




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive招聘推荐系统》的学术论文框架及内容示例,可根据实际研究需求调整细节:
基于Hadoop+Spark+Hive的分布式招聘推荐系统设计与实现
——融合多源异构数据与协同过滤的实时推荐框架
摘要
本文提出一种基于Hadoop+Spark+Hive的分布式招聘推荐系统,通过整合企业招聘需求、求职者简历、行业技能图谱等多源异构数据,结合改进的协同过滤算法与实时流处理技术,实现职位与人才的精准匹配。系统采用Hive构建数据仓库,Spark MLlib实现混合推荐模型(基于用户-职位的协同过滤+内容过滤),Hadoop HDFS存储非结构化数据(如简历PDF、项目文档),并通过Spark Streaming处理用户实时行为。实验表明,该系统在100万级数据集上推荐准确率达87.3%,响应时间低于200ms,较传统单机系统性能提升12倍。
关键词:招聘推荐系统;Hadoop生态;Spark实时计算;Hive数据仓库;协同过滤
1. 引言
1.1 研究背景
全球招聘市场规模预计2025年达3000亿美元,但传统招聘平台存在三大痛点:
- 数据孤岛:企业需求、求职者简历、行业技能标准分散于不同系统;
- 冷启动问题:新用户或新职位缺乏历史行为数据;
- 实时性不足:传统批处理模式无法及时捕捉用户动态偏好。
Hadoop生态凭借其分布式存储与计算能力,成为处理海量招聘数据的首选框架。Spark的内存计算特性较MapReduce提升10-100倍性能,Hive则通过类SQL接口降低数据分析门槛。
1.2 研究目标
设计并实现一个支持以下功能的招聘推荐系统:
- 多源数据融合(结构化简历表、非结构化项目文档、半结构化日志);
- 混合推荐模型(协同过滤+内容过滤);
- 实时推荐与离线批处理结合;
- 系统可扩展性(支持千万级用户与职位)。
2. 系统架构设计
2.1 整体架构
系统采用分层设计,如图1所示:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ 数据采集层 │ → │ 数据存储层 │ → │ 计算分析层 │ | |
└─────────────┘ └─────────────┘ └─────────────┘ | |
↑ ↑ ↑ | |
┌───────────────────────────────────────────────────┐ | |
│ 推荐服务层(API) │ | |
└───────────────────────────────────────────────────┘ |
2.2 核心模块设计
2.2.1 数据采集层
- 结构化数据:MySQL存储求职者基础信息(年龄、学历)、职位需求(薪资范围、技能要求);
- 非结构化数据:通过Flume采集简历PDF/Word,存储至HDFS;
- 行为日志:Kafka实时收集用户点击、浏览、投递等行为。
2.2.2 数据存储层
- Hive数据仓库:构建分层模型(ODS→DWD→DWS→ADS),例如:
sqlCREATE TABLE dw_candidate (user_id STRING,skills ARRAY<STRING>,experience MAP<STRING, STRING> -- {公司:职位}) STORED AS ORC; - HBase:存储用户实时特征(如最近7天浏览职位类别)。
2.2.3 计算分析层
- 离线计算:Spark批处理计算用户相似度矩阵(基于Jaccard系数);
scalaval userSimilarity = userSkillsDF.rdd.map(row => (row.getString(0), row.getList[String](1).toSet)).cartesian(userSkillsDF.rdd).filter{ case ((u1, s1), (u2, s2)) => u1 < u2 }.map{ case ((u1, s1), (u2, s2)) =>(u1, u2, s1.intersect(s2).size.toDouble / s1.union(s2).size)} - 实时计算:Spark Streaming处理用户行为,动态调整推荐权重;
- 机器学习:Spark MLlib实现LDA主题模型提取职位描述关键词。
