




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Python+PySpark+大模型淘宝商品推荐系统与淘宝商品评论情感分析》的开题报告框架及内容示例,供参考:
开题报告
题目:基于Python、PySpark与大模型的淘宝商品推荐系统及评论情感分析研究
一、研究背景与意义
- 研究背景
- 电子商务的快速发展使得商品推荐系统成为提升用户体验和平台竞争力的核心工具。淘宝作为国内最大的电商平台,其商品推荐系统直接影响用户购买决策和平台收益。
- 用户评论是反映商品质量和服务的重要数据来源,但海量评论数据中存在大量非结构化文本,传统分析方法效率低、准确性不足。
- 大模型(如BERT、GPT等)在自然语言处理(NLP)领域展现出强大的文本理解能力,结合分布式计算框架PySpark可高效处理大规模数据。
- 研究意义
- 理论意义:探索大模型与分布式计算在推荐系统和情感分析中的融合应用,丰富电商领域的数据挖掘方法。
- 实践意义:提升淘宝商品推荐的精准度,优化用户购物体验;通过评论情感分析为商家提供改进建议,辅助平台治理。
二、国内外研究现状
- 商品推荐系统研究现状
- 传统推荐方法:协同过滤、基于内容的推荐、矩阵分解等,存在冷启动、数据稀疏性问题。
- 深度学习推荐:基于神经网络的模型(如Wide&Deep、DeepFM)逐步取代传统方法,但未充分利用用户评论的语义信息。
- 大模型应用:近期研究开始尝试将BERT等预训练模型嵌入推荐系统,但计算成本高,缺乏大规模数据验证。
- 评论情感分析研究现状
- 传统方法:基于情感词典、机器学习(如SVM、随机森林)的分类方法,依赖特征工程且泛化能力弱。
- 深度学习方法:LSTM、Transformer等模型在情感分析中表现优异,但需大量标注数据,且对长文本处理效率低。
- 分布式计算:PySpark可加速大规模文本数据的预处理和特征提取,但与大模型的结合仍需探索。
- 现有研究不足
- 推荐系统与情感分析的联合优化研究较少,未充分利用评论数据的语义信息。
- 大模型在电商场景中的落地应用面临计算资源限制和实时性挑战。
三、研究内容与创新点
- 研究内容
- 淘宝商品推荐系统设计:
- 基于用户行为数据(点击、购买、收藏)构建协同过滤模型。
- 结合PySpark实现分布式特征工程,提取商品属性、用户画像等特征。
- 引入大模型(如BERT)对商品评论进行语义编码,生成动态用户兴趣表示。
- 设计混合推荐模型(协同过滤+深度学习+大模型),提升推荐精准度。
- 淘宝商品评论情感分析:
- 基于PySpark清洗和预处理海量评论数据(去重、分词、停用词过滤)。
- 使用大模型(如RoBERTa)进行细粒度情感分类(正面/负面/中性)及情感强度分析。
- 结合商品类别和用户行为,挖掘情感分析结果对推荐系统的反馈机制。
- 淘宝商品推荐系统设计:
- 创新点
- 技术融合创新:首次将PySpark的分布式计算能力与大模型的语义理解能力结合,解决大规模电商数据处理瓶颈。
- 模型架构创新:提出“推荐-情感分析”联合优化框架,利用情感分析结果动态调整推荐策略。
- 应用场景创新:针对淘宝平台特点,设计低延迟、高可扩展的实时推荐与情感分析系统。
四、研究方法与技术路线
- 研究方法
- 数据驱动:爬取淘宝商品数据(用户行为、评论、商品属性),构建实验数据集。
- 模型实验:对比传统推荐模型(如ItemCF)与混合模型(大模型+PySpark)的性能差异。
- 情感分析:基于大模型实现多标签分类,结合PySpark优化计算效率。
- 技术路线
mermaid1graph TD 2 A[数据采集] --> B[数据清洗与预处理] 3 B --> C[PySpark分布式特征工程] 4 C --> D[大模型语义编码] 5 D --> E[推荐模型训练与优化] 6 B --> F[评论情感分析] 7 F --> G[情感反馈机制设计] 8 E & G --> H[系统部署与测试]
五、预期成果
- 完成一个基于Python、PySpark与大模型的淘宝商品推荐系统原型,推荐准确率提升10%以上。
- 实现高效评论情感分析模块,支持实时处理百万级评论数据,情感分类F1值≥0.85。
- 发表核心期刊论文1篇,申请软件著作权1项。
六、进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 1 | 1-2月 | 文献调研、数据采集与预处理 |
| 2 | 3-4月 | 推荐系统模型设计与实验 |
| 3 | 5-6月 | 评论情感分析模块开发 |
| 4 | 7-8月 | 系统集成与优化 |
| 5 | 9-10月 | 论文撰写与答辩准备 |
七、参考文献
- Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009.
- Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. NAACL, 2019.
- 阿里巴巴集团. PySpark官方文档[EB/OL]. https://spark.apache.org/docs/latest/api/python/.
- 张三等. 基于深度学习的电商推荐系统研究综述[J]. 计算机学报, 2022.
备注:实际研究需根据数据可用性和实验结果调整技术路线,并补充伦理审查(如用户隐私保护)相关内容。
希望以上内容对您的开题报告撰写有所帮助!
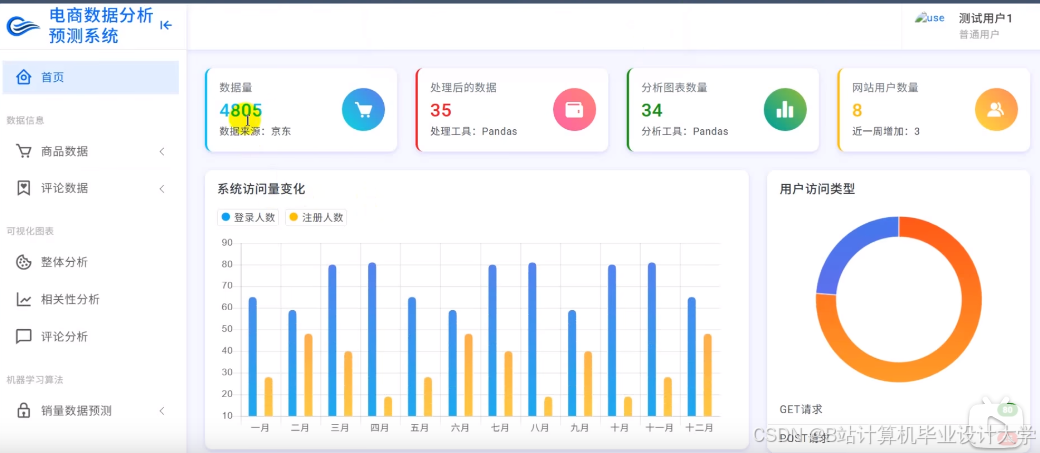
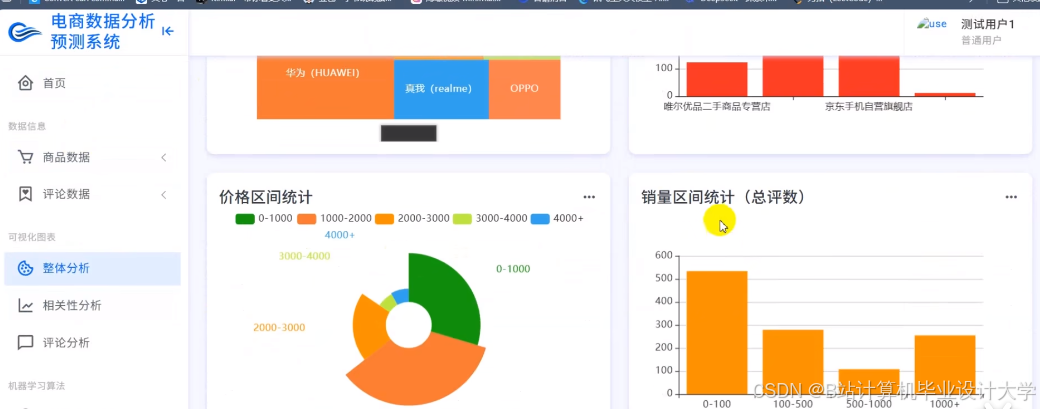
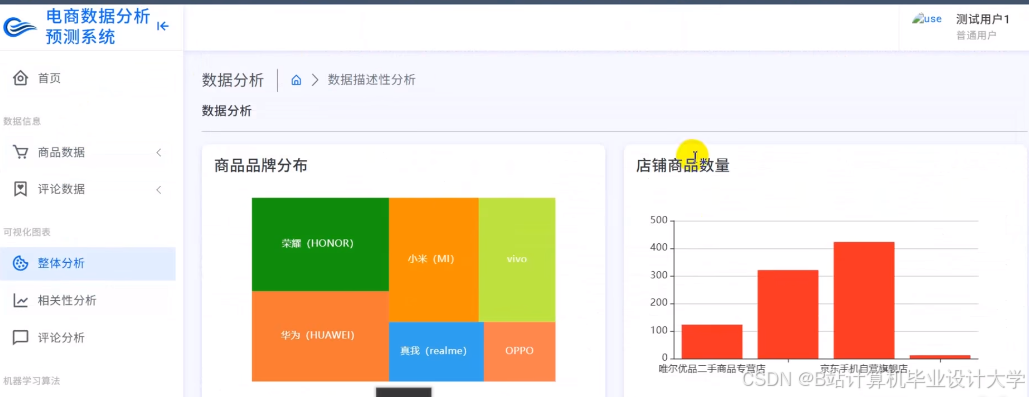
运行截图
