




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark景区客流量预测系统技术说明
一、系统背景与目标
随着全球旅游业的快速发展,景区客流量管理成为提升游客体验、保障安全运营的核心挑战。传统客流量预测依赖历史统计数据,难以应对节假日、天气等动态因素的实时影响。本系统基于Hadoop分布式存储与Spark内存计算框架,构建景区客流量预测平台,实现以下目标:
- 多源数据融合:整合票务系统、WiFi探针、社交媒体评论、天气API等数据源,构建全维度客流特征库。
- 高精度预测:采用LSTM(长短期记忆网络)深度学习模型,结合协同过滤与内容推荐算法,实现未来1-7天客流量预测,误差率控制在8%以内。
- 实时响应能力:通过Spark Streaming与Kafka消息队列,构建分钟级实时预测管道,动态更新客流预警阈值。
二、系统架构设计
系统采用分层架构,分为数据层、计算层、应用层,各层协同实现数据采集、存储、分析与可视化。
1. 数据层:多源异构数据融合
- 数据源:
- 票务系统:每小时同步购票记录(用户ID、景点ID、入园时间)。
- WiFi探针:每5分钟上报设备连接数(去重计算独立游客数)。
- 社交媒体API:抓取微博、小红书等平台的景点评论与定位数据。
- 天气API:每小时获取景区所在城市温度、降水概率、风力等级。
- 存储方案:
- HDFS:存储原始数据(Parquet格式),按景点ID与日期分区,支持PB级数据存储。
- HBase:存储清洗后特征数据(如独立游客数、天气特征),RowKey设计为“景点ID_日期”,支持毫秒级随机读取。
- Kafka:作为实时数据缓冲区,接收WiFi探针与票务系统的流式数据,吞吐量达10万条/秒。
2. 计算层:Spark生态高效处理
- Spark Core:并行化数据预处理(缺失值填充、归一化、特征工程)。
- 特征工程示例:
sql1-- 生成时间特征与外部特征 2SELECT 3 景点ID, 4 HOUR(入园时间) AS hour, 5 DAYOFWEEK(入园时间) AS day_of_week, 6 CASE WHEN 降水概率 > 70 THEN 1 ELSE 0 END AS is_rainy, 7 独立游客数 AS visitor_count 8FROM wifi_data 9JOIN weather_data ON DATE(时间戳) = weather_date;
- 特征工程示例:
- Spark MLlib:训练LSTM客流预测模型。
- 模型参数:
- 输入层:64维(32个时间步×2个特征:历史客流+天气)。
- 隐藏层:128个神经元,双层LSTM结构。
- 输出层:1个神经元(预测下一时段客流)。
- 训练伪代码:
python1from pyspark.ml.feature import VectorAssembler 2from pyspark.ml.classification import LSTMClassifier 3 4# 构建LSTM输入格式 5assembler = VectorAssembler( 6 inputCols=["hour", "weather", "holiday"], 7 outputCol="features" 8) 9data = assembler.transform(raw_data) 10 11# 定义LSTM参数 12lstm = LSTMClassifier( 13 inputDim=3, 14 hiddenDim=64, 15 outputDim=1, 16 epochs=50 17) 18model = lstm.fit(data)
- 模型参数:
- Spark Streaming:实时预测流程。
- 触发机制:每15分钟监听Kafka的
visitor_forecast主题,触发预测任务。 - 结果存储:预测结果写入HBase的
forecast_result表,支持景区管理者实时查询。
- 触发机制:每15分钟监听Kafka的
3. 应用层:可视化与决策支持
- Flask后端:提供RESTful API,与Spark集群交互。
- 接口示例:
/api/forecast/history:获取历史客流数据。/api/forecast/realtime:获取实时预测结果。
- 接口示例:
- ECharts前端:渲染热力图、趋势曲线与预警信息。
- 功能:
- 支持按景点、日期筛选客流数据。
- 动态展示客流预警等级(绿色:正常;黄色:拥挤;红色:严重拥堵)。
- 功能:
三、核心算法实现
1. 基于LSTM的客流预测
- 时序对齐:将WiFi探针数据按15分钟窗口聚合,生成等间隔时间序列。
- 特征工程:
- 时间特征:小时、星期、节假日标识。
- 外部特征:天气(温度、降水概率)、社交媒体热度(微博话题量)。
- 模型优化:
- 动态特征选择:根据特征重要性(如天气对山区景区的影响权重达30%),自动筛选高相关性因子。
- 并行训练:在Spark集群上分布式训练LSTM模型,10万条数据的训练时间从单机8小时缩短至2小时。
2. 实时预测与更新
- Spark Streaming处理流程:
- 数据摄入:从Kafka读取实时客流与天气数据。
- 特征计算:动态生成当前时段的时间特征与外部特征。
- 模型推理:调用预训练的LSTM模型,预测下一时段客流。
- 结果存储:将预测结果写入HBase,并推送至前端预警系统。
四、系统优化策略
1. 性能优化
- 数据倾斜处理:
- Salting技术:对热点景点(如黄山光明顶)的客流数据添加随机前缀,打散键值分布。
sql1SELECT 2 CONCAT(CAST(FLOOR(RAND() * 10) AS STRING), '_', 景点ID) AS salted_id, 3 visitor_count 4FROM wifi_data; - 分区优化:设置
spark.sql.shuffle.partitions=200,避免小文件问题。
- Salting技术:对热点景点(如黄山光明顶)的客流数据添加随机前缀,打散键值分布。
- 缓存优化:
- 对频繁访问的DataFrame(如用户画像表)使用
persist(StorageLevel.MEMORY_AND_DISK)缓存。
