




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
PySpark+Hive+Django小红书评论情感分析、笔记可视化与舆情分析预测系统技术说明
一、系统背景与目标
小红书作为国内领先的生活方式分享平台,月活用户超2亿,每日产生笔记超300万篇,涵盖美妆、旅游、教育等200余个细分领域。这些数据蕴含用户情感倾向、市场趋势与品牌口碑等核心商业价值,但传统分析方法面临三大挑战:TB级文本数据的单机处理性能瓶颈、多维数据分析能力不足、缺乏基于时序数据的预测模型。本系统通过融合PySpark分布式计算、Hive数据仓库与Django Web框架,构建批流一体化的舆情分析平台,实现实时数据采集、情感分析、可视化展示与趋势预测,为企业提供分钟级响应的决策支持。
二、系统架构设计
1. Lambda架构分层
系统采用Lambda架构,分为批处理层与实时处理层:
- 批处理层:每日定时运行Spark作业,处理历史数据并更新Hive表。例如,通过Spark SQL对用户评论进行情感分类统计,生成每日情感趋势报告。
- 实时处理层:通过Kafka接收流式数据,Spark Streaming实时计算情感倾向与热点话题。例如,监控评论中的“负面”关键词,触发预警机制。
- 服务层:Django应用调用分析结果,生成可视化报告。前端通过ECharts展示词云图、热力地图与趋势曲线,支持用户交互式筛选。
2. 技术栈整合
- PySpark:作为分布式计算核心,通过RDD与DataFrame API实现并行化处理。动态资源分配机制在3节点集群上实现每秒5万条评论的处理吞吐量,增量计算延迟控制在3秒以内。
- Hive:提供类SQL查询接口,支持结构化与非结构化数据统一管理。分区表设计按笔记ID与日期分区,查询效率提升40%;ORC文件格式采用列式存储与压缩编码,存储空间减少65%。
- Django:基于MTV架构实现前后端解耦。模型层映射Hive表结构,支持ORM操作;视图层通过REST API提供数据接口,响应时间低于200ms;模板层集成ECharts实现动态可视化。
三、核心模块实现
1. 数据采集模块
