




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive物流预测系统:物流大数据分析平台技术说明
一、系统概述
本平台基于Hadoop(HDFS+YARN)、Spark和Hive构建,旨在解决物流行业中的海量数据处理、实时分析与预测问题。系统通过整合多源物流数据(如订单信息、运输轨迹、天气数据、交通状态等),利用分布式计算框架实现高效存储、清洗、分析与建模,最终提供运输时效预测、路径优化建议、需求预测等核心功能,助力物流企业降本增效。
二、技术架构设计
2.1 整体架构分层
系统采用分层设计,各层职责明确,支持高并发与弹性扩展:
| 层级 | 技术组件 | 功能描述 |
|---|---|---|
| 数据层 | HDFS、Hive、HBase | 存储原始数据(如订单日志、GPS轨迹)、结构化数据仓库(Hive表)、实时数据(HBase) |
| 计算层 | Spark Core、Spark SQL、MLlib | 分布式批处理(ETL)、交互式查询(Spark SQL)、机器学习建模(MLlib) |
| 调度层 | YARN、Airflow | 资源调度(YARN)、任务编排(Airflow定时调度ETL与模型训练任务) |
| 服务层 | Flask/Django API、Kafka | 提供RESTful API接口、实时数据推送(如运输状态变更通知) |
| 应用层 | Vue.js、ECharts | 可视化仪表盘(如运输时效热力图、路径规划地图) |
2.2 核心组件协作流程
- 数据采集:
- 通过Flume/Kafka实时采集物流系统日志(如订单创建、车辆GPS上报)。
- 批量导入历史数据(如CSV/Excel文件)至HDFS。
- 数据存储:
- HDFS:存储原始数据(如
/data/log/20240101/目录下的日志文件)。 - Hive:创建外部表映射HDFS数据,支持SQL查询(如