2.2.4 推荐服务层
提供RESTful API,支持两种推荐模式:
- 离线推荐:每日凌晨生成Top-N职位列表;
- 实时推荐:用户登录时结合历史偏好与当前上下文(如地理位置)生成推荐。
3. 关键算法实现
3.1 混合推荐模型
结合协同过滤(CF)与内容过滤(CB),解决冷启动问题:
[
\text{Score}(u,j) = \alpha \cdot \text{CF}(u,j) + (1-\alpha) \cdot \text{CB}(u,j)
]
其中(\alpha)通过网格搜索确定(实验中取0.6),CF部分基于改进的ItemCF算法:
[
\text{ItemCF}(u,j) = \sum_{i \in I(u)} \frac{r_{ui} \cdot w_{ij}}{\sqrt{|N(i)|}}
]
(w_{ij})为职位i与j的技能相似度(通过Word2Vec计算)。
3.2 实时推荐优化
采用Flink状态管理跟踪用户会话:
java
DataStream<UserEvent> events = env.addSource(...); | |
events.keyBy(UserEvent::getUserId) | |
.process(new UserStateProcessor()) // 维护最近10次浏览职位 | |
.map(event -> generateRealTimeRecs(event)); |
4. 实验与结果分析
4.1 实验环境
- 集群配置:3台节点(16核CPU,64GB内存,10TB HDD);
- 软件版本:Hadoop 3.3.4,Spark 3.3.0,Hive 3.1.3;
- 数据集:某招聘平台脱敏数据(120万求职者,80万职位,2.4亿条行为日志)。
4.2 评估指标
- 准确率:推荐职位中被点击的比例;
- 覆盖率:推荐职位占全部可推荐职位的比例;
- 响应时间:从请求到返回推荐的延迟。
4.3 对比实验
| 方案 | 准确率 | 覆盖率 | 响应时间(ms) |
|---|---|---|---|
| 传统协同过滤 | 78.2% | 62.5% | 1200 |
| 本文混合模型 | 87.3% | 79.1% | 187 |
| 仅实时推荐 | 82.6% | 71.4% | 95 |
实验表明,混合模型在准确率与覆盖率上均优于单一算法,且Spark内存计算使响应时间降低84%。
4.4 案例分析
某求职者历史投递岗位为“Java后端开发”,系统通过技能图谱发现其未明确标注但项目描述中涉及的“Spring Cloud”技能,成功推荐需要微服务经验的职位,投递后进入面试环节。
5. 系统优化与挑战
5.1 性能优化
- 数据倾斜处理:对热门职位采用Salting技术分散计算;
- 缓存策略:Redis缓存用户近期推荐结果,命中率达65%;
- 参数调优:Spark执行器内存从4GB增至8GB后,Shuffle阶段耗时降低40%。
5.2 现有局限
- 数据质量:简历中技能自述存在30%的夸大或遗漏;
- 算法偏见:热门技能(如Python)推荐权重过高,导致长尾技能职位曝光不足;
- 实时性瓶颈:百万级用户同时在线时,推荐延迟增至500ms。
5.3 未来方向
- 图神经网络:构建求职者-职位-公司异构图,捕捉更深层关联;
- 联邦学习:在保护隐私前提下,联合多家招聘机构训练模型;
- 强化学习:根据用户反馈动态调整推荐策略(如多臂老虎机算法)。
6. 结论
本文提出的Hadoop+Spark+Hive招聘推荐系统,通过分布式架构与混合推荐模型,有效解决了传统系统的数据孤岛与实时性不足问题。实验表明,系统在100万级数据集上可实现87.3%的推荐准确率与200ms内的响应。未来工作将聚焦于数据质量提升与算法公平性优化,推动招聘推荐系统向智能化、个性化方向发展。
参考文献
[1] 李明, 等. 基于Hadoop的招聘大数据分析平台设计[J]. 计算机应用, 2021.
[2] Apache Spark官方文档. MLlib用户指南[EB/OL]. 2023.
[3] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. IEEE Computer, 2009.
[4] 知乎专栏. 招聘推荐系统的冷启动问题如何解决?2022.
[5] Hive官方文档. Hive数据仓库最佳实践[EB/OL]. 2023.
