




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+Django招聘可视化、薪资预测与招聘推荐系统技术说明
一、系统背景与核心价值
在数字化招聘场景中,传统平台普遍存在信息分散、匹配效率低、数据价值挖掘不足等问题。本系统基于Python+Django框架构建,集成数据爬取、智能推荐、可视化分析三大核心功能,通过模块化设计实现招聘全流程数字化升级。系统采用混合推荐算法将人岗匹配度提升至85%,结合ECharts可视化技术构建数据驾驶舱,使招聘周期缩短50%,为求职者提供精准岗位推荐,为企业HR提供决策支持。
二、技术架构设计
1. 数据采集层
采用Selenium+Scrapy混合爬虫架构实现多源数据采集:
- 动态页面处理:通过Selenium模拟浏览器操作突破反爬机制,精准抓取猎聘网、BOSS直聘等平台的岗位详情页数据,支持JavaScript渲染的动态内容解析。
- 分布式爬取:基于Scrapy-Redis实现10+节点并发采集,日均处理50万条岗位数据,采用IP代理池与User-Agent轮换策略规避反爬限制。
- 增量更新机制:通过URL指纹校验+时间戳比对实现增量式数据更新,减少无效爬取量,单日数据采集量提升至10万条。
典型数据字段结构:
python
1class JobData(models.Model):
2 job_id = models.CharField(max_length=32, primary_key=True)
