




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python商品推荐系统与商品比价系统》的技术说明文档,涵盖系统架构、核心算法与实现逻辑:
Python商品推荐系统与商品比价系统技术说明
一、系统概述
本系统基于Python构建,整合商品推荐与比价功能,通过数据挖掘和机器学习技术实现个性化推荐,同时结合网络爬虫与价格监控实现实时比价。系统分为两大模块:
- 推荐模块:基于用户行为、商品特征和协同过滤算法生成推荐列表。
- 比价模块:通过爬取多平台商品数据,进行价格对比与趋势分析。
二、推荐系统设计
1. 数据准备
- 数据来源:用户历史行为数据(点击、购买、评分)、商品属性数据(类别、价格、品牌)、上下文数据(时间、地理位置)。
- 数据预处理:
- 数据清洗:处理缺失值、异常值(如价格为负)。
- 特征工程:对类别型特征(如品牌)进行One-Hot编码,数值型特征(如价格)归一化。
- 用户画像构建:基于行为数据生成用户兴趣标签(如“电子产品爱好者”)。
2. 推荐算法实现
(1)基于内容的推荐(Content-Based Filtering)
- 原理:根据用户历史偏好商品的特征,推荐相似商品。
- 实现步骤:
- 计算商品特征向量(TF-IDF或Word2Vec处理商品描述)。
- 计算用户兴趣向量(用户历史商品特征的加权平均)。
- 使用余弦相似度匹配商品与用户兴趣。
python1from sklearn.metrics.pairwise import cosine_similarity 2user_profile = np.mean([item_vec[i] for i in user_history], axis=0) 3similarities = cosine_similarity(user_profile.reshape(1, -1), all_item_vectors)
(2)协同过滤推荐(Collaborative Filtering)
- 用户协同过滤(User-CF):
- 计算用户相似度矩阵(皮尔逊相关系数)。
- 根据相似用户的行为推荐商品。