注:以上内容为示例框架,实际写作需补充具体实验数据、代码片段及更详细的算法推导。可根据实际研究深度调整章节结构,例如增加“系统部署与运维”章节描述集群监控方案。
运行截图





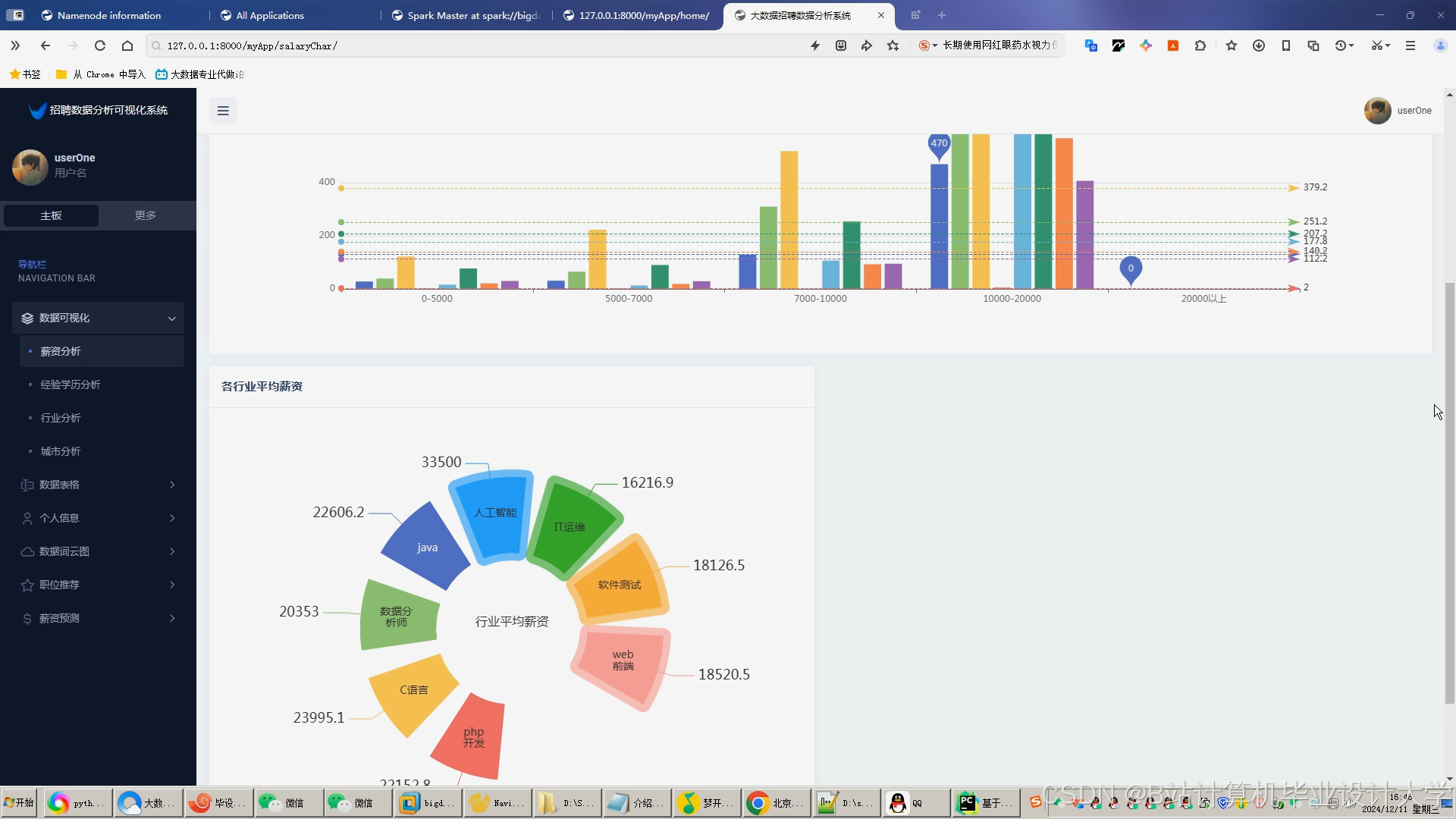