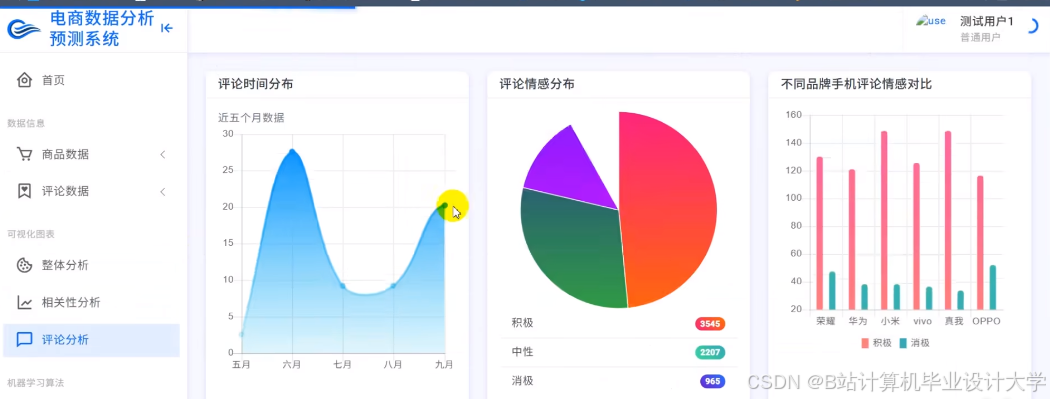
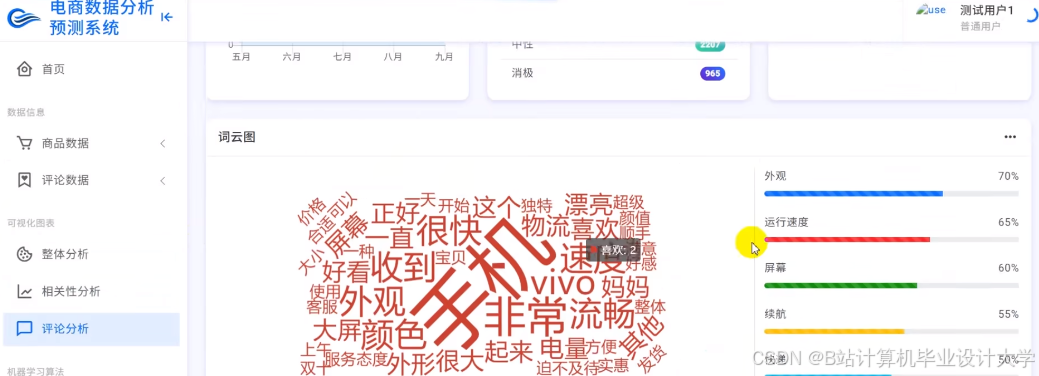
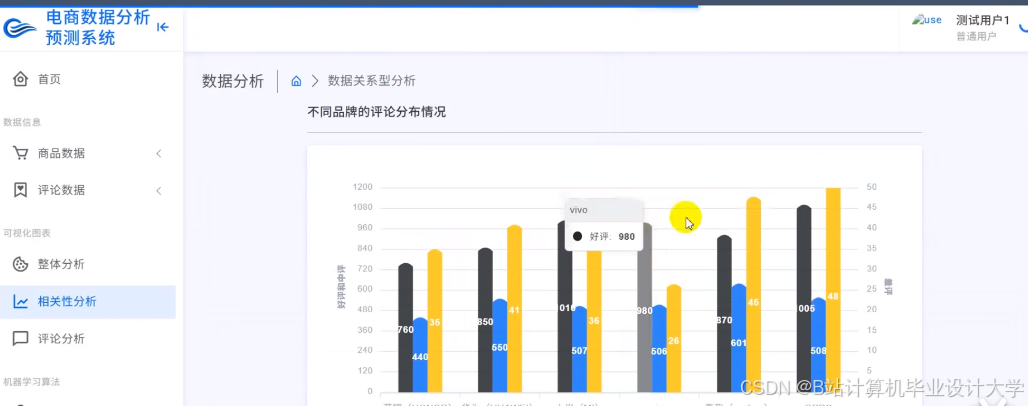
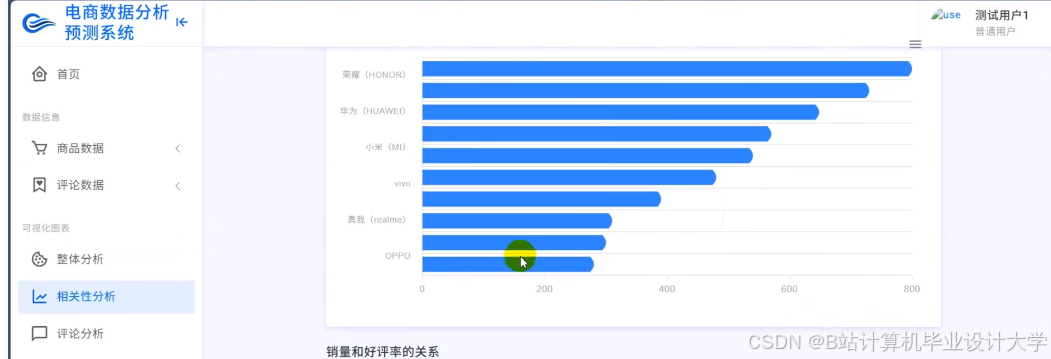
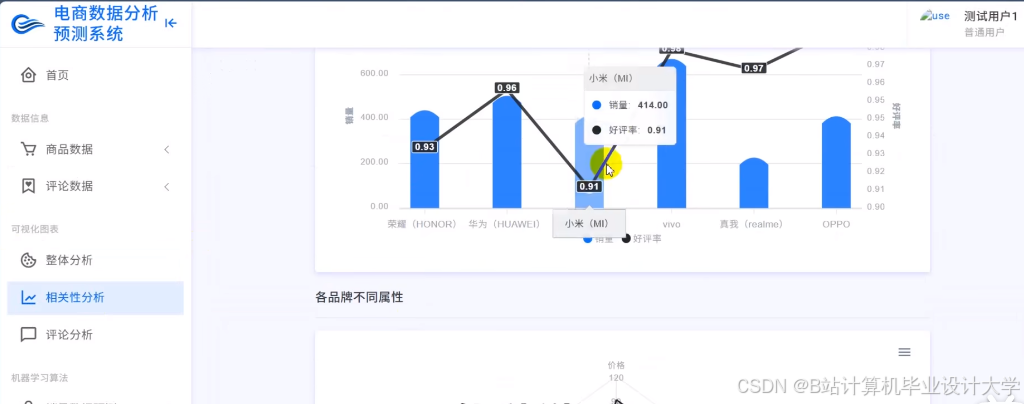