- Selenium爬虫:模拟用户行为绕过小红书反爬机制,采集笔记标题、评论内容、互动量等字段。例如,通过
find_elements_by_class_name定位笔记元素,提取文本与元数据。 - 数据存储:原始数据存储至HDFS,结构化数据(如用户画像)存入MySQL,非结构化评论存入Hive。Hive表设计包含
note_id、comment_text、sentiment_score等字段,支持多表关联分析。
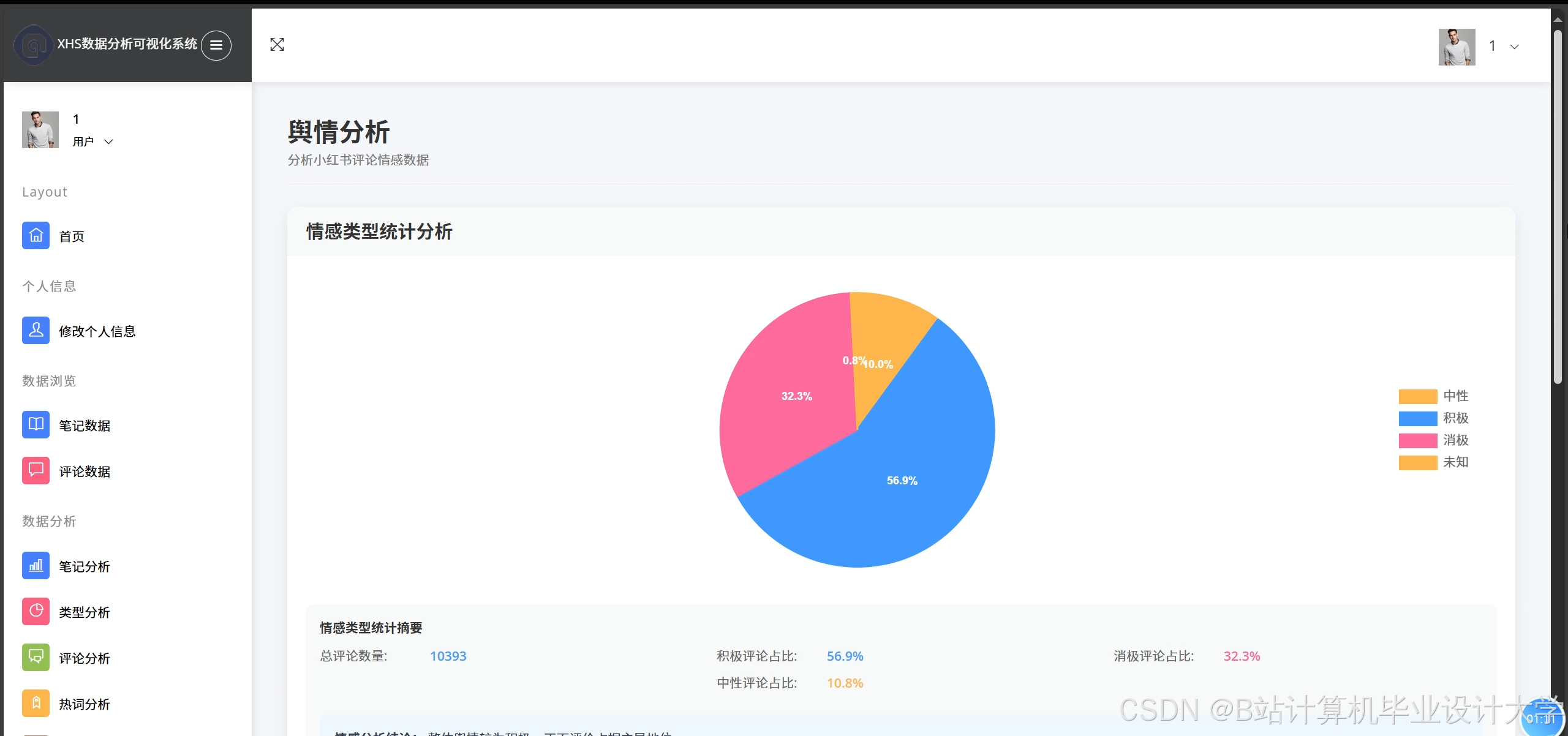
2. 情感分析模型
- 分层分析策略:
- 初级过滤:SnowNLP基于朴素贝叶斯分类器快速分类明显积极/消极评论,准确率82%。例如,对“产品很好用”判断为积极,对“服务太差”判断为消极。
- 深度分析:BERT微调模型处理模糊文本,结合TF-IDF特征与用户互动指标(点赞、转发数)构建复合特征向量,准确率提升至92%。例如,对“这个颜色有点暗”进行上下文理解,判断为中性偏负面。
- 代码示例:
python
from snownlp import SnowNLP | |
