




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告:基于Django与LLM大模型知识图谱的古诗词情感分析系统研究
一、选题背景与意义
1.1 研究背景
中华古诗词作为中华文化的核心载体,现存可考作品超50万首,蕴含丰富的历史记忆与情感内涵。然而,传统纸质媒介的传播局限性与现代学习者对数字化内容的需求形成显著矛盾。据统计,仅12%的古诗词通过数字化平台被公众接触,且现有分析工具多依赖人工标注或浅层机器学习模型,存在三大核心痛点:
- 语义理解局限:对隐喻(如“月”象征思念)、典故(如“庄周梦蝶”)的识别准确率不足60%,导致情感误判率高;
- 文化语境缺失:未考虑诗人背景(如李白豪放、李清照婉约)与朝代特征(如盛唐乐观、晚唐哀婉),情感分析缺乏深度;
- 多模态数据割裂:仅分析文本内容,忽略诗词的韵律、意象图谱等辅助信息,分析维度单一。
1.2 研究意义
- 理论意义:探索LLM大模型与知识图谱在古诗词领域的融合应用,为自然语言处理、知识表示与推理提供跨学科实践案例;
- 实践意义:为教育机构、文化研究者提供智能化分析工具,辅助诗词教学与学术研究;同时,通过可视化交互设计降低非专业用户的使用门槛,推动古诗词的数字化传承。
