




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python职业篮球运动员数据分析可视化与球员预测技术说明
一、项目背景与目标
职业篮球联赛(如NBA、CBA)数据量庞大且维度丰富,涵盖球员基础信息、比赛技术统计、战术执行数据等。传统分析依赖人工统计和经验判断,难以挖掘数据深层规律。本系统基于Python构建自动化数据分析与可视化平台,整合多赛季球员数据,通过机器学习模型预测球员未来表现(如得分、篮板、效率值),为球队选秀、交易和战术制定提供数据支持。目标用户包括球队经理、教练和篮球分析师,核心需求包括:
- 快速生成球员技术统计可视化报告(如得分趋势、投篮热区);
- 预测球员未来赛季表现,辅助决策;
- 对比球员能力,识别潜力新星或高性价比球员。
二、系统架构设计
系统采用模块化设计,包含数据采集、数据预处理、数据分析与可视化、预测模型四大模块,各模块通过Python库协同工作。
(一)数据采集模块
- 数据源:
- 官方API:如NBA官方API(
stats.nba.com)提供球员基础信息(身高、体重、位置)、比赛数据(得分、篮板、助攻)和高级统计(PER效率值、Win Shares胜利贡献值)。 - 第三方数据平台:如Basketball Reference、ESPN,补充历史数据(如新秀赛季表现)和衍生指标(如真实命中率TS%)。
- 爬虫采集:使用
requests和BeautifulSoup爬取网页数据,例如球员新闻动态(伤病信息、交易传闻)作为辅助特征。
- 官方API:如NBA官方API(
- 数据存储:
- 结构化数据(如比赛统计)存入CSV或SQLite数据库,便于快速查询;
- 非结构化数据(如新闻文本)存入MongoDB,支持灵活检索。
(二)数据预处理模块
- 数据清洗:
- 处理缺失值:如用球员职业生涯均值填充单场数据缺失;