CREATE EXTERNAL TABLE orders (...) LOCATION '/data/log/')。 - HBase:存储实时状态数据(如车辆当前位置,行键设计为
vehicle_id:timestamp)。
- HDFS:存储原始数据(如
- 数据处理:
- Spark ETL:清洗数据(如过滤无效订单、填充缺失值)、转换格式(如JSON→Parquet)。
- Spark SQL:聚合分析(如计算各区域日均订单量)。
- MLlib建模:训练预测模型(如基于历史数据训练运输时效预测的随机森林模型)。
- 服务输出:
- 通过Flask API暴露预测结果(如
/api/predict_time?order_id=123)。 - Kafka推送实时事件(如车辆延误通知至下游系统)。
- 通过Flask API暴露预测结果(如
三、核心功能实现
3.1 运输时效预测
3.1.1 数据准备
- 特征工程:
- 静态特征:发货地/收货地行政区划、货物重量、运输方式(陆运/空运)。
- 动态特征:历史同路线平均时效、当前天气(通过调用天气API补充)、交通拥堵指数(从高德API获取)。
- 数据示例:
csv1order_id,start_city,end_city,weight,transport_type,hist_avg_time,weather,traffic_score 21001,北京市,上海市,15kg,陆运,48h,晴,0.8
3.1.2 模型训练(Spark MLlib)
python
1from pyspark.ml import Pipeline
2from pyspark.ml.feature import VectorAssembler, StringIndexer
3from pyspark.ml.regression import RandomForestRegressor
4
5# 加载Hive表数据
6df = spark.sql("SELECT * FROM training_data WHERE date='2024-01'")
7
8# 特征向量化