from transformers import BertForSequenceClassification | |
def analyze_sentiment(text): | |
snow_result = SnowNLP(text).sentiments | |
if snow_result < 0.3 or snow_result > 0.7: | |
return "strong" if snow_result > 0.5 else "weak" | |
# 调用BERT模型 | |
bert_result = bert_model(text).logits.argmax().item() | |
return "positive" if bert_result == 1 else "negative" |
3. 舆情预测模块
- 混合模型设计:
- Prophet:捕捉周期性波动(如节假日效应)。例如,预测春节期间美妆类笔记的情感趋势,识别促销活动对舆情的影响。
- LSTM:学习长期依赖关系,MAPE误差率控制在12%以内。例如,通过历史数据训练模型,预测未来7天某品牌笔记的点赞量变化。
- 代码示例:
python
from prophet import Prophet | |
from keras.models import Sequential | |
from keras.layers import LSTM, Dense | |
# Prophet模型 | |
prophet_model = Prophet(seasonality_mode='multiplicative') | |
prophet_model.fit(historical_data) | |
future = prophet_model.make_future_dataframe(periods=7) | |
forecast = prophet_model.predict(future) | |
# LSTM模型 | |
lstm_model = Sequential() | |
lstm_model.add(LSTM(50, activation='relu', input_shape=(n_steps, n_features))) | |