- 修正异常值:如剔除得分超过60分的异常比赛(可能为数据录入错误);
- 统一数据格式:如将日期格式标准化为
YYYY-MM-DD。
- 特征工程:
- 基础特征:身高、体重、年龄、位置;
- 技术统计特征:过去3个赛季的场均得分、篮板、助攻、投篮命中率;
- 衍生特征:
- 效率值(PER):综合评估球员贡献的指标;
- 投篮热区效率:将球场划分为多个区域,计算各区域命中率与联盟平均值的差值;
- 比赛影响力指标:如
Box Plus/Minus(BPM)衡量球员在场时对球队得分差的影响。
- 时间序列特征:滑动窗口统计(如过去5场比赛的得分波动率)。
(三)数据分析与可视化模块
- 可视化库:
Matplotlib/Seaborn:绘制基础统计图表(如柱状图对比球员得分、折线图展示赛季得分趋势);Plotly:生成交互式图表(如投篮热区3D散点图,支持缩放和悬停查看具体数据);Pandas Profiling:自动生成数据报告,包含统计摘要、缺失值分析和相关性矩阵。
- 典型可视化场景:
- 球员对比:雷达图展示5名球员在得分、篮板、助攻、防守等维度的能力;
- 投篮分析:用
Plotly绘制投篮位置散点图,颜色深浅表示命中率高低; - 趋势预测:折线图叠加预测区间,展示球员未来3个赛季得分可能范围。
(四)预测模型模块
- 模型选择:
- 线性回归:适用于简单特征与目标变量(如场均得分)的线性关系预测;
- 随机森林:处理高维特征(如技术统计+衍生特征),避免过拟合;
- XGBoost:基于梯度提升树的优化算法,支持并行计算,适合大规模数据训练;
- LSTM神经网络:捕捉时间序列数据(如球员状态随赛季变化的规律),预测未来表现。
- 模型训练与评估:
- 数据划分:按时间划分训练集(前70%赛季)和测试集(后30%赛季);
- 评估指标:
- 回归任务:均方误差(MSE)、平均绝对误差(MAE);
- 分类任务(如预测球员是否入选全明星):准确率、F1分数。