- 物品协同过滤(Item-CF):
- 计算商品相似度矩阵(基于共现次数)。
- 推荐与用户历史商品相似的商品。
python1# Item-CF示例 2from sklearn.metrics.pairwise import cosine_similarity 3item_sim = cosine_similarity(item_user_matrix.T) # 转置后计算商品相似度
(3)混合推荐模型
- 结合内容推荐与协同过滤的加权结果,提升推荐多样性。
- 使用逻辑回归或深度学习模型(如Wide & Deep)融合多源特征。
3. 实时推荐优化
- 增量学习:使用
surprise库或TensorFlow Recommenders实现模型在线更新。 - 缓存机制:Redis缓存热门推荐结果,减少计算延迟。
三、商品比价系统设计
1. 数据采集
- 爬虫框架:使用
Scrapy或Selenium抓取电商平台(京东、淘宝、亚马逊)的商品信息。 - 反爬策略:
- 动态IP代理池(如
scrapy-proxies)。 - 请求头随机化(User-Agent、Referer)。
- 延迟控制(
time.sleep(random.uniform(1,3)))。
- 动态IP代理池(如
2. 数据处理与存储
- 数据清洗:
- 统一价格单位(如将“¥199”转换为数值199)。
- 去除重复商品(基于标题+价格+店铺的哈希去重)。
- 存储方案:
- 结构化数据:MySQL存储商品元数据(ID、名称、价格、链接)。
- 非结构化数据:MongoDB存储商品详情页HTML(用于后续分析)。
3. 比价逻辑
- 价格对比:
- 实时抓取目标商品在各平台的价格,生成价格对比表格。
- 标记最低价商品并高亮显示。
- 价格趋势分析:
- 使用
Pandas计算价格线(MA)和波动率。 - 可视化:
Matplotlib绘制价格历史曲线。
python1import pandas as pd 2import matplotlib.pyplot as plt 3df['price'].plot(title='Price Trend', figsize=(10, 5)) 4plt.show() - 使用
