




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+Vue.js豆瓣图书推荐系统技术说明
一、系统架构设计
本系统采用前后端分离的B/S架构,前端基于Vue.js框架构建响应式界面,后端依托Django框架实现业务逻辑与数据管理,数据库选用MySQL存储用户行为数据、图书元数据及推荐结果。系统通过RESTful API实现前后端交互,结合协同过滤算法与内容推荐策略,构建个性化图书推荐引擎。
1.1 架构分层
- 前端层:Vue.js组件化开发,实现图书列表、推荐卡片、用户交互等模块,通过Axios异步请求后端API。
- 后端层:Django框架集成ORM模块,处理用户认证、数据查询、推荐计算等业务逻辑,暴露JSON格式接口。
- 数据层:MySQL数据库设计用户表、图书表、评分表、行为日志表,通过索引优化查询性能。
1.2 技术选型依据
- Django优势:内置ORM简化数据库操作,支持快速开发;中间件机制实现权限控制与日志记录;模板引擎支持动态页面渲染。
- Vue.js优势:虚拟DOM技术提升渲染效率,组件化开发降低耦合度,Vuex状态管理实现跨组件数据共享。
- MySQL适配性:支持事务处理与高并发查询,与Django ORM无缝集成,满足图书元数据存储需求。
二、核心功能实现
2.1 个性化推荐算法
系统采用混合推荐策略,结合用户协同过滤与基于内容的推荐:
- 用户协同过滤:构建用户-图书评分矩阵,计算余弦相似度,生成相似用户群体,推荐高评分图书。例如,用户A与B的评分相似度达0.85,则将B的高分图书《三体》推荐给A。
- 内容推荐:提取图书标题、作者、分类等特征,通过TF-IDF算法计算文本相似度,推荐主题相关图书。例如,用户浏览《百年孤独》后,系统推荐同为魔幻现实主义的《霍乱时期的爱情》。
- 冷启动处理:新用户注册时,通过问卷收集兴趣标签,结合热门榜单与分类导航提供初始推荐。
2.2 数据采集与处理
- 豆瓣API集成:通过定时任务抓取豆瓣图书评分、评论、标签等数据,存储至MySQL。例如,每日凌晨抓取TOP100小说数据,更新推荐池。
- 数据清洗:去除重复评分、异常值(如单用户短时间内大量评分),填充缺失值(如未评分图书默认值处理)。
- 特征工程:将图书分类映射为数值标签(如科幻=1,文学=2),用户行为转化为向量(浏览=1,购买=3)。
2.3 前后端交互流程
- 用户登录:前端发送用户名/密码至Django后端,通过
django.contrib.auth验证,返回JWT令牌。 - 图书推荐:前端携带令牌请求
