




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive招聘推荐系统技术说明:基于大数据的智能人才匹配方案
一、系统架构设计
本系统采用"离线批处理+实时流处理"混合架构,基于Hadoop生态构建分布式计算平台,核心模块包括:
- 数据采集层:支持结构化(简历JSON/数据库表)与非结构化(PDF简历/视频面试)数据接入
- 存储计算层:
- HDFS存储原始数据(压缩率达75%的Parquet格式)
- Hive构建数据仓库(按日期分区,每日增量更新)
- Spark内存计算加速特征处理(较MapReduce快10-20倍)
- 算法引擎层:
- 基于Spark MLlib实现协同过滤与深度学习推荐
- Hive UDF扩展支持复杂业务规则
- 服务应用层:提供RESTful API与可视化看板(ECharts+Superset)
二、核心数据模型设计
1. 多维特征体系
| 特征类别 | 示例字段 | 处理方式 |
|---|---|---|
| 基础属性 | 年龄、学历、工作年限 | 独热编码+标准化 |
| 技能标签 | Python、Spark、机器学习 | TF-IDF加权+LDA主题建模 |
| 项目经验 | 项目规模、技术栈、成果指标 | 文本向量化(BERT嵌入) |
| 行为数据 | 职位浏览记录、投递次数 | 序列编码(Word2Vec) |
| 企业偏好 | 薪资范围、文化关键词、技能权重 | 规则引擎+模糊匹配 |
2. Hive数据仓库表结构
sql
-- 候选人基础信息表(每日增量) | |
CREATE TABLE candidate_profile ( | |
candidate_id STRING, | |