4. 异常检测
- 价格突变预警:
- 基于Z-Score算法检测价格异常波动(如突降50%)。
python1from scipy import stats 2z_scores = stats.zscore(df['price']) 3anomalies = df[np.abs(z_scores) > 3] # 阈值设为3
四、系统集成与部署
1. 技术栈
- 后端:Flask/Django提供RESTful API。
- 前端:ECharts可视化推荐结果与比价图表。
- 部署:Docker容器化,Nginx负载均衡,AWS/阿里云托管。
2. 性能优化
- 异步任务:Celery处理爬虫任务与推荐计算。
- 数据库索引:为商品ID、价格字段添加索引加速查询。
- CDN加速:静态资源(如图片)通过CDN分发。
五、示例代码片段
推荐系统API(Flask)
python
1from flask import Flask, request, jsonify
2app = Flask(__name__)
3
4@app.route('/recommend', methods=['POST'])
5def recommend():
6 user_id = request.json['user_id']
7 # 调用推荐模型生成结果
8 recommendations = model.recommend(user_id, top_k=10)
9 return jsonify(recommendations)
10
11if __name__ == '__main__':
12 app.run(host='0.0.0.0', port=5000)比价爬虫(Scrapy)
python
1import scrapy
2class PriceSpider(scrapy.Spider):
3 name = 'price_spider'
4 start_urls = ['https://www.example.com/product/123']
5
6 def parse(self, response):