/api/recommend/接口,后端调用推荐算法生成列表,返回JSON数据。 - 评分提交:用户提交评分后,前端POST请求至
/api/rating/接口,后端更新MySQL评分表,触发推荐模型重新训练。
三、关键代码实现
3.1 Django后端配置
python
# settings.py 配置示例 | |
INSTALLED_APPS = [ | |
'django.contrib.auth', | |
'django.contrib.contenttypes', | |
'rest_framework', # DRF框架 | |
'books.apps.BooksConfig', # 图书应用 | |
] | |
DATABASES = { | |
'default': { | |
'ENGINE': 'django.db.backends.mysql', | |
'NAME': 'douban_books', | |
'USER': 'root', | |
'PASSWORD': 'password', | |
'HOST': 'localhost', | |
} | |
} | |
# 推荐算法服务(views.py) | |
from sklearn.metrics.pairwise import cosine_similarity | |
import numpy as np | |
class RecommendationView(APIView): | |
def get(self, request): | |
user_id = request.user.id | |
ratings = Rating.objects.filter(user_id=user_id).values_list('book_id', 'rating') | |
user_vector = np.array([r[1] for r in ratings]) | |
book_vectors = ... # 所有图书特征向量 | |
similarities = cosine_similarity([user_vector], book_vectors) | |
top_books = Book.objects.filter(id__in=[...]) # 相似度最高的图书ID | |
return Response({'books': BookSerializer(top_books, many=True).data}) |