- 模型优化:
- 特征选择:通过
sklearn的SelectKBest筛选重要性高的特征; - 超参数调优:使用
GridSearchCV或Optuna搜索最佳参数(如随机森林的树深度、LSTM的隐藏层维度)。
- 特征选择:通过
三、关键技术实现
(一)数据采集与存储
- NBA API调用示例:
python
1import requests
2import pandas as pd
3
4# 获取球员基础信息
5url = "https://api.stats.nba.com/stats/commonallplayers"
6params = {
7 "LeagueID": "00",
8 "Season": "2023-24",
9 "IsOnlyCurrentSeason": "0"
10}
11headers = {"User-Agent": "Mozilla/5.0"}
12response = requests.get(url, params=params, headers=headers)
13data = response.json()["resultSets"][0]["rowSet"]
14columns = response.json()["resultSets"][0]["headers"]
15players_df = pd.DataFrame(data, columns=columns)
16players_df.to_csv("players_2023.csv", index=False)- SQLite存储比赛数据:
python
1import sqlite3
2conn = sqlite3.connect("basketball.db")
3cursor = conn.cursor()
4cursor.execute("""
5 CREATE TABLE IF NOT EXISTS game_stats (
6 player_id INTEGER,
7 season TEXT,
8 pts REAL,
9 reb REAL,
10 ast REAL,
11 PRIMARY KEY (player_id, season)
12 )
13""")
14# 插入数据示例
15cursor.execute("INSERT INTO game_stats VALUES (123, '2023-24', 25.3, 8.2, 4.5)")
16conn.commit()
17conn.close()(二)数据预处理与特征工程
- 计算效率值(PER):
python
1def calculate_per(df):
2 # 简化版PER计算公式(实际需更复杂逻辑)
3 uPER = (df["pts"] + 0.44 * df["fta"] * (1 - df["ft%"]) +
4 0.5 * df["trb"] + 0.25 * df["ast"] + ...) / df["mp"]
5 per = uPER * (15 / df["league_pace"])
6 return per
7df["PER"] = calculate_per(df)- 投篮热区特征提取:
python
1import numpy as np
2# 假设投篮数据包含x,y坐标和命中结果(1=命中,0=未命中)
3shots = pd.DataFrame({
4 "x": np.random.uniform(-25, 25, 1000), # 球场x坐标(-25到25英尺)
5 "y": np.random.uniform(-47.5, 0, 1000), # 球场y坐标(-47.5到0英尺)
6 "made": np.random.randint(0, 2, 1000)
7})
8# 将球场划分为5x5区域
9shots["zone_x"] = pd.cut(shots["x"], bins=5, labels=False)