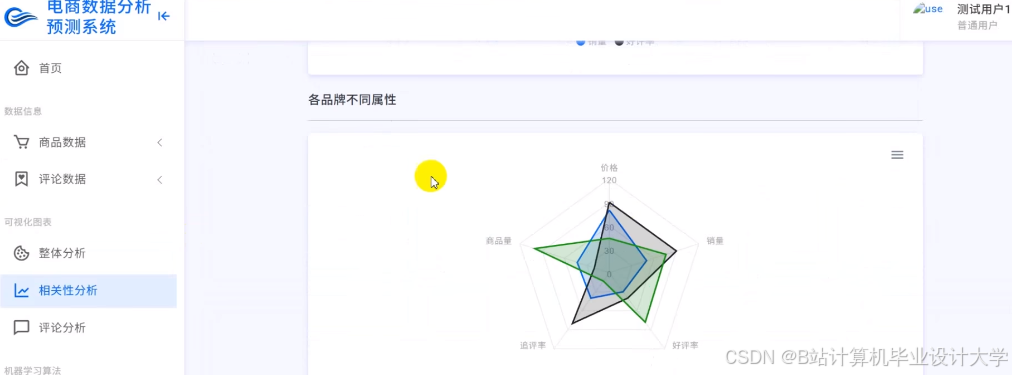
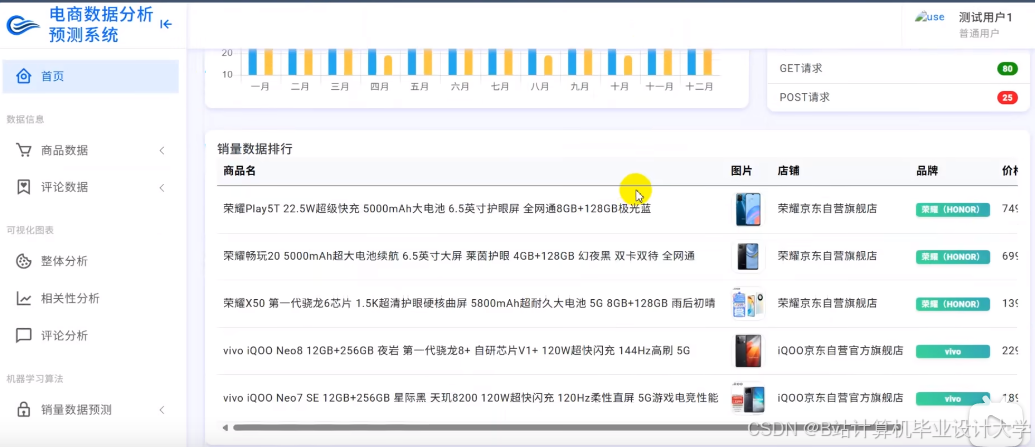
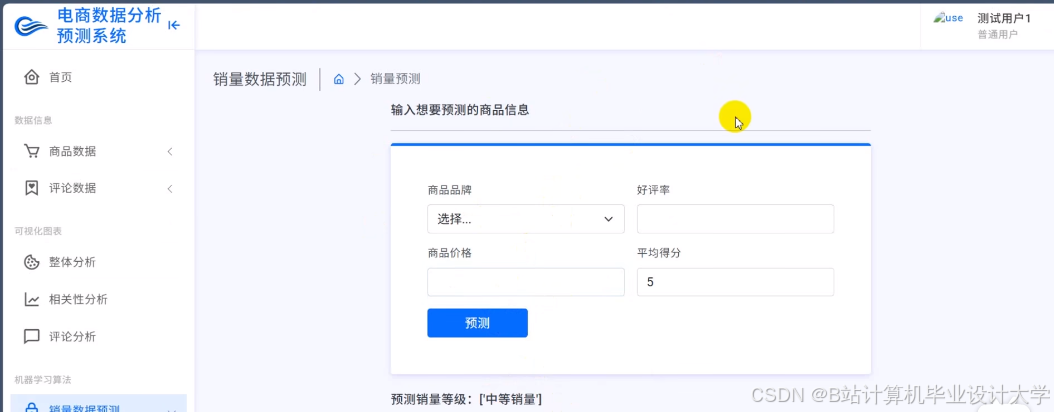
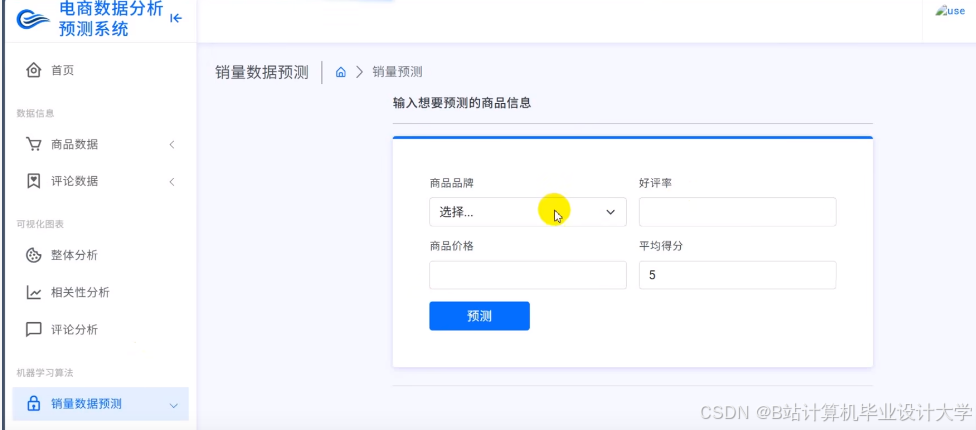