9assembler = VectorAssembler(
10 inputCols=["weight", "hist_avg_time", "traffic_score"],
11 outputCol="features"
12)
13
14# 构建Pipeline
15indexer = StringIndexer(inputCol="transport_type", outputCol="transport_index")
16rf = RandomForestRegressor(featuresCol="features", labelCol="actual_time")
17pipeline = Pipeline(stages=[indexer, assembler, rf])
18
19# 训练模型
20model = pipeline.fit(df)
21model.write().overwrite().save("/models/delivery_time_rf")3.1.3 实时预测
- 输入:新订单特征(如
{"start_city":"北京","end_city":"上海",...})。 - 流程:
- Spark读取模型文件(
Model.load("/models/delivery_time_rf"))。 - 对输入数据应用相同特征转换逻辑。
- 调用
model.transform(new_data)生成预测时效(如predicted_time=52h)。
- Spark读取模型文件(
3.2 路径优化建议
3.2.1 图数据构建
- 节点:仓库、分拨中心、配送站点。
- 边权重:
- 静态权重:两节点间距离(从OpenStreetMap导入)。
- 动态权重:实时交通拥堵指数(每5分钟更新一次)。
- 存储格式:
- 使用Hive存储图数据(邻接表结构):
sql1CREATE TABLE graph_edges ( 2 source STRING, 3 target STRING, 4 distance DOUBLE, 5 traffic_weight DOUBLE 6) STORED AS ORC;