10shots["zone_y"] = pd.cut(shots["y"], bins=5, labels=False)
11# 计算各区域命中率
12heatmap = shots.groupby(["zone_x", "zone_y"])["made"].mean().unstack()(三)可视化实现
- 投篮热区3D可视化:
python
1import plotly.graph_objects as go
2import numpy as np
3
4# 生成模拟数据
5x = np.linspace(-25, 25, 10)
6y = np.linspace(-47.5, 0, 10)
7X, Y = np.meshgrid(x, y)
8Z = np.random.rand(10, 10) # 命中率模拟值
9
10fig = go.Figure(data=[go.Surface(z=Z, x=X, y=Y, colorscale="Viridis")])
11fig.update_layout(title="投篮热区命中率", scene=dict(zaxis=dict(title="命中率")))
12fig.show()- 球员能力雷达图:
python
1import plotly.express as px
2
3categories = ["得分", "篮板", "助攻", "抢断", "盖帽"]
4player1 = [25.3, 8.2, 4.5, 1.2, 0.8]
5player2 = [20.1, 10.5, 3.8, 1.5, 1.2]
6
7fig = px.line_polar(
8 r=[player1, player2],
9 theta=categories,
10 line_close=True,
11 title="球员能力对比"
12)
13fig.show()(四)预测模型实现
- XGBoost预测场均得分:
python
1import xgboost as xgb
2from sklearn.model_selection import train_test_split
3from sklearn.metrics import mean_absolute_error
4
5# 特征:身高、体重、年龄、过去3年场均得分、篮板、助攻
6X = df[["height", "weight", "age", "pts_last1", "reb_last1", "ast_last1"]]
7y = df["pts_next"] # 目标变量:下赛季场均得分
8
9X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
10model = xgb.XGBRegressor(
11 n_estimators=100,
12 max_depth=5,
13 learning_rate=0.1
14)
15model.fit(X_train, y_train)
16preds = model.predict(X_test)
17print("MAE:", mean_absolute_error(y_test, preds))- LSTM时间序列预测:
python
1import torch
2import torch.nn as nn
3import numpy as np
4
5# 假设数据为球员过去5个赛季的场均得分
6data = np.array([20.1, 22.3, 24.5, 23.8, 25.2]).reshape(-1, 1)
7# 转换为LSTM输入格式(样本数, 时间步长, 特征数)
8X = data[:-1].reshape(1, 4, 1) # 用前4个赛季预测第5个赛季
9y = data[1:].reshape(1, 4, 1) # 实际值(用于监督学习)