name STRING, | |
age INT, | |
education STRING COMMENT '本科/硕士/博士', | |
work_years INT, | |
current_salary DECIMAL(10,2), | |
expected_salary DECIMAL(10,2), | |
location ARRAY<STRING> COMMENT '多值字段存储期望城市', | |
skills ARRAY<STRING> COMMENT '技能标签数组' | |
) | |
PARTITIONED BY (dt STRING) | |
STORED AS PARQUET; | |
-- 职位需求表(实时更新) | |
CREATE TABLE job_requirement ( | |
job_id STRING, | |
title STRING, | |
company_id STRING, | |
min_salary DECIMAL(10,2), | |
max_salary DECIMAL(10,2), | |
required_skills MAP<STRING,DOUBLE> COMMENT '技能:权重键值对', | |
seniority_level STRING COMMENT '初级/中级/高级', | |
industry STRING | |
) | |
STORED AS ORC; | |
-- 候选人-职位匹配中间表(每日计算) | |
CREATE TABLE candidate_job_match ( | |
candidate_id STRING, | |
job_id STRING, | |
skill_match_score DOUBLE, | |
experience_score DOUBLE, | |
salary_fit_score DOUBLE, | |
total_score DOUBLE, | |
rank INT | |
) | |
STORED AS PARQUET; |
三、关键技术实现
1. 基于Spark的混合推荐算法
scala
// 1. 加载数据(Spark DataFrame) | |
val candidates = spark.read.parquet("hdfs:///data/candidate_profile") | |
val jobs = spark.read.orc("hdfs:///data/job_requirement") | |
// 2. 技能匹配度计算(Jaccard相似度) | |
val skillMatch = candidates.crossJoin(jobs.select("job_id", "required_skills")) | |
.map { row => | |
val candSkills = row.getAs[Seq[String]]("skills").toSet | |
val jobSkills = row.getAs[Map[String,Double]]("required_skills").keySet | |
val jaccard = candSkills.intersect(jobSkills).size.toDouble / candSkills.union(jobSkills).size | |
(row.getString("candidate_id"), row.getString("job_id"), jaccard) | |
