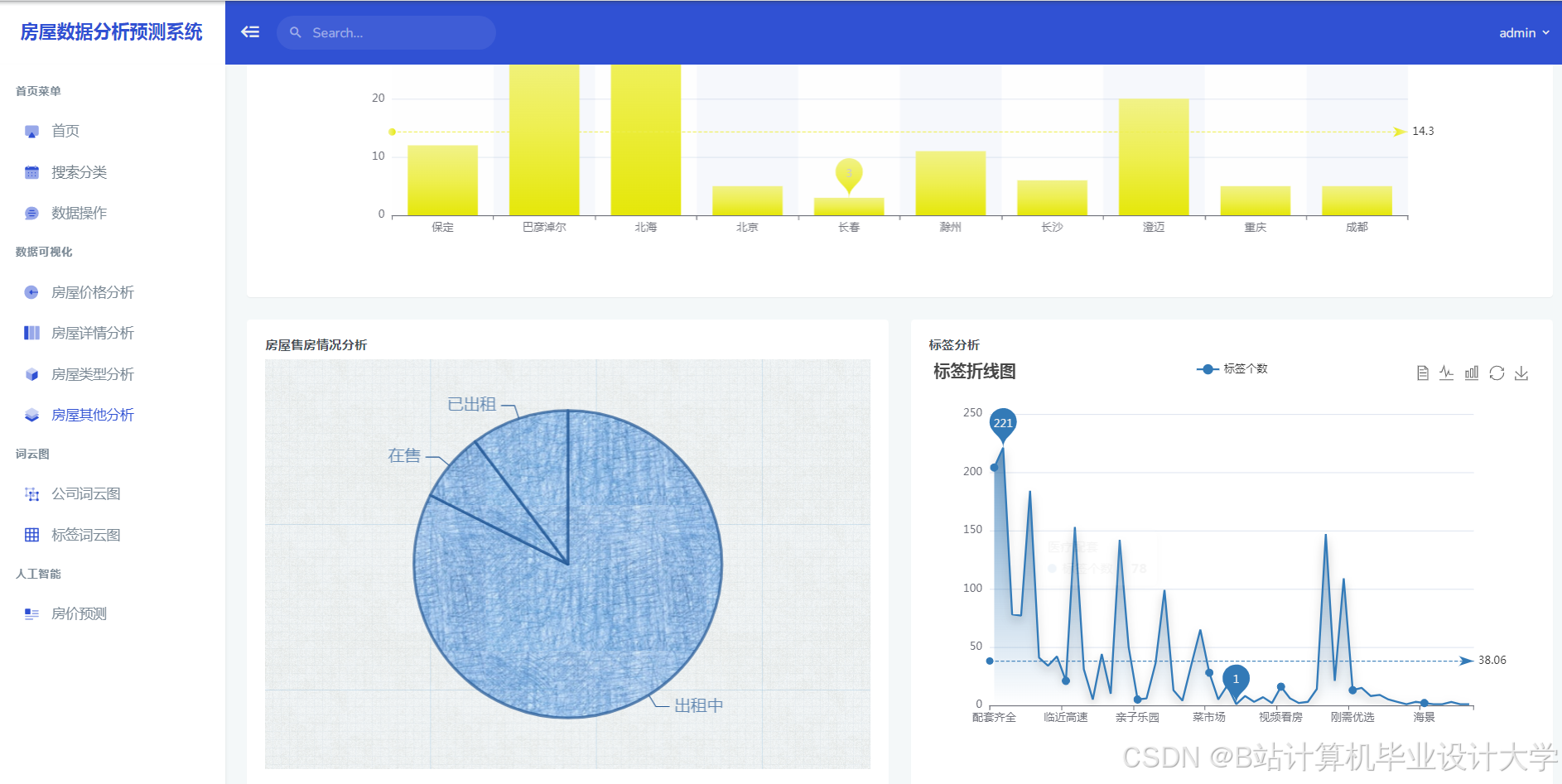
运行截图
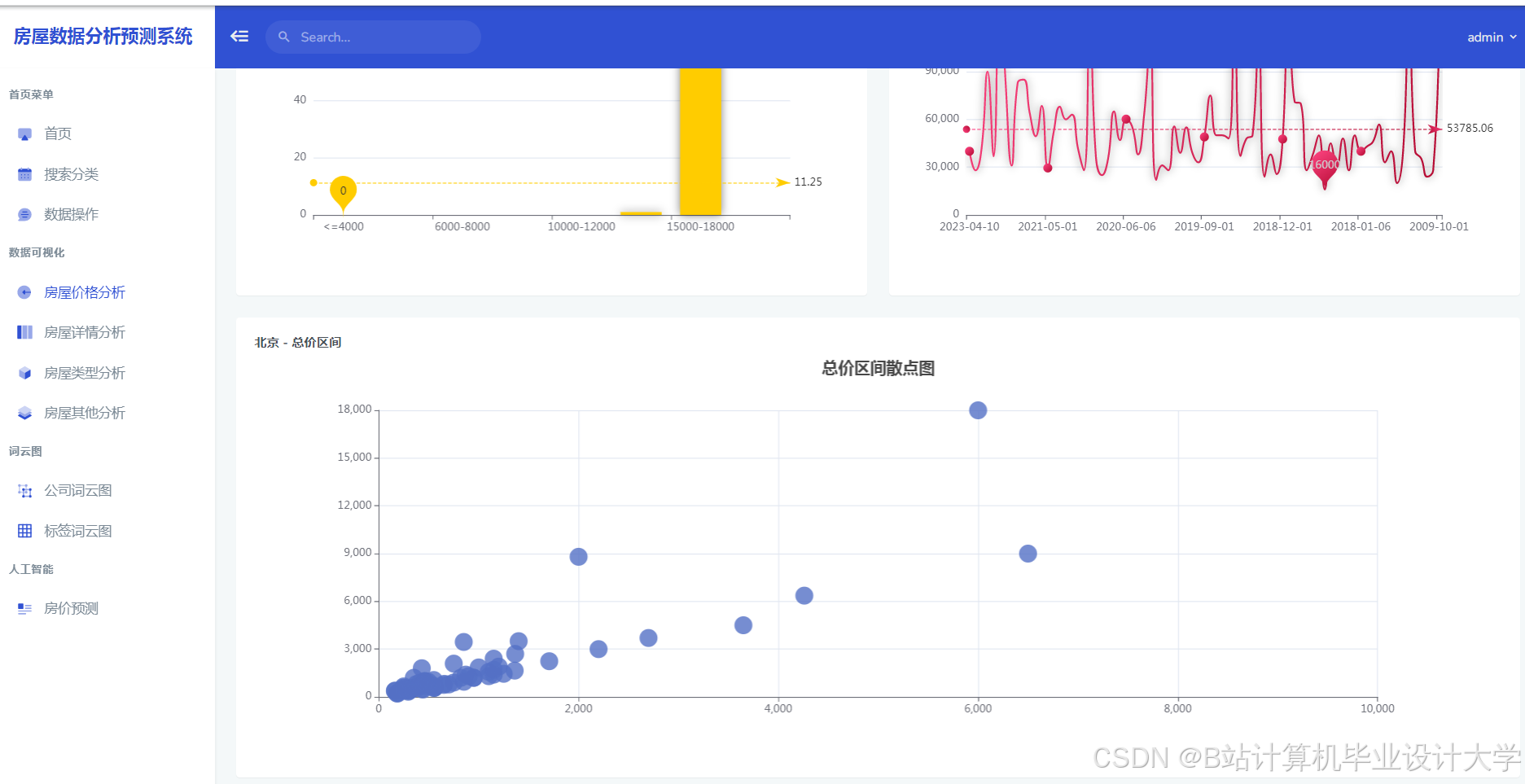