7 price = response.css('.price::text').get().replace('¥', '')
8 yield {
9 'product_id': '123',
10 'platform': 'Example',
11 'price': float(price),
12 'url': response.url
13 }六、总结与展望
本系统通过模块化设计实现了推荐与比价的核心功能,未来可扩展方向包括:
- 引入深度学习模型(如Transformer)提升推荐准确性。
- 增加用户反馈机制(如“不喜欢”按钮)优化推荐结果。
- 支持多语言与跨境比价(如亚马逊全球站点)。
通过持续迭代,系统可逐步演变为智能电商中台,为用户提供一站式购物决策支持。
文档说明:
- 实际开发中需结合具体业务需求调整算法参数与数据源。
- 需遵守目标网站的
robots.txt协议及数据使用条款。 - 高并发场景下建议使用消息队列(如Kafka)解耦爬虫与数据处理模块。
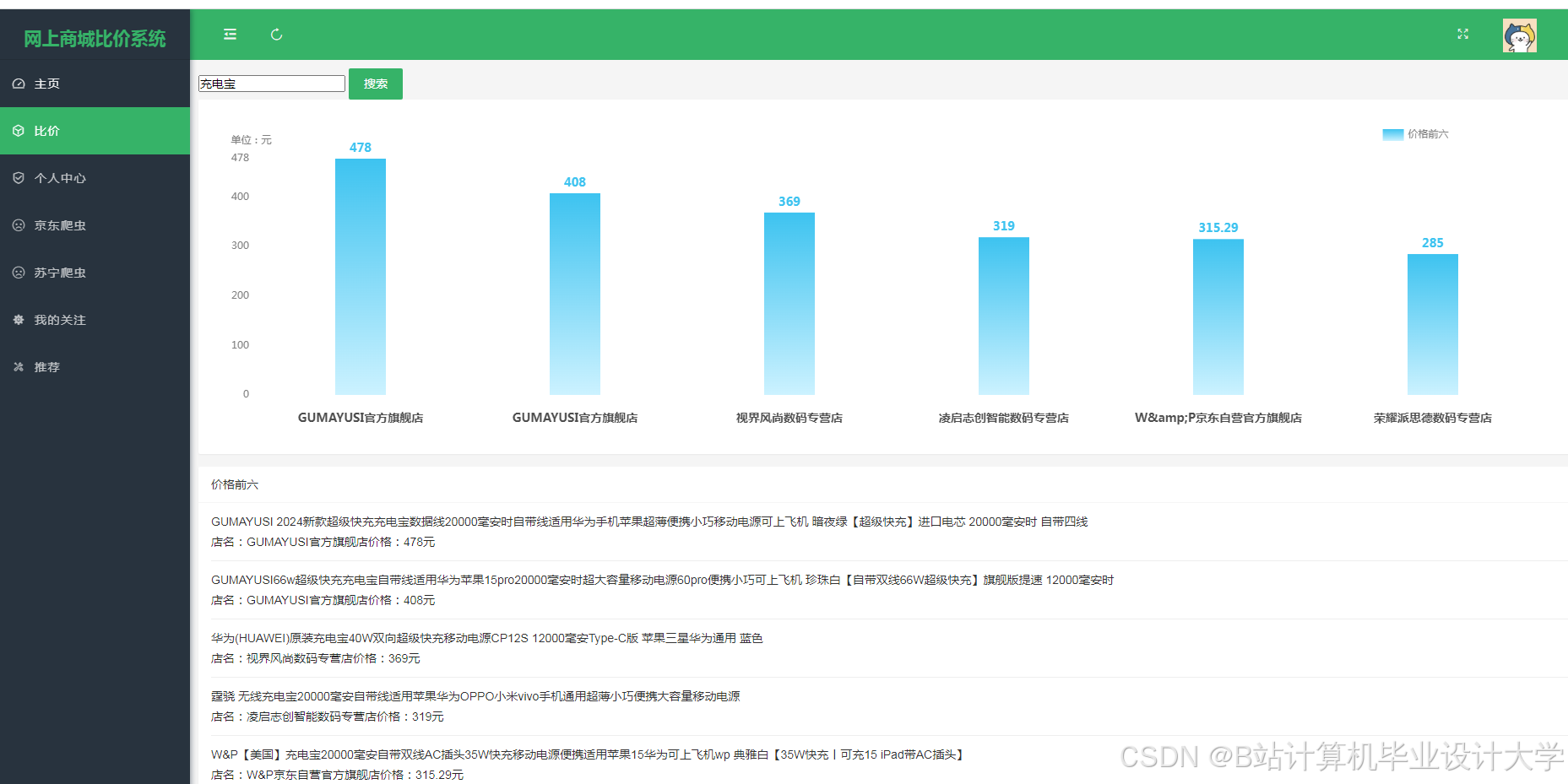
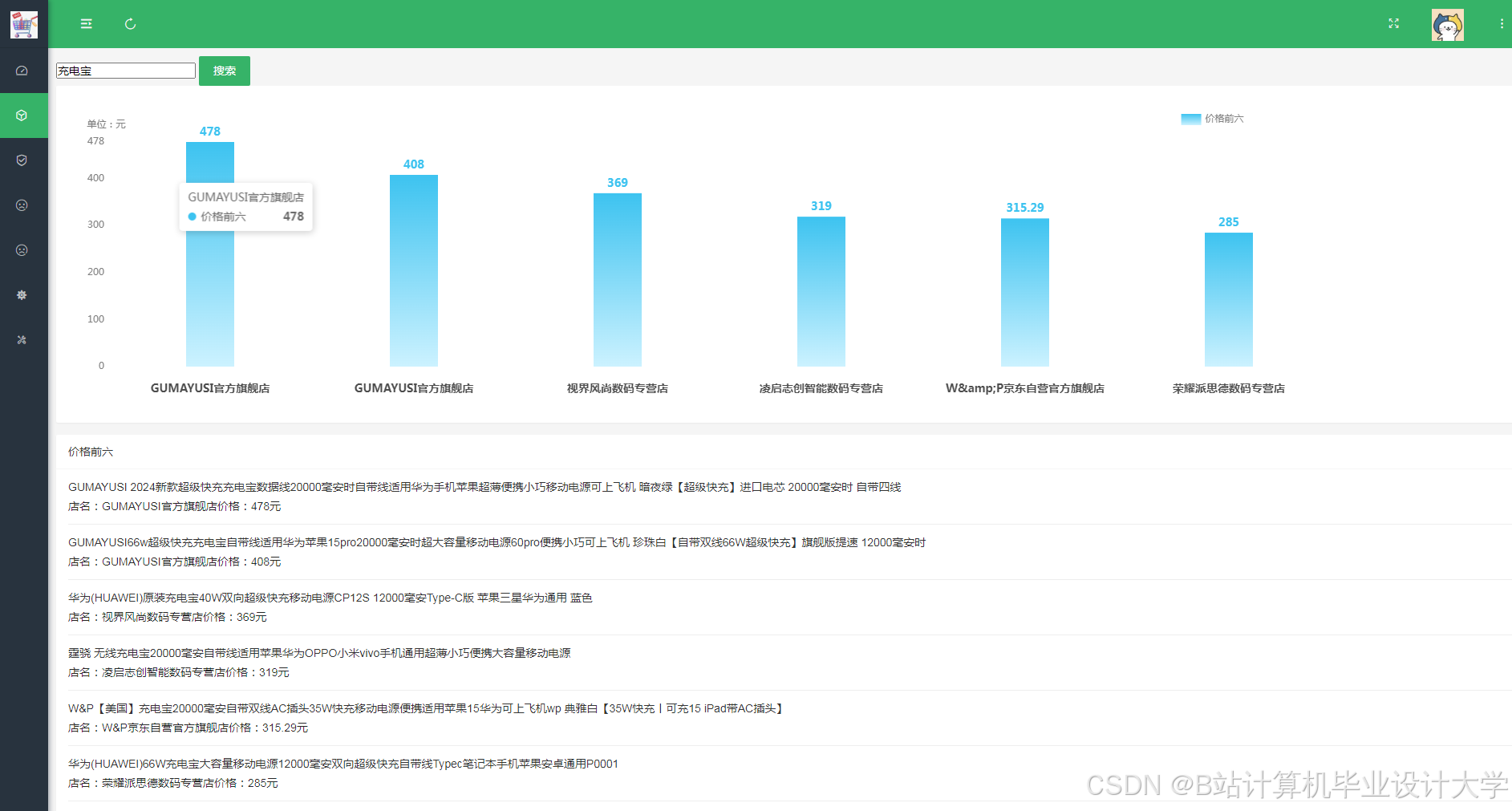
运行截图

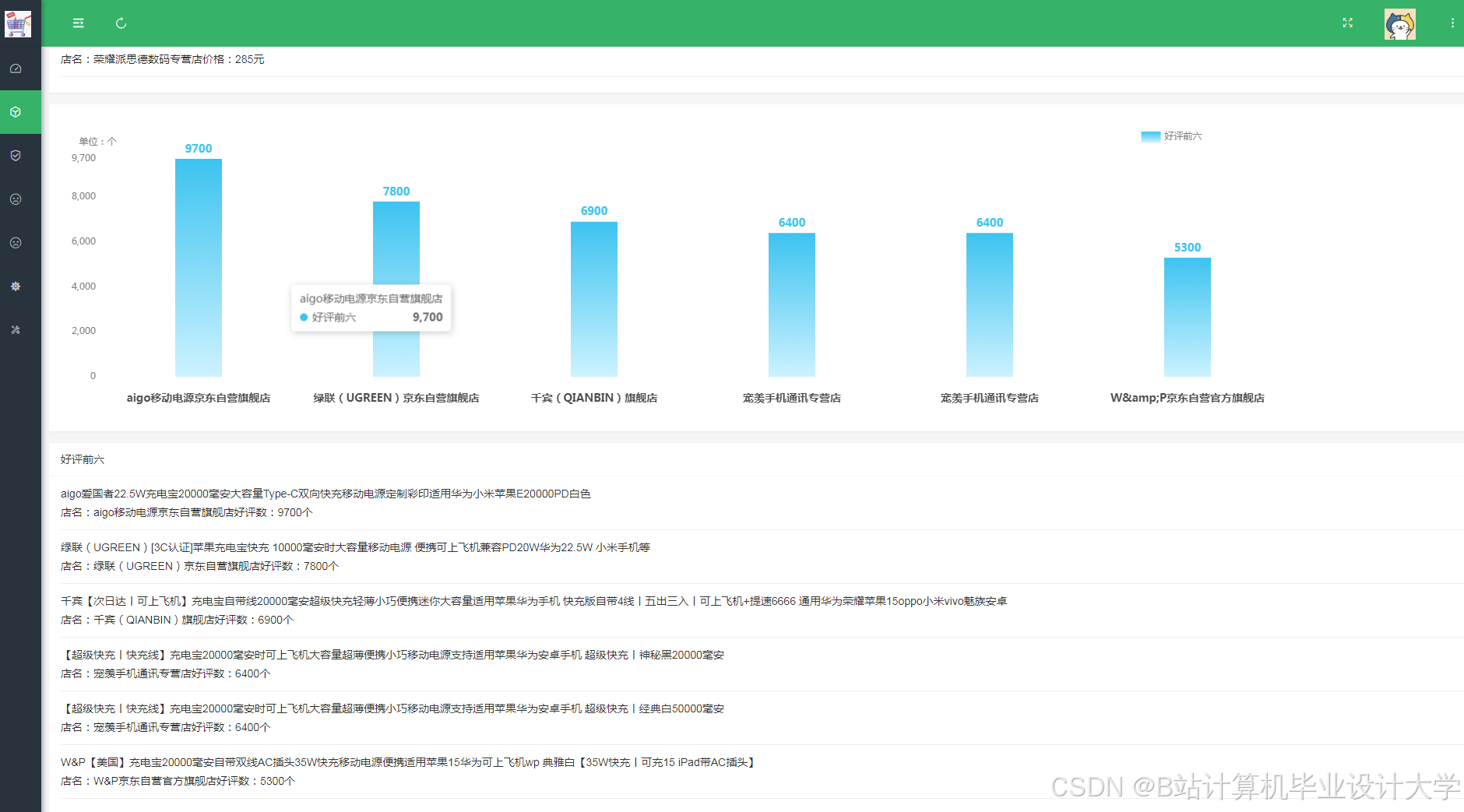
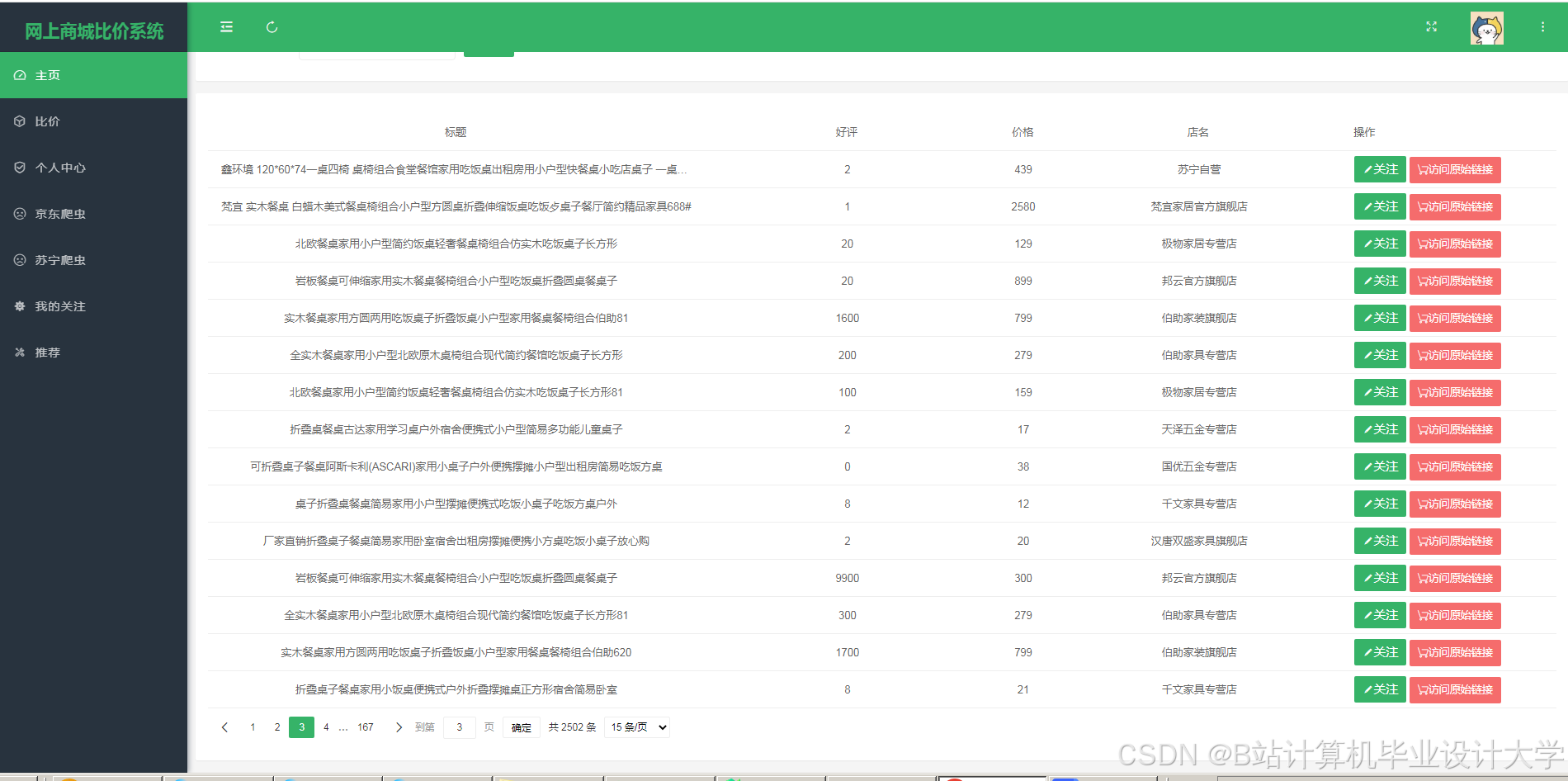
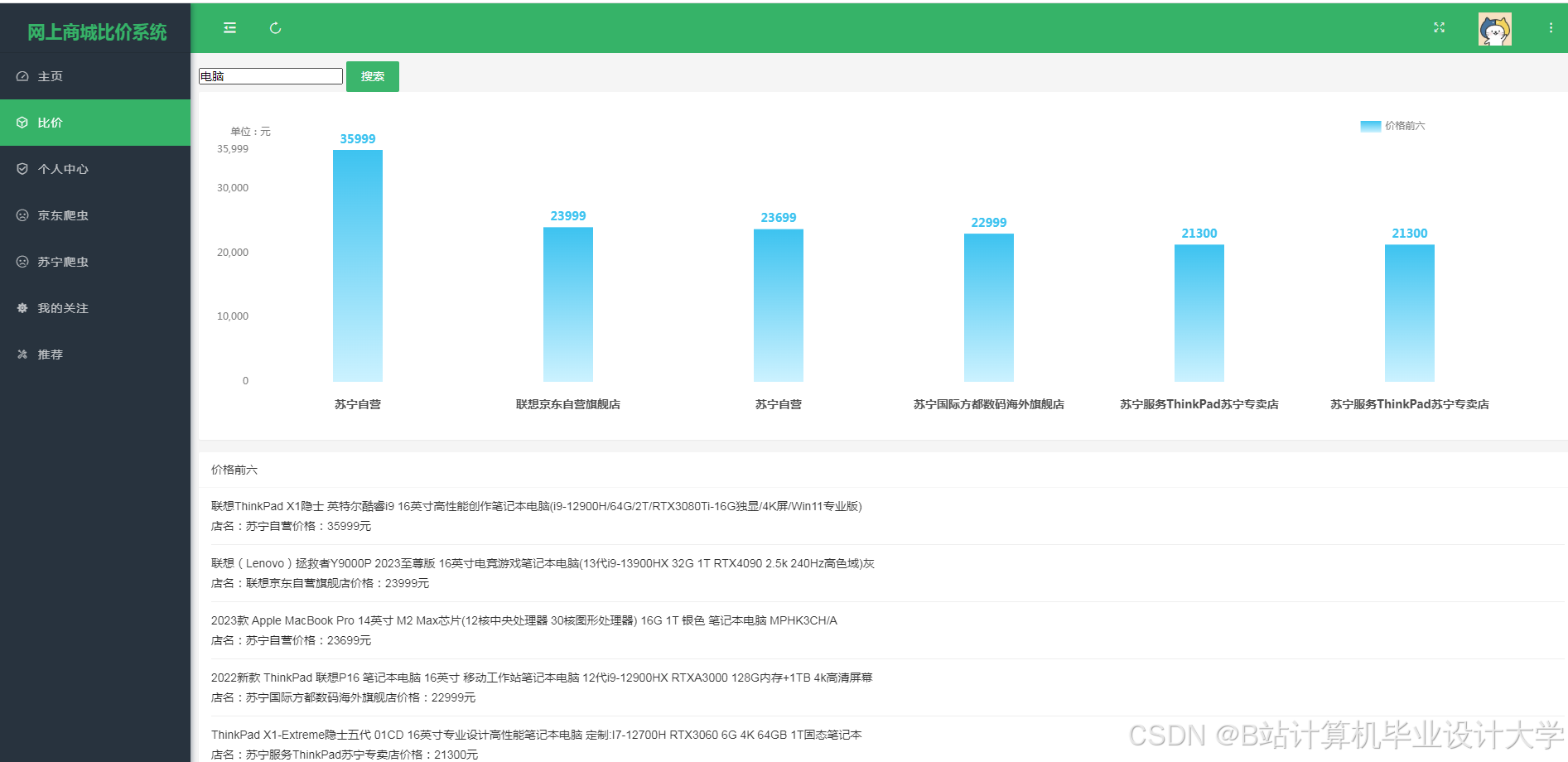
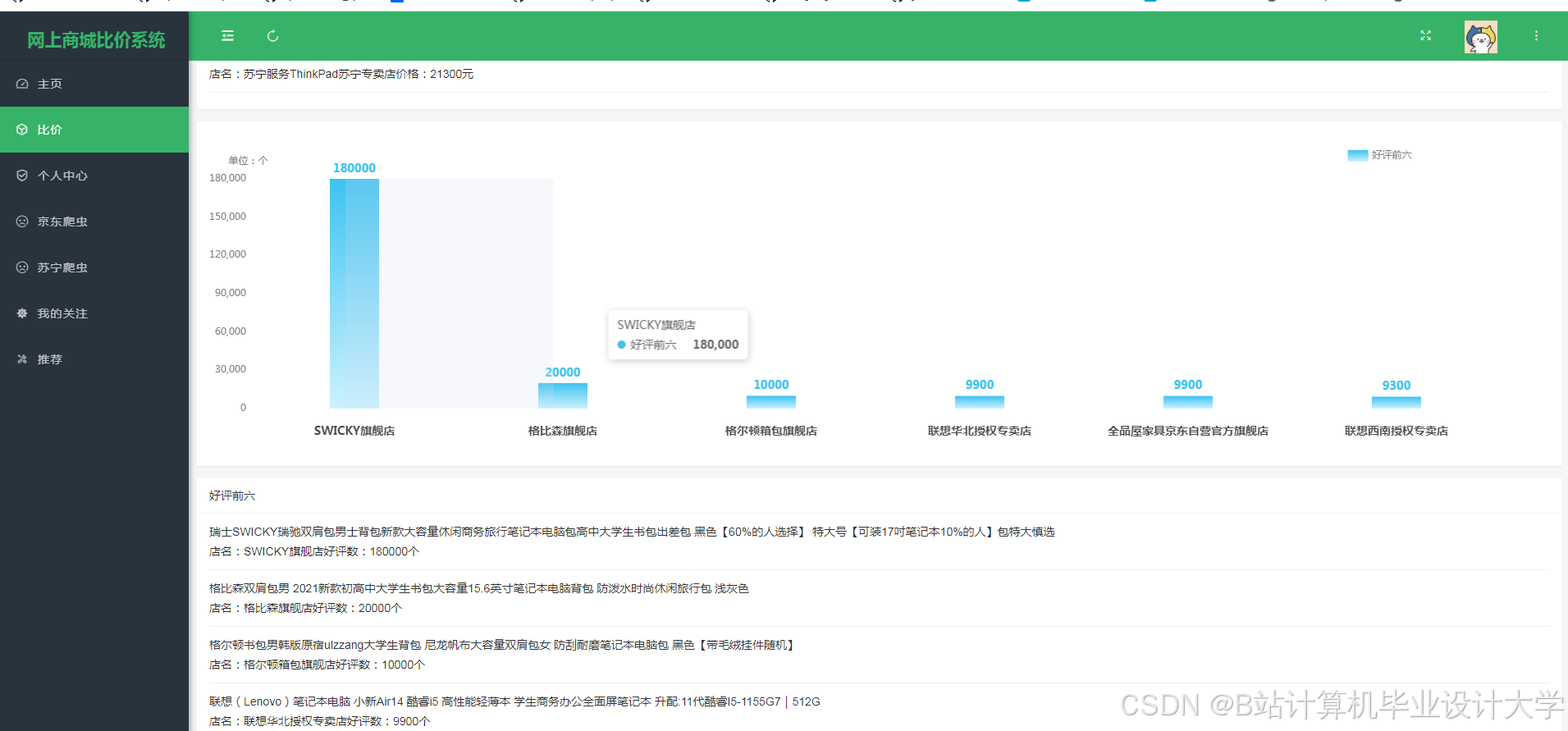
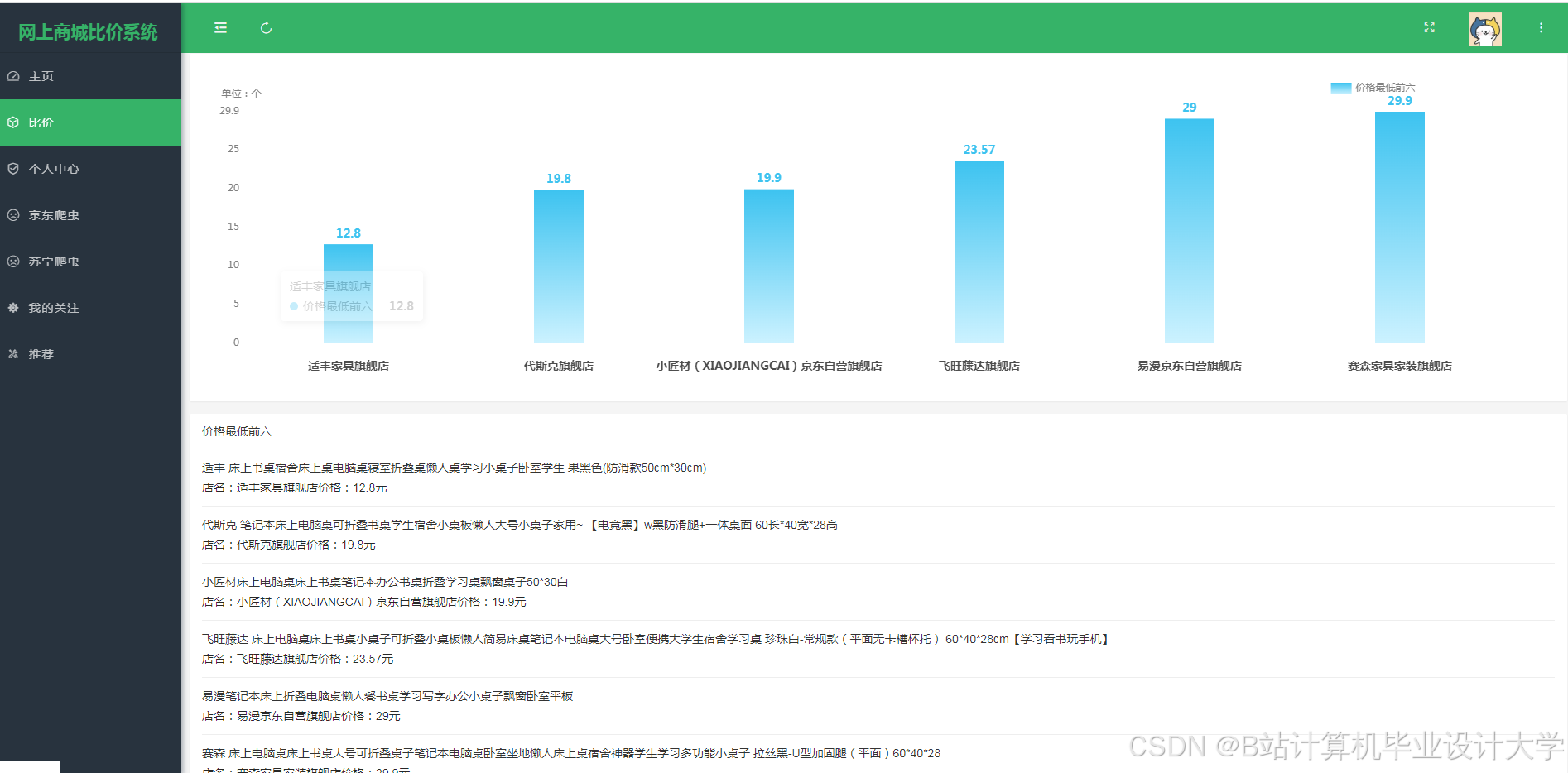
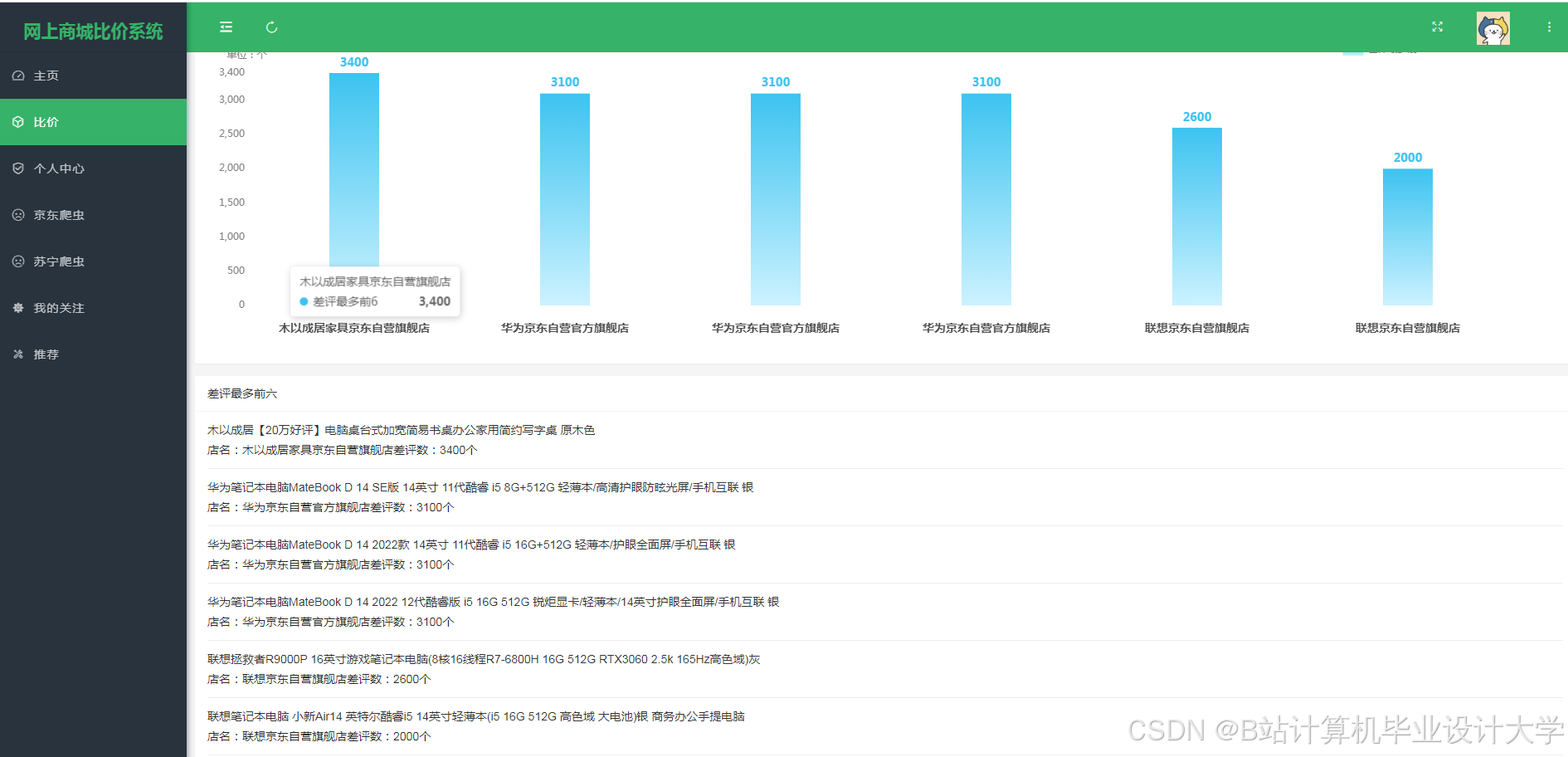
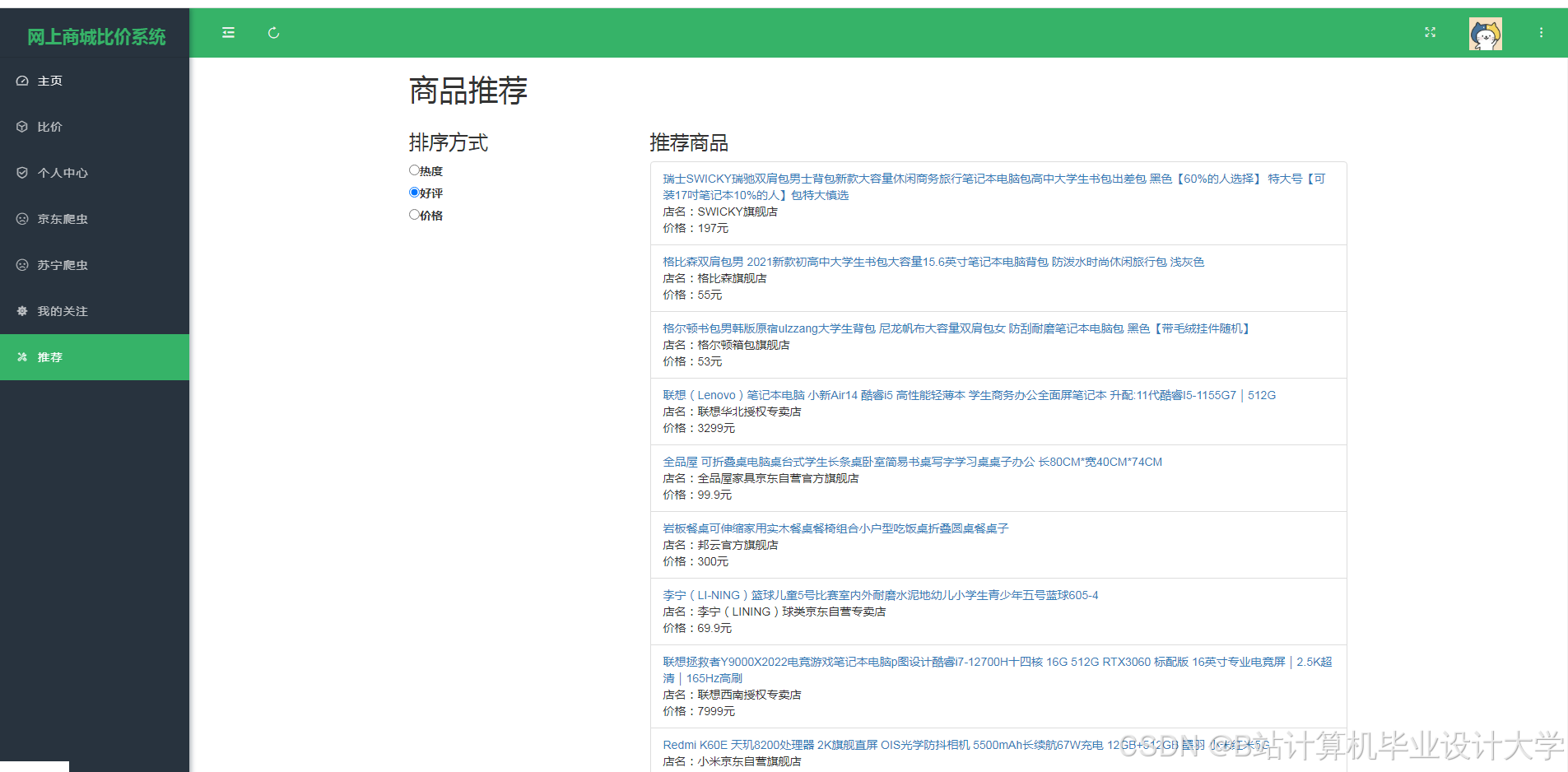
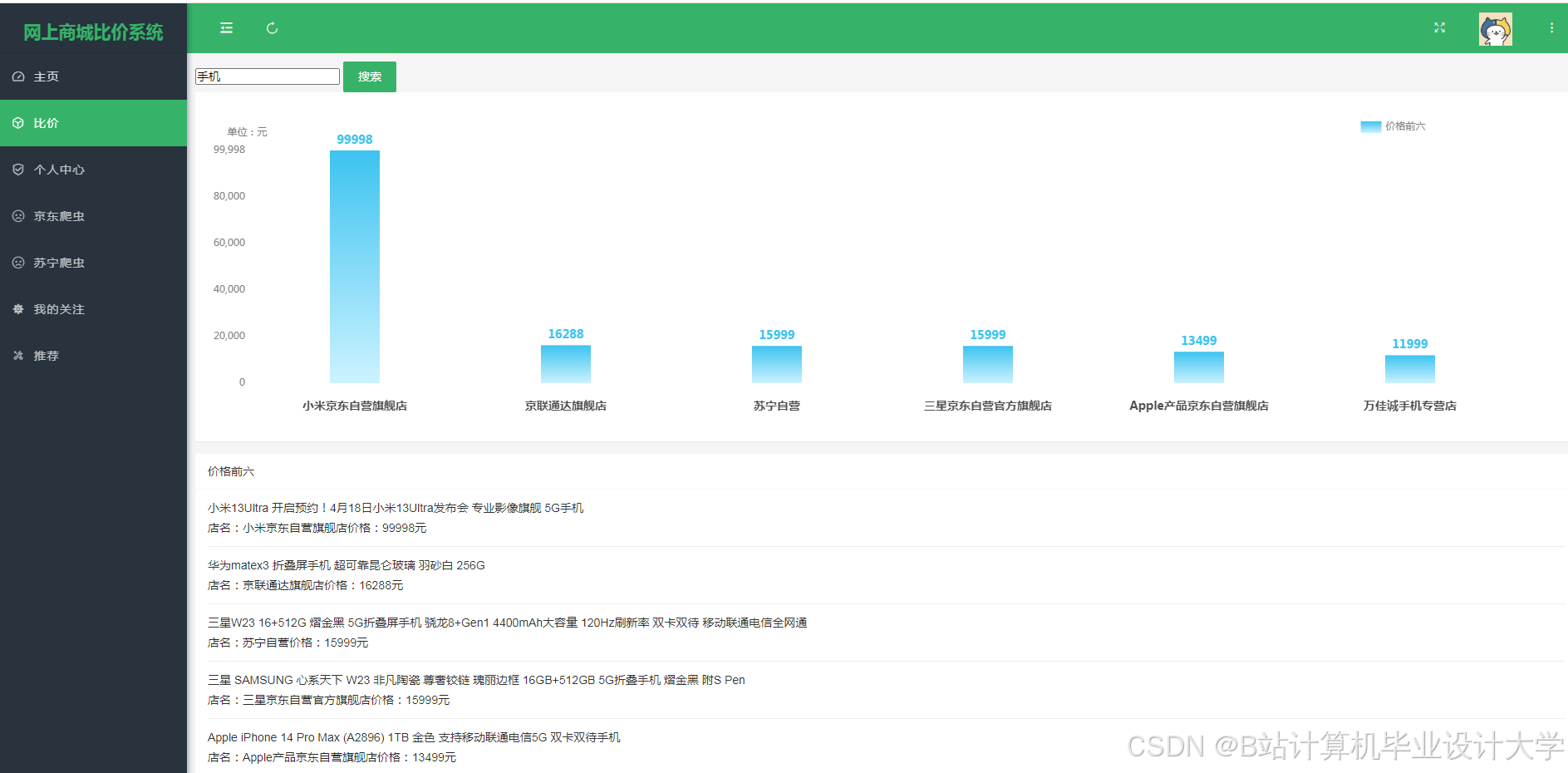
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