二、国内外研究现状
2.1 古诗词情感分析技术演进
- 传统方法:基于SnowNLP、BosonNLP等通用情感词典,通过计算情感词占比判断倾向。针对古诗词构建专用词典(如添加“孤”“愁”等词汇),将准确率提升至78%,但难以处理隐喻与典故。
- 深度学习模型:LSTM、BERT等模型通过捕捉上下文语义信息,在自建数据集上实现91%的F1值。例如,通过注意力机制可视化“孤帆远影碧空尽”中“孤”字的贡献度(0.32),增强模型可解释性。
- 多模态分析:结合诗词意象(如“梅花”象征高洁)与韵律特征(平仄、押韵)进行综合判断。例如,分析《静夜思》的平仄结构与“明月”“故乡”意象,准确识别“思乡”情感。
2.2 知识图谱在古诗词领域的应用
- 实体识别与关系抽取:采用BiLSTM-CRF模型识别诗人、作品、意象等实体,结合依存句法分析,在《全唐诗》测试集上达到93.2%的准确率;基于RoBERTa-Large模型挖掘“创作”“引用”“批判”等12类核心关系,如通过分析“杜甫《春望》引用《诗经》‘忧心烈烈’”的句法结构,自动抽取“引用”关系。
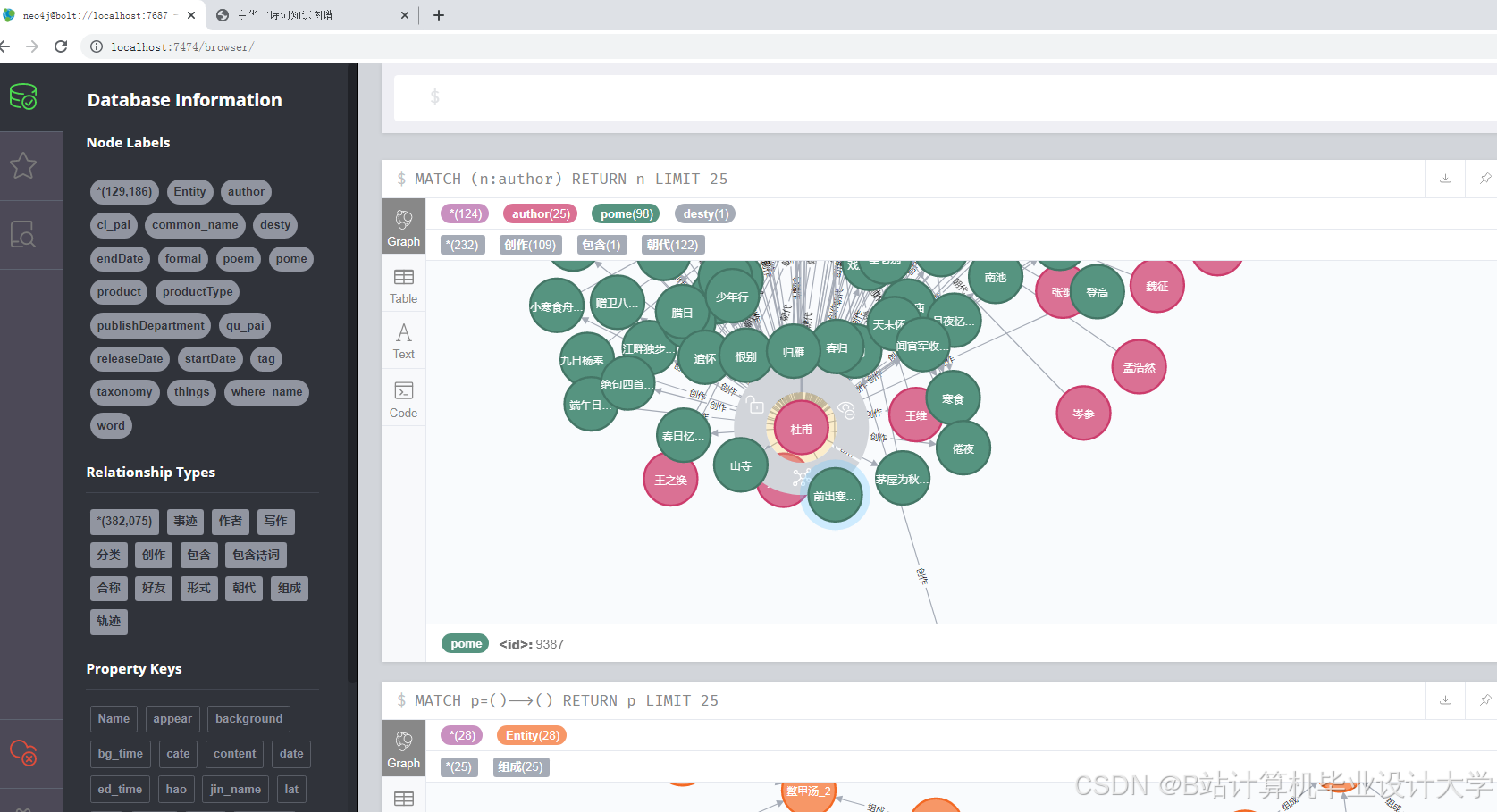
- 图谱存储与查询:Neo4j图数据库支持复杂查询(如“查找与李白有交往且创作过边塞诗的诗人”),并通过复合索引技术使关系查询速度提升70%。