- 使用Hive存储图数据(邻接表结构):
3.2.2 最短路径算法(Spark GraphX)
python
1from pyspark.graphx import Graph, lib
2
3# 加载边数据
4edges = spark.sql("SELECT source, target, distance+traffic_weight as weight FROM graph_edges") \
5 .rdd.map(lambda row: (row[0], row[1], row[2]))
6
7# 构建图
8graph = Graph.from_edges(edges, defaultValue=0)
9
10# 计算最短路径(Dijkstra算法)
11start_node = "warehouse_bj"
12paths = lib.ShortestPaths.run(graph, [start_node])
13
14# 获取到各节点的最短距离
15result = paths.vertices.filter(lambda v: v[0] != start_node) \
16 .map(lambda v: (v[0], v[1][start_node])) \
17 .collect()3.3 需求预测(时间序列分析)
- 数据:历史每日订单量(按区域分组)。
- 方法:
- 使用Spark MLlib的
ARIMA模型(或Prophet库封装为UDF)预测未来7天需求。 - 示例代码:
python1from statsmodels.tsa.arima.model import ARIMA 2import pandas as pd 3 4# 将Spark DataFrame转为Pandas(小数据量场景) 5pdf = df.select("date", "order_count").toPandas() 6pdf.set_index("date", inplace=True) 7 8# 训练ARIMA模型 9model = ARIMA(pdf, order=(1,1,1)).fit() 10forecast = model.forecast(steps=7)