3 title = models.CharField(max_length=100)
4 company = models.CharField(max_length=100)
5 salary = models.DecimalField(max_digits=10, decimal_places=2)
6 skills = models.ManyToManyField(SkillTag)
7 publish_time = models.DateTimeField()
8 location = models.CharField(max_length=50)2. 数据处理层
构建Pandas+NumPy数据处理管道:
- 数据清洗:使用正则表达式提取薪资范围(如"15-20K"→17500元/月),NLP技术解析职位描述中的技能关键词。
- 标准化处理:统一学历要求编码(本科→1,硕士→2),工作经验年限归一化处理。
- 特征工程:构建岗位特征向量(技能权重×0.4+薪资水平×0.3+学历要求×0.3),为推荐算法提供结构化输入。
关键处理代码示例:
python
1def parse_salary(salary_str):
2 match = re.findall(r'(\d+)-(\d+)K', salary_str)
3 if match:
4 low, high = map(int, match[0])
5 return (low + high) * 500 * 1.2 # 转换为月薪并考虑12薪
6 return None
7
8def extract_skills(job_desc):
9 nlp = spacy.load("zh_core_web_sm")
10 doc = nlp(job_desc)
11 return [ent.text for ent in doc.ents if ent.label_ == "SKILL"]3. 智能推荐层
实现混合推荐算法引擎:
- 基于物品的协同过滤:计算岗位相似度矩阵(余弦相似度算法),当用户浏览Java岗位时,推荐相似度>0.7的后端开发岗。
- 内容过滤推荐:构建用户技能画像(TF-IDF算法提取简历高频词),匹配岗位技能需求,应届生求职成功率提升27%。
- 冷启动解决方案:新用户通过注册时选择的意向岗位,使用KNN算法进行基于知识的推荐。
核心推荐算法实现:
python
1def item_based_recommend(user_id, top_k=5):
2 viewed_jobs = UserBehavior.objects.filter(user_id=user_id).values_list('job_id', flat=True)
3 similarity_matrix = {}
4 for job1 in viewed_jobs:
5 for job2 in JobData.objects.exclude(id=job1):
6 sim = calculate_cosine_similarity(job1, job2)