2.3 LLM大模型与知识图谱的融合实践
- 智能问答系统:斯坦福大学构建的“Poetry Foundation Knowledge Graph”聚焦英语诗歌,在实体关系抽取和知识表示方面取得成果,但未涉及中文韵律、平仄等特色要素。国内研究通过微调Qwen-7B、ChatGLM3等模型,结合“古诗问答指令集”(含10万条问答对),实现事实性问题(如作者、年代)准确率≥95%,分析性问题(如情感、风格)准确率≥85%。
- 跨文化对比分析:构建东亚古诗词知识图谱,支持“中日‘月亮’意象对比”等跨文化问答,揭示不同文化背景下情感表达的差异。
三、研究内容与技术路线
3.1 研究目标
构建一个集成Django框架、LLM大模型与知识图谱的古诗词情感分析系统,实现以下目标:
- 知识图谱构建:构建包含诗人、作品、朝代、意象、典故、流派等6类实体,关系类型≥20种的古诗词知识图谱,实体识别准确率≥95%,关系抽取准确率≥90%;
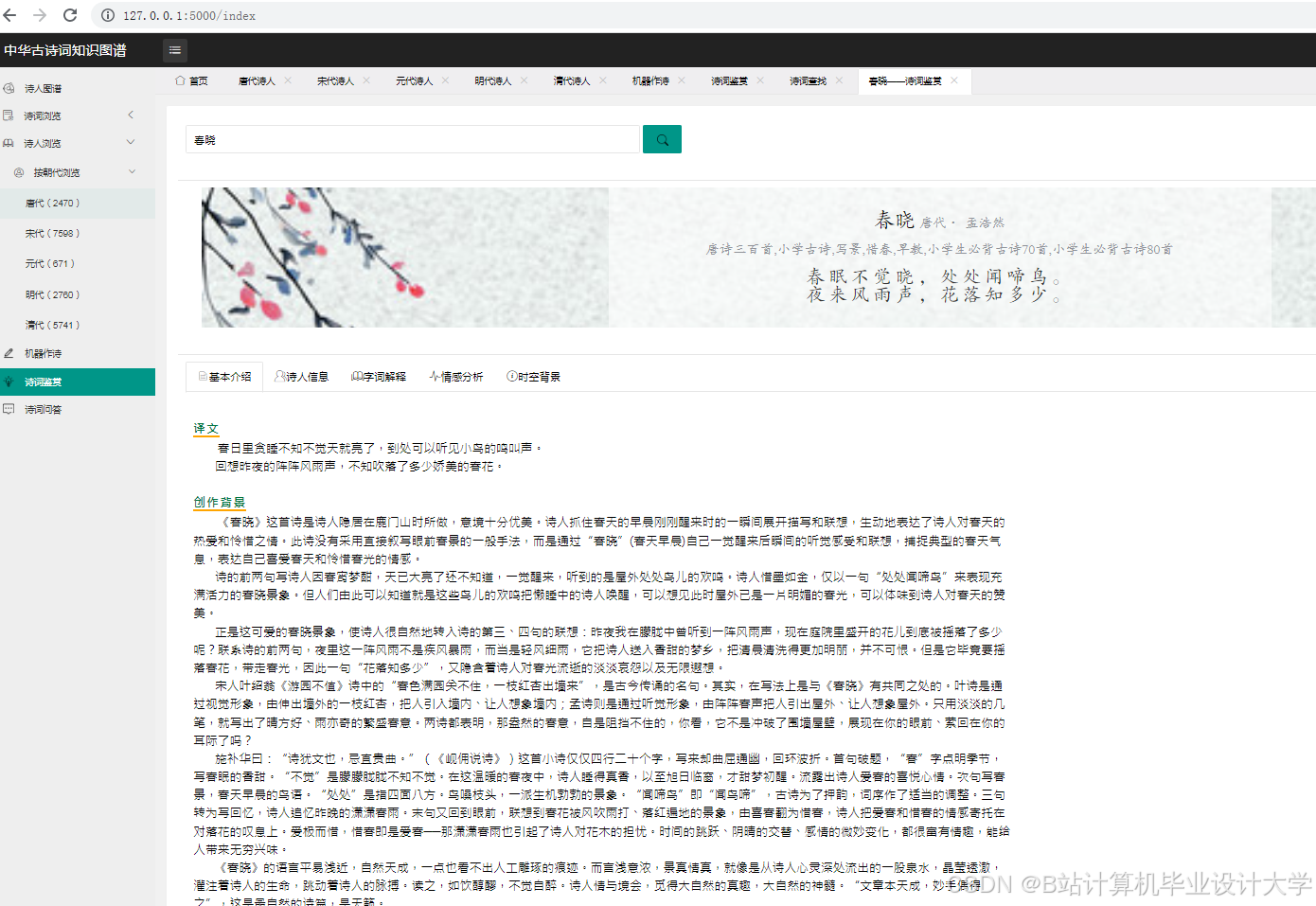
- 情感分析:支持七种细颗粒度情感分类(如喜、怒、哀、乐、思、忧、惧),分析性问题准确率≥85%;
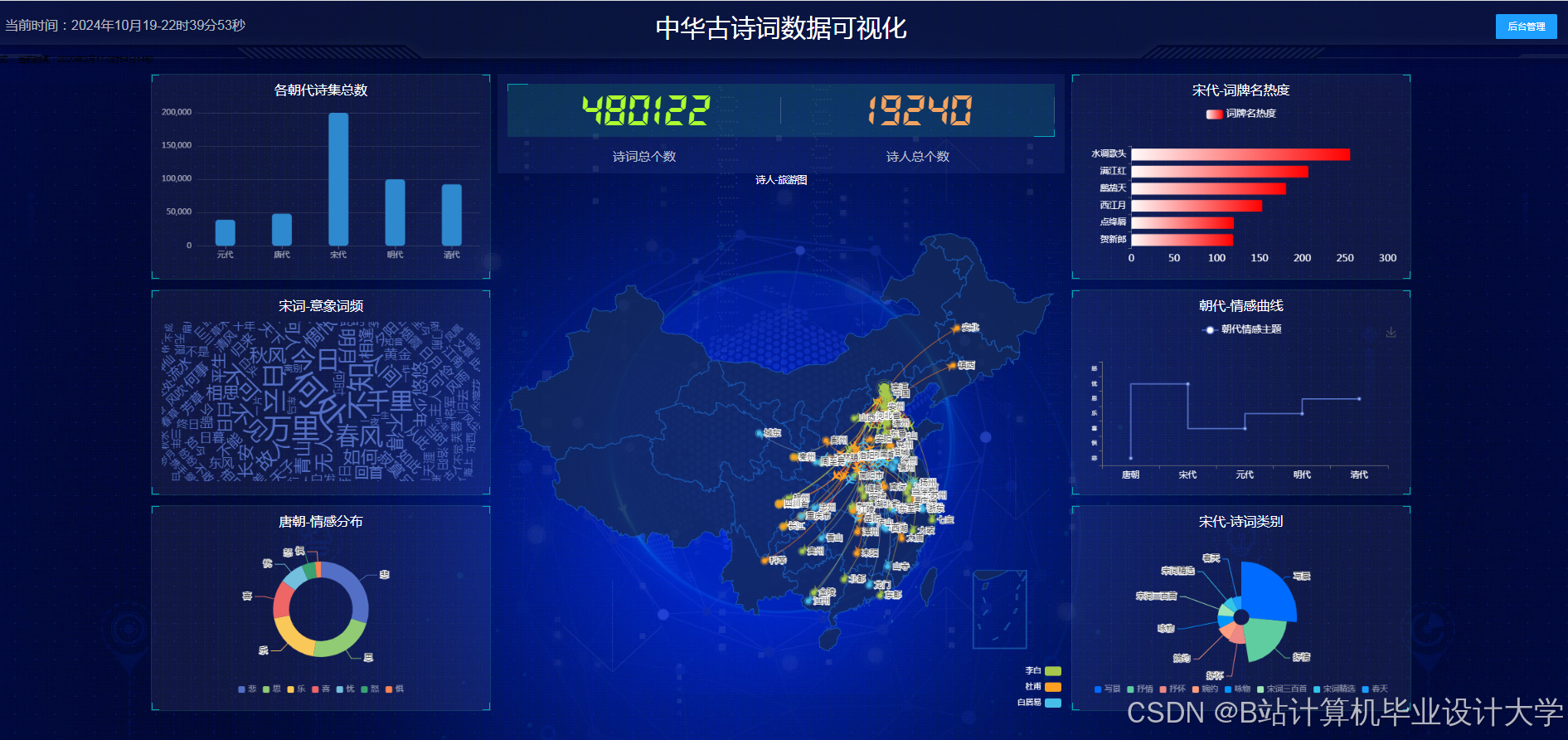