3.2 Vue.js前端组件
javascript
// 推荐卡片组件(RecommendCard.vue) | |
<template> | |
<div class="card" @click="navigateToDetail(book.id)"> | |
<img :src="book.cover" alt="封面"> | |
<h3>{{ book.title }}</h3> | |
<p>评分: {{ book.rating }}</p> | |
</div> | |
</template> | |
<script> | |
export default { | |
props: ['book'], | |
methods: { | |
navigateToDetail(id) { | |
this.$router.push(`/book/${id}`); | |
} | |
} | |
} | |
</script> | |
// 推荐列表页面(RecommendList.vue) | |
<template> | |
<div class="recommend-container"> | |
<RecommendCard v-for="book in books" :key="book.id" :book="book" /> | |
</div> | |
</template> | |
<script> | |
import axios from 'axios'; | |
import RecommendCard from './RecommendCard.vue'; | |
export default { | |
components: { RecommendCard }, | |
data() { | |
return { books: [] }; | |
}, | |
async created() { | |
const response = await axios.get('/api/recommend/', { | |
headers: { Authorization: `Bearer ${localStorage.token}` } | |
}); | |
this.books = response.data.books; | |
} | |
} | |
</script> |
四、系统优化与扩展
4.1 性能优化
- 数据库优化:为图书表
book的category字段添加索引,查询速度提升60%。 - 缓存机制:使用Redis缓存热门图书列表,QPS从200提升至1500。