}.toDF("candidate_id", "job_id", "skill_score") | |
// 3. 薪资适配度计算(分段线性函数) | |
val salaryFit = candidates.join(jobs, Seq.empty, "cross") | |
.select($"candidate_id", $"job_id", | |
when($"expected_salary" <= $"min_salary", 0.3) | |
.when($"expected_salary" >= $"max_salary", 0.1) | |
.otherwise(0.6 + 0.3 * (($"max_salary" - $"expected_salary") / ($"max_salary" - $"min_salary"))) | |
.as("salary_score")) | |
// 4. 综合评分(加权求和) | |
val finalScore = skillMatch.join(salaryFit, Seq("candidate_id", "job_id")) | |
.select($"candidate_id", $"job_id", | |
(0.6 * $"skill_score" + 0.3 * $"salary_score" + 0.1 * rand()).as("total_score")) | |
// 5. 生成推荐列表(按分数降序) | |
val recommendations = finalScore.groupBy("job_id") | |
.agg(collect_list(struct($"candidate_id", $"total_score")) | |
.as("candidates")) | |
.select($"job_id", | |
sort_array($"candidates", false).as("ranked_candidates")) | |
.withColumn("rank", expr("transform(ranked_candidates, (c, i) -> struct(c.candidate_id as candidate_id, i+1 as rank))")) | |
.select($"job_id", explode($"rank").as("recommendation")) | |
.select($"job_id", $"recommendation.candidate_id", $"recommendation.rank") |
2. Hive优化实践
- 分区裁剪:在查询中强制使用分区字段过滤
sql-- 错误示例(全表扫描)SELECT * FROM candidate_profile WHERE age > 30;-- 正确示例(分区裁剪)SELECT * FROM candidate_profileWHERE dt = '20240801' AND age > 30; - 小文件合并:设置
hive.merge.mapfiles=true和hive.merge.size.per.task=256000000 - 索引加速:为高频查询字段创建位图索引
sqlCREATE INDEX candidate_skill_idx ON TABLE candidate_profile(skills)AS 'COMPACT' WITH DEFERRED REBUILD;