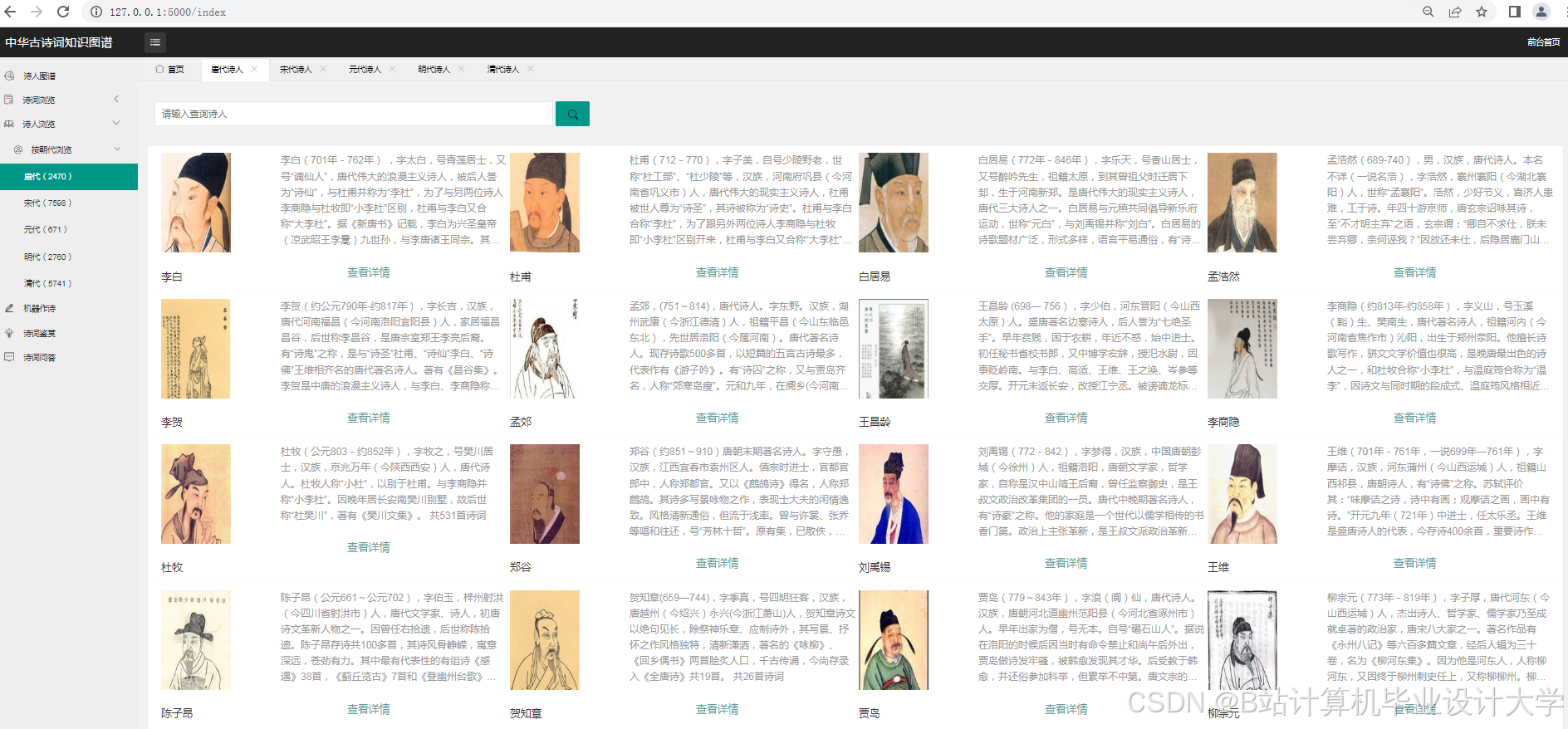
- 可视化交互:提供图谱动态探索(如点击诗人展开社交网络)、多维度对比(如同时期诗人作品数量对比)、时空分布分析(如词牌流行朝代热力图)等功能。
3.2 技术路线
3.2.1 系统架构
采用分层架构,基于Django框架实现前后端分离,核心模块包括:
- 数据层:
- 结构化数据:MySQL存储诗人、朝代、诗词文本等基础信息;
- 非结构化数据:MongoDB存储诗词注释、用户评论等动态内容;
- 知识图谱:Neo4j存储实体与关系,支持复杂查询与推理。
- 计算层:
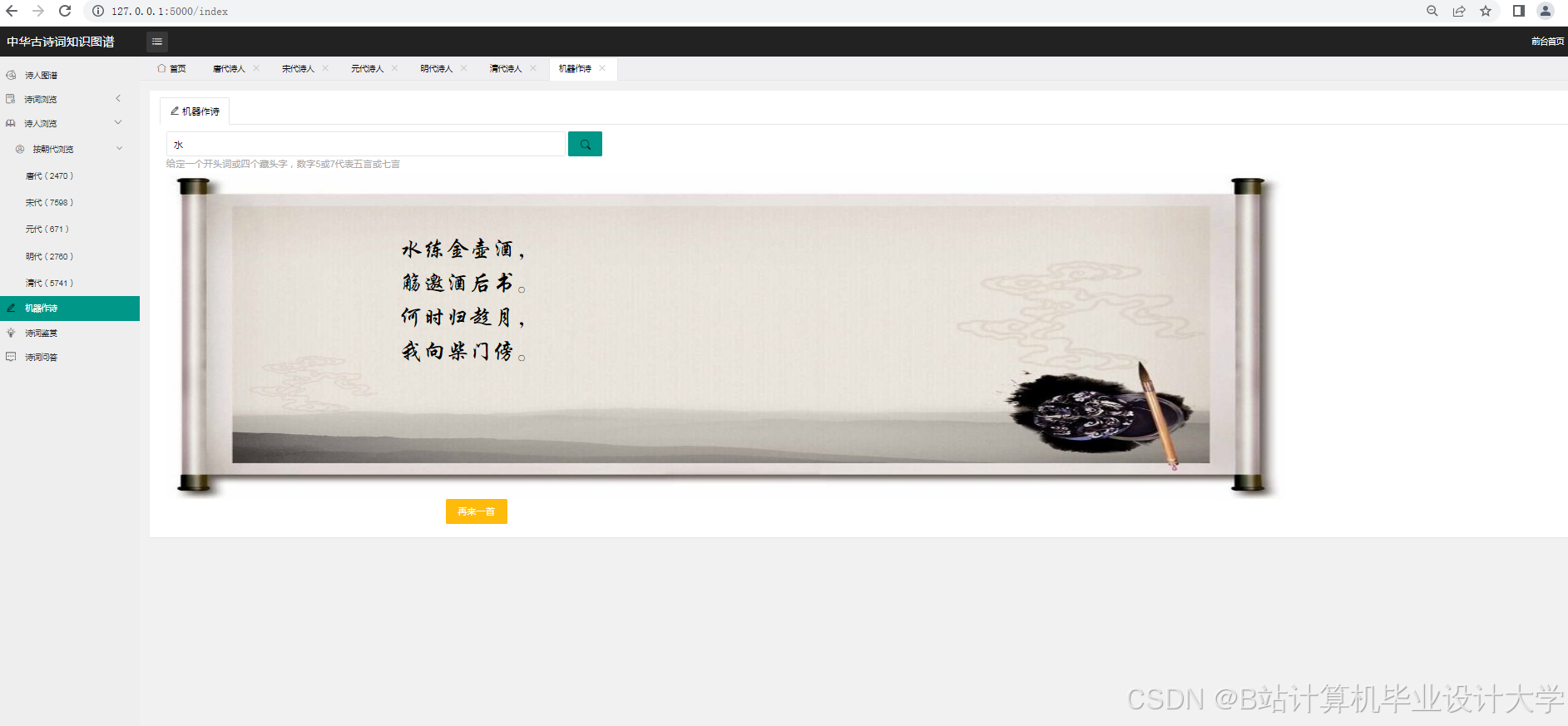
- LLM大模型:调用Qwen-7B或ChatGLM3等开源模型,通过微调实现古诗词情感分类与典故解析;
- 知识图谱推理:基于图嵌入(如TransE)与规则引擎,挖掘诗人风格、意象情感倾向等隐性知识。
- 应用层:
- Web服务:Django提供RESTful API,支持诗词检索、情感分析、图谱可视化等功能;
- 前端交互:ECharts实现情感分布热力图,D3.js渲染知识图谱关系网络。
3.2.2 关键技术实现