10
11class LSTMModel(nn.Module):
12 def __init__(self):
13 super().__init__()
14 self.lstm = nn.LSTM(input_size=1, hidden_size=10, batch_first=True)
15 self.fc = nn.Linear(10, 1)
16 def forward(self, x):
17 out, _ = self.lstm(x)
18 out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出
19 return out
20
21model = LSTMModel()
22criterion = nn.MSELoss()
23optimizer = torch.optim.Adam(model.parameters())
24# 训练逻辑(简化版)
25for epoch in range(100):
26 outputs = model(torch.FloatTensor(X))
27 loss = criterion(outputs, torch.FloatTensor(y[:, -1, :]))
28 optimizer.zero_grad()
29 loss.backward()
30 optimizer.step()四、系统测试与优化
(一)功能测试
- 数据采集测试:验证API调用是否返回完整数据,爬虫是否抓取到目标网页内容;
- 可视化测试:检查图表是否正确显示数据(如投篮热区颜色是否与命中率对应);
- 预测测试:输入历史数据后,模型输出是否符合逻辑(如年轻球员预测得分高于退役球员)。
(二)性能测试
- 数据处理速度:测试10万条数据的清洗和特征工程耗时(优化后应<1分钟);
- 模型训练时间:XGBoost在10万样本上的训练时间应<5分钟;