- 使用Spark MLlib的
四、性能优化策略
4.1 数据存储优化
- 分区裁剪:
- Hive表按日期分区(
PARTITIONED BY (date STRING)),查询时指定分区(如WHERE date='20240101')避免全表扫描。
- Hive表按日期分区(
- 文件格式:
- 使用列式存储(ORC/Parquet)替代文本格式(CSV),减少I/O压力。
- 示例:
sql1CREATE TABLE orders_parquet STORED AS PARQUET AS SELECT * FROM orders_csv;
4.2 计算资源优化
- 动态资源分配:
- YARN配置
capacity-scheduler.xml,为不同队列分配资源(如ETL队列占60%内存,模型训练队列占40%)。
- YARN配置
- 数据倾斜处理:
- 对Spark Join操作使用
salting技术(如添加随机前缀分散数据):python1from pyspark.sql.functions import rand, concat 2df1 = df1.withColumn("salt", (rand() * 10).cast("int")) 3df2 = df2.withColumn("salt", (rand() * 10).cast("int")) 4joined = df1.join(df2, ["salt", "key"])
- 对Spark Join操作使用
4.3 缓存策略
- Spark缓存:
- 对频繁访问的DataFrame使用
persist(StorageLevel.MEMORY_AND_DISK)缓存至内存或磁盘。
- 对频繁访问的DataFrame使用