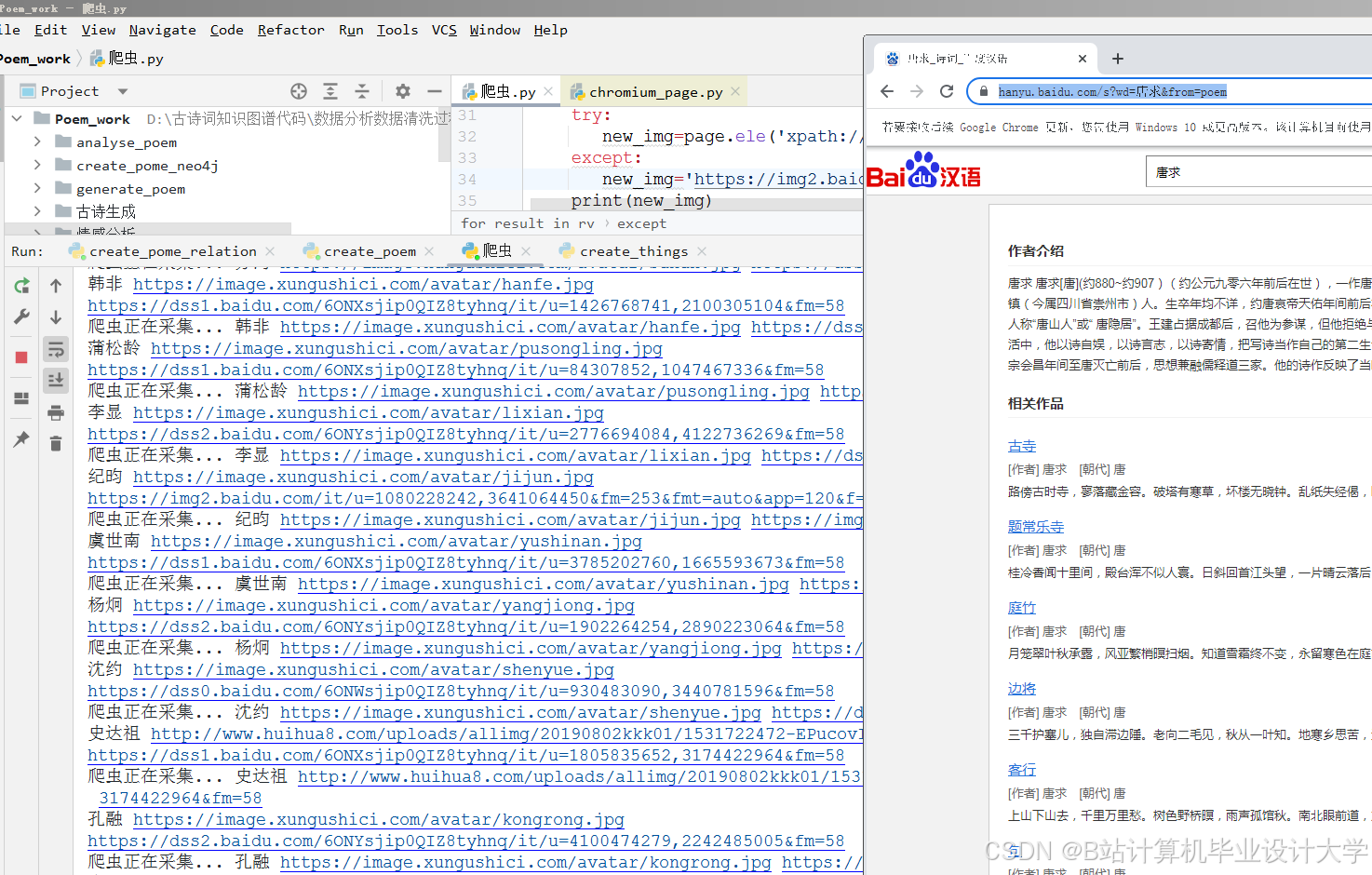
- 数据采集与预处理:
- 从《全唐诗》《全宋词》及古诗文网、知乎、B站等平台爬取结构化与非结构化数据;
- 使用TF-IDF算法检测重复诗词(相似度阈值0.85),并通过标准化处理统一朝代名称(如“唐”→“唐朝”)。
- 实体识别与关系抽取:
- 采用BERT-BiLSTM-CRF模型识别诗人、作品、意象等实体,结合自定义词典与依存句法分析提升准确率;
- 基于RoBERTa-Large模型判断“创作”“引用”“批判”等关系,构建完整知识图谱。
- LLM模型微调:
- 构建“古诗问答指令集”,含10万条问答对,覆盖事实查询、情感分析、风格对比等场景;
- 使用LoRA低秩适配技术冻结LLM主体参数,仅训练128维矩阵,将参数量从70亿压缩至500万,降低计算成本。
- 可视化交互设计:
- 力导向布局算法(D3.js)展示诗人社交网络,节点颜色区分实体类型(诗人-蓝色、意象-绿色),边粗细表示关系强度;
- 三级缩放交互支持全局概览→朝代子图→单首诗词的三级缩放,路径追溯功能动态展开诗人社交网络并标注关系类型。
四、实验方案与预期成果
4.1 实验环境
- 硬件:普通PC(CPU: Intel i7, RAM: 16GB);