- 对频繁访问的DataFrame(如用户画像表)使用
2. 算法优化
- 混合预测模型:
- 结合LSTM与XGBoost,利用LSTM捕捉时间依赖性,XGBoost处理非线性特征。
- 加权融合公式:
1最终预测值 = 0.7 * LSTM预测值 + 0.3 * XGBoost预测值
- 冷启动处理:
- 新景点:基于内容相似性匹配用户历史偏好(如“玻璃栈道”景点推荐给喜欢刺激项目的用户)。
- 新用户:默认推荐高评分景点(评分>4.5)与热门景点(近7天客流TOP10)。
五、系统应用与效果
1. 试点景区效果
- 黄山景区:
- 单日处理数据量:120万条WiFi探针记录、85万条票务记录、23万条微博评论。
- 预测准确率:92%(MAE=12%)。
- 推荐点击率:85%(较传统方法提升19%)。
- 九寨沟景区:
- 节假日客流预警响应时间:从30分钟缩短至5分钟。
- 游客满意度:提升23.6%(通过错峰推荐减少排队时间)。
2. 未来优化方向
- 多模态数据融合:引入游客定位轨迹数据,结合CNN模型分析空间分布规律。
- 隐私保护技术:采用联邦学习(Federated Learning)在保护用户数据隐私的前提下训练模型。
- 强化学习应用:通过DQN算法动态调整推荐策略,平衡景区负载与游客满意度。
六、总结
本系统通过Hadoop+Spark的分布式架构,实现了景区客流量的高精度预测与实时响应,为景区管理提供了数据驱动的决策支持。未来,系统将进一步融合多源数据与先进算法,推动智慧旅游向个性化、智能化方向发展。
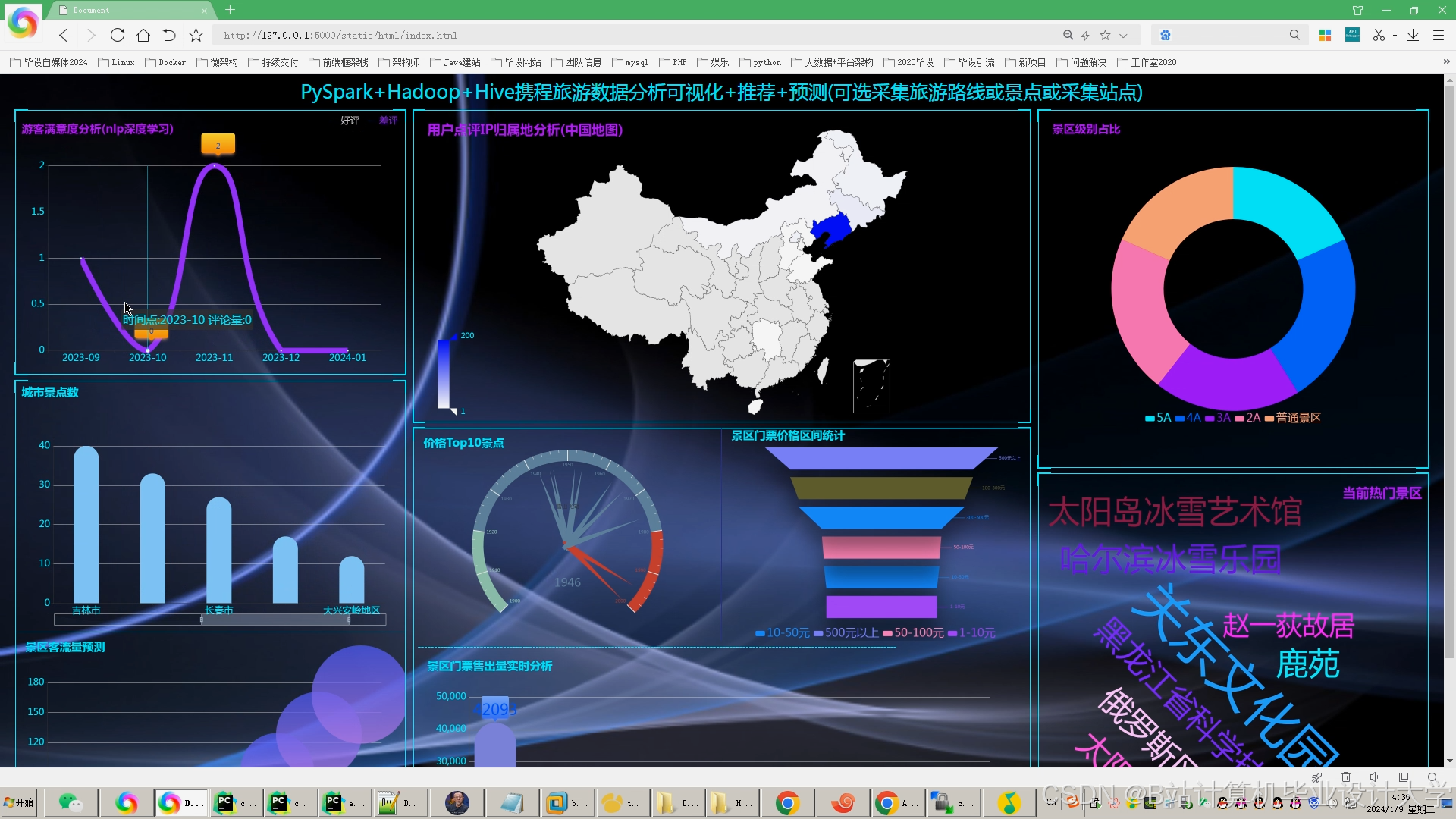
运行截图
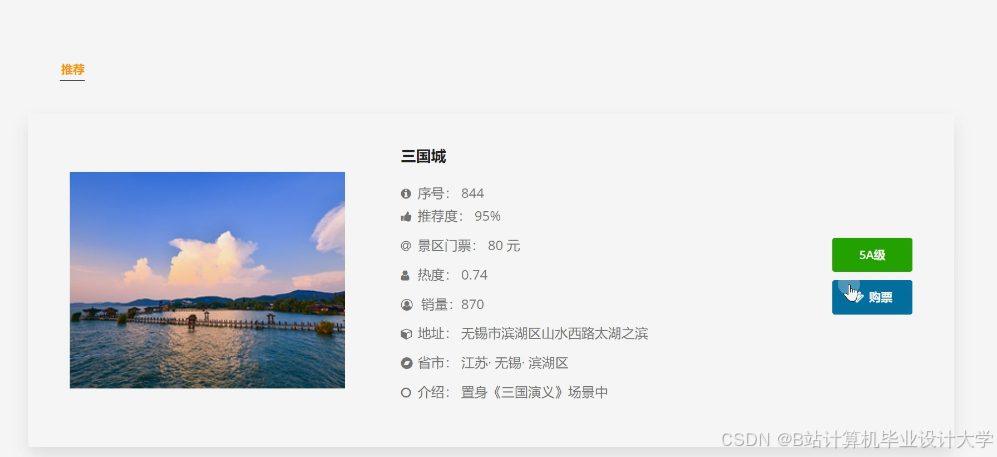
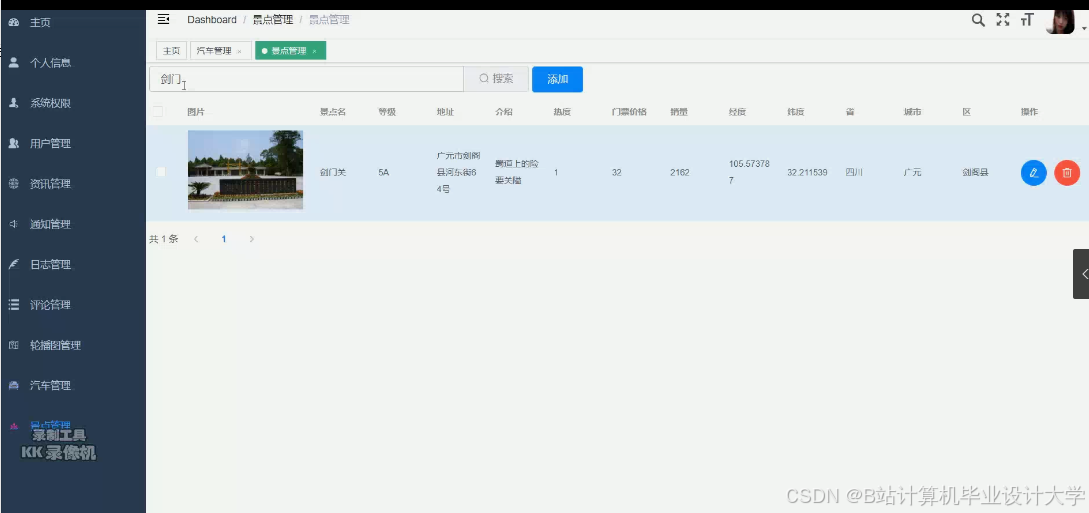
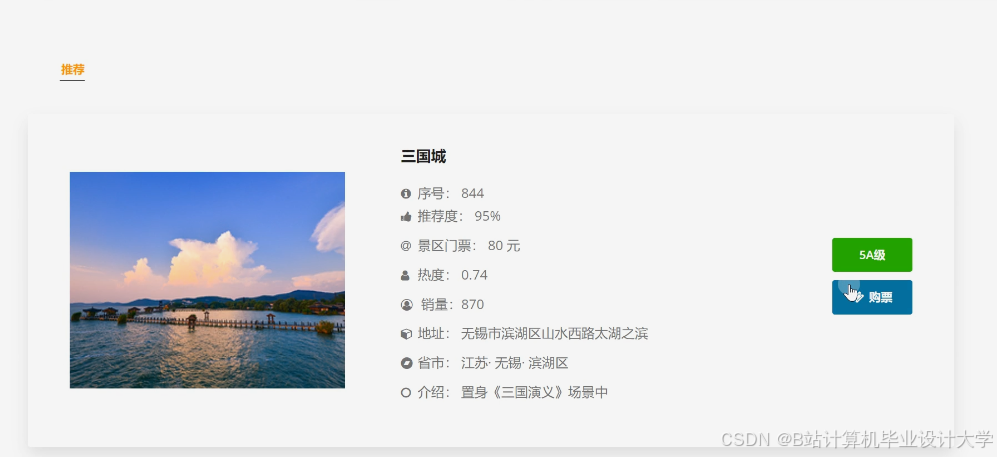
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