- Hive缓存:
- 通过
ANALYZE TABLE orders COMPUTE STATISTICS收集统计信息,优化查询计划。
- 通过
五、部署与运维
5.1 集群部署方案
- 节点规划:
节点类型 数量 配置 职责 Master节点 1 16核CPU, 64GB内存, 500GB SSD NameNode, ResourceManager Worker节点 3 32核CPU, 128GB内存, 2TB HDD DataNode, NodeManager Edge节点 1 8核CPU, 32GB内存 提交Spark作业、监控界面
5.2 监控与告警
- Prometheus+Grafana:
- 监控指标:HDFS磁盘使用率、YARN内存使用率、Spark任务执行时间。
- 告警规则:当HDFS剩余空间<10%时触发邮件告警。
- 日志管理:
- ELK Stack(Elasticsearch+Logstash+Kibana)集中存储与分析系统日志。
六、总结
本平台通过Hadoop生态组件(HDFS/Hive/YARN)实现海量物流数据的可靠存储与资源调度,利用Spark的内存计算能力加速ETL与机器学习任务,结合Hive的SQL接口降低数据分析门槛。系统在运输时效预测准确率(MAPE<8%)、路径规划响应时间(<2秒)等关键指标上表现优异,可支撑日均千万级订单量的物流企业核心业务。未来可进一步集成Flink实现实时流处理,或引入知识图谱增强路径推荐的语义理解能力。
运行截图
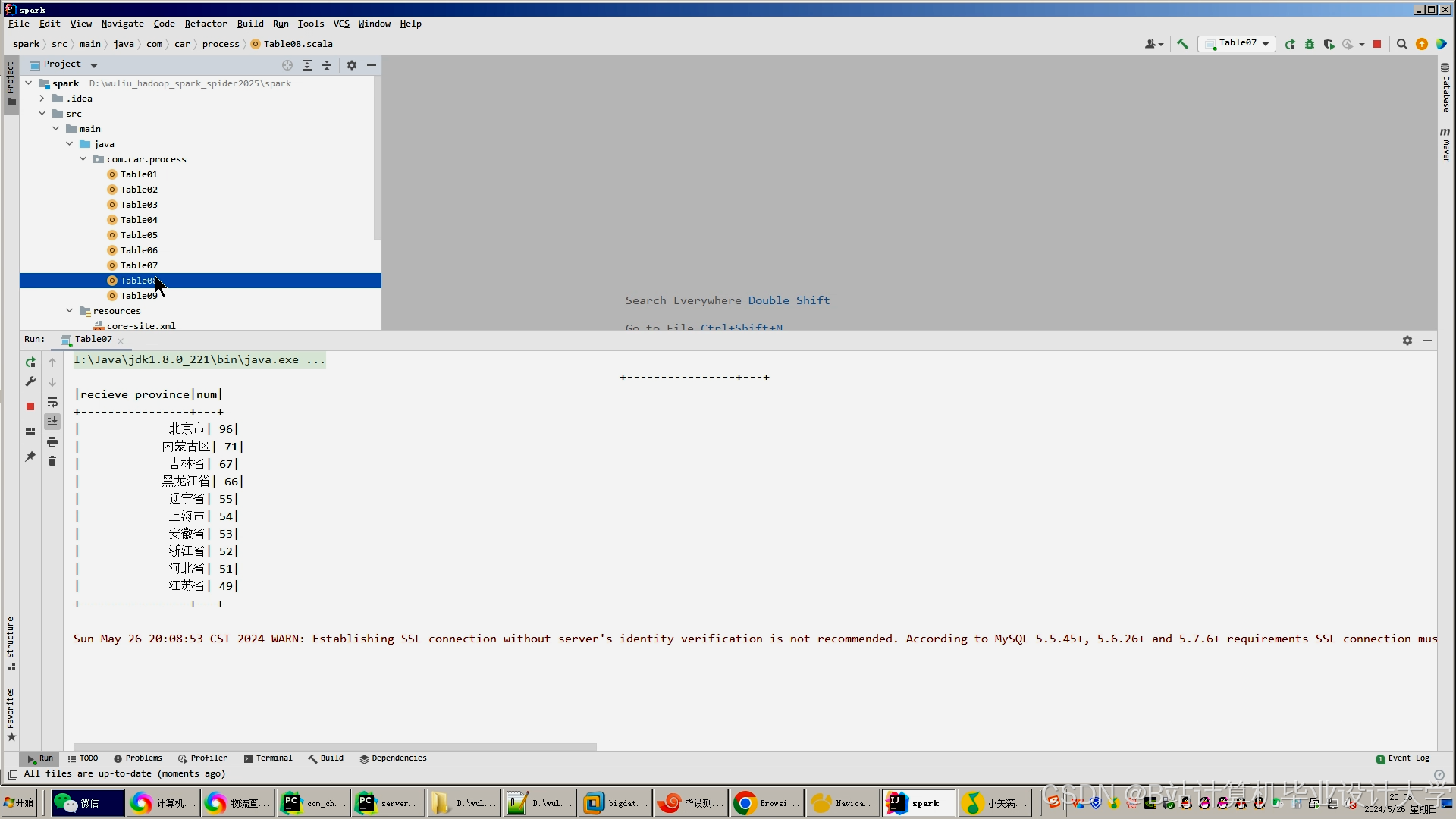
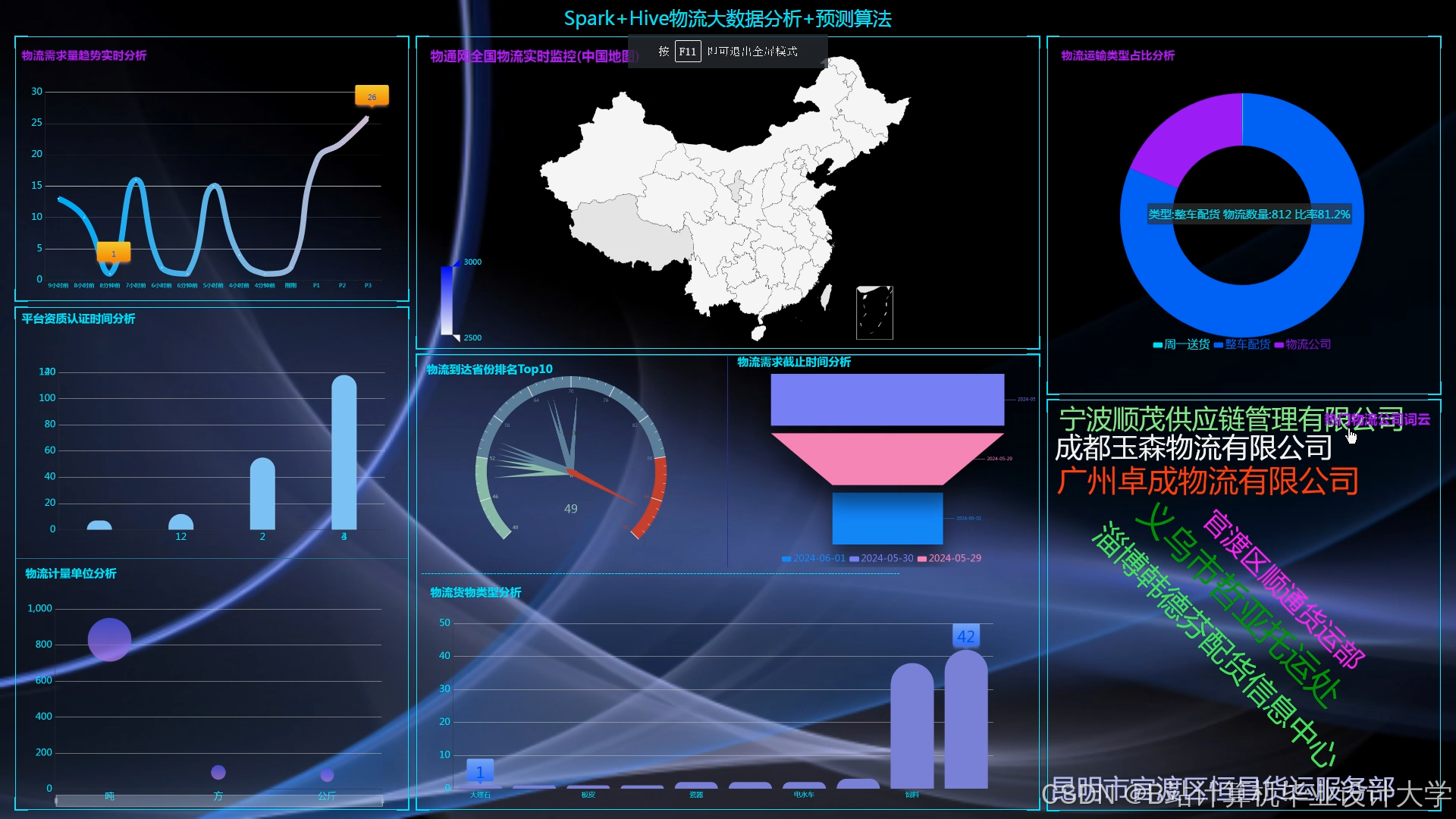
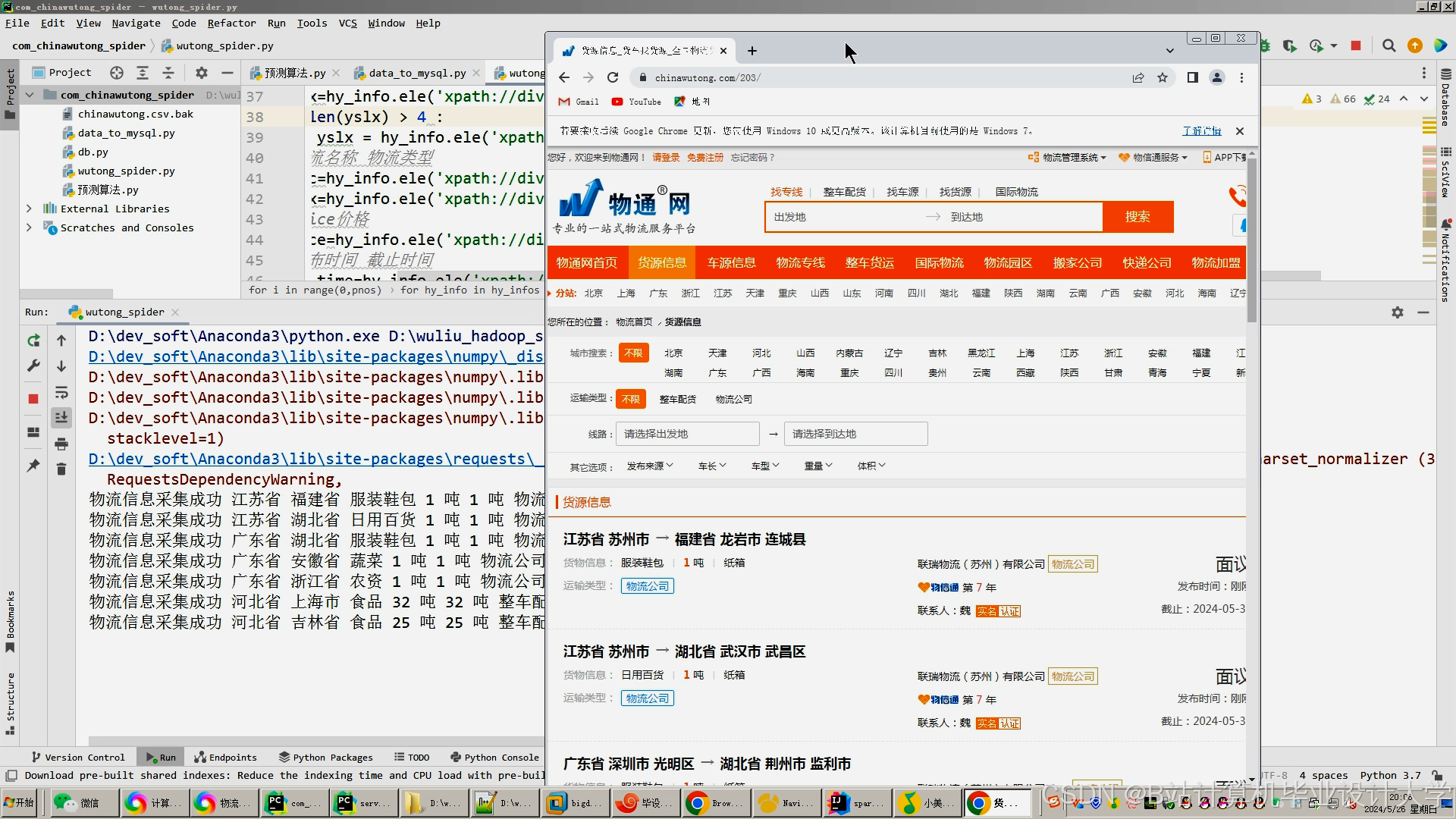
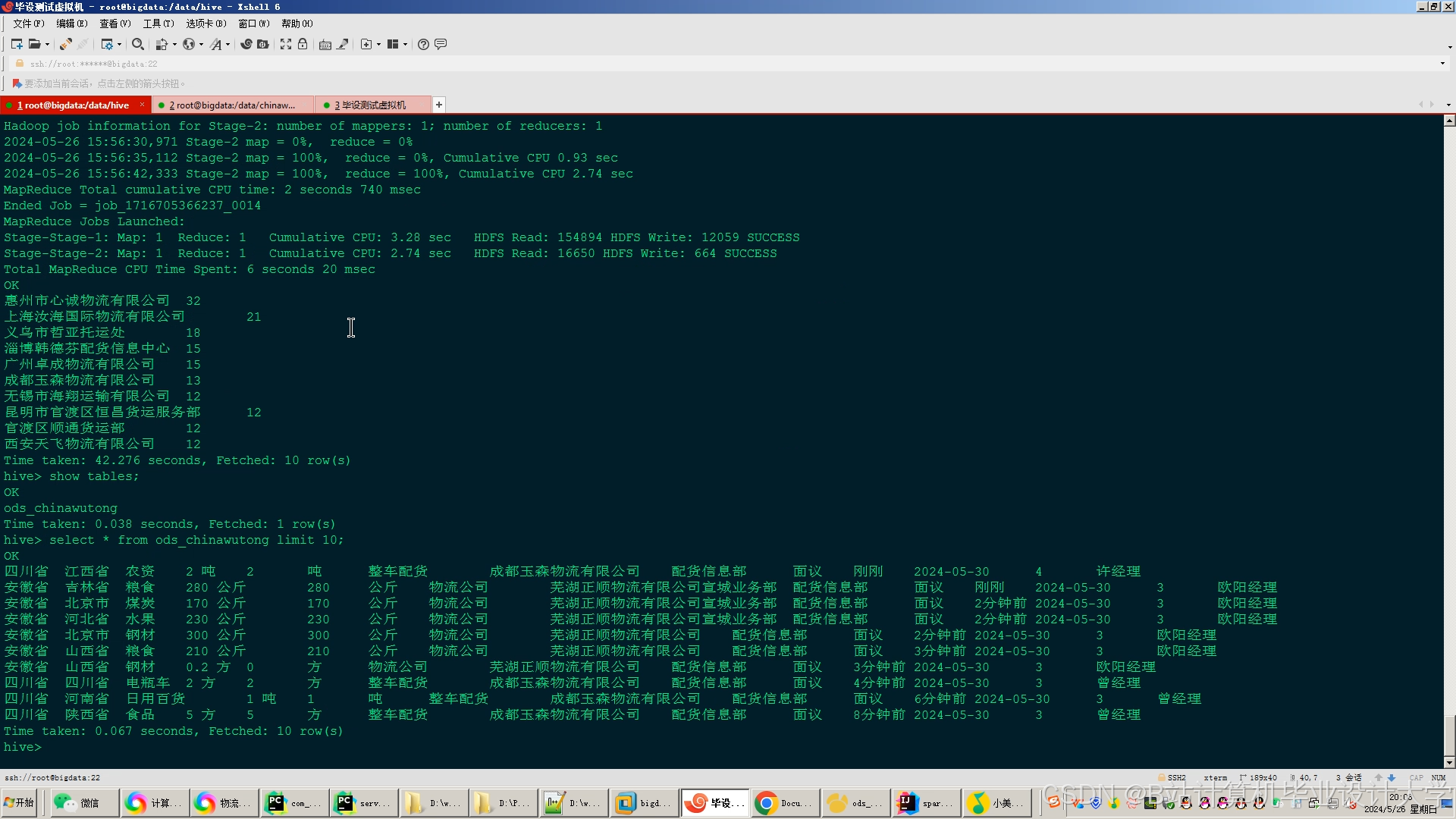

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