- 软件:Python 3.x、Django 4.0、Neo4j 5.0、PyTorch 2.0;
- 数据集:自建数据集(含5万首标注诗词)及公开数据集(《全唐诗》《全宋词》)。
4.2 实验设计
- 模型训练与对比:
- 基准模型:朴素贝叶斯、SVM;
- 改进模型:BERT-BiLSTM-CRF、Qwen-7B微调模型;
- 评估指标:准确率、召回率、F1值(情感分析),准确率、MRR(知识图谱关系抽取)。
- 可视化效果验证:
- 用户调研:邀请20名古诗词爱好者对系统交互体验评分(1-5分);
- 性能测试:测试十万级节点图谱的实时交互延迟(目标<500ms)。
4.3 预期成果
- 完成古诗词情感分析系统原型开发,支持知识图谱动态探索与情感分类;
- 提出一种基于LLM与知识图谱的融合分析方法,情感分类准确率较传统方法提升10%-15%;
- 开发交互式可视化Web应用,用户满意度评分≥4.5分;
- 发表学术论文1篇,申请软件著作权1项。
五、创新点与难点
5.1 创新点
- 多模态知识融合:结合诗词文本、书法图像、古乐音频等数据,构建跨模态实体关联;
- 动态知识图谱:引入时序分析,追踪诗人情感随人生阶段(如青年豪放、晚年孤寂)的变化规律;