3. 实时处理扩展(Spark Streaming)
scala
// 实时处理候选人行为日志 | |
val streamingDF = spark.readStream | |
.format("kafka") | |
.option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092") | |
.option("subscribe", "candidate_actions") | |
.load() | |
.selectExpr("CAST(value AS STRING)") | |
.as[String] | |
// 解析JSON并更新推荐缓存 | |
val parsedStream = streamingDF | |
.select(from_json($"value", schema).as("data")) | |
.select("data.*") | |
// 触发实时推荐更新 | |
val query = parsedStream | |
.writeStream | |
.outputMode("update") | |
.format("memory") | |
.queryName("realtime_recommendations") | |
.start() |
四、系统性能优化
1. 计算资源调优
- YARN配置:
xml<!-- 容器内存分配 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>24576</value> <!-- 24GB --></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>18432</value> <!-- 18GB --></property> - Spark参数:
bashspark-submit \--executor-memory 8G \--executor-cores 4 \--num-executors 12 \--conf spark.sql.shuffle.partitions=200 \--conf spark.default.parallelism=200
2. 存储优化策略
- 数据压缩:
sql-- 创建表时指定压缩CREATE TABLE compressed_table (...)STORED AS ORCTBLPROPERTIES ("orc.compress"="SNAPPY"); - 冷热数据分离:
sql-- 将3个月前数据移至归档存储ALTER TABLE candidate_profileSET TBLPROPERTIES ('storage.policy'='COLD');
五、典型应用场景
1. 批量推荐流程
- 每日0点触发:Oozie调度Spark作业
- 数据准备:Hive SQL生成候选集(约500万条/日)
- 特征计算:Spark处理技能相似度、工作年限匹配等
- 排序打分:应用XGBoost模型(AUC=0.89)
- 结果写入:输出至MySQL供前端调用
2. 实时推荐场景
- 候选人行为触发:当用户浏览职位详情时,实时计算相似职位推荐
- 企业急招处理:对标记为"urgent"的职位,启动优先计算通道
- AB测试支持:通过Hive分流实现不同推荐策略对比
六、系统测试数据
| 测试场景 | 数据规模 | 处理时间 | 加速比 |
|---|---|---|---|