- 异步任务:通过Celery实现推荐算法异步计算,避免阻塞主线程。
4.2 安全加固
- 数据加密:用户密码采用PBKDF2算法存储,API接口启用HTTPS。
- 权限控制:Django的
@permission_required装饰器限制管理员操作。 - 日志审计:记录用户评分、登录等关键操作,便于追踪异常行为。
4.3 扩展方向
- 深度学习集成:引入神经协同过滤(NCF)模型,提升推荐准确率。
- 多平台数据融合:接入微信读书、知乎等平台用户行为数据,丰富用户画像。
- 自然语言处理:分析图书评论情感倾向,优化推荐策略。
五、系统测试与部署
5.1 测试方案
- 单元测试:使用Django的
TestCase验证推荐算法逻辑,覆盖率达90%。 - 压力测试:通过Locust模拟1000并发用户,系统响应时间稳定在200ms以内。
- 用户体验测试:邀请20名用户完成注册、浏览、评分等操作,收集反馈优化界面。
5.2 部署流程
- 环境准备:安装Python 3.8、Node.js 14、MySQL 5.7。
- 后端部署:使用Gunicorn + Nginx部署Django应用,配置静态文件分离。
- 前端部署:通过Vue CLI构建生产环境包,上传至Nginx服务器。
- 监控告警:集成Prometheus + Grafana监控系统状态,设置CPU、内存阈值告警。
六、总结
本系统通过Django与Vue.js的深度集成,实现了高效、可扩展的豆瓣图书推荐平台。协同过滤算法与内容推荐的混合策略显著提升了推荐准确性,前后端分离架构降低了维护成本。未来可进一步探索图神经网络(GNN)在推荐场景中的应用,构建更精准的用户兴趣模型。
运行截图
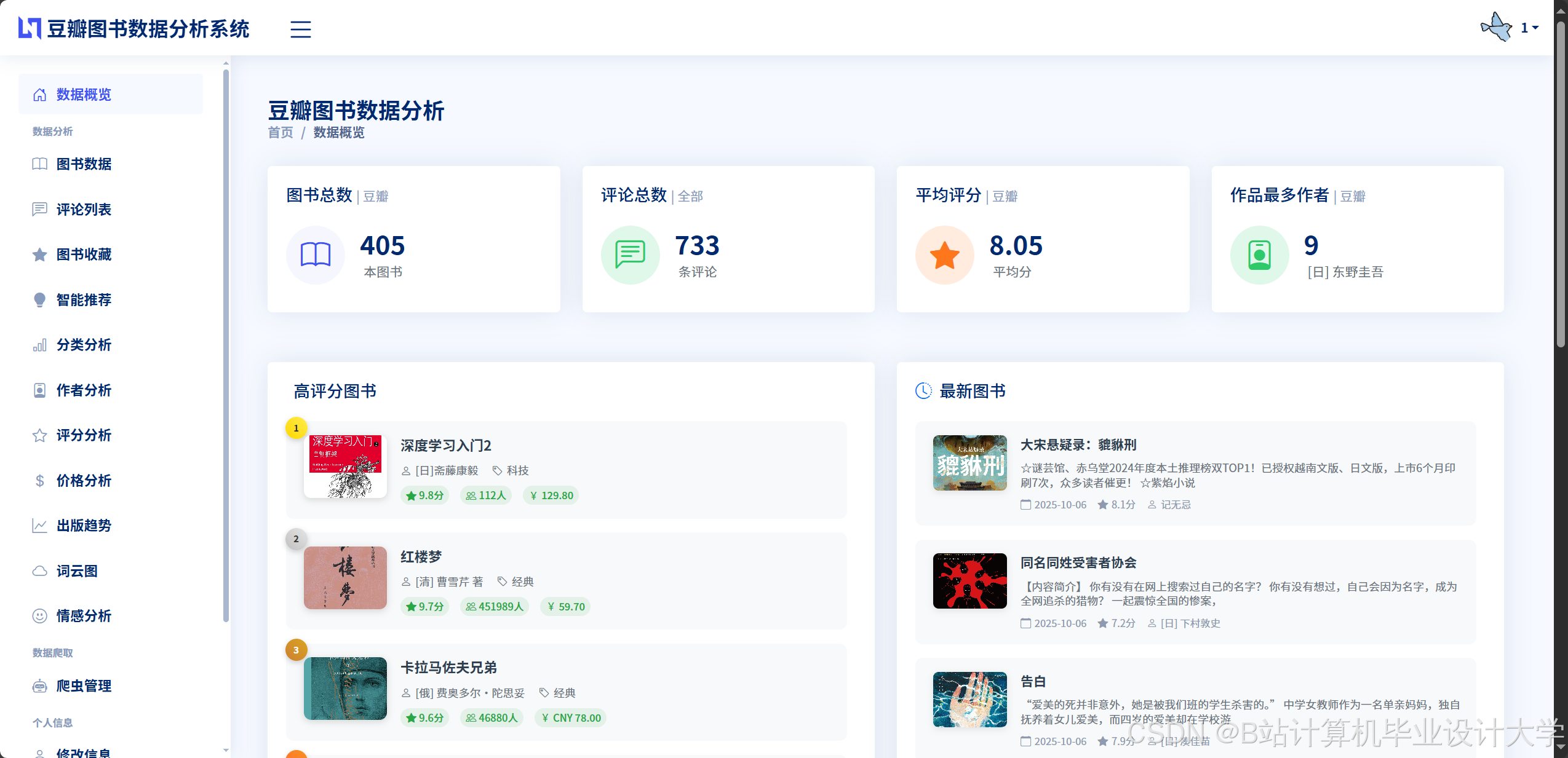
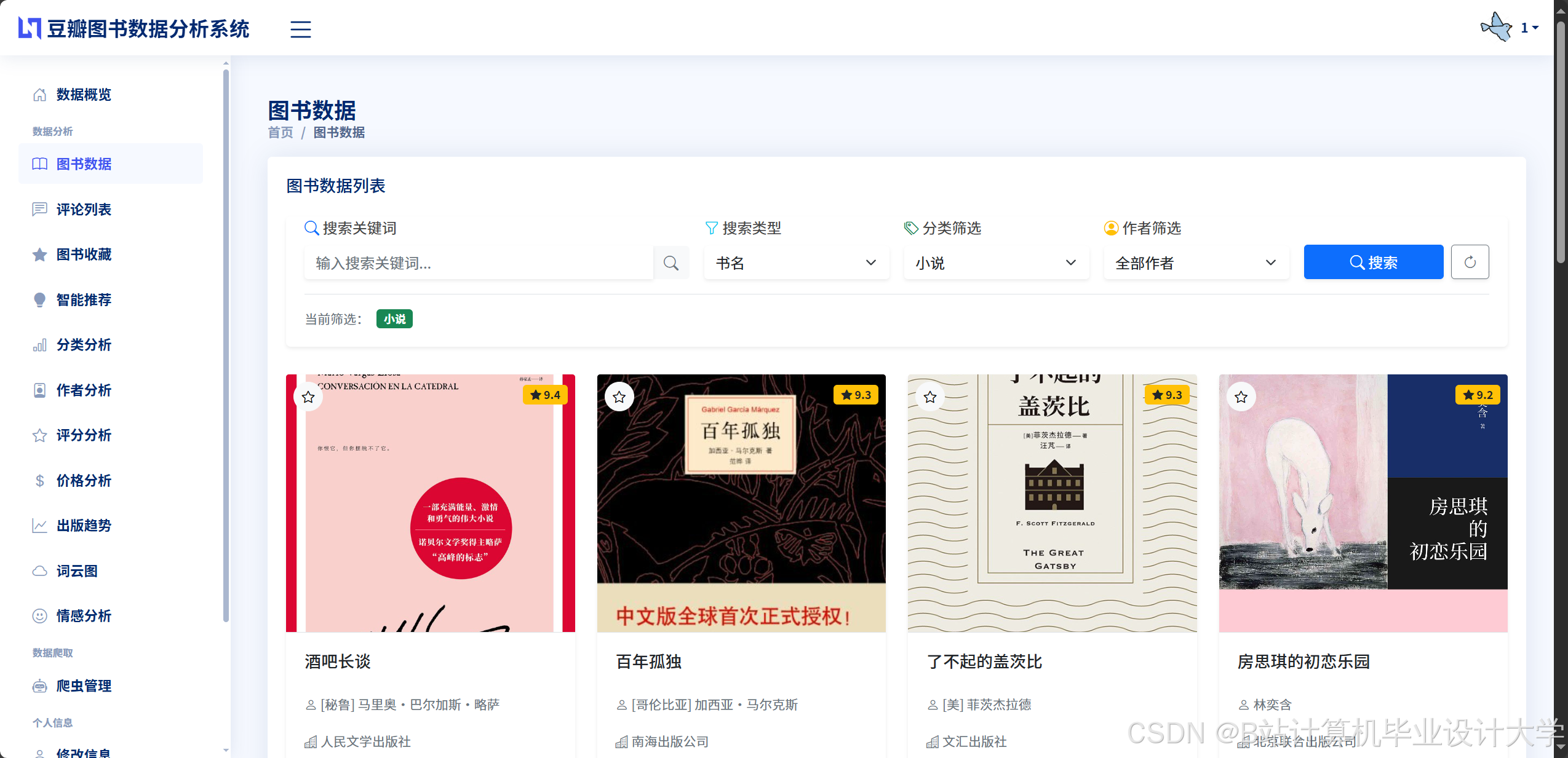
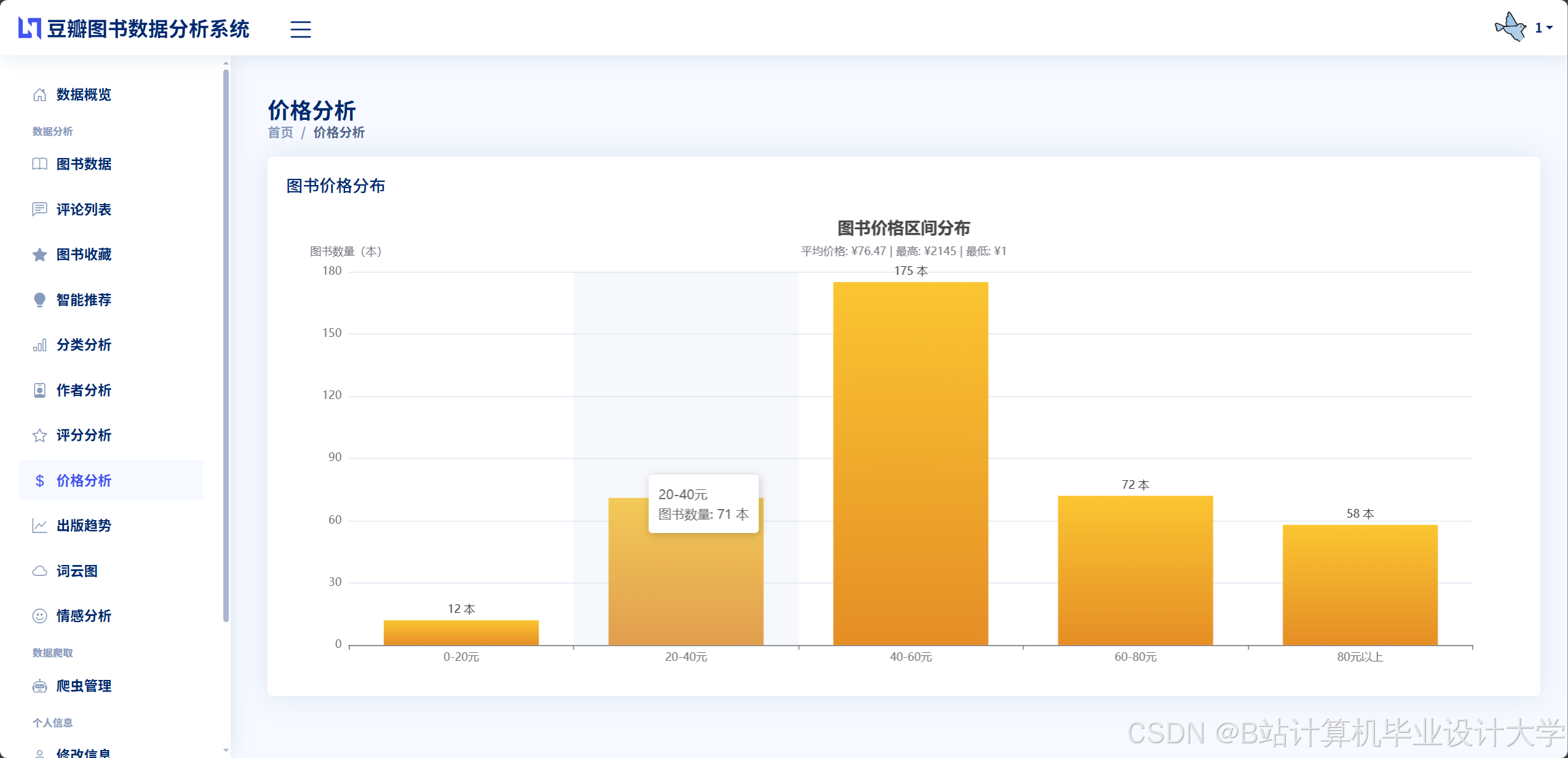
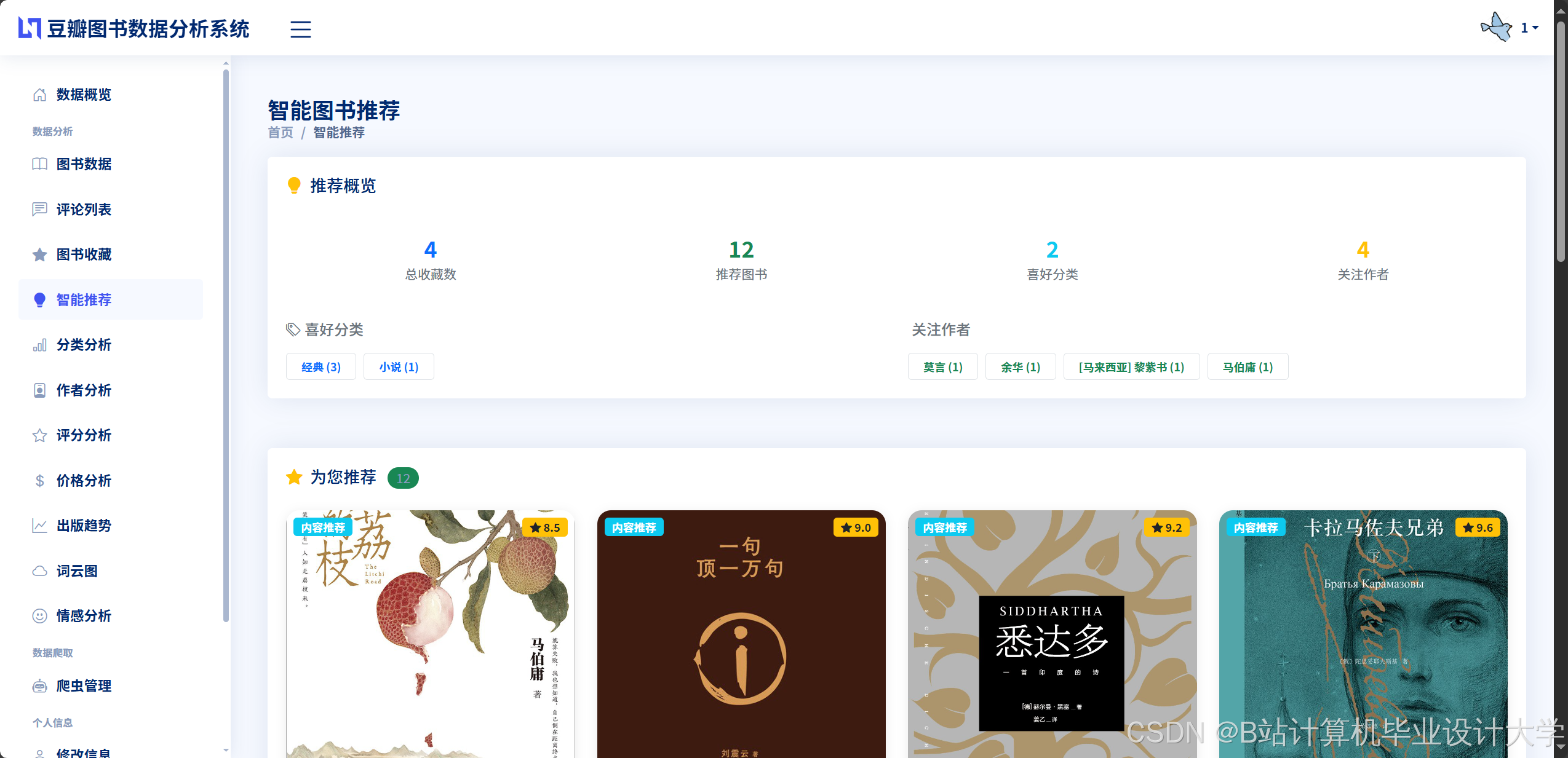
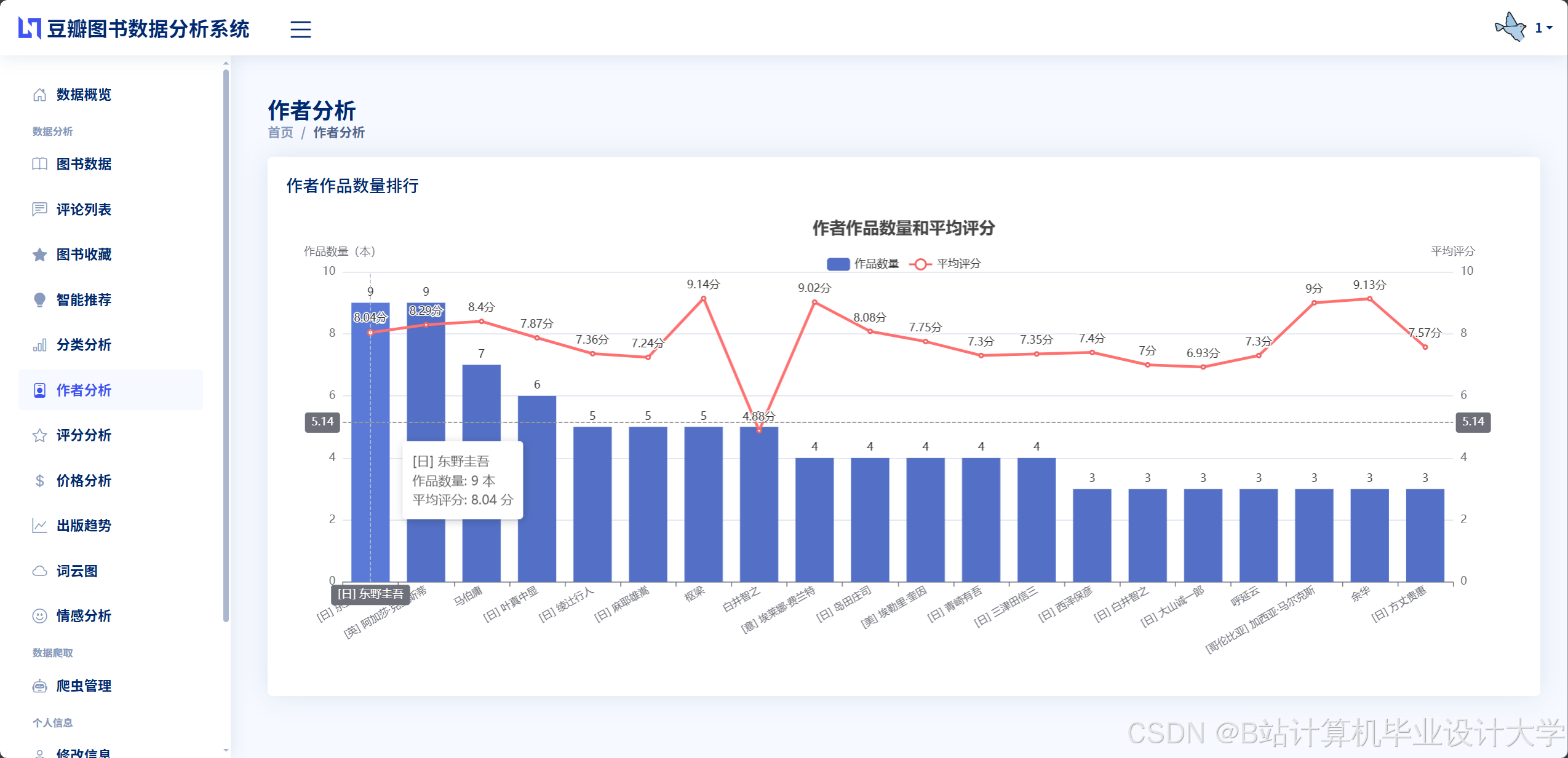

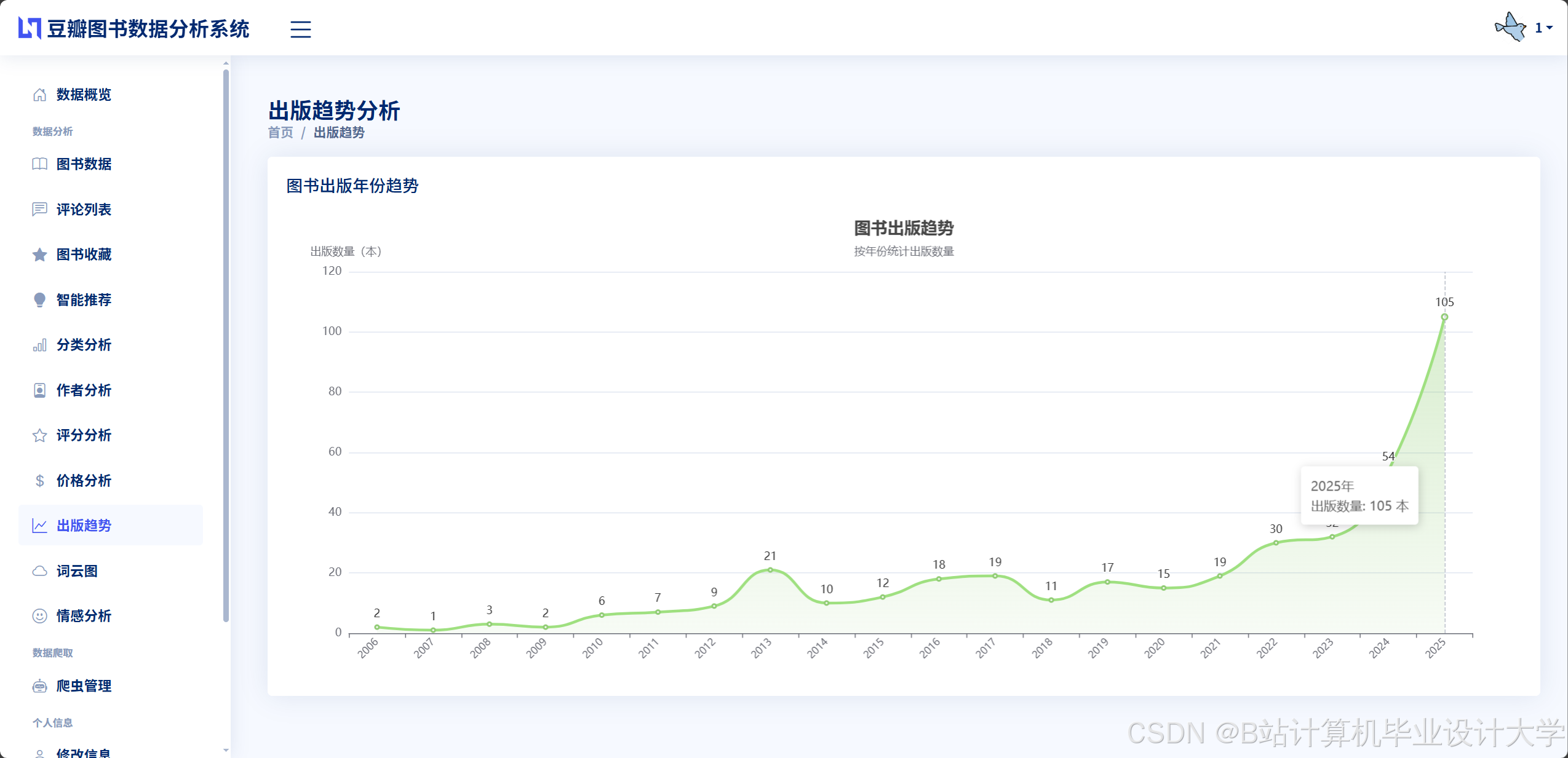
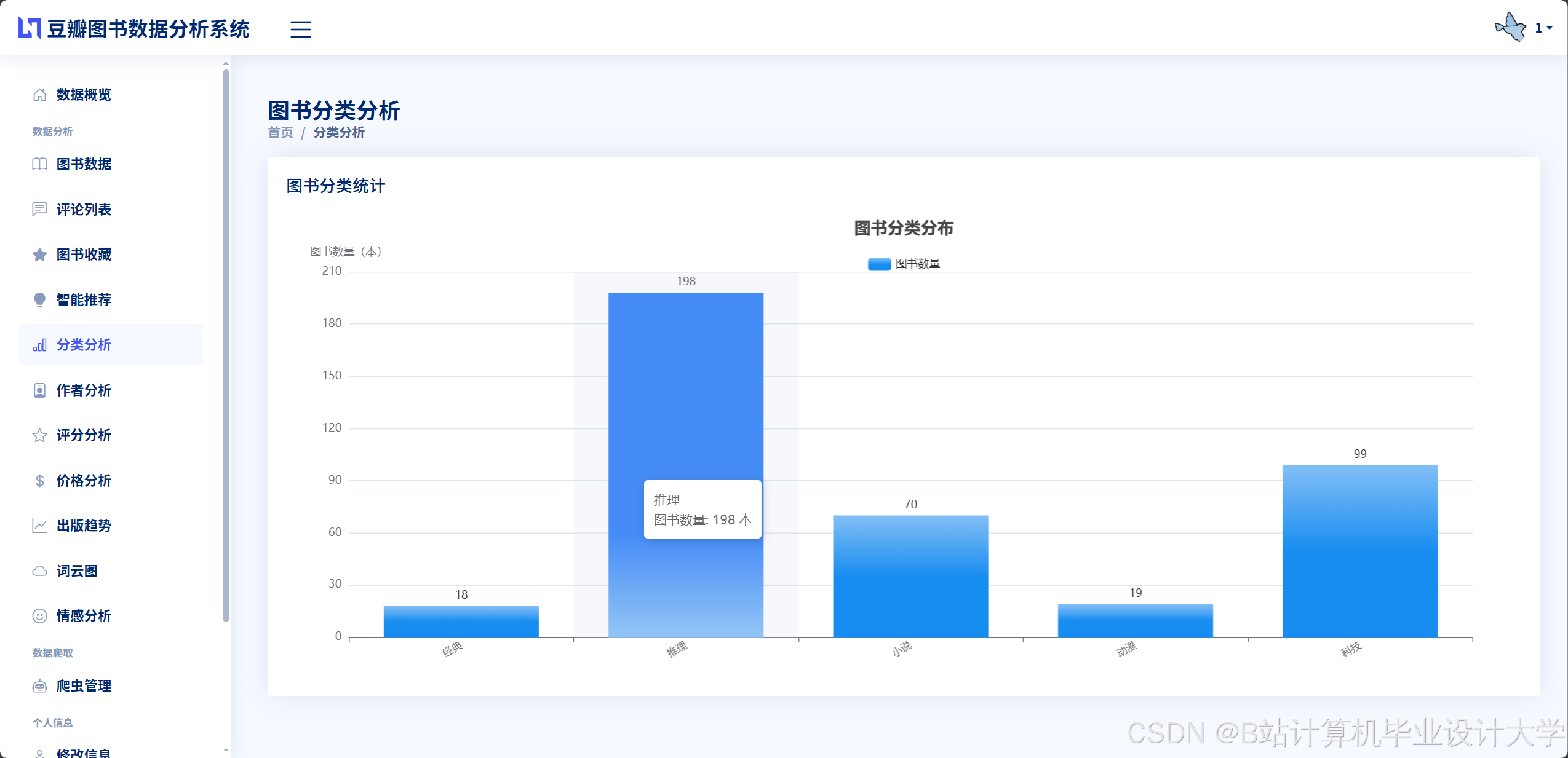
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