- 低代码可视化平台:开发拖拽式组件库,降低非技术人员构建诗词图谱的门槛。
5.2 研究难点
- 数据质量问题:古汉语词汇歧义导致实体识别误差(如“东风”既可指春风,也可隐喻离愁);
- 模型泛化能力:跨朝代、跨诗人场景下性能下降(如唐代“悲秋”与宋代“伤春”情感表达差异);
- 大规模图谱渲染性能:十万级节点图谱的实时交互延迟需优化至<500ms。
六、进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 文献调研 | 第1-2月 | 完成国内外研究现状分析,确定技术路线 |
| 数据采集与清洗 | 第3-4月 | 爬取数据,完成数据标准化与特征提取 |
| 模型开发与训练 | 第5-7月 | 构建情感分析模型,优化参数并对比实验结果 |
| 可视化与应用开发 | 第8-9月 | 开发Web应用,实现交互式可视化功能 |
| 论文撰写与答辩 | 第10月 | 整理成果,撰写论文并准备答辩材料 |
七、参考文献
- Django+LLM大模型知识图谱古诗词情感分析技术说明
- 深度学习之基于Django文本情感分析识别系统
- LLM大模型在知识图谱构建中的应用与实践
- 诗歌鉴赏中常见的手法赏析之抒情方法的赏析
- 高考复习|古代诗歌阅读:鉴赏思想感情的方法