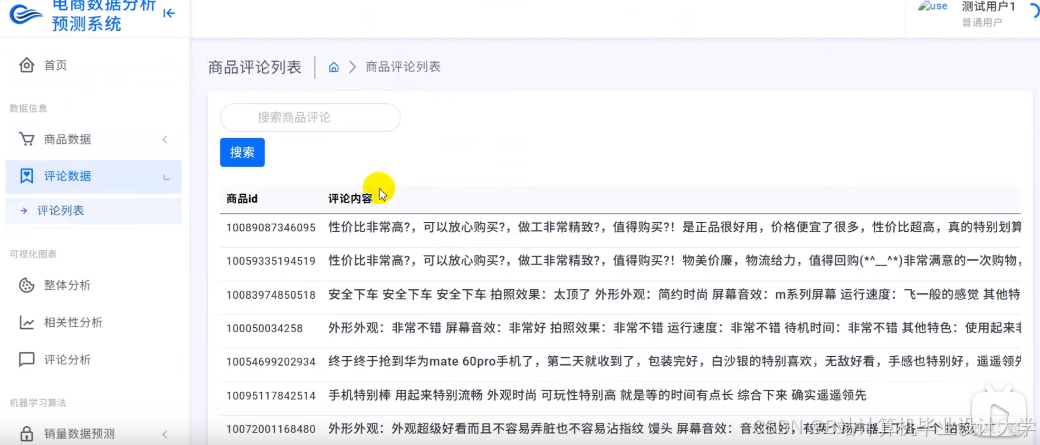
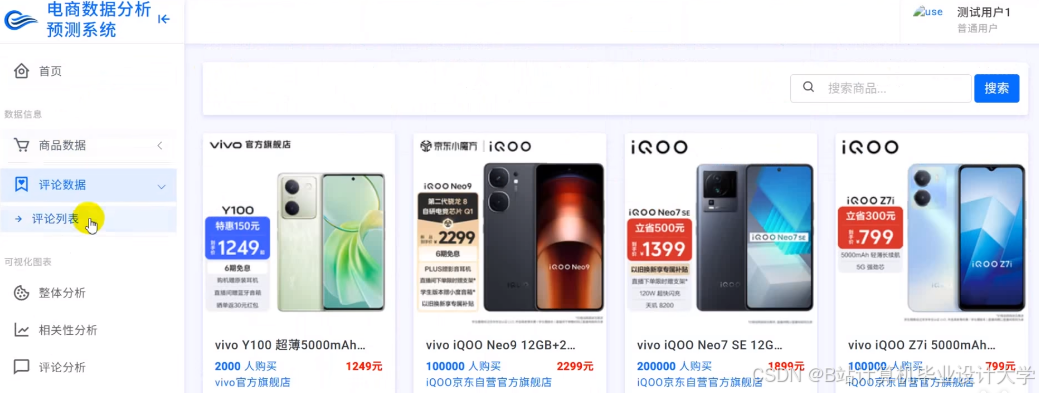
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 7438
7438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