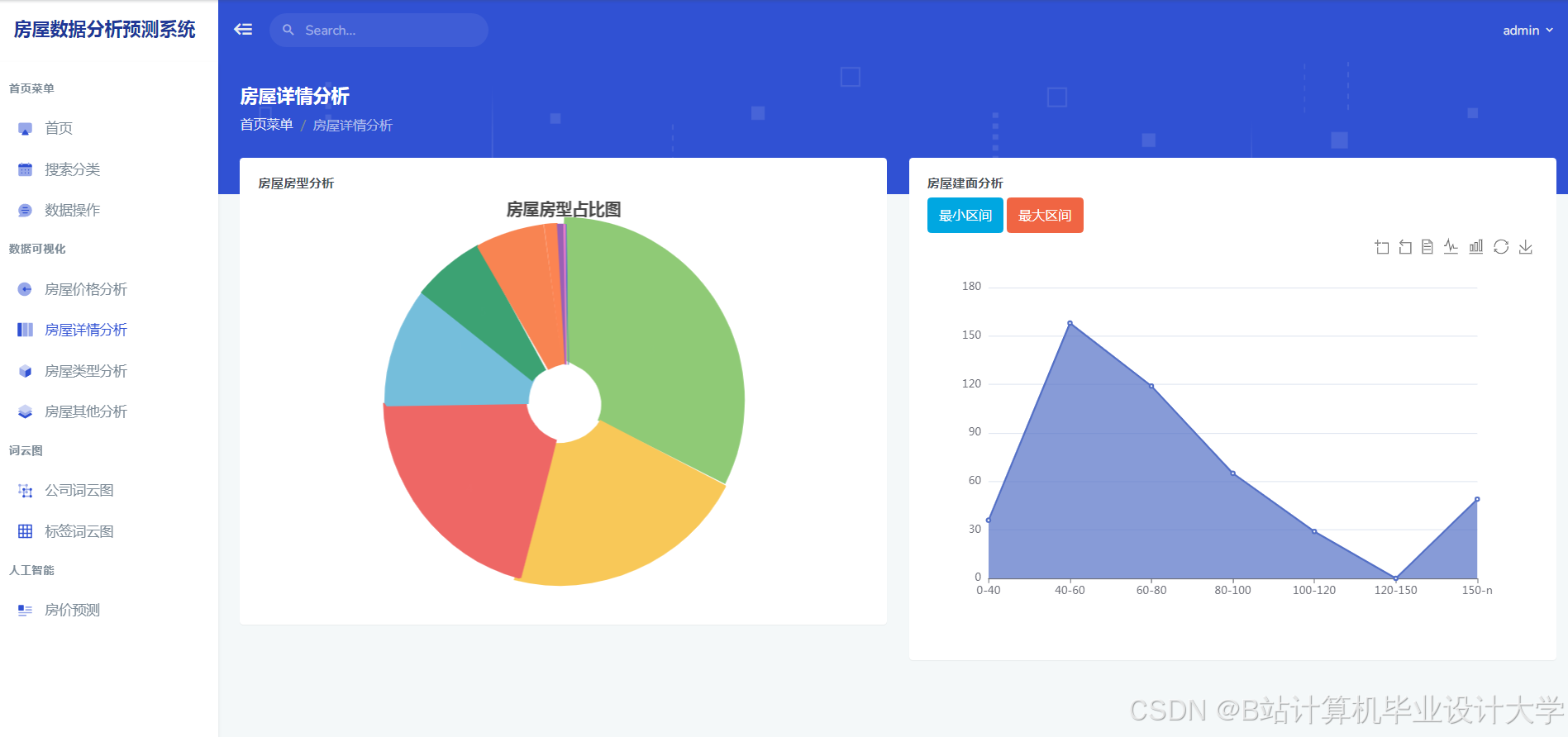