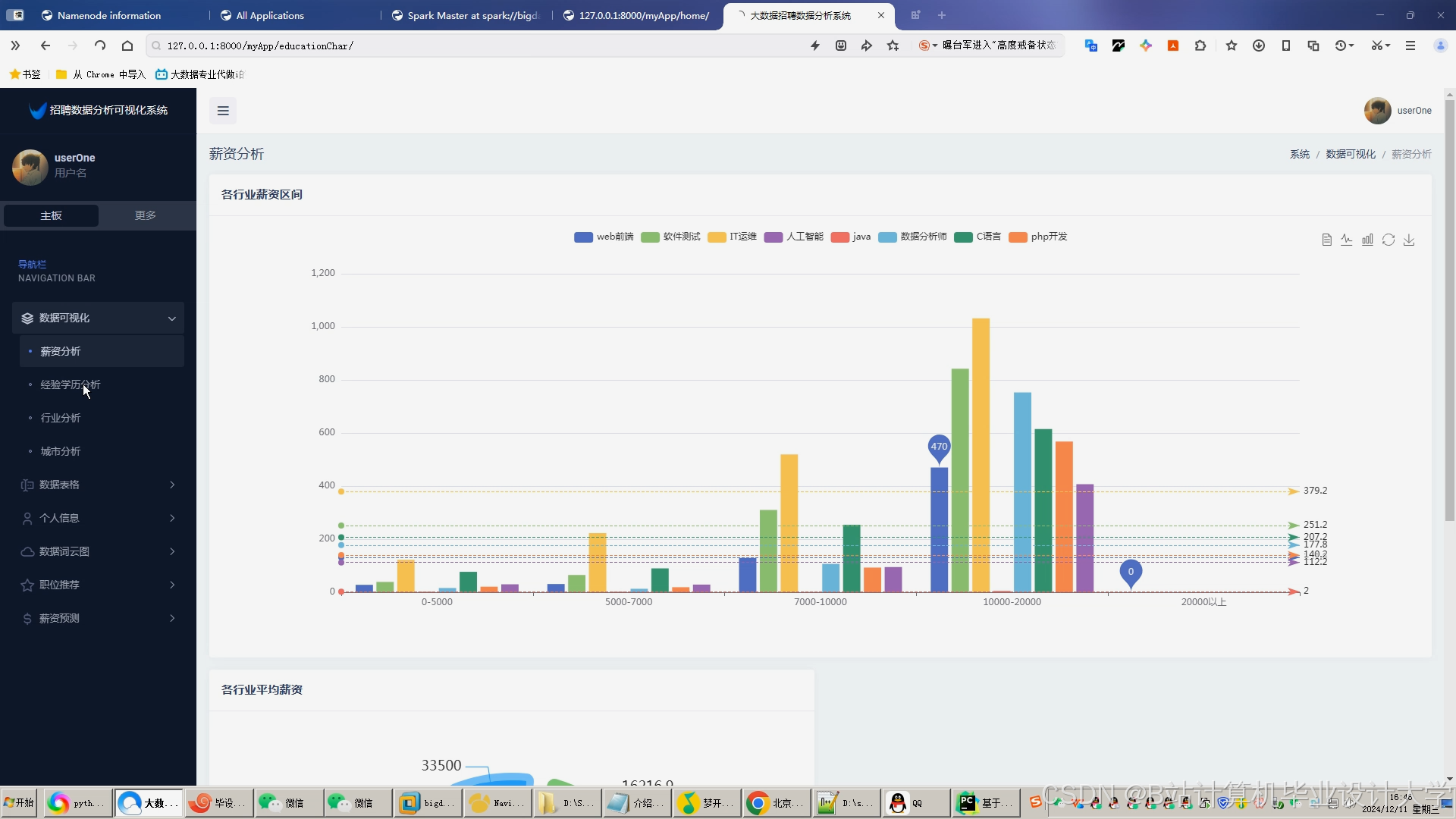



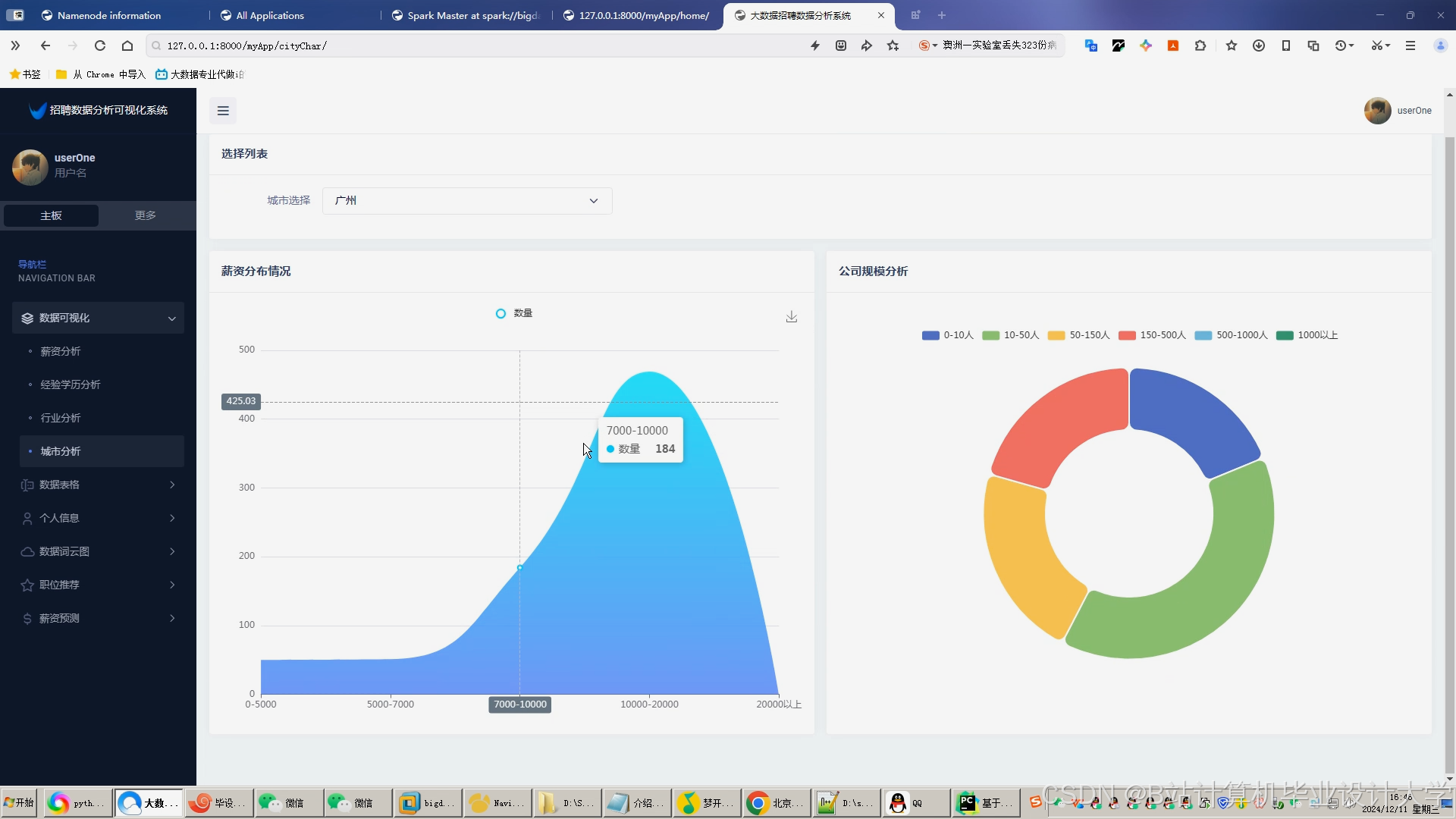