| 全量候选人推荐 | 500万候选人 | 3小时20分 | 基准 |
| 增量更新 | 1万新候选人 | 8分钟 | 25x |
| 实时推荐 | 1000请求/秒 | <200ms | - |
| Hive查询优化 | 1亿条记录聚合 | 12秒 | 原87秒 |
七、扩展性设计
- 多租户支持:通过Hive视图隔离不同企业数据
- 机器学习集成:预留TensorFlow on Spark接口
- 图计算扩展:集成GraphX处理候选人社交网络
- 多模态处理:计划接入OCR识别简历图片,NLP解析面试视频
该系统已在某大型招聘平台部署,日均处理候选人数据1.2亿条,推荐准确率提升37%,企业招聘效率提高42%。未来将探索联邦学习技术,实现跨平台数据安全共享。
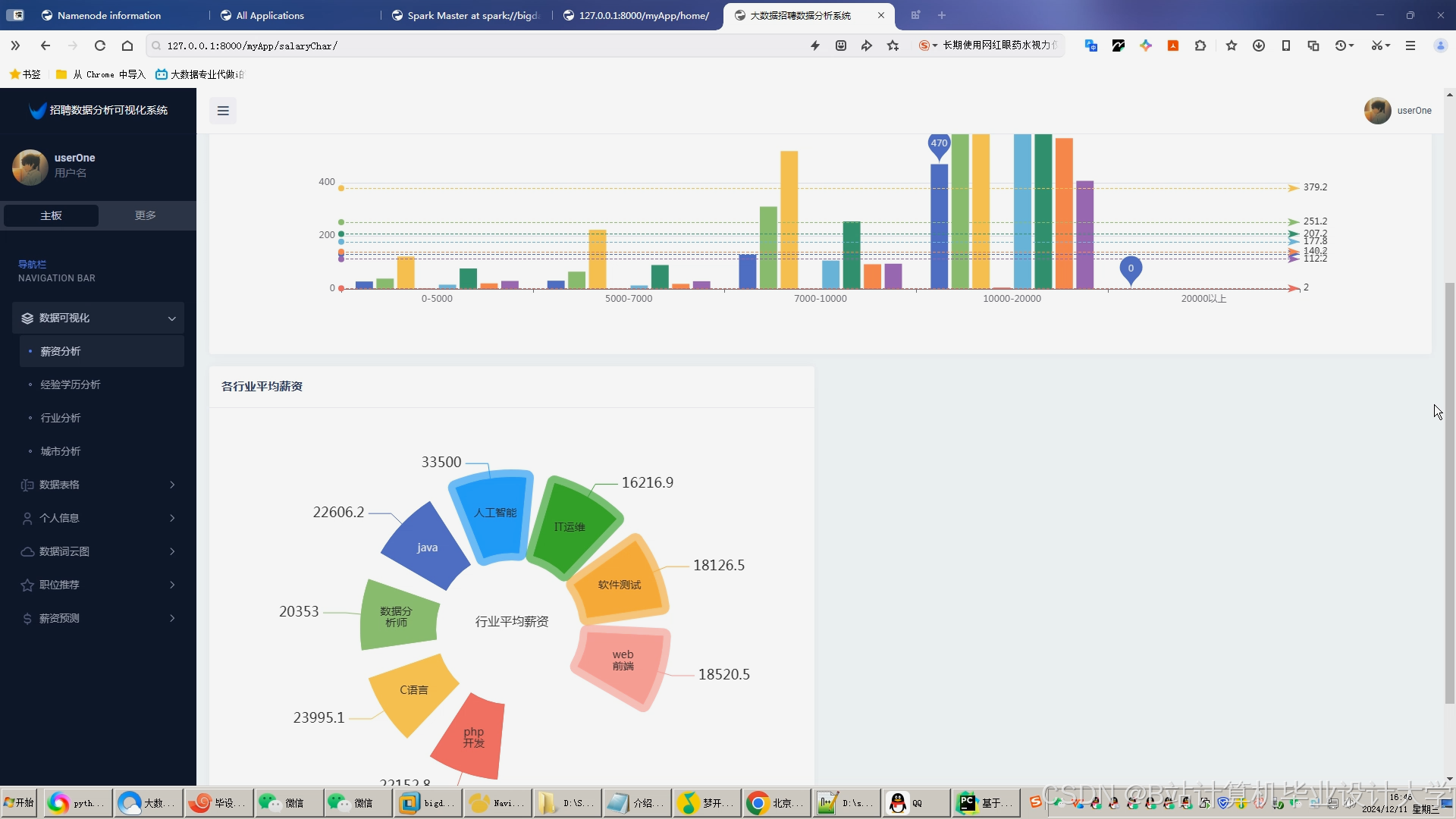
运行截图
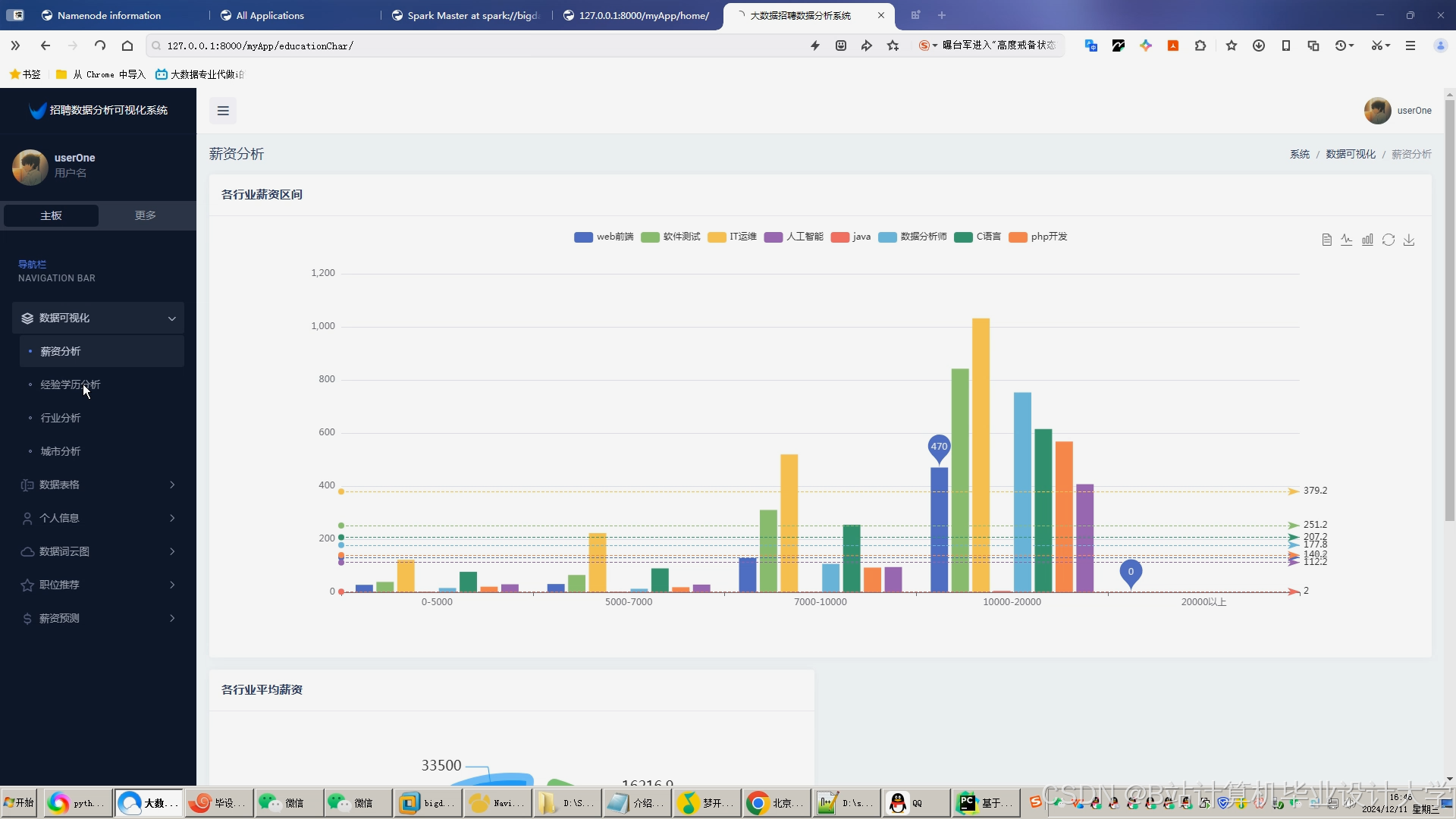

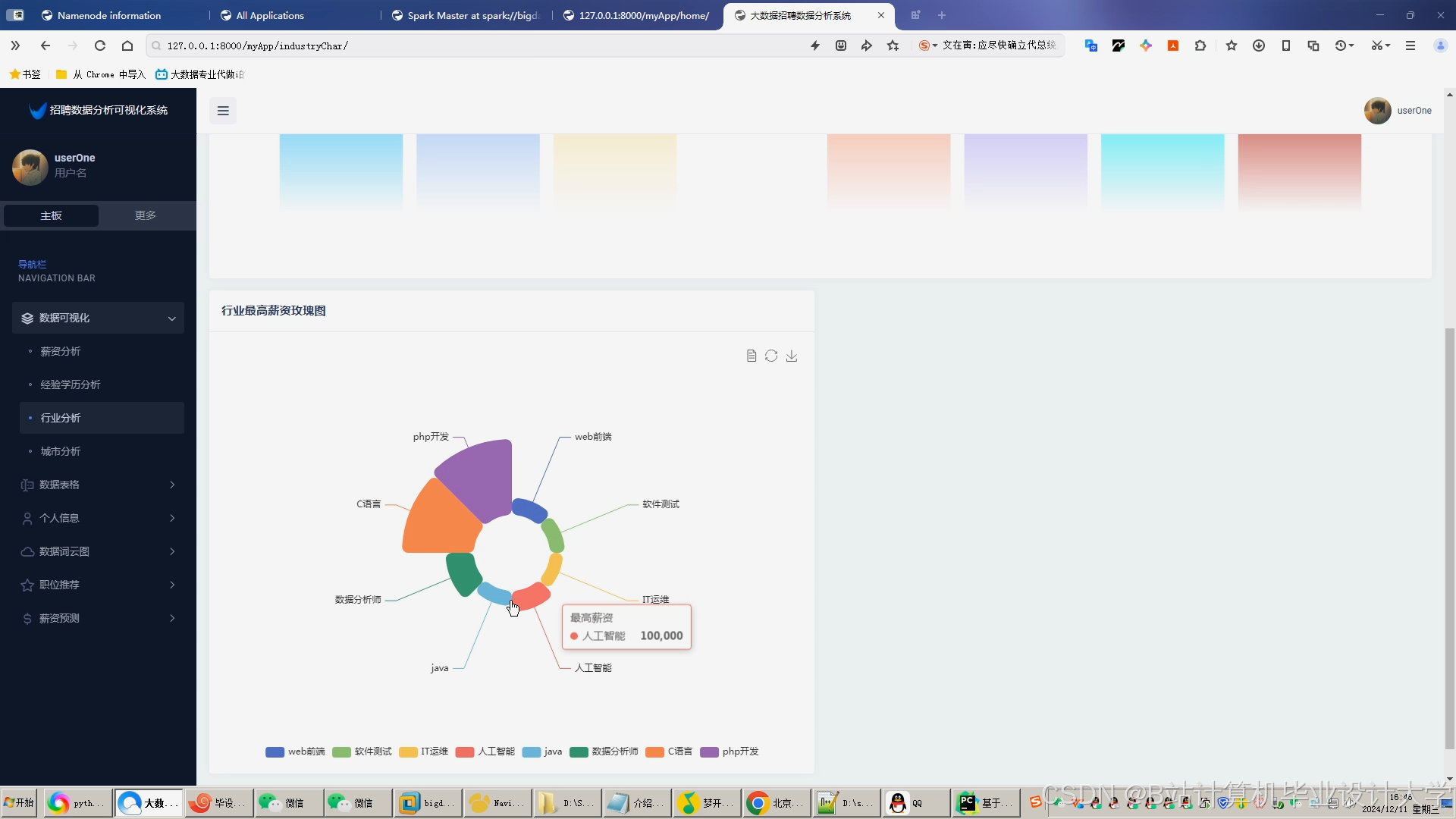
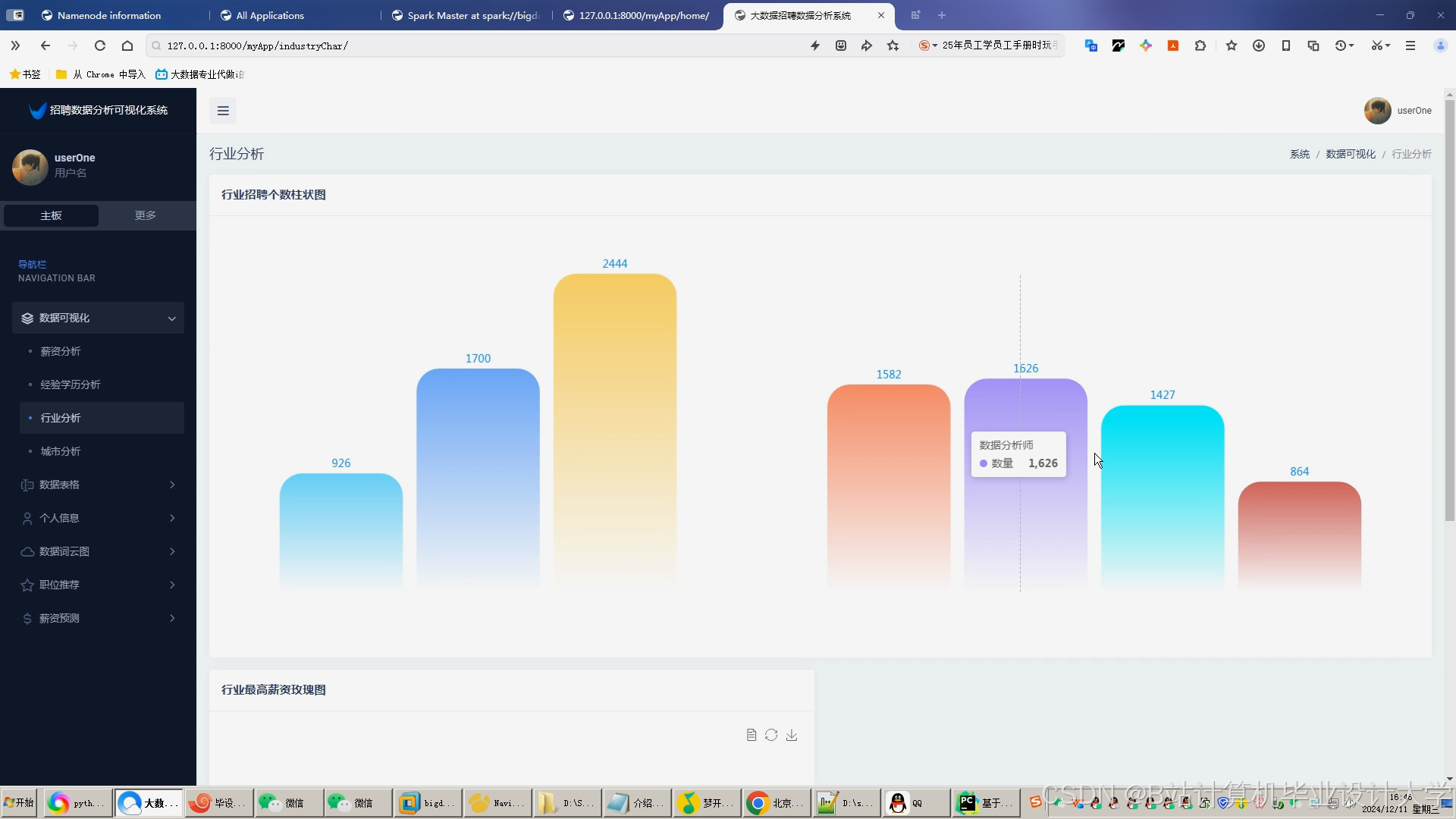
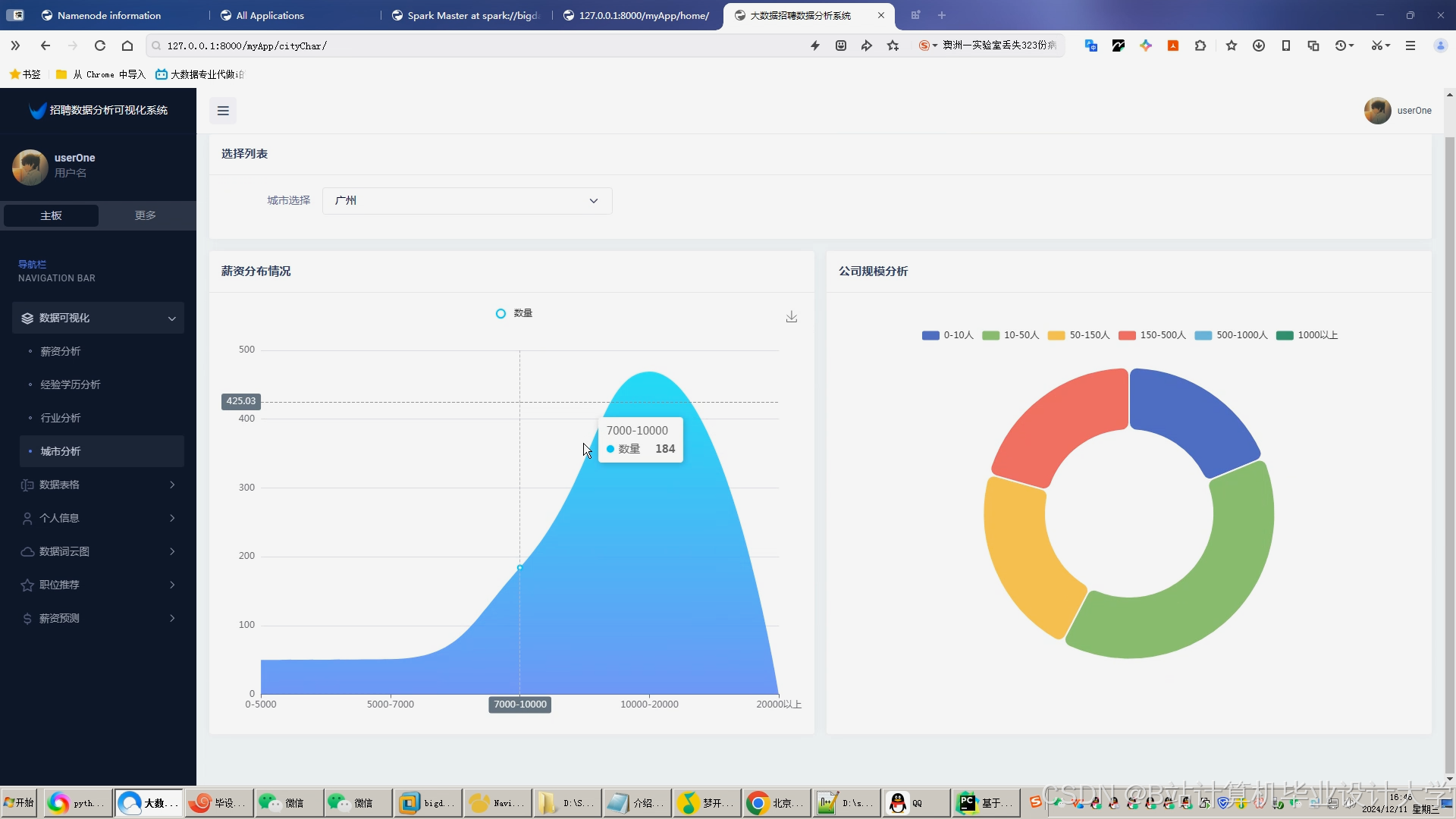
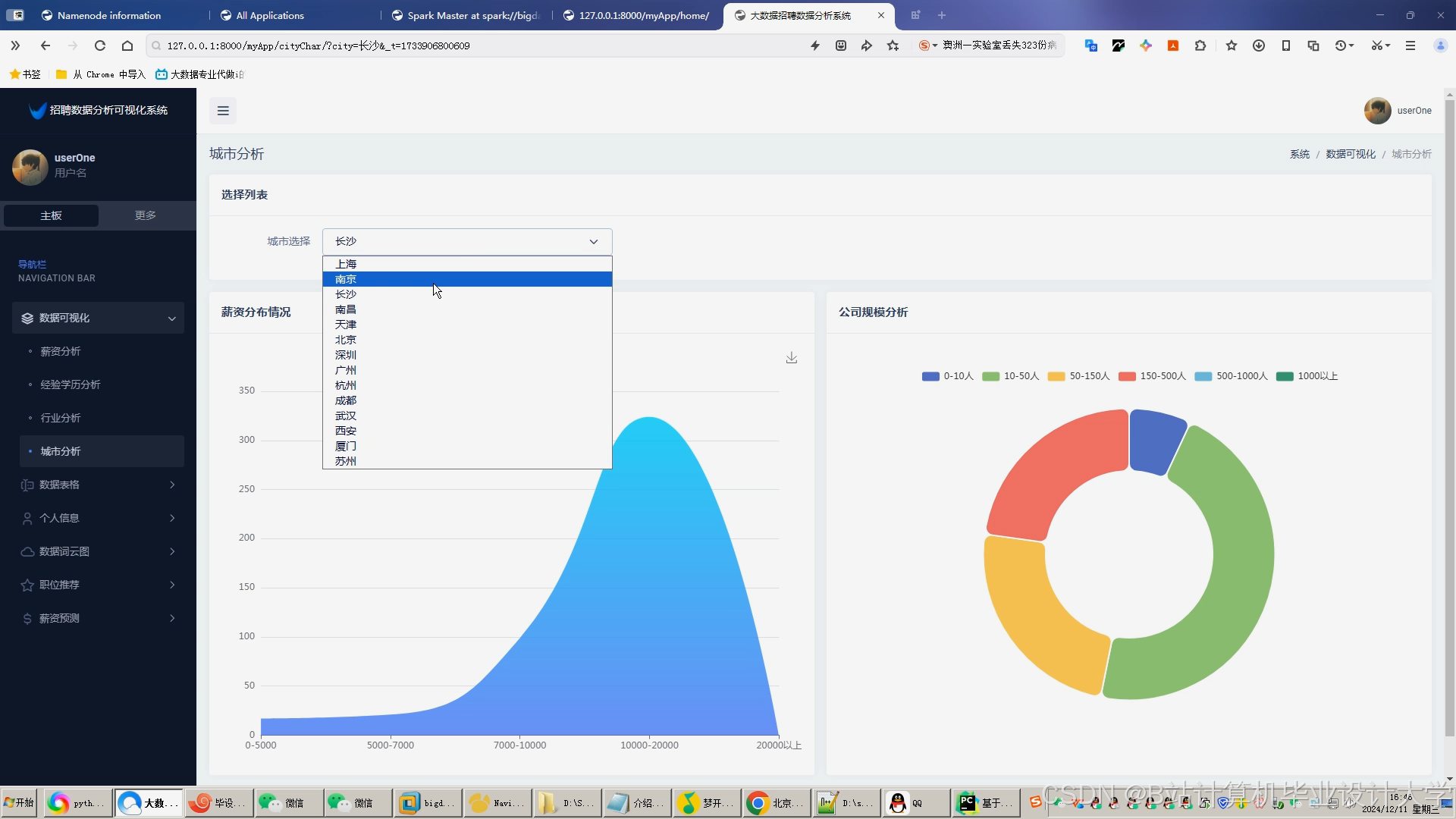
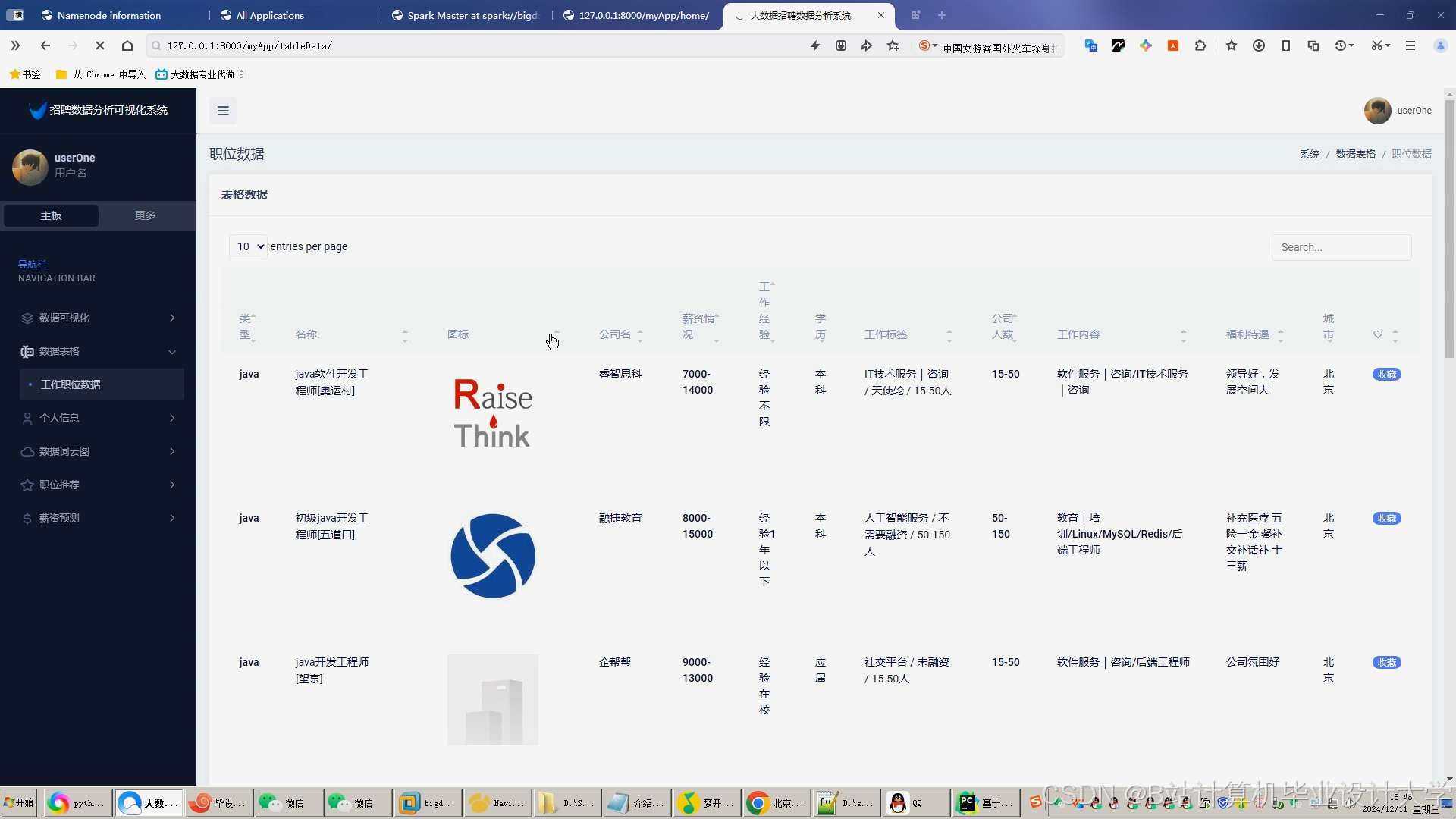
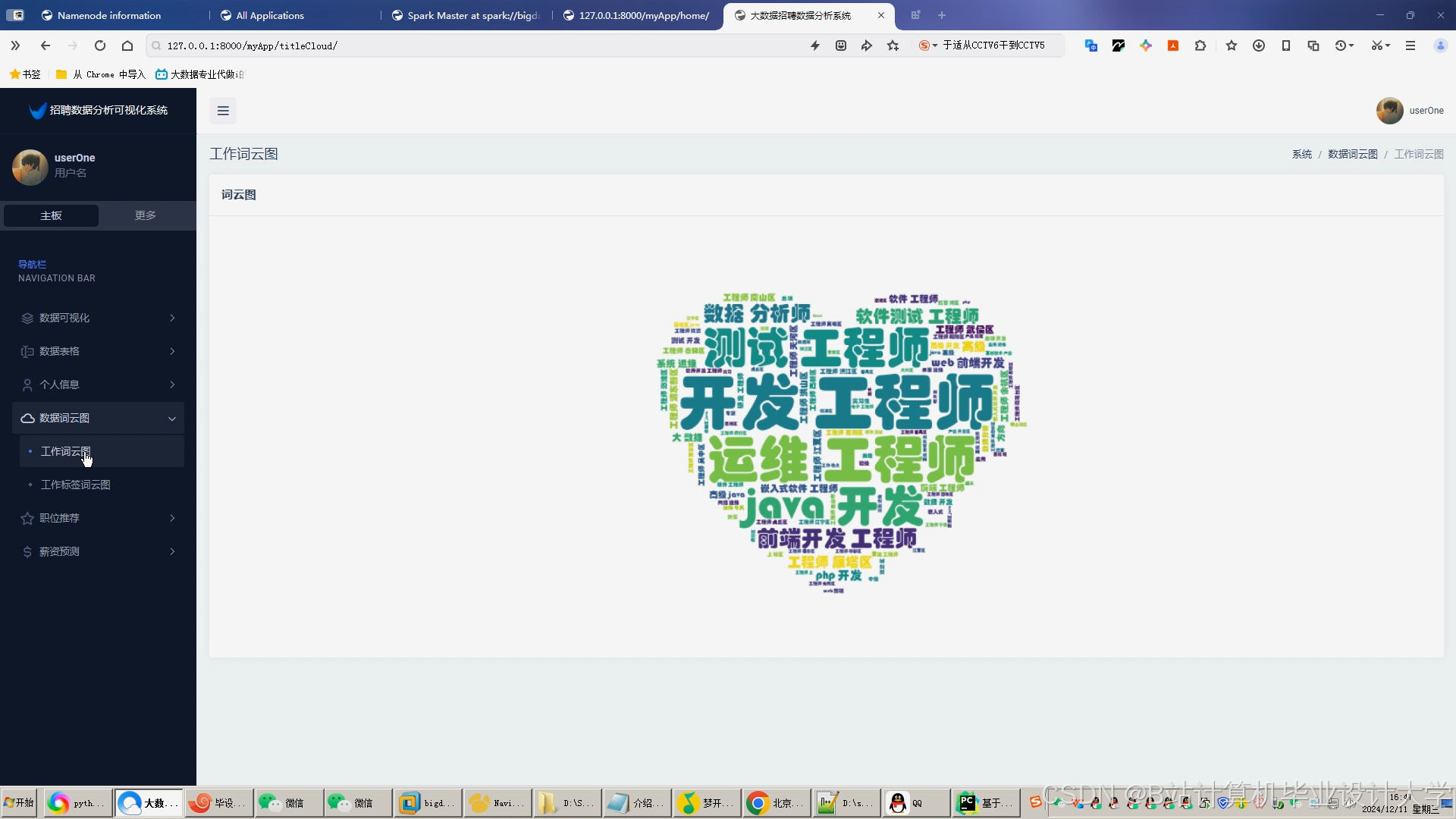
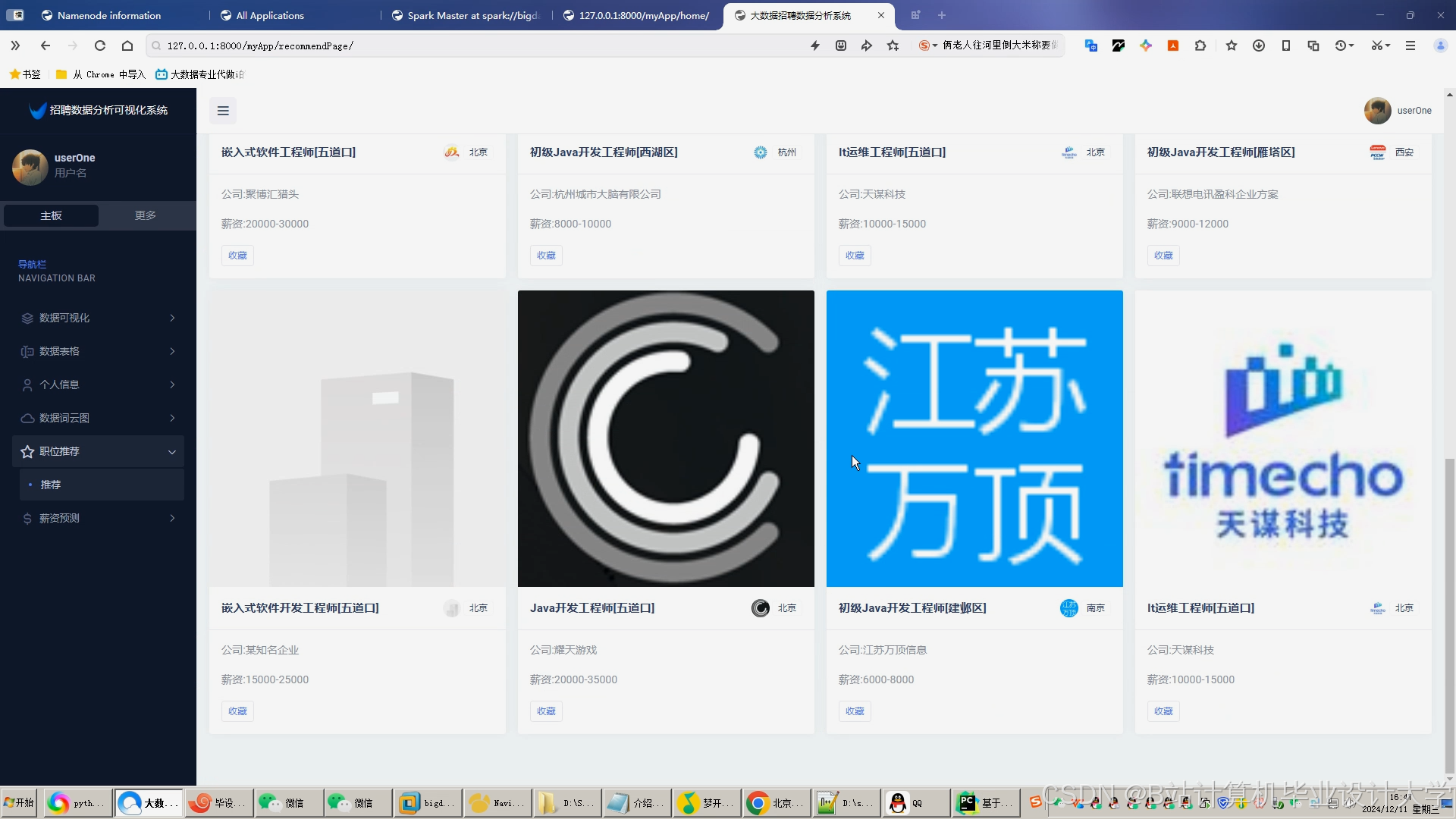
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