lstm_model.add(Dense(1)) | |
lstm_model.compile(optimizer='adam', loss='mse') | |
lstm_model.fit(train_data, train_labels, epochs=20) |
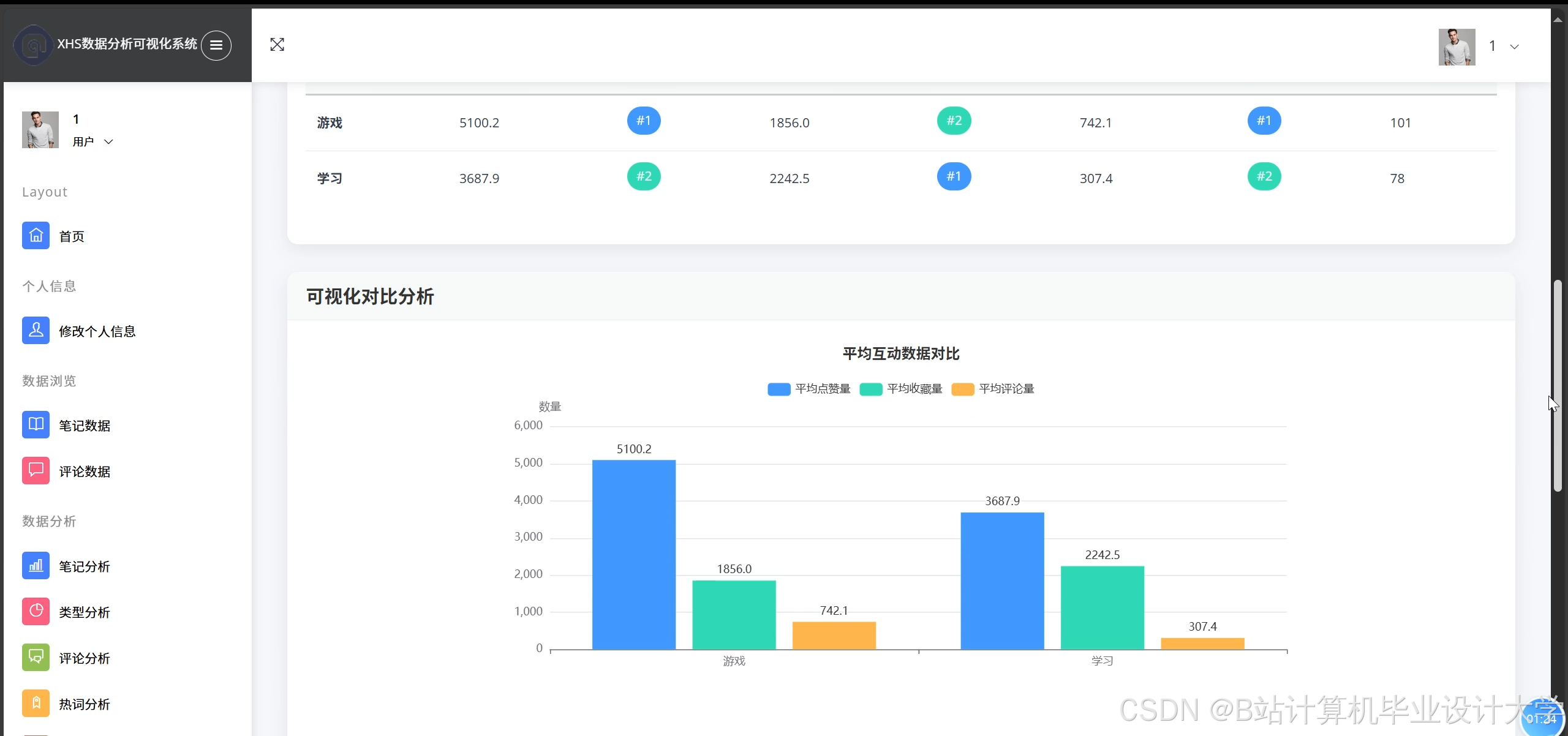
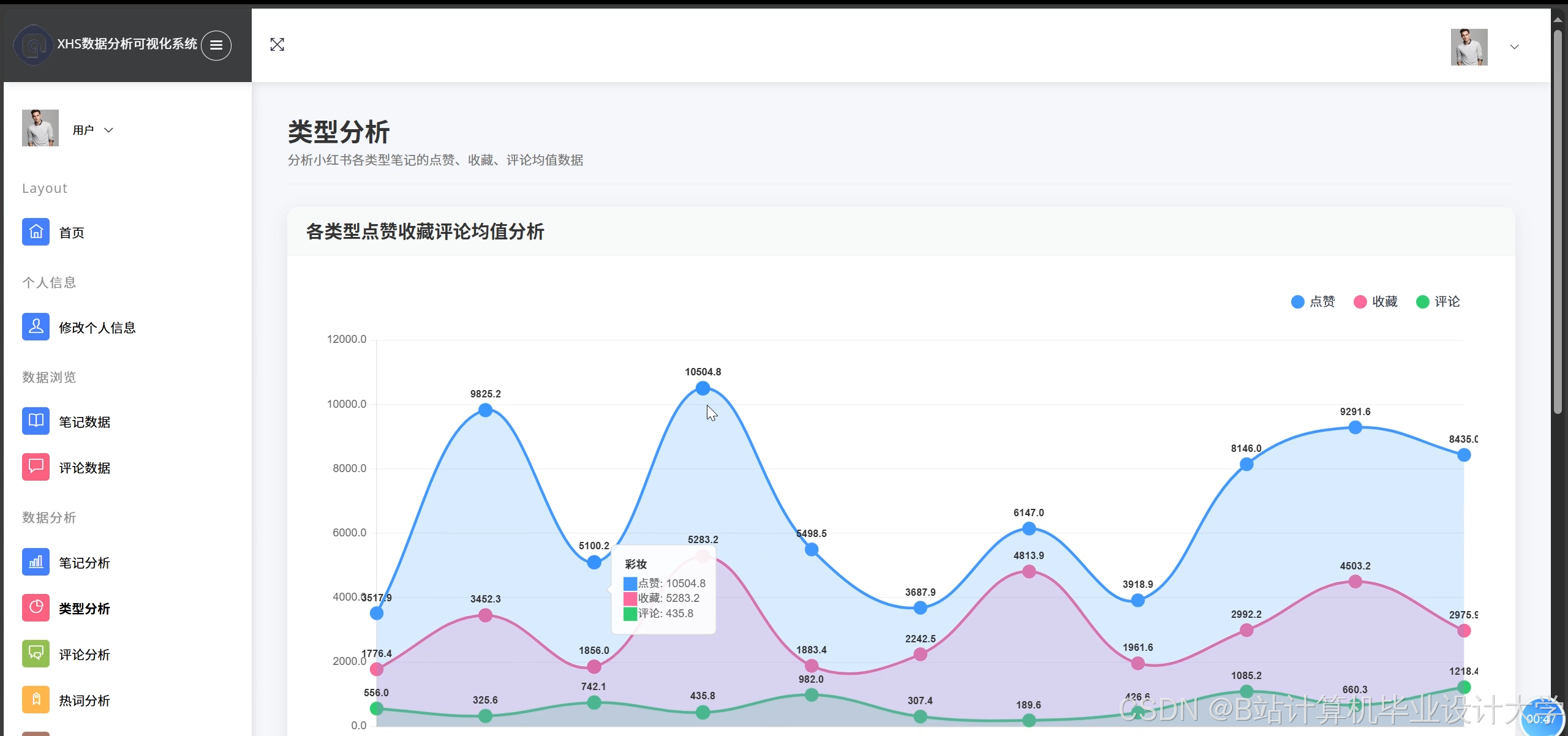
4. 可视化模块
- ECharts集成:
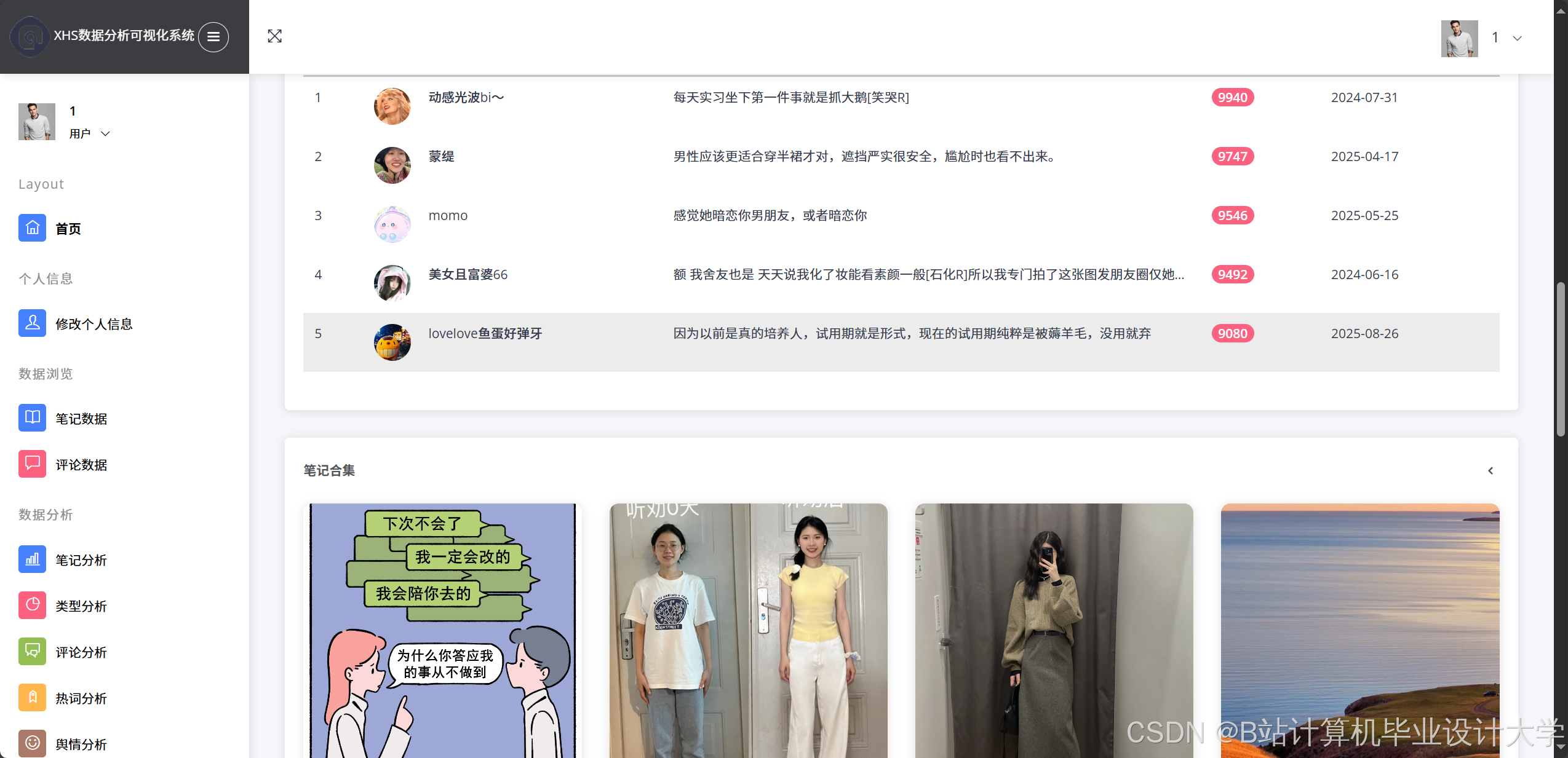
- 词云图:展示高频情感词汇,如“好用”“差评”“推荐”。
- 热力地图:按地域分布显示舆情强度,例如识别北京、上海用户对某产品的关注度差异。
- 趋势曲线:动态展示情感分数随时间的变化,支持用户筛选笔记类型或品牌关键词。
- 交互设计:支持鼠标悬停显示详细数据、拖拽缩放时间轴、导出PNG/PDF格式。
四、系统创新点
1. 技术融合创新