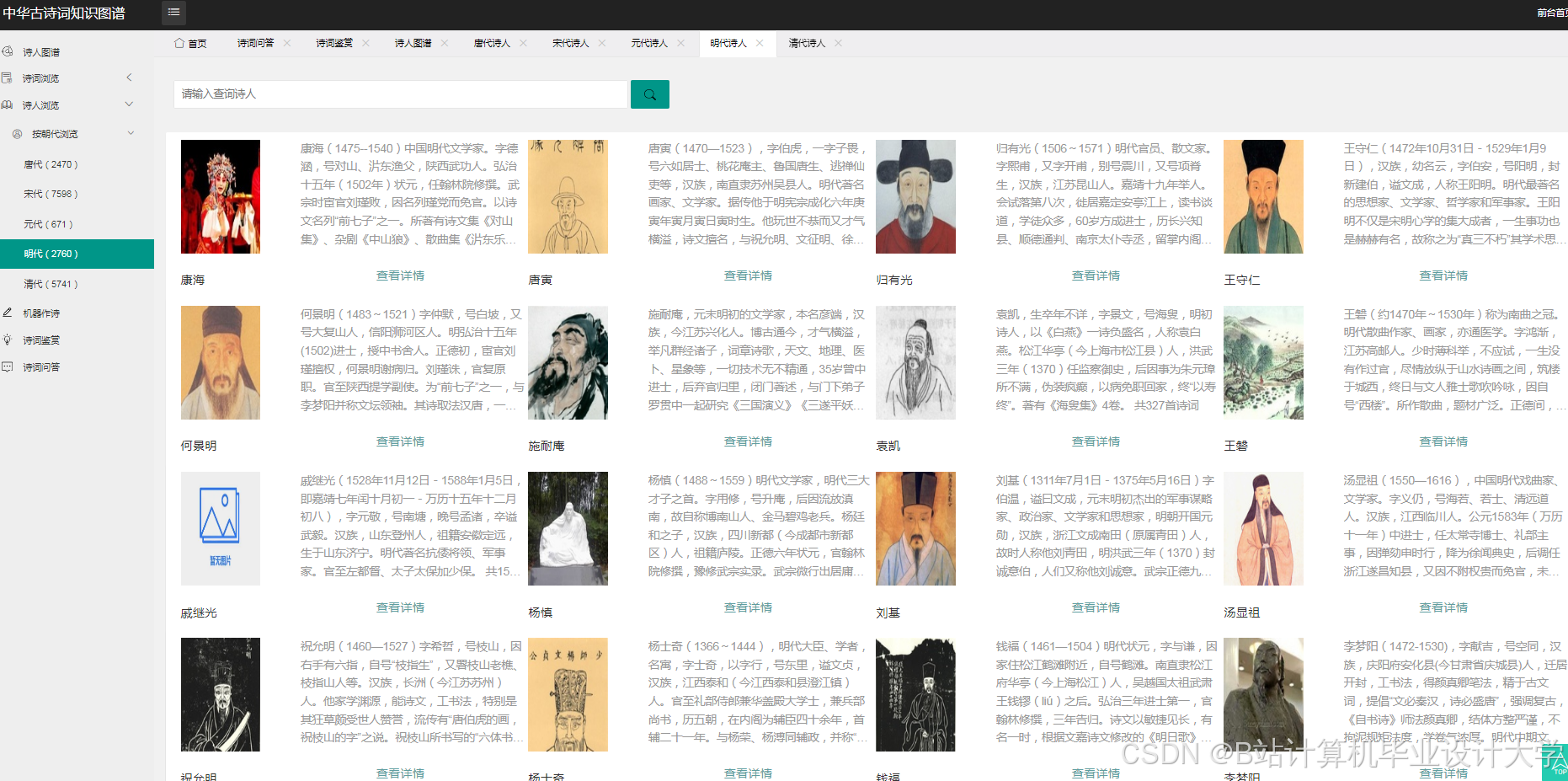
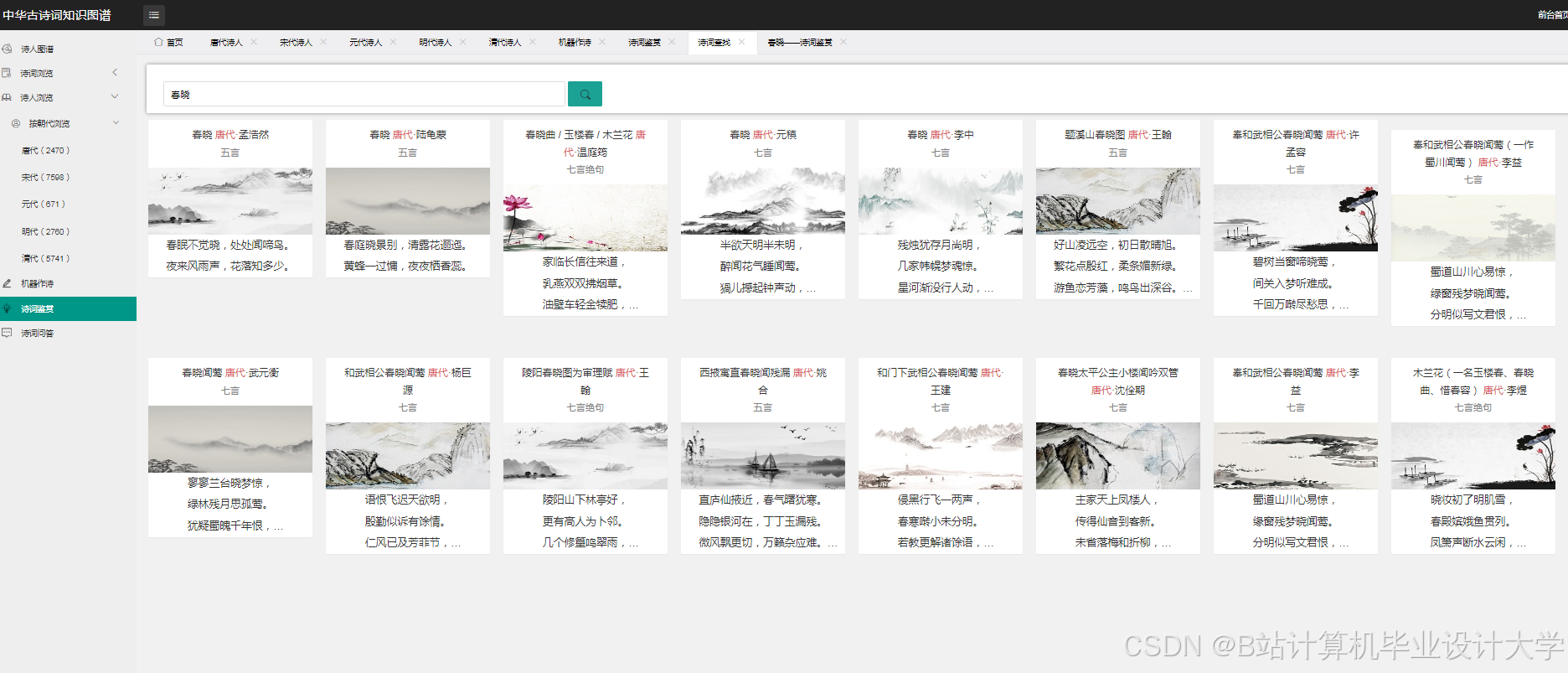
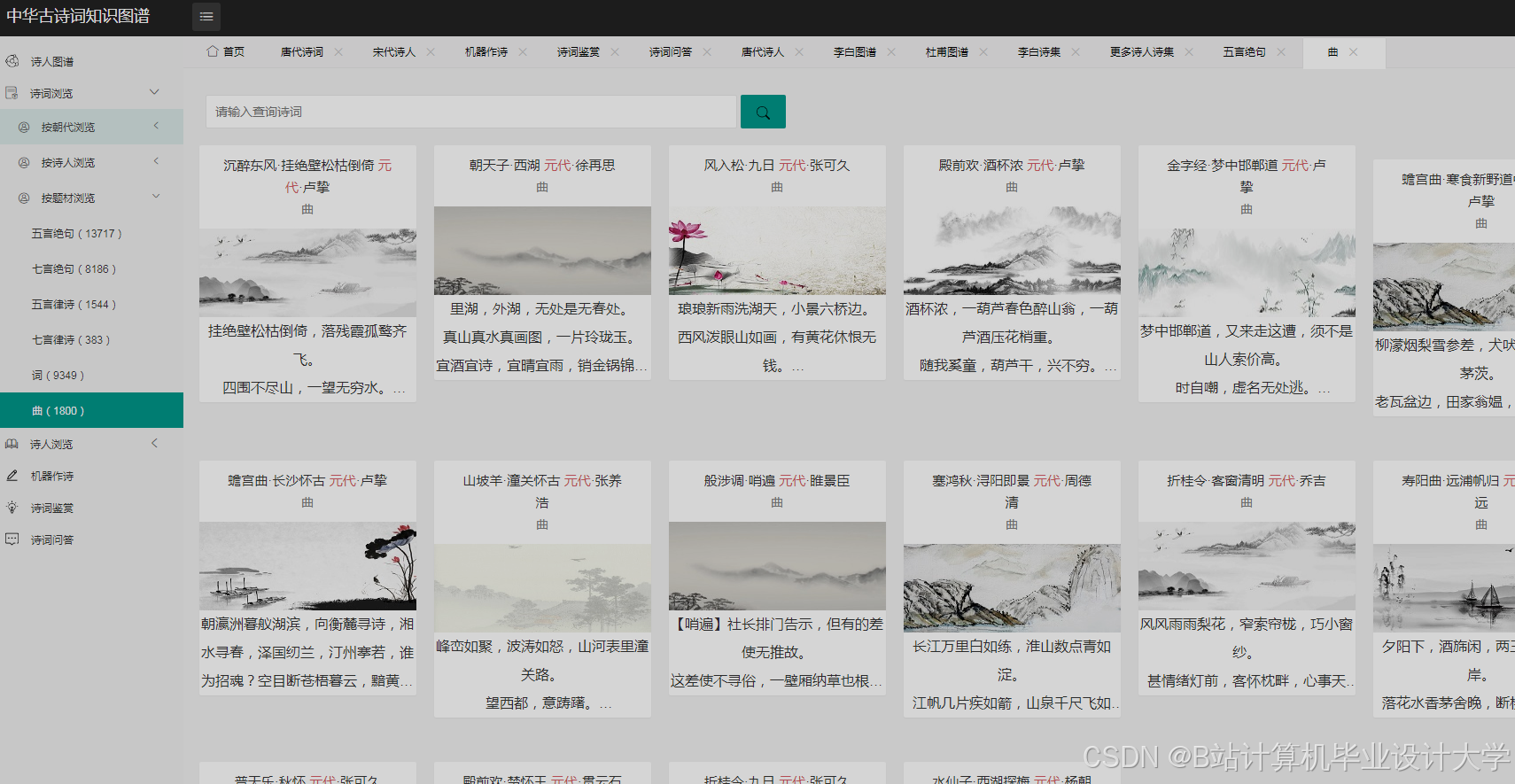
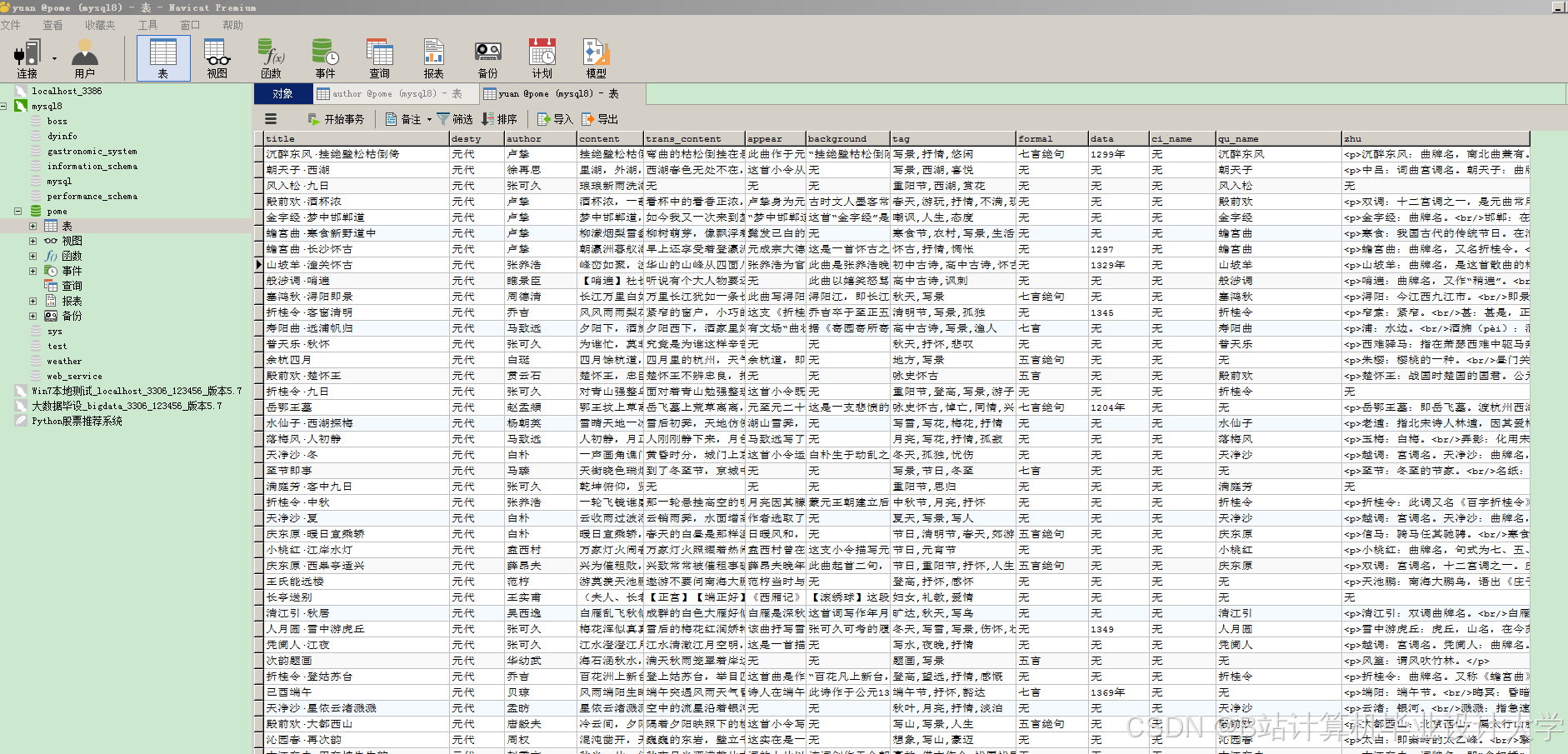
运行截图
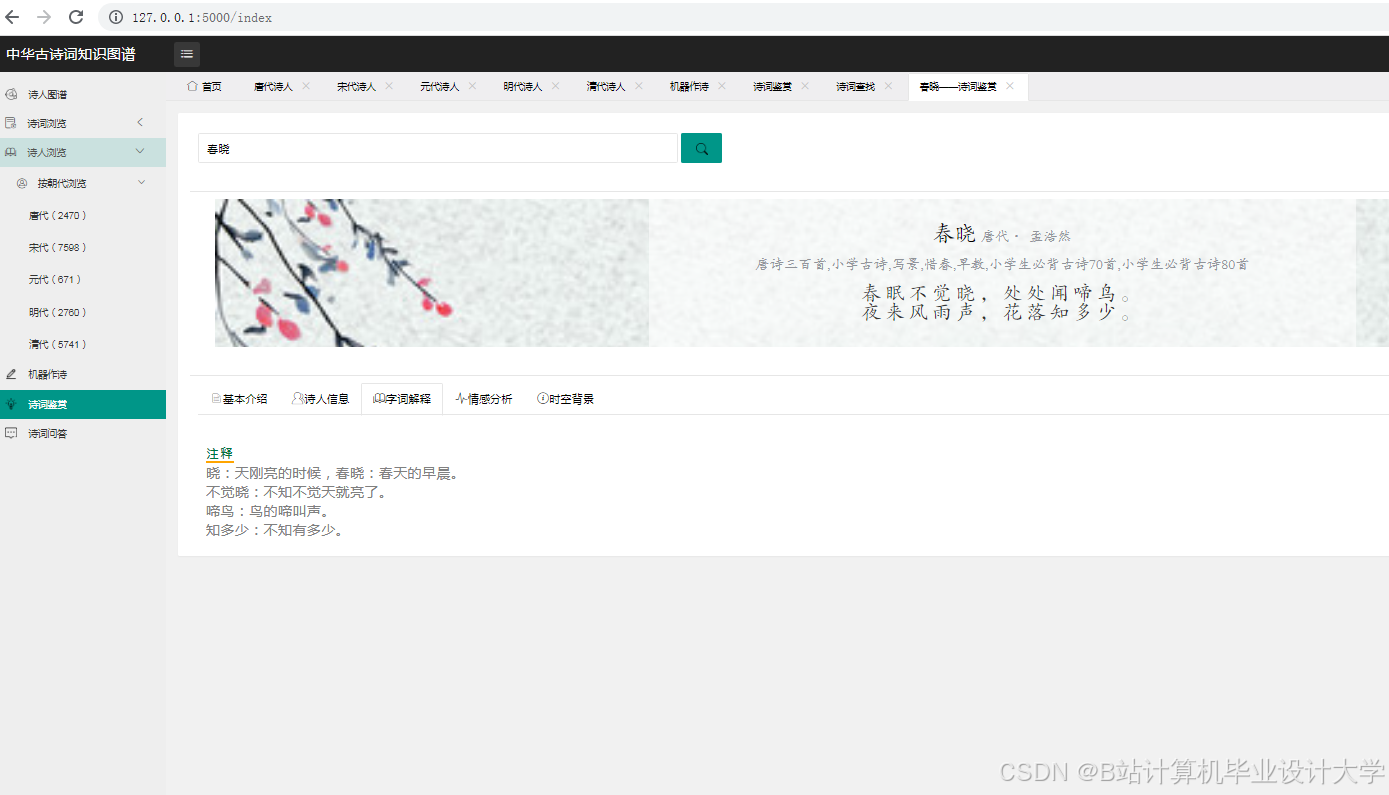
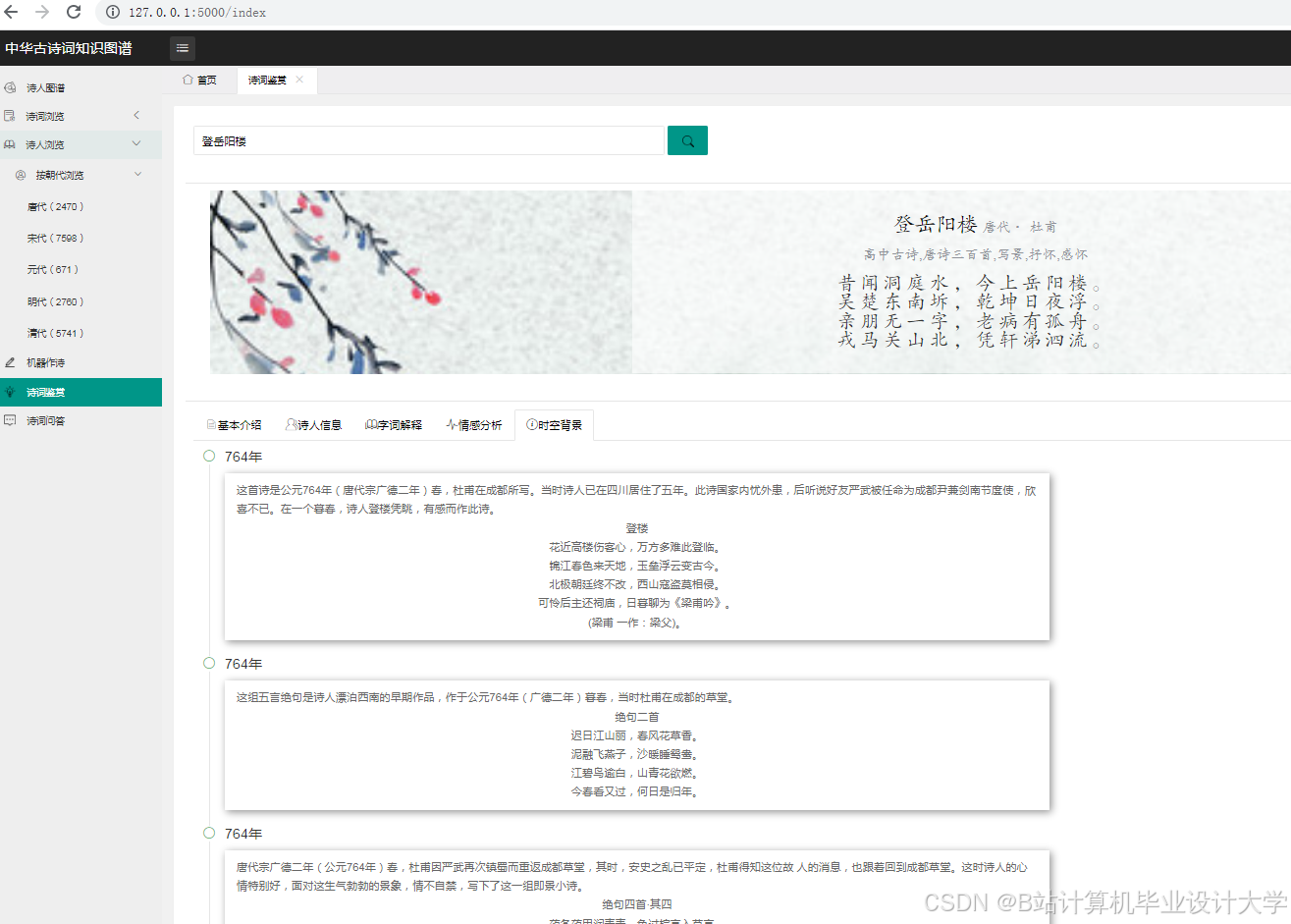
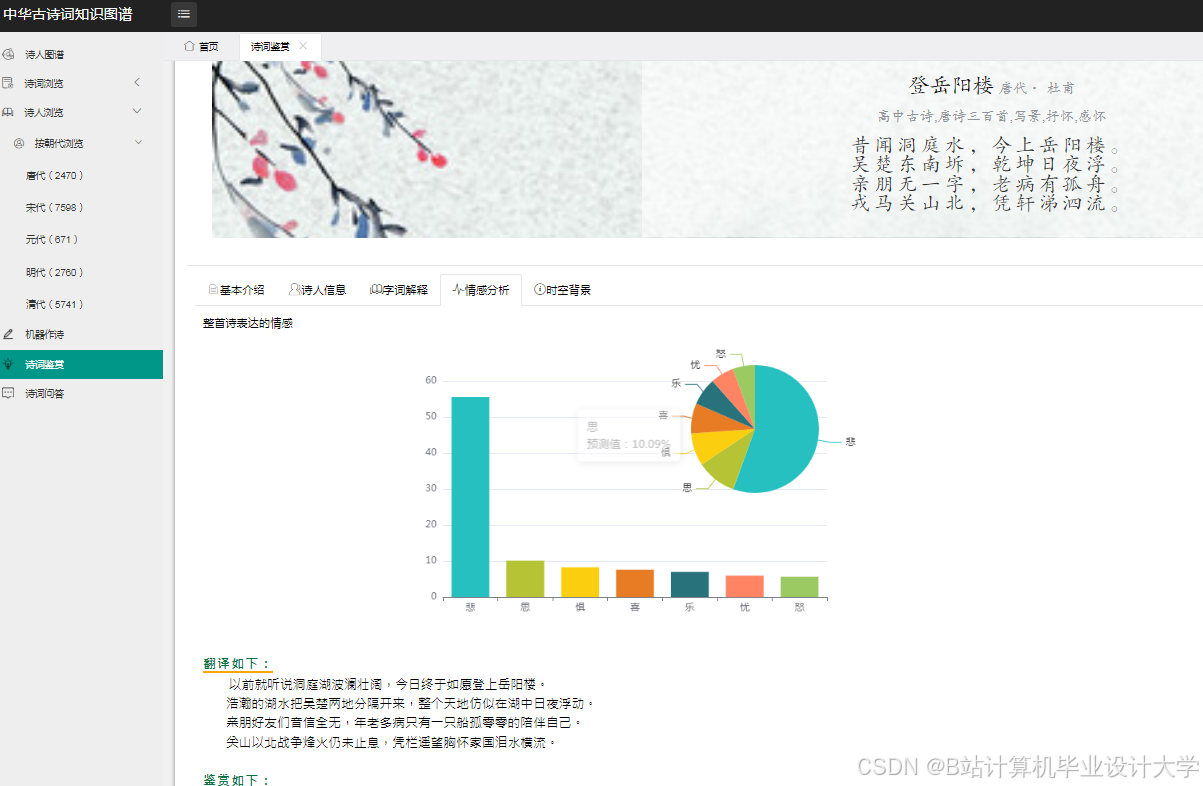
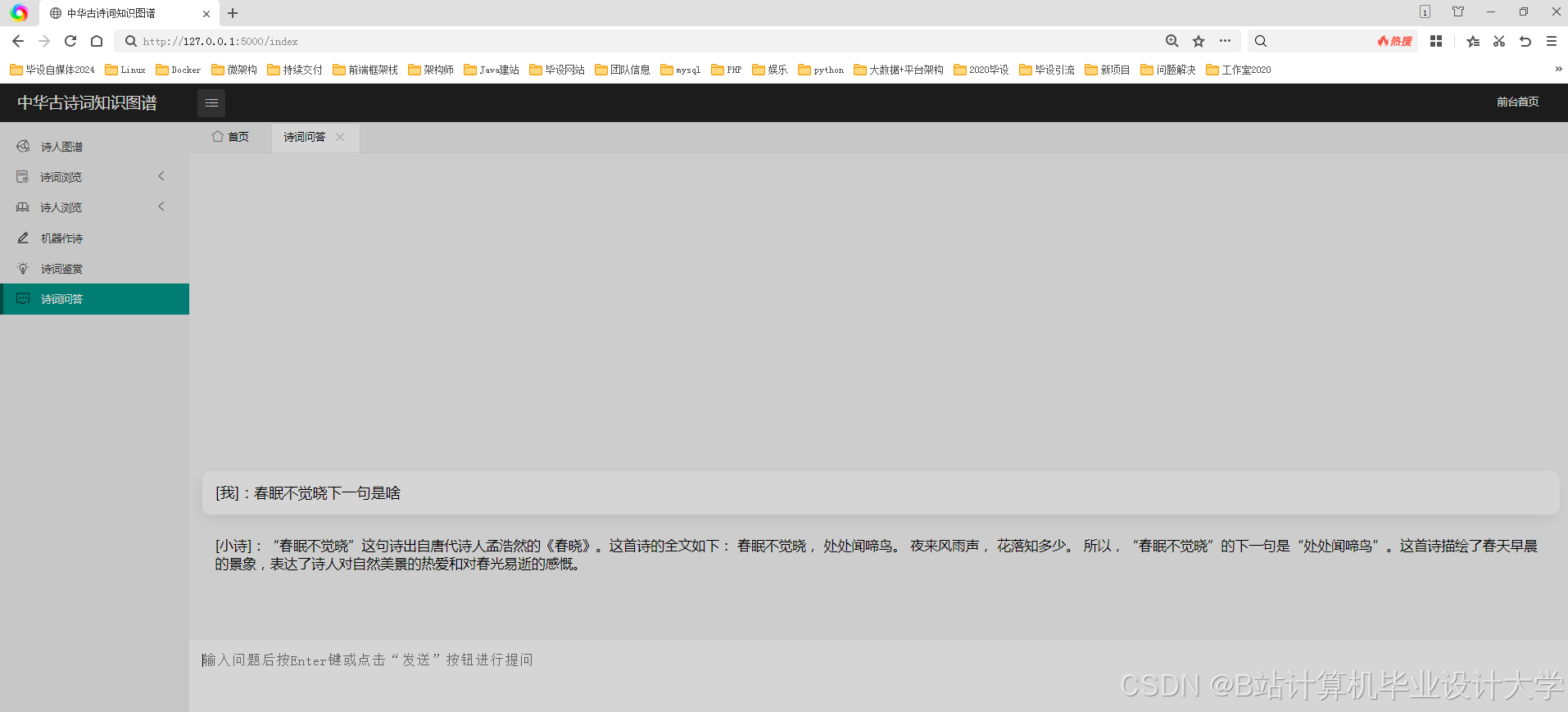
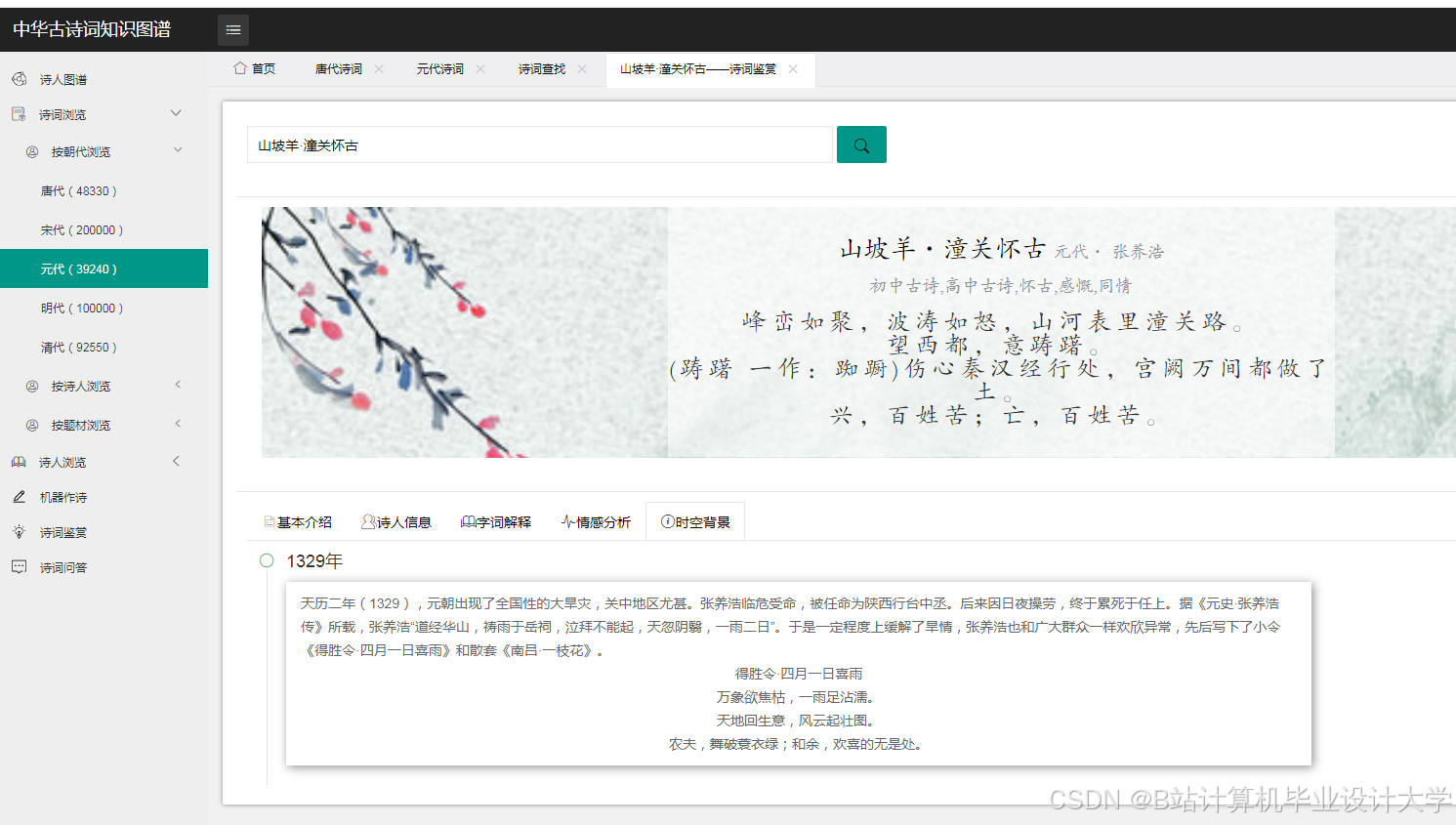
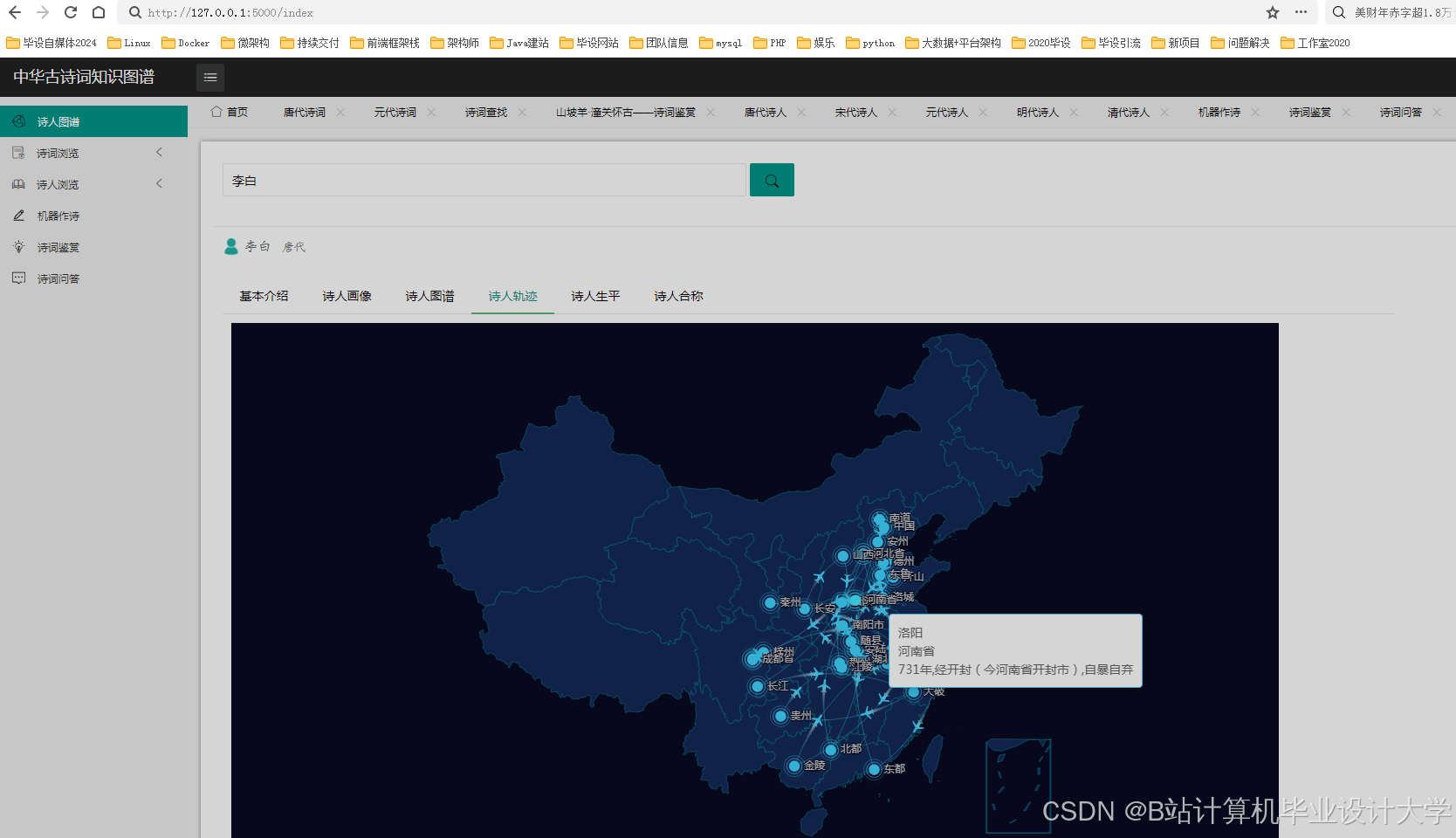
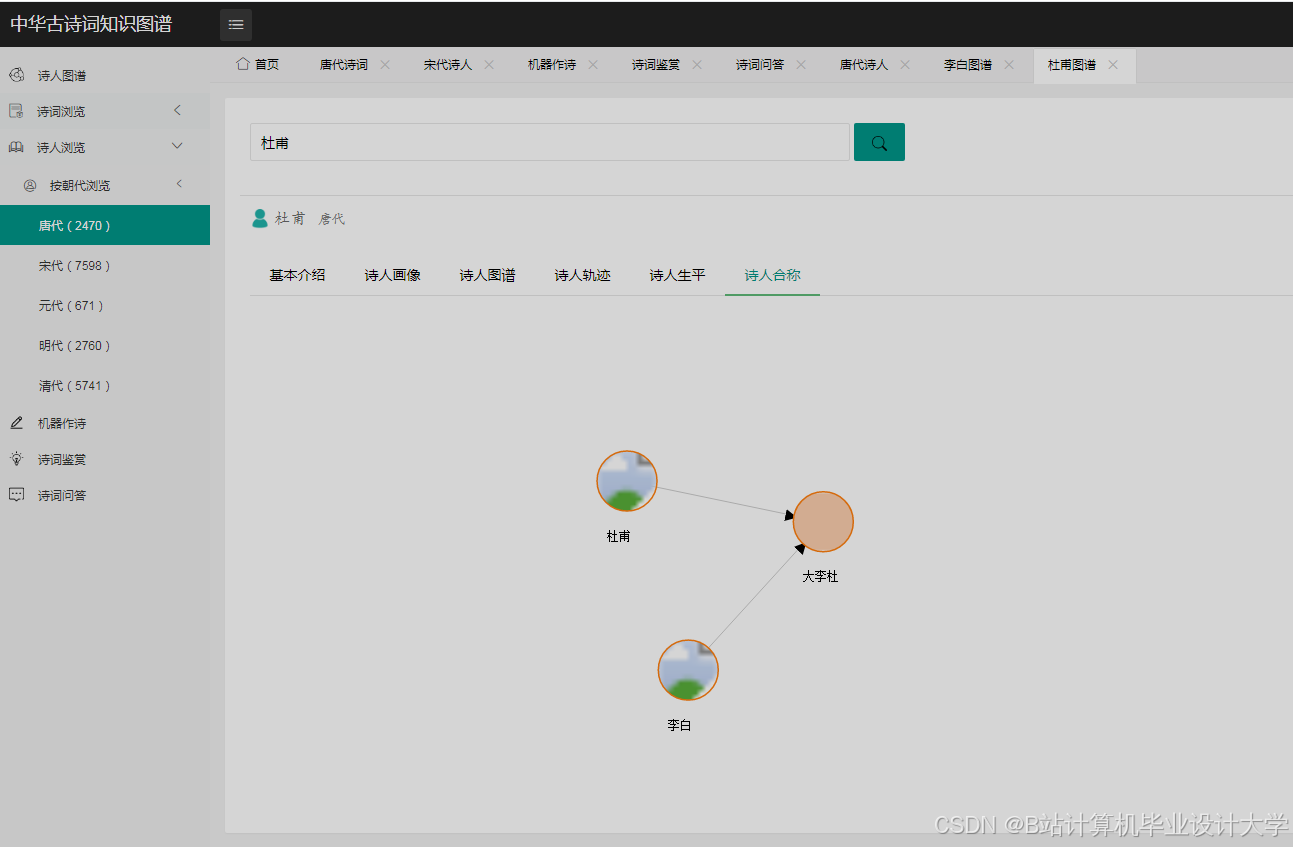
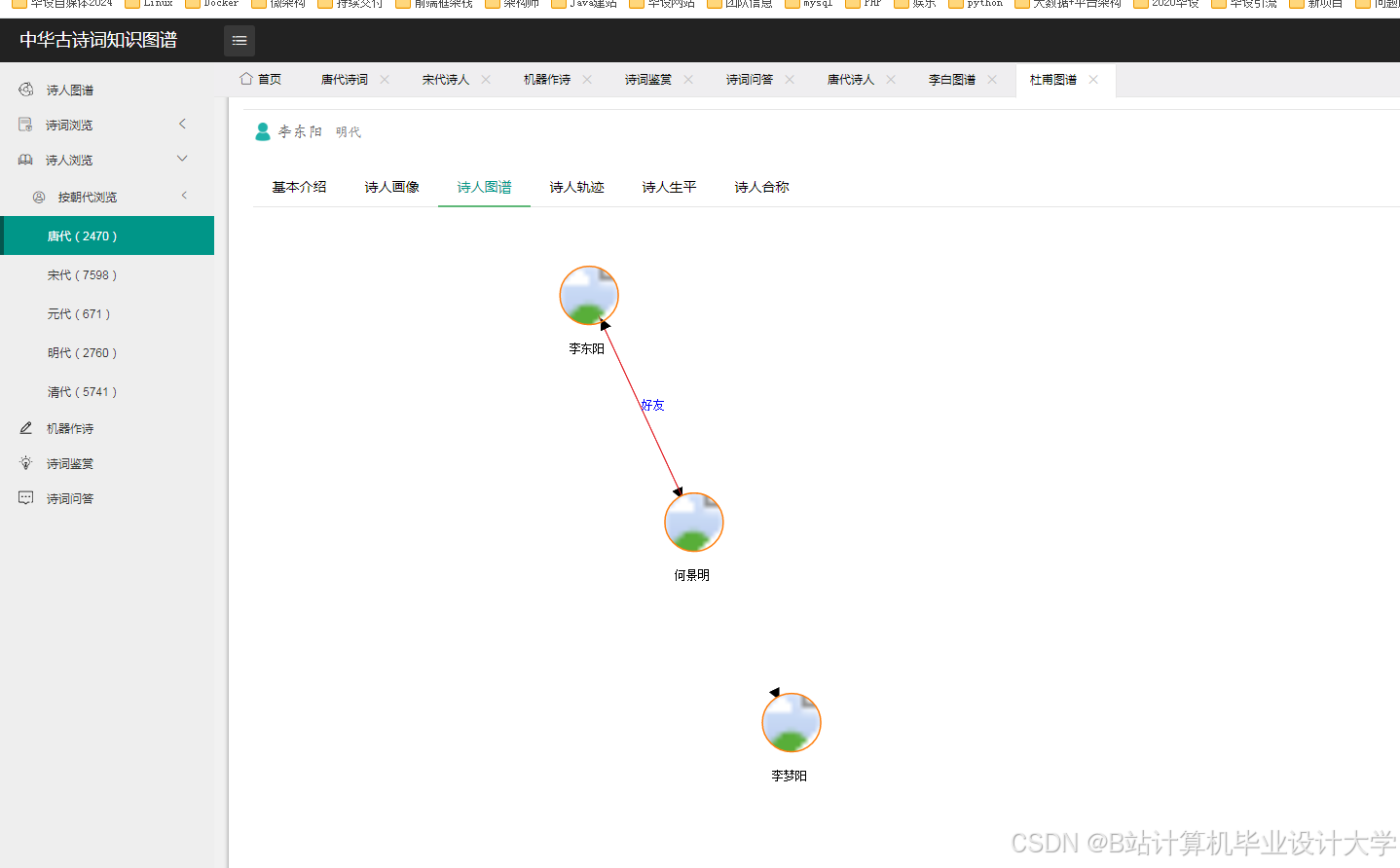

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