- 可视化渲染速度:复杂图表(如3D热区)生成时间应<3秒。
(三)预测效果测试
- 基准对比:与NBA官方预测或专家预测对比,验证模型准确性;
- 误差分析:识别预测偏差大的案例(如伤病影响未被模型捕捉),优化特征工程。
五、总结与展望
本系统通过Python生态库实现了职业篮球运动员数据的自动化采集、清洗、分析和预测,为球队决策提供了量化支持。未来可扩展以下方向:
- 实时分析:结合WebSocket实时推送比赛数据,动态更新球员表现预测;
- 战术分析:通过球员位置数据和传球网络分析战术执行效果;
- 多模态融合:引入视频分析(如计算机视觉识别球员动作)和音频分析(如解说情绪),提升预测全面性。
运行截图
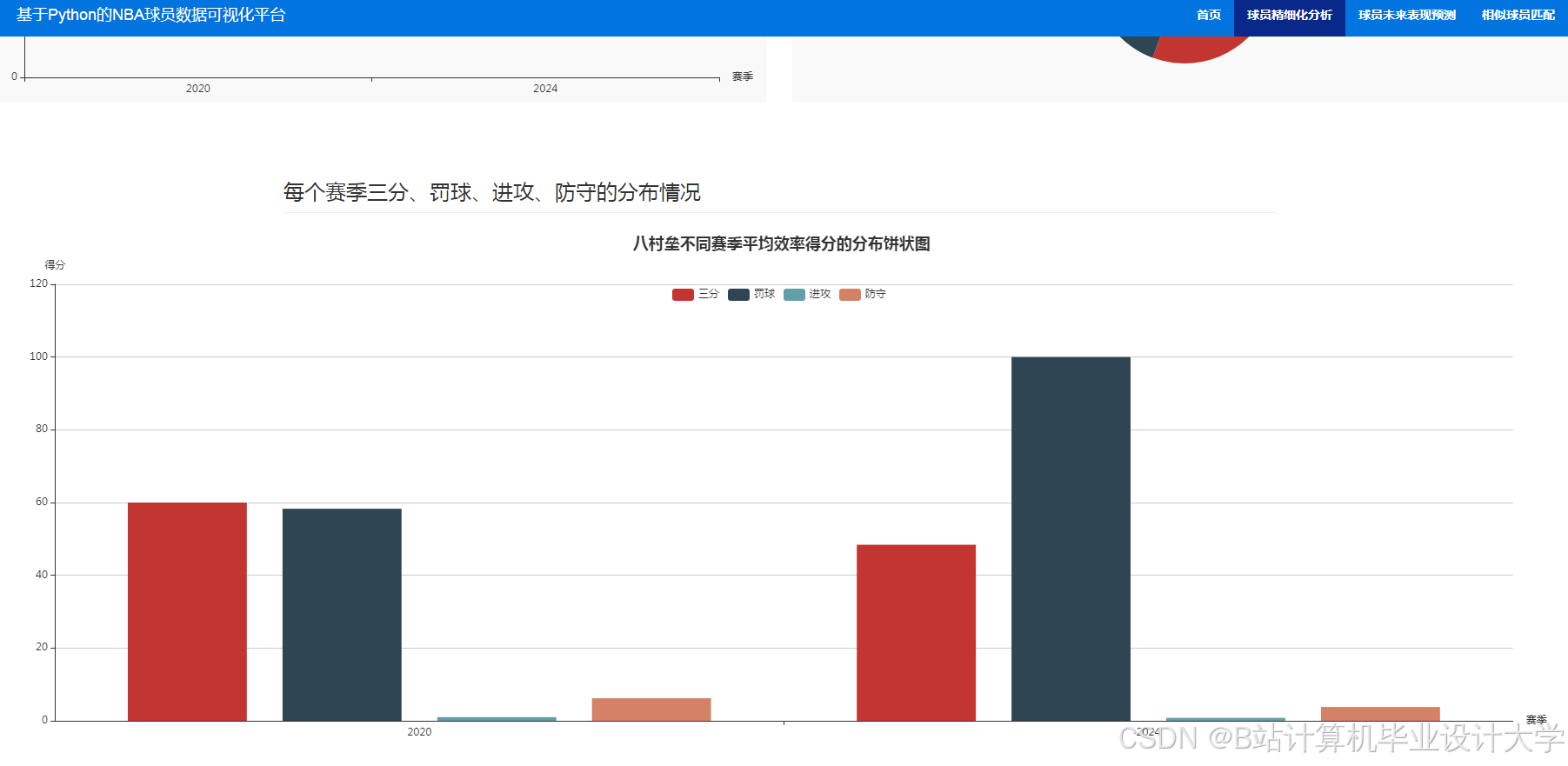
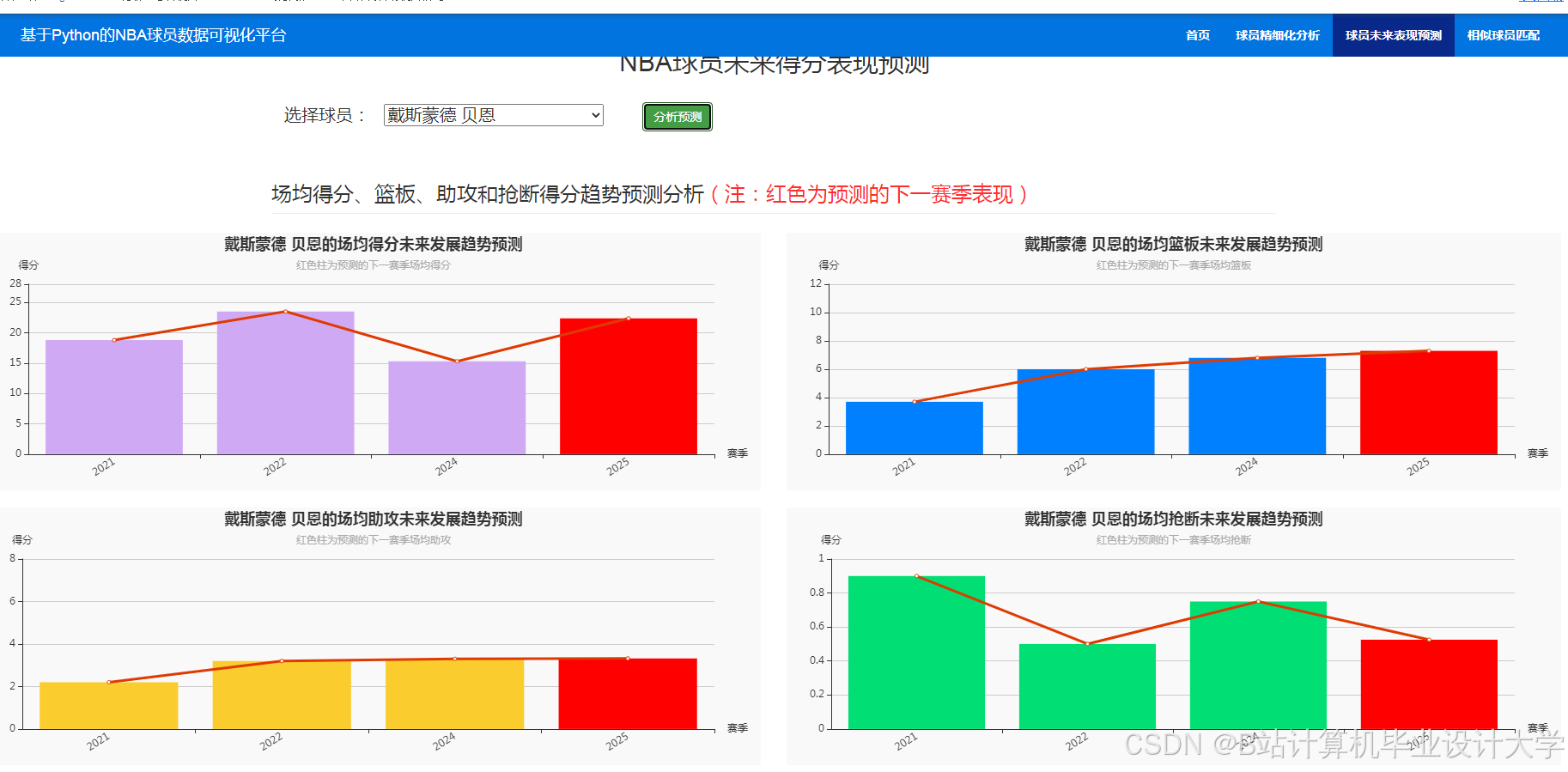
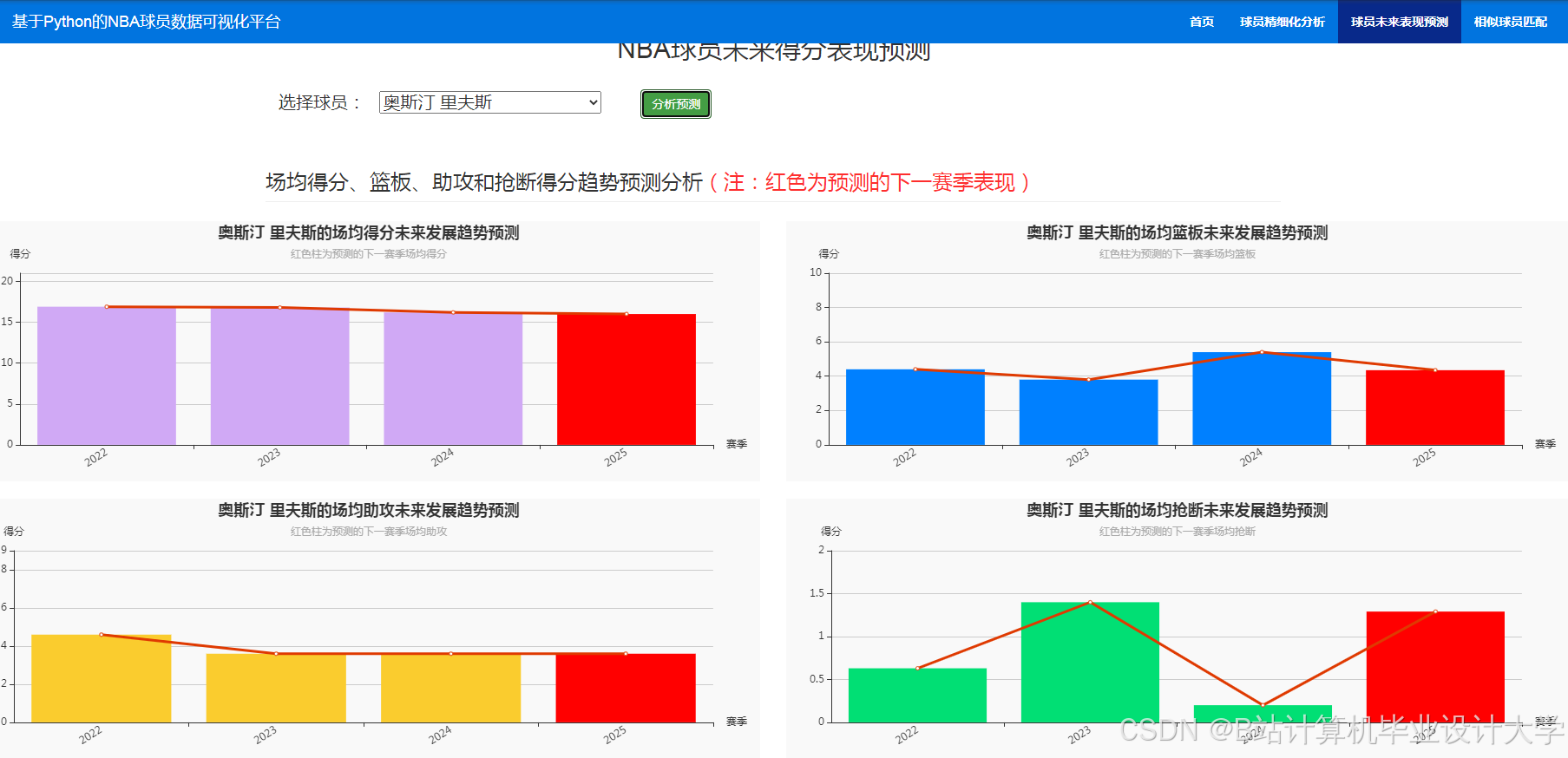
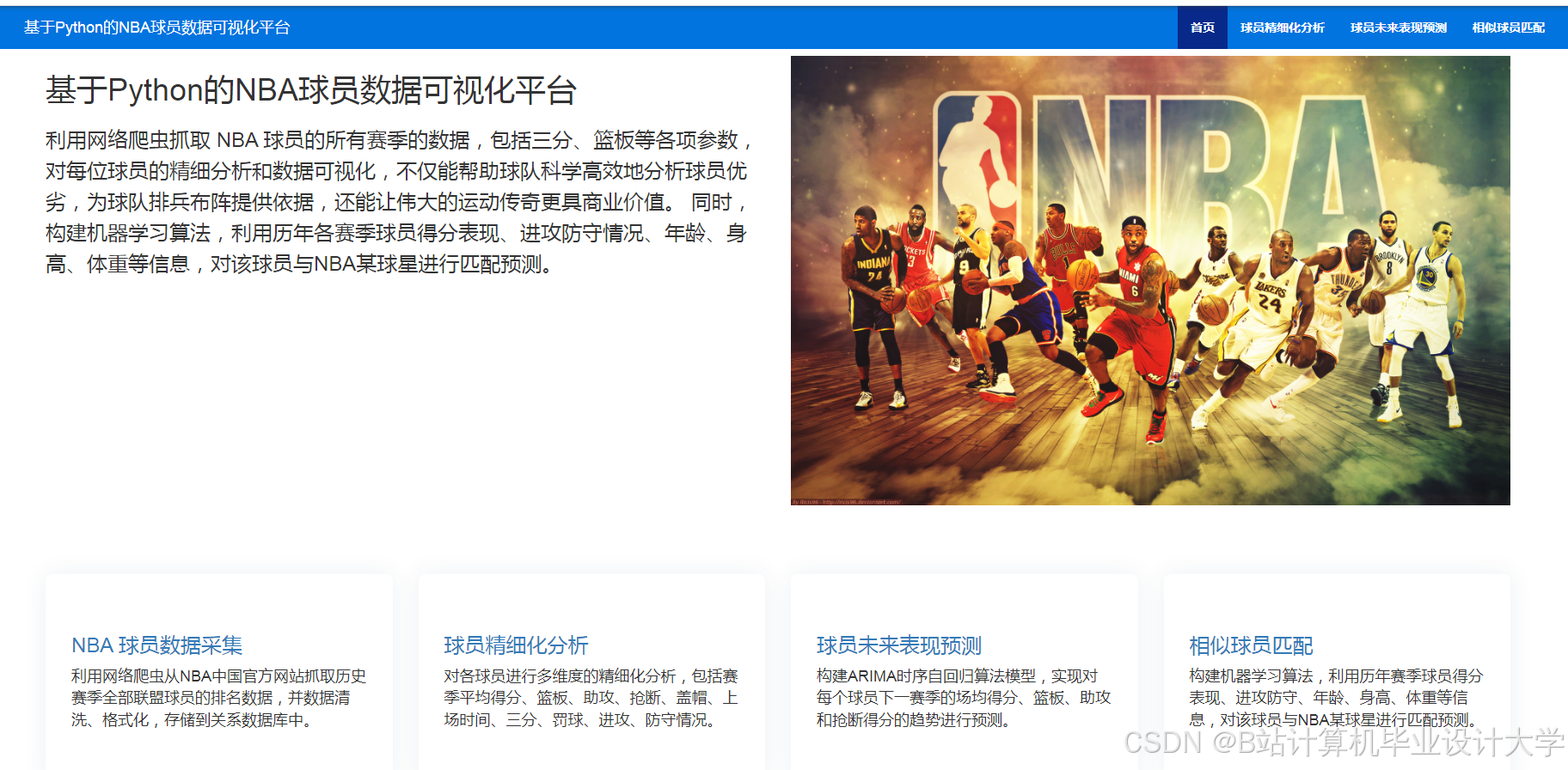
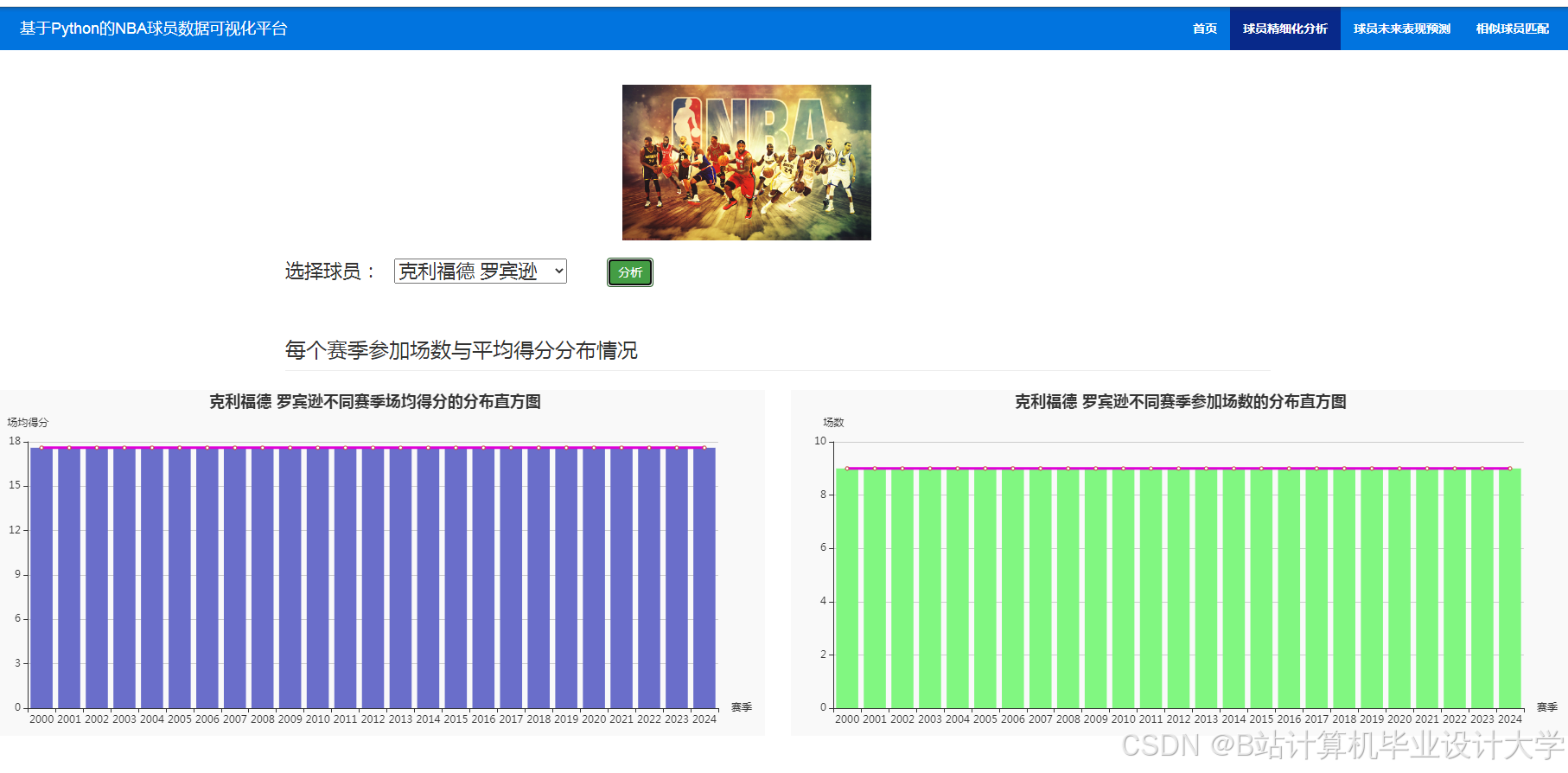
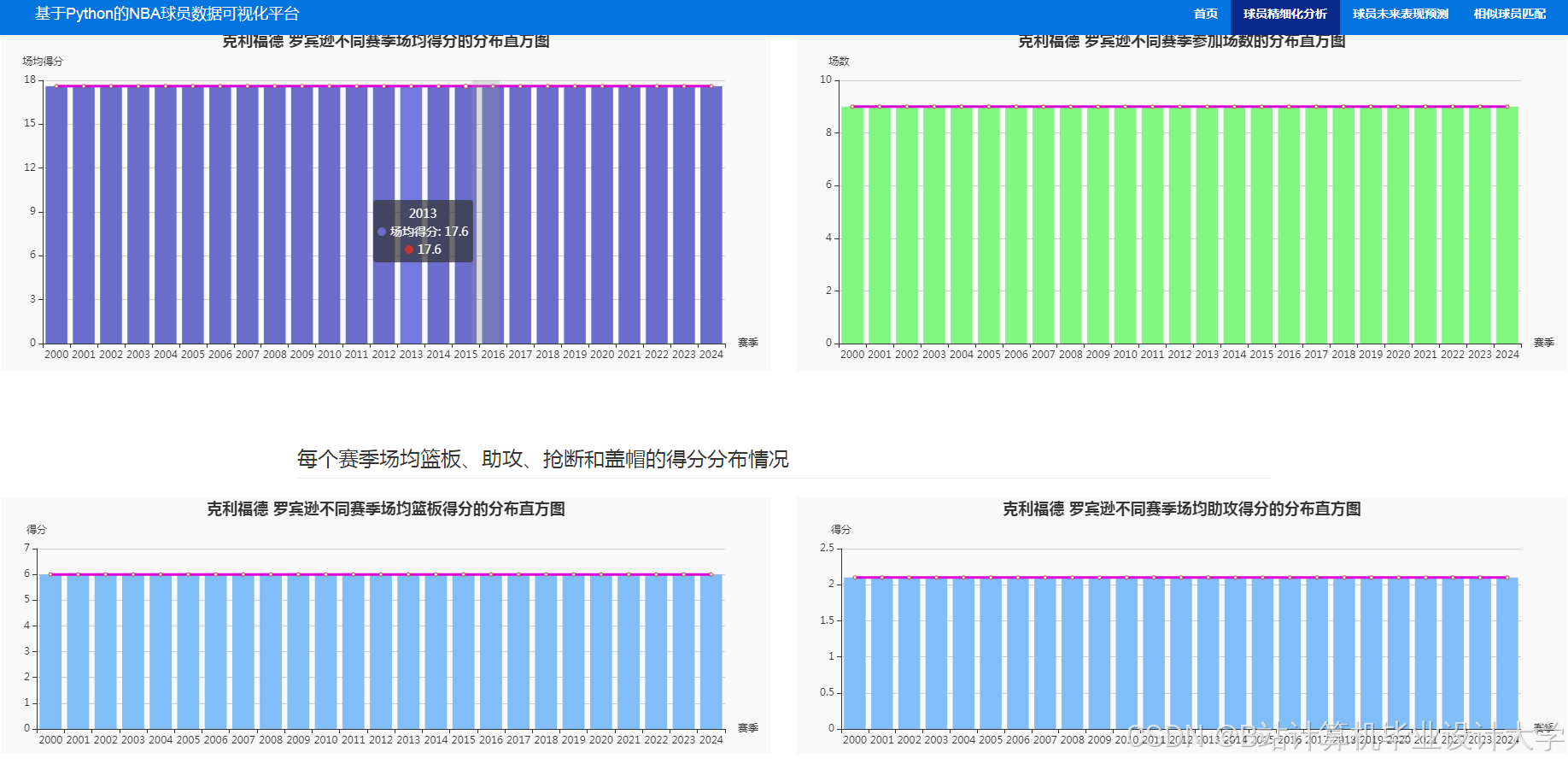
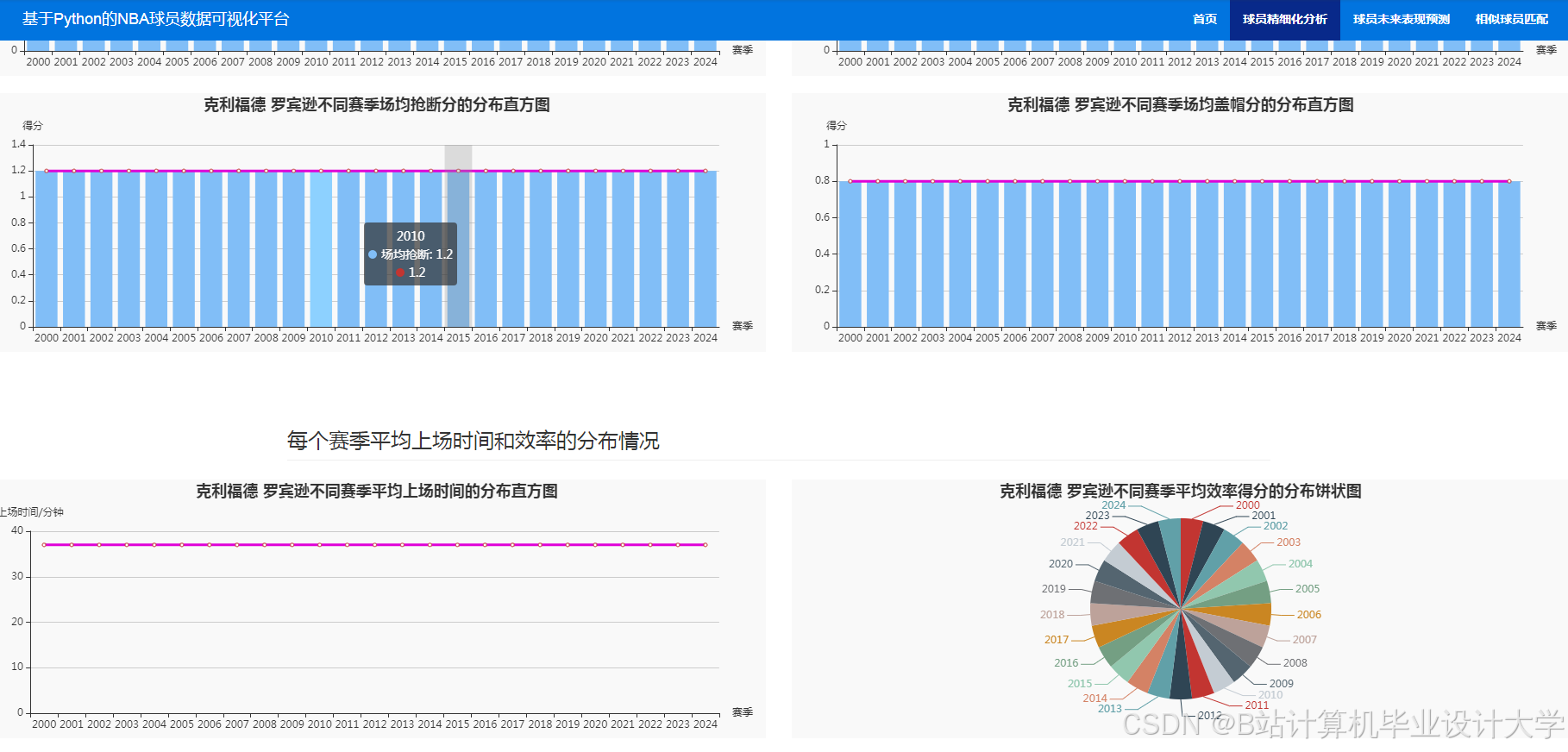
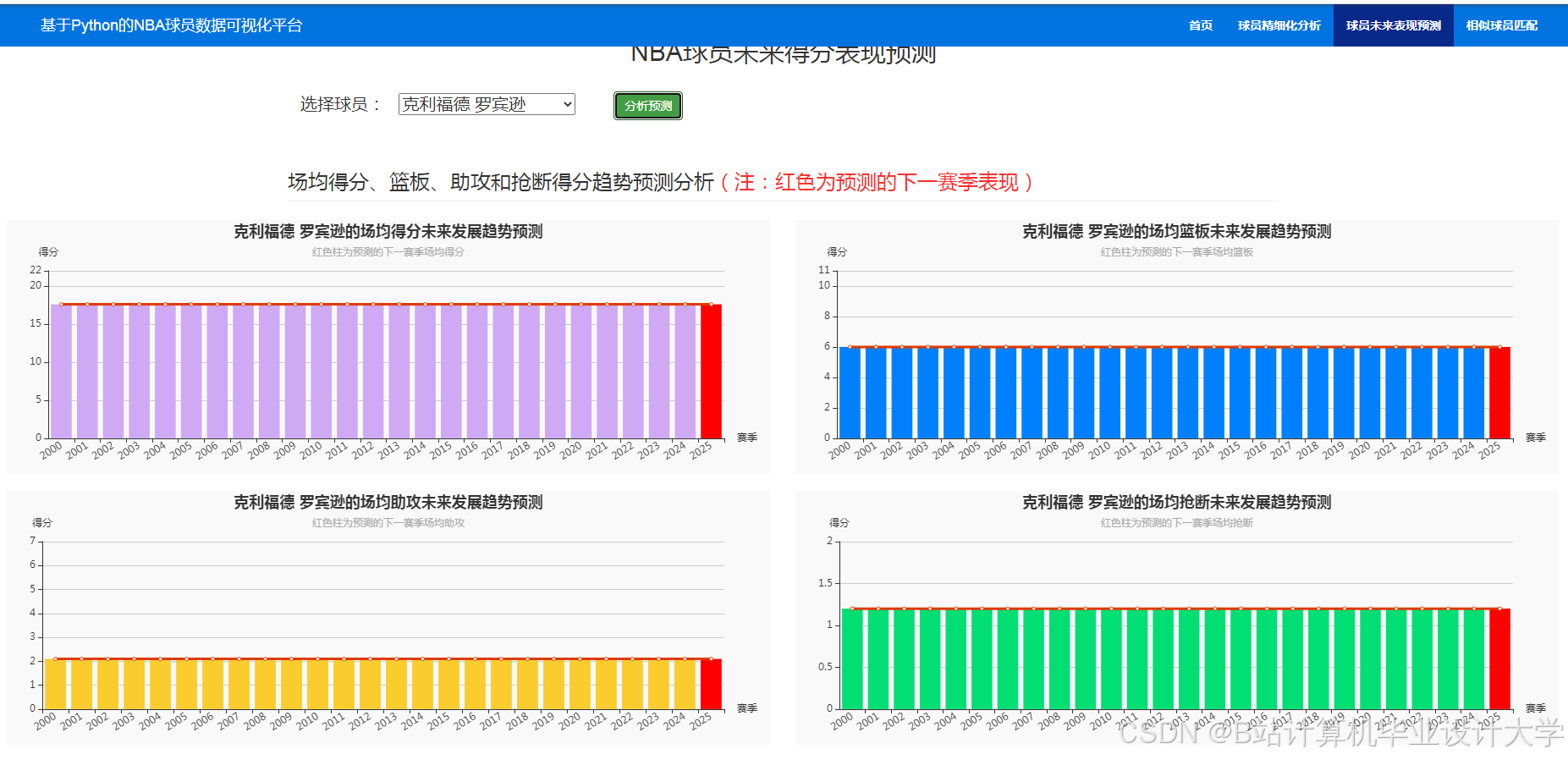
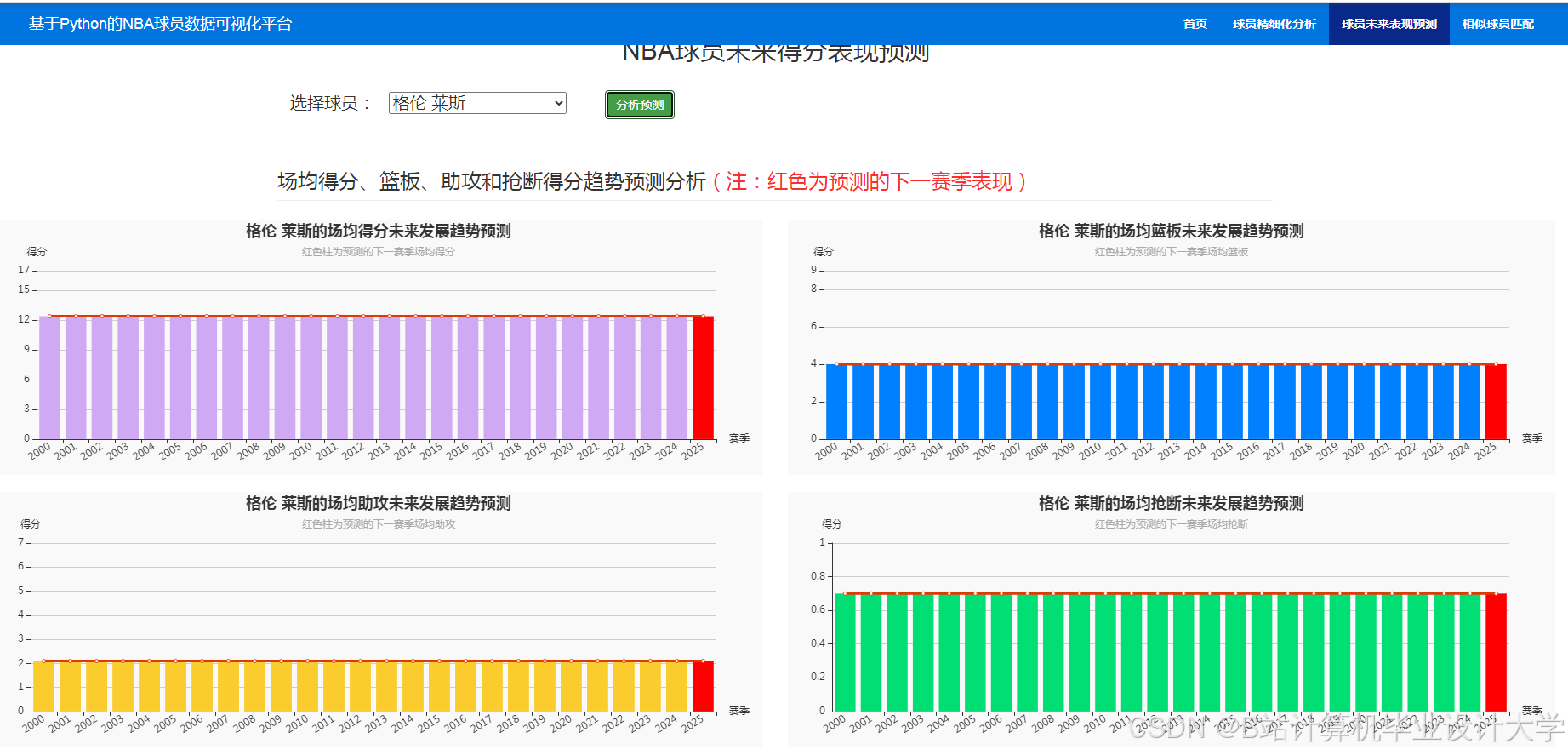
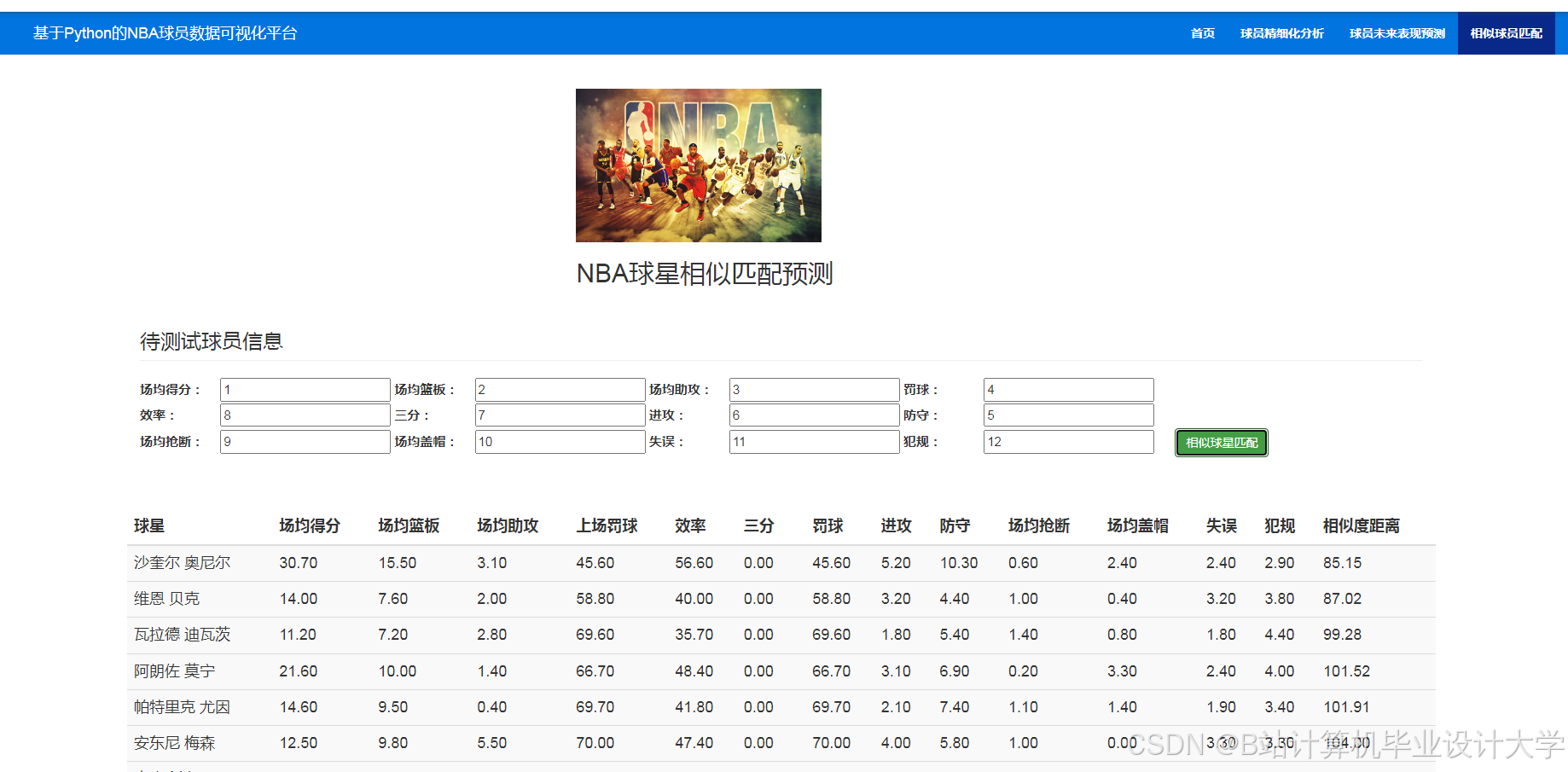

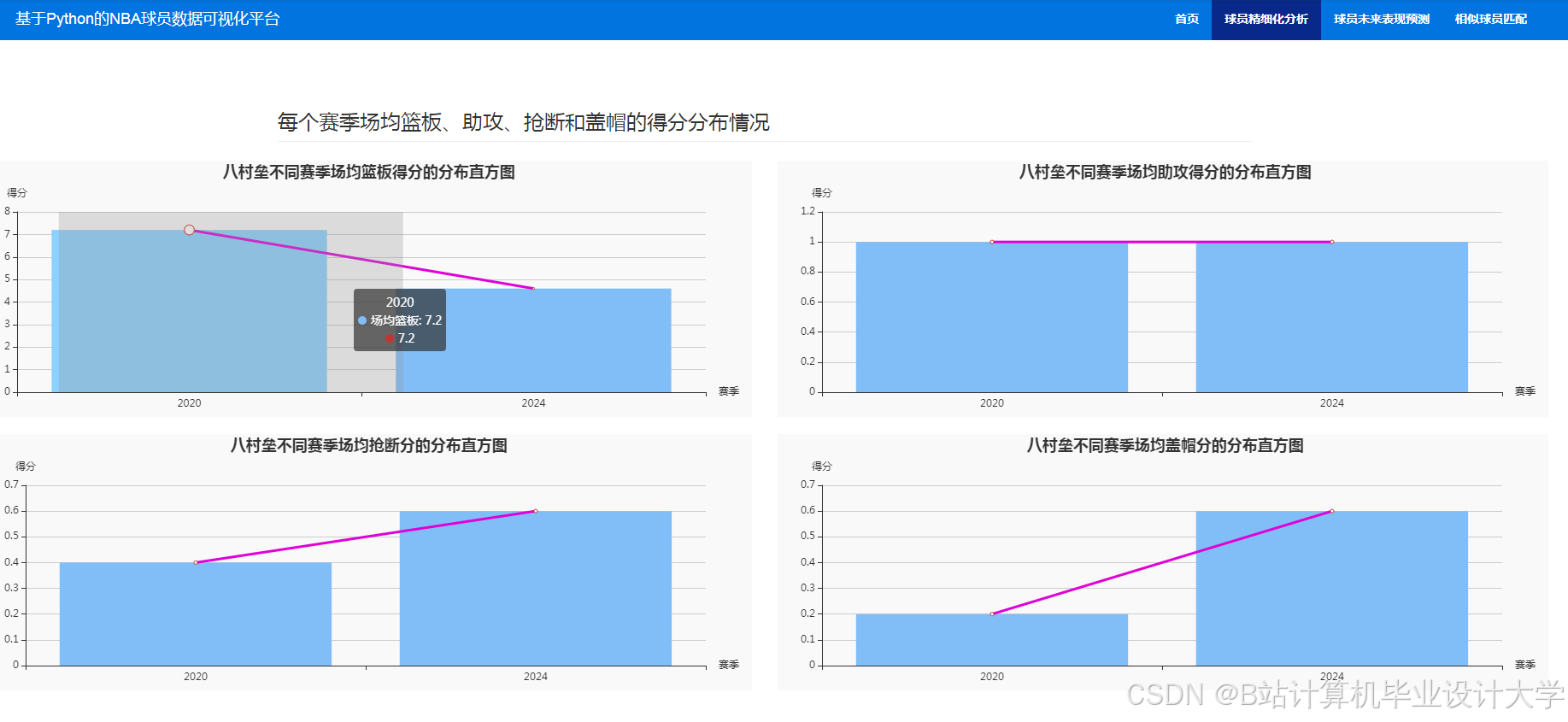
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