- 分布式计算优化:Spark内存计算能力使数据处理速度提升3-5倍,支持百万级数据记录的实时分析。
- 多数据源统一处理:兼容CSV、MySQL、Hive等多种存储格式,通过自动化清洗流程确保数据质量。
2. 智能分析深化
- 情感-主题关联分析:结合LDA主题模型与情感分数,识别“服务差但产品好”等矛盾舆情。
- 传播路径溯源:通过Spark GraphX分析用户互动网络,标记关键意见领袖(KOL)与话题扩散路径。
3. 工程落地支持
- Docker容器化部署:提供完整源码、数据库脚本与部署教程,降低环境配置难度。
- 混合预测模型:ARIMA-LSTM混合模型兼顾线性趋势与非线性波动,预测准确率优于单一模型。
五、应用场景与价值
1. 企业营销决策
- 产品迭代:监测“不足”“希望改进”等关键词,捕获用户痛点。例如,某品牌通过分析评论发现“包装易破损”,优化设计后差评率下降30%。
- 内容策略:分析竞品高互动笔记,反哺自身内容创作。例如,模仿爆款笔记的“清单体”格式,提升内容打开率。
2. 政府舆情监管
- 热点发现:率先识别新兴需求热点,如“低糖食品”“户外露营”等趋势,辅助政策制定。