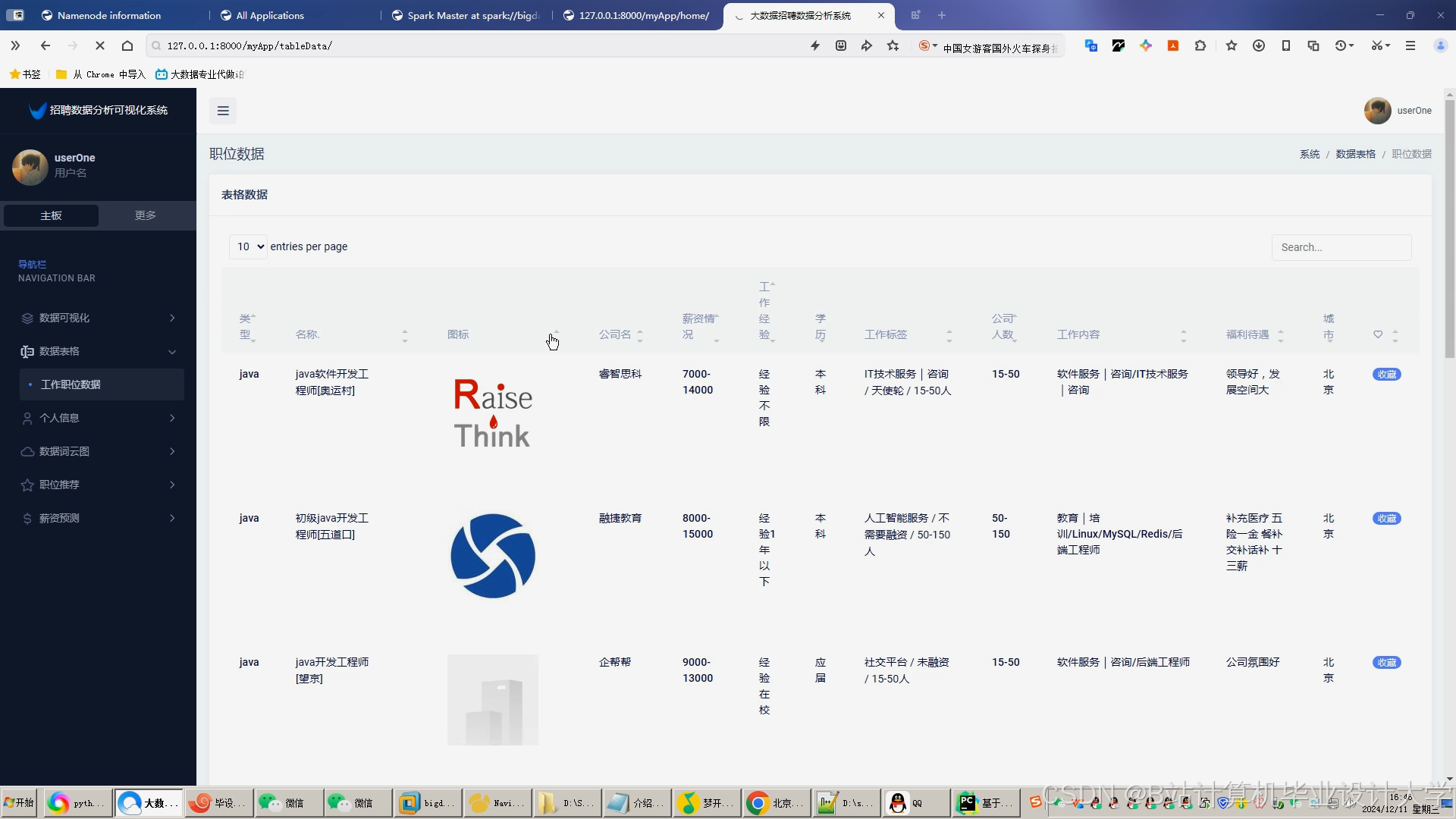
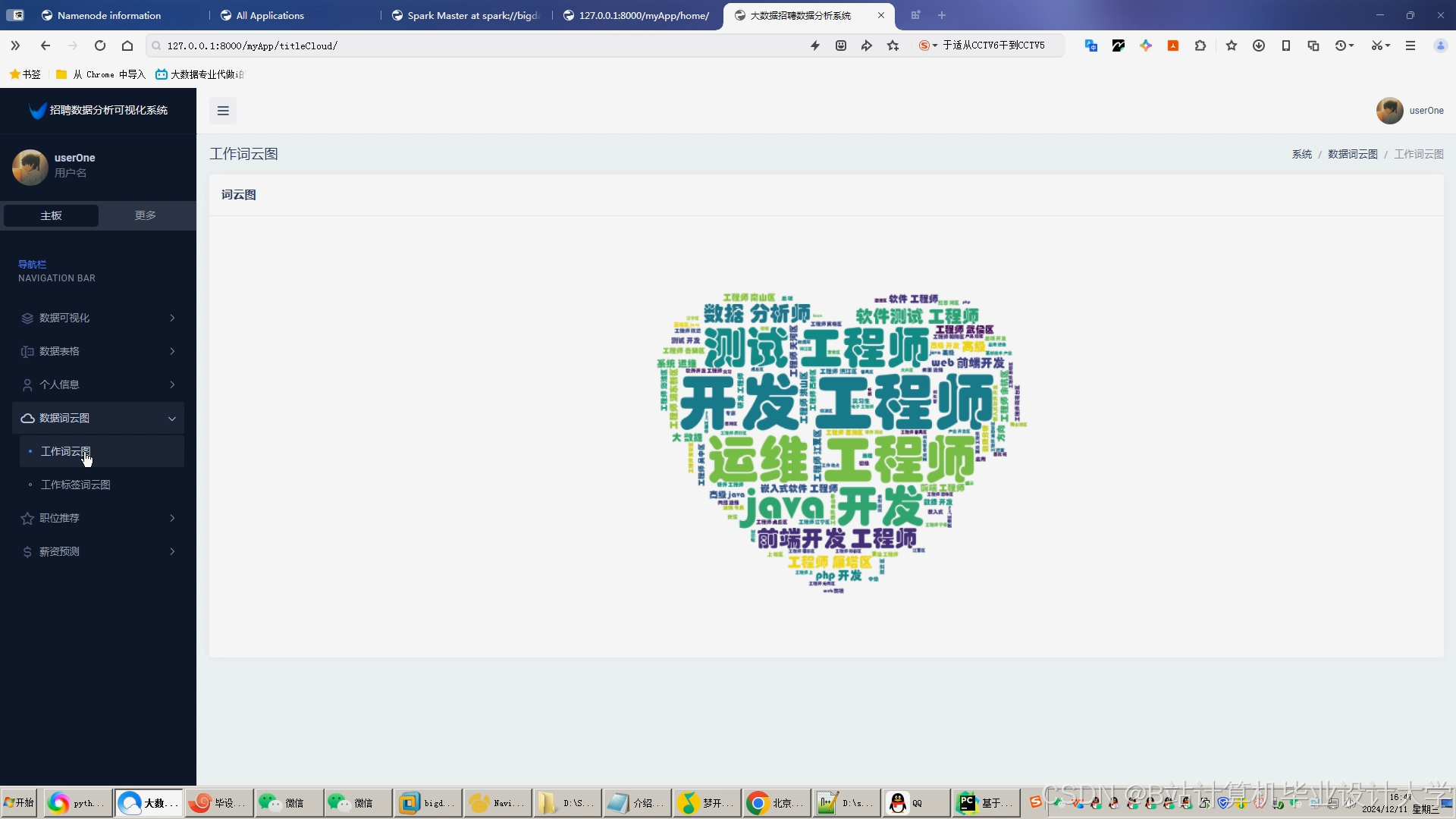

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