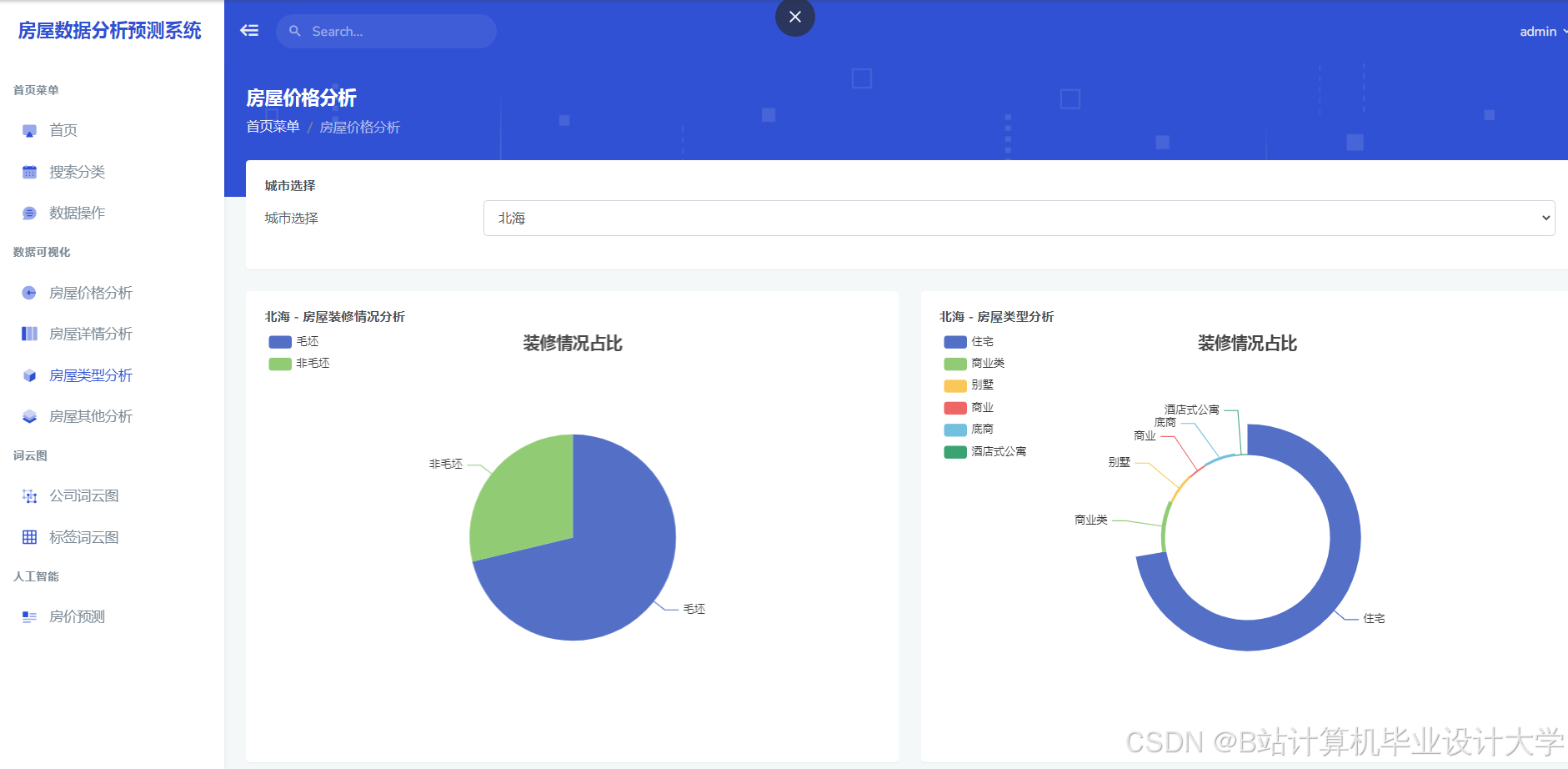
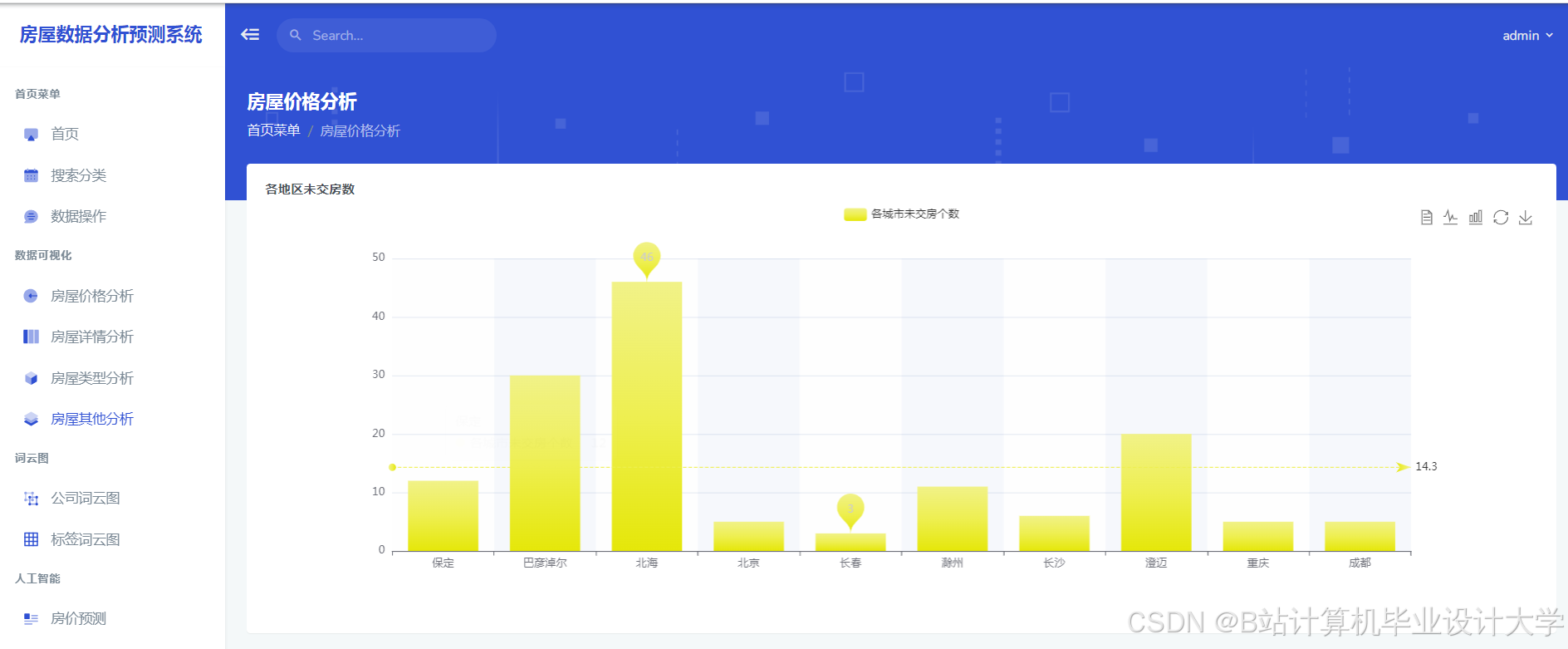


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