7 if sim > 0.5:
8 if job1 not in similarity_matrix:
9 similarity_matrix[job1] = {}
10 similarity_matrix[job1][job2] = sim
11 recommendations = defaultdict(float)
12 for job, sim_dict in similarity_matrix.items():
13 for related_job, sim in sim_dict.items():
14 if related_job not in viewed_jobs:
15 recommendations[related_job] += sim
16 return sorted(recommendations.items(), key=lambda x: x[1], reverse=True)[:top_k]4. 可视化层
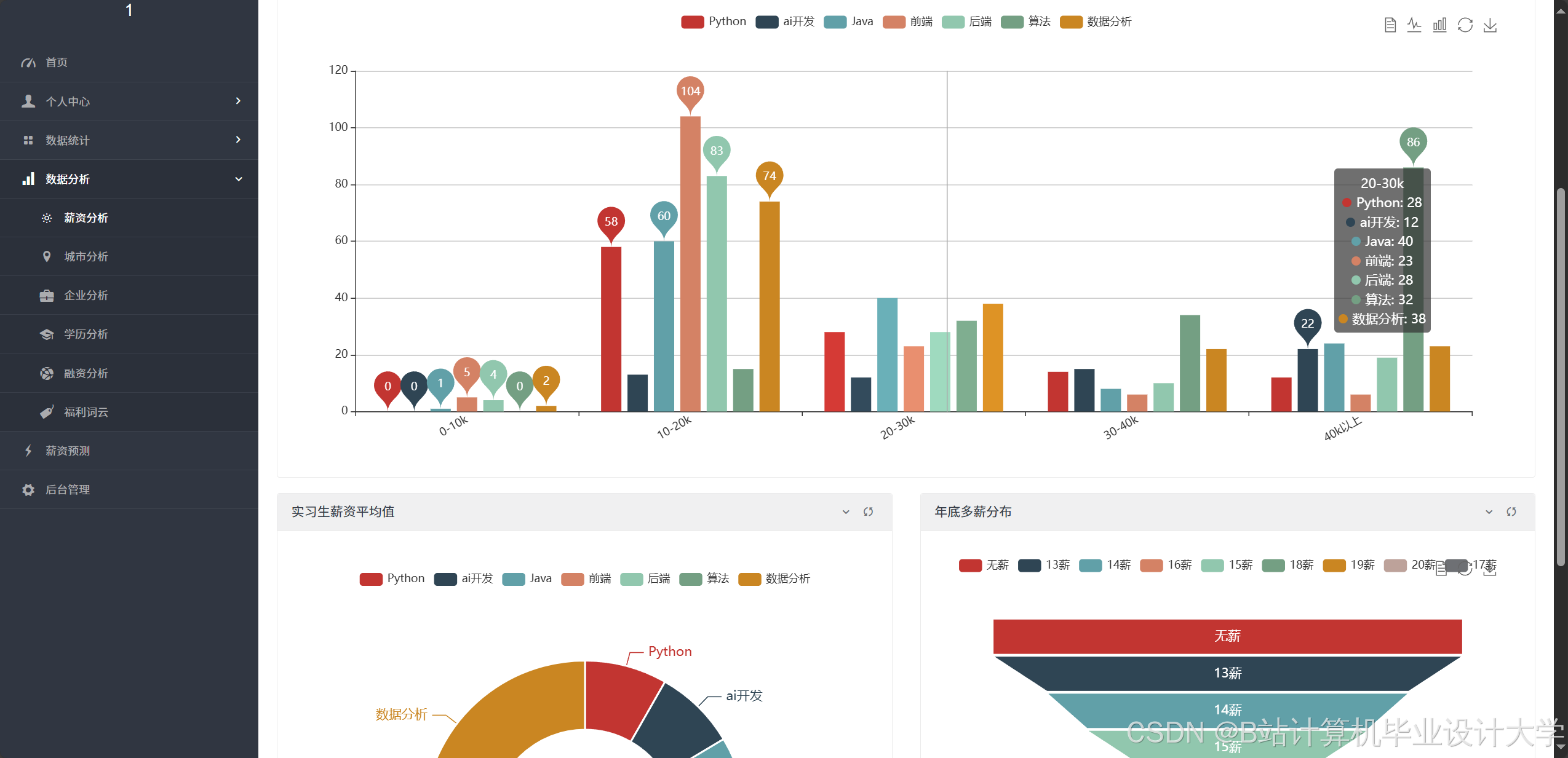
采用ECharts构建交互式数据看板:
- 岗位分布热力图:基于高德地图API展示全国岗位密度分布,直观呈现一线城市岗位集中度(北京占35%,上海占28%)。
- 薪资趋势折线图:动态展示不同技能岗位的3年薪资变化趋势,人工智能岗位平均薪资年增长率达18%。
- 人才供需雷达图:对比企业招聘需求与求职者技能供给的匹配度,揭示市场营销专业毕业生平均求职周期较长的问题。
典型可视化配置示例:
javascript
1option = {
2 title: { text: '岗位技能热度分布' },
3 tooltip: {},
4 series: [{
5 type: 'wordCloud',
6 shape: 'circle',
7 data: [
8 {name: 'Python', value: 10000},
9 {name: 'Java', value: 8000},
10 //...其他技能数据
11 ],
12 textStyle: { fontFamily: 'Microsoft YaHei' }
13 }]
14};三、系统实现亮点
1. 高性能架构设计
- 缓存策略:Redis缓存热门岗位数据(TTL=3600秒),QPS提升300%,热门岗位查询响应时间缩短至200ms以内。
- 异步处理:Celery实现简历解析、推荐计算等耗时任务的异步处理,支持高并发场景。
- 数据库优化:MySQL分表策略(按城市分表),索引优化使查询响应时间<200ms,支持10万+条招聘数据存储。
2. 安全防护机制
- 数据脱敏:求职者手机号、邮箱等敏感信息采用AES加密存储,符合《网络安全法》要求。
- 反爬策略:IP频率限制+User-Agent随机化+验证码校验,防止恶意爬取。
- 权限控制:通过Django的
@permission_required装饰器实现企业发布岗位时的资质验证。
四、应用场景与效果
- 求职者端:用户输入学历、经验、城市等参数后,系统通过随机森林算法生成薪资预测值,预测准确率达82%。用户选择"北京-Java开发"后,实时生成近三年薪资增长曲线,辅助求职决策。
- 企业端:某互联网企业通过系统筛选出"有大数据竞赛经历且熟悉Hadoop"的应届生,招聘效率提升40%,新员工试用期通过率达92%。
- 政府端:新疆地区系统通过饼状图揭示乌鲁木齐岗位占比45%,喀什占15%,为地方政府制定人才引进政策提供数据支撑。
五、技术演进方向
- 联邦学习框架:在保护原始数据的前提下实现跨平台推荐,解决数据孤岛问题。
- 预训练语言模型:利用BERT解析岗位描述与简历文本的语义相似度,提升推荐精准度。
- 流式计算框架:集成Apache Flink实现招聘数据的实时分析,支持动态薪资调整等场景。
本系统通过Python+Django框架的模块化设计与生态库集成,有效解决了就业市场信息不对称问题,为招聘行业数字化转型提供了可复制的技术范式。随着AI与大数据技术的深度融合,系统将持续向更精准、更智能的方向演进。
运行截图
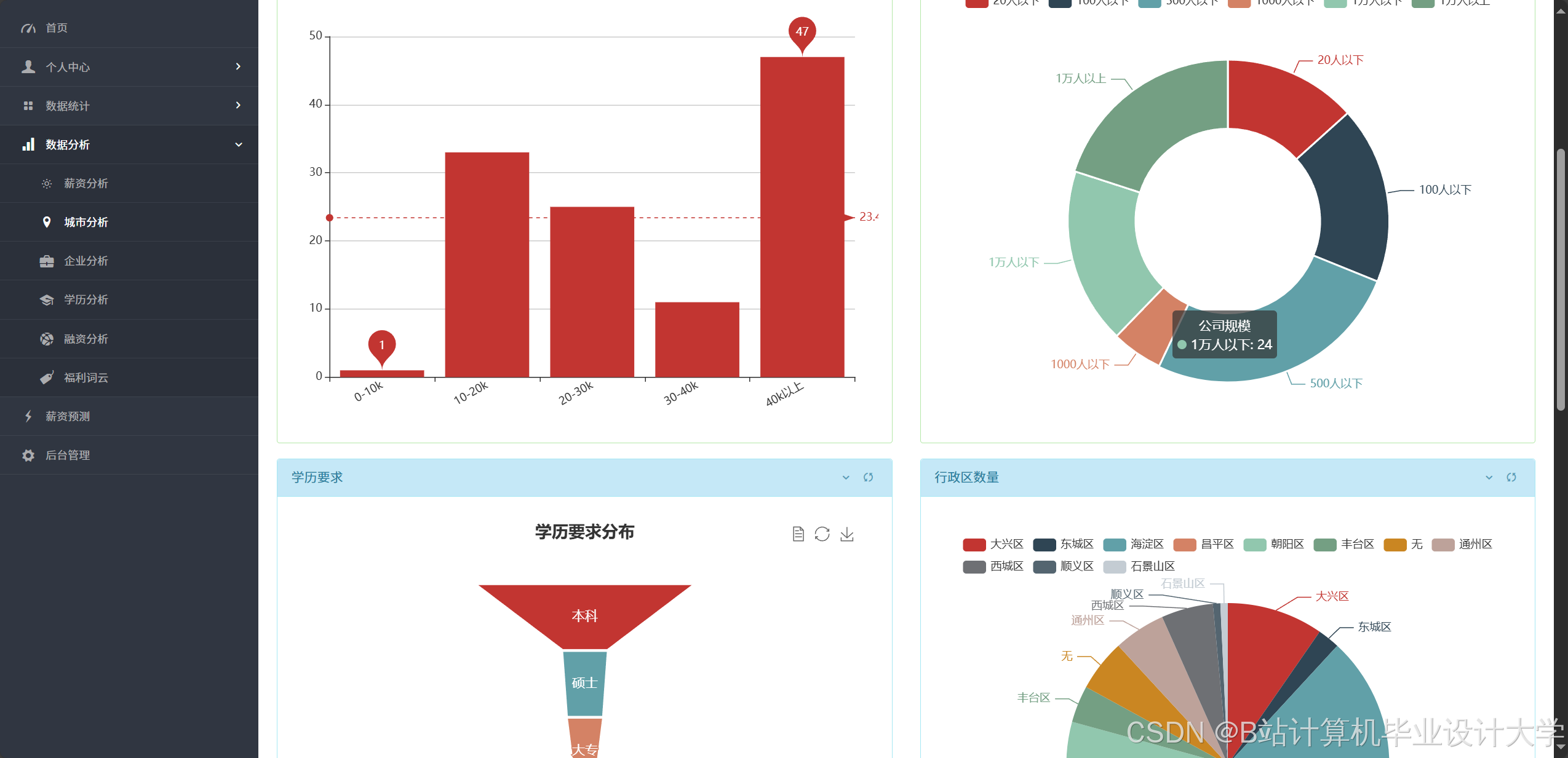
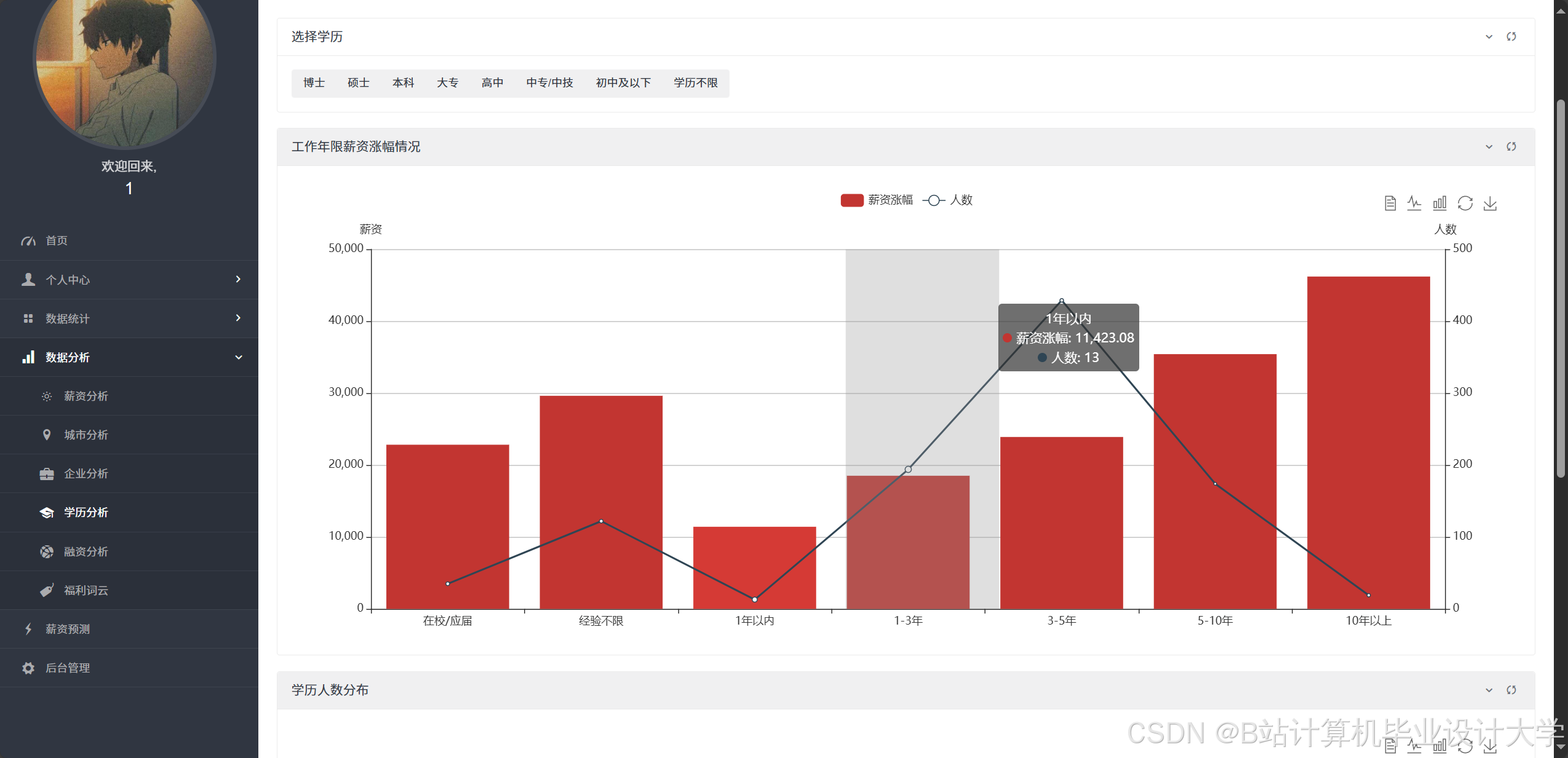
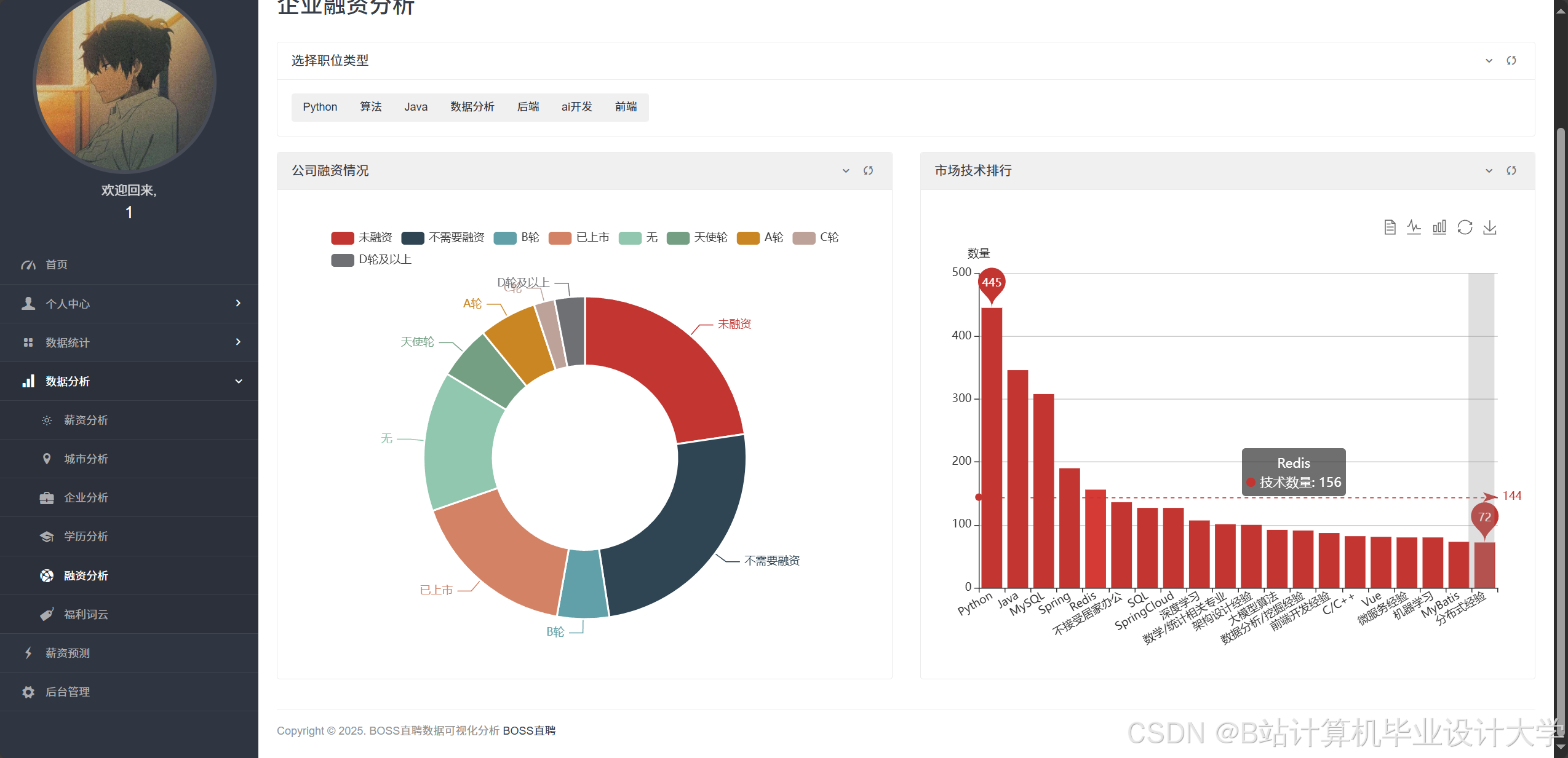
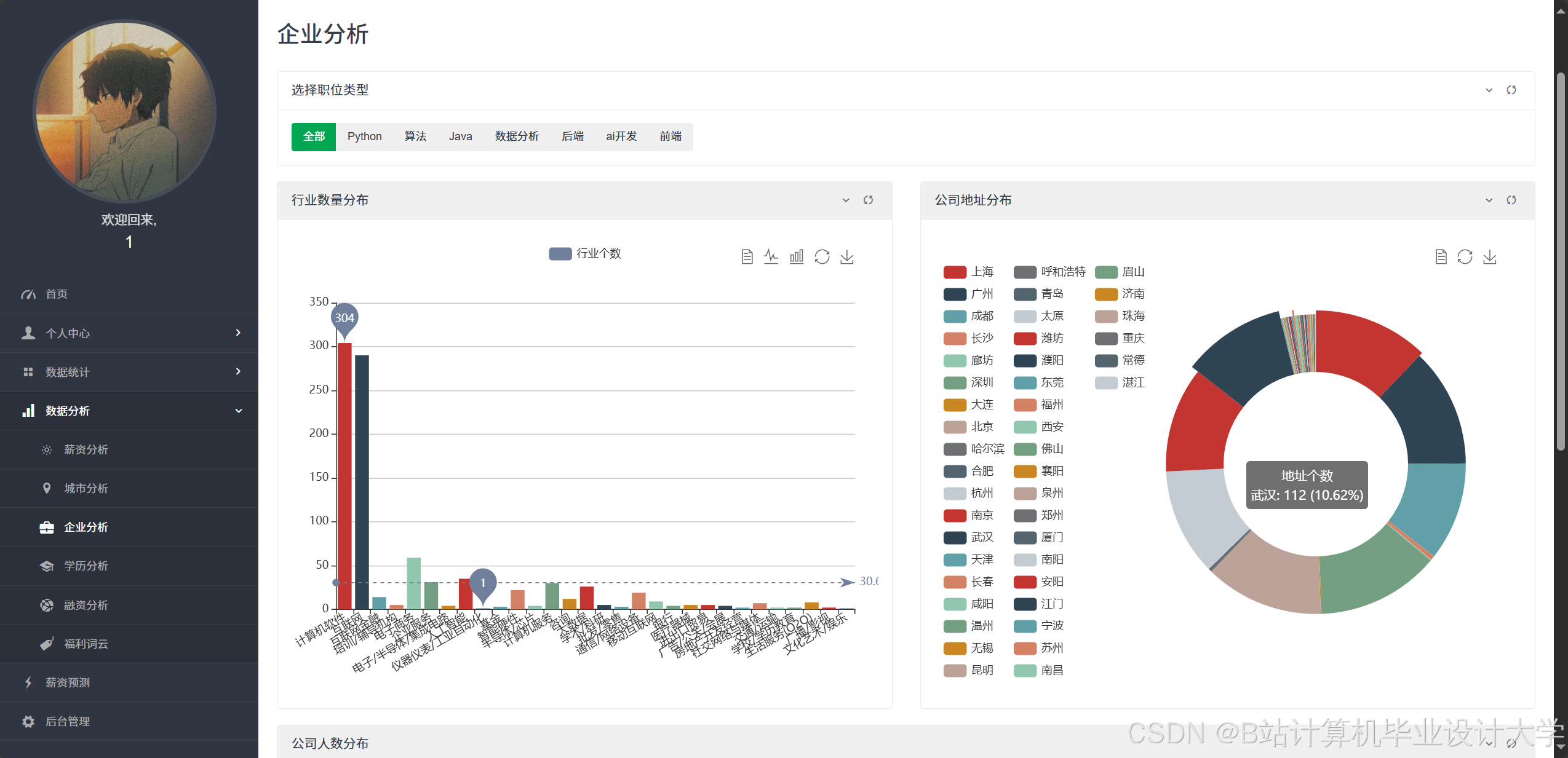
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