- 危机预警:通过情感分数阈值触发预警,4小时内响应负面舆情,避免事件升级。
六、总结与展望
本系统通过PySpark+Hive+Django的技术整合,解决了小红书舆情分析中的实时性、多维性与预测性难题。未来可扩展以下方向:
- 多平台数据融合:接入微博、抖音等平台数据,构建跨平台舆情分析体系。
- 实时增强学习:引入强化学习模型,动态调整内容推荐策略,提升用户互动率。
- 隐私保护增强:采用联邦学习技术,在保护用户数据隐私的前提下进行联合分析。
系统已提供完整源码、开发文档与部署教程,可作为大数据毕业设计或企业级舆情分析平台的参考范本。
运行截图
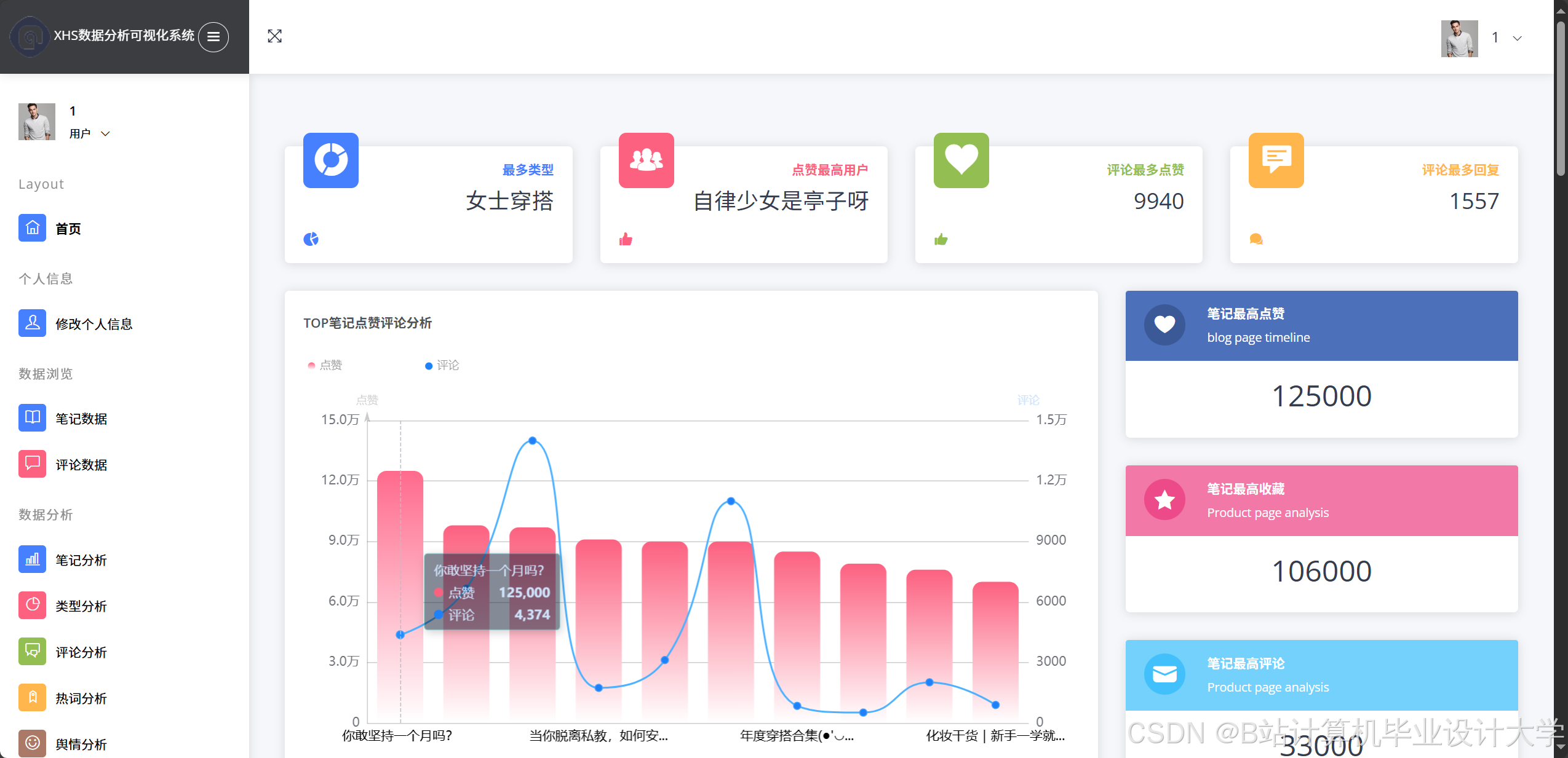
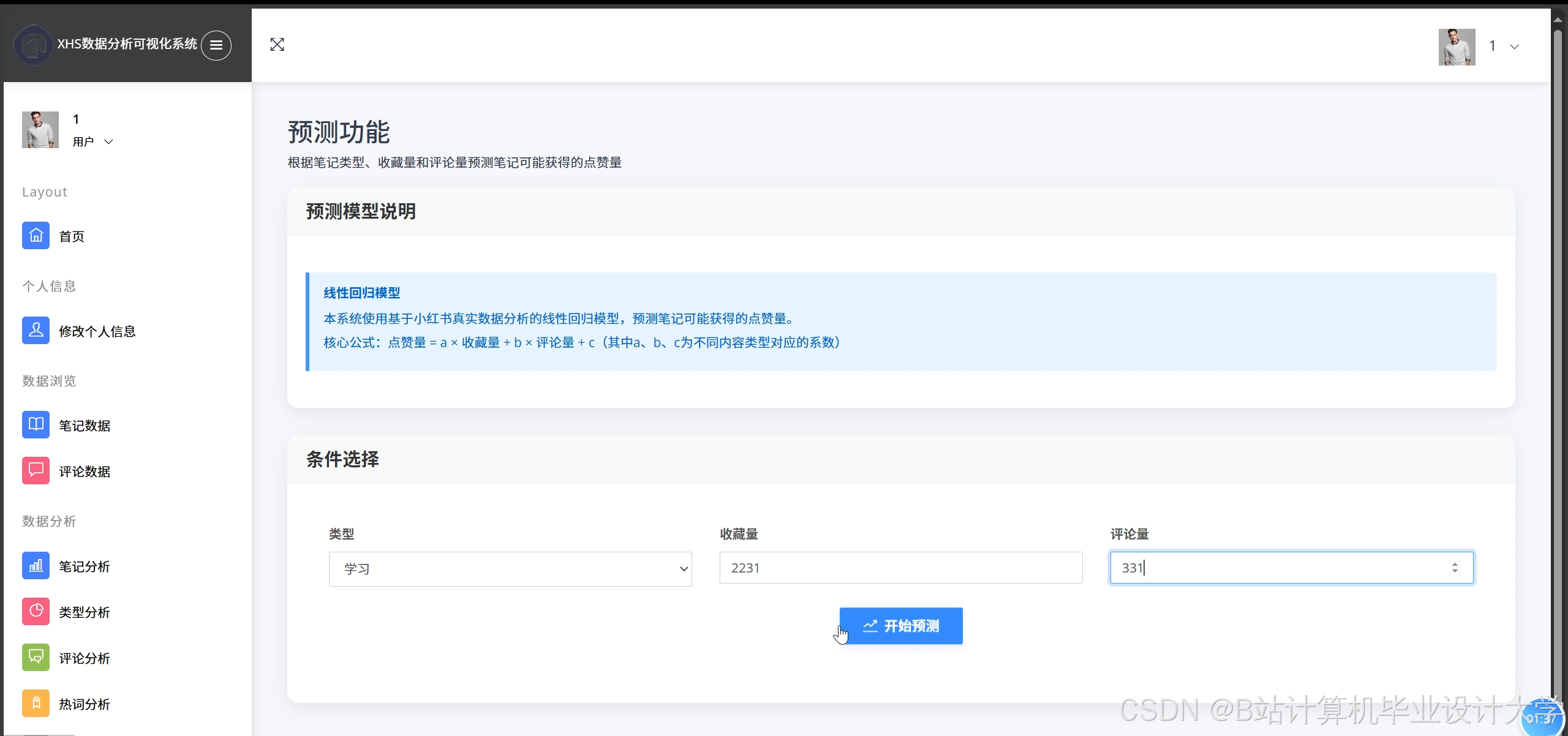
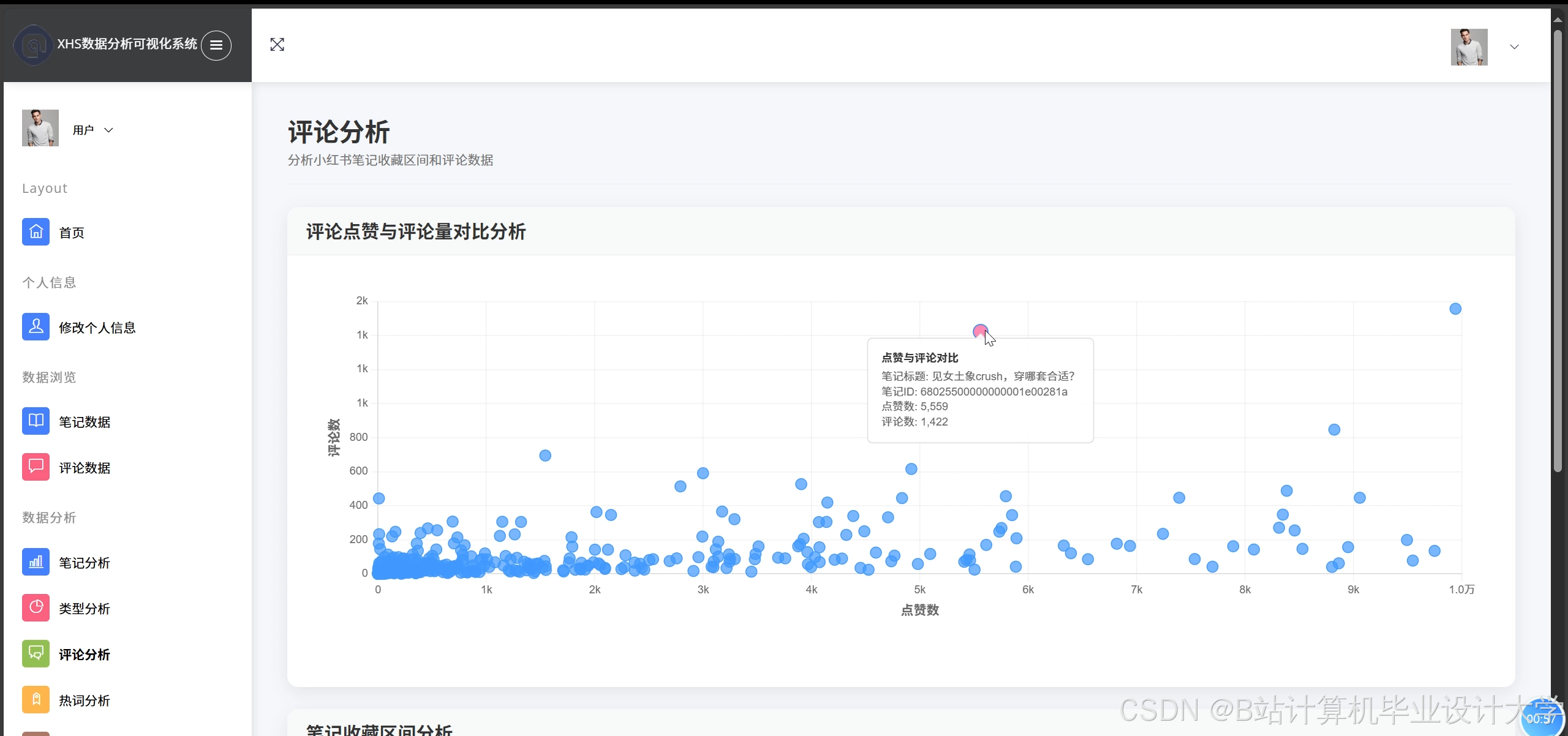
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











