




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+PySpark+Hadoop图书推荐系统》的开题报告范例,供参考:
开题报告
题目:基于Python、PySpark与Hadoop的分布式图书推荐系统设计与实现
一、研究背景与意义
-
背景
随着电子商务和数字图书馆的快速发展,图书推荐系统成为提升用户体验和平台收益的关键工具。传统推荐系统(如基于协同过滤或内容过滤的算法)在处理海量数据时面临性能瓶颈,而分布式计算框架(如Hadoop、Spark)可有效解决这一问题。
Python凭借其丰富的机器学习库(如Scikit-learn、Surprise)和易用性成为推荐系统开发的热门语言;PySpark作为Spark的Python接口,支持大规模数据的高效处理;Hadoop则提供分布式存储(HDFS)和资源调度(YARN)能力。三者结合可构建高并发、可扩展的图书推荐系统。 -
意义
- 技术层面:探索Python生态与分布式计算框架的融合,验证PySpark在推荐算法中的加速效果。
- 应用层面:通过分布式处理海量图书数据(如用户行为、图书元数据),提升推荐实时性与准确性。
- 学术价值:为分布式推荐系统在图书领域的应用提供理论支持与实践案例。
二、国内外研究现状
- 图书推荐系统
- 国外:Amazon、Goodreads等平台采用混合推荐算法(协同过滤+内容过滤),结合用户评分、浏览历史等数据。
- 国内:当当网、豆瓣读书通过社交关系链(如好友书单)优化推荐效果,但缺乏对分布式架构的深度应用。
- 分布式推荐技术
- Hadoop生态:Mahout项目提供基于MapReduce的推荐算法实现,但迭代计算效率较低。
- Spark生态:MLlib库支持ALS(交替最小二乘法)等矩阵分解算法,利用内存计算显著提升性能。
- 现有问题:现有系统多聚焦于算法优化,忽视图书内容特征(如文本语义、主题模型)与用户行为的融合分析。
三、研究目标与内容
- 研究目标
- 设计并实现一个基于Python+PySpark+Hadoop的分布式图书推荐系统,支持海量数据的高效处理。
- 融合用户行为数据与图书内容特征(如文本摘要、主题分布),提升推荐多样性。
- 通过实验验证分布式架构对推荐性能(响应时间、吞吐量)的优化效果。
- 研究内容
- 数据层:
- 利用Hadoop HDFS存储用户行为日志(点击、购买、评分)和图书元数据(标题、作者、简介)。
- 使用Hive/Spark SQL构建数据仓库,支持结构化查询。
- 算法层:
- 基于PySpark实现ALS协同过滤算法,处理用户-图书评分矩阵。
- 结合TF-IDF或BERT模型提取图书文本特征,构建基于内容的推荐模块。
- 设计混合推荐策略(加权融合或级联融合),平衡精准度与多样性。
- 服务层:
- 使用Flask/FastAPI构建RESTful接口,提供推荐结果查询服务。
- 通过Kafka实现用户实时行为数据的流式处理(如新增评分)。
- 可视化层:
- 基于Matplotlib/Plotly展示推荐结果分布、算法性能对比等分析图表。
- 数据层:
四、研究方法与技术路线
- 研究方法
- 文献调研:分析分布式推荐算法与图书领域特征的最新研究。
- 系统设计:采用分层架构(数据层、算法层、服务层),模块间通过API解耦。
- 实验验证:在公开数据集(如Book-Crossing、Amazon Book Reviews)上测试推荐准确率(RMSE、MAE)和系统吞吐量。
- 技术路线
数据源(用户行为日志、图书元数据)↓Hadoop HDFS(分布式存储)↓PySpark(数据清洗、特征提取、推荐算法)↓Flask API(推荐服务接口)↓前端应用(Web/移动端展示)
五、预期成果与创新点
- 预期成果
- 完成系统原型开发,支持千万级图书数据的实时推荐。
- 在CCF-C类会议或核心期刊发表1篇论文,申请1项软件著作权。
- 创新点
- 分布式混合推荐:结合PySpark的内存计算优势与Hadoop的存储能力,实现大规模数据下的低延迟推荐。
- 多模态特征融合:将图书文本语义、用户评分、时间衰减因子等多维度数据纳入推荐模型。
- 动态调参机制:基于Spark MLlib的Hyperopt库自动优化算法参数(如隐特征维度、正则化系数)。
六、进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 需求分析 | 第1-2周 | 调研图书推荐场景需求,确定功能模块 |
| 环境搭建 | 第3-4周 | 配置Hadoop+Spark集群,测试数据吞吐量 |
| 数据处理 | 第5-6周 | 完成数据清洗、特征提取与存储设计 |
| 算法实现 | 第7-10周 | 实现ALS、基于内容的推荐及混合策略 |
| 系统集成 | 第11-12周 | 开发API服务,完成前后端联调 |
| 测试优化 | 第13-14周 | 性能调优,撰写论文与结题报告 |
七、参考文献
[1] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009.
[2] Apache Spark Documentation. https://spark.apache.org/docs/latest/
[3] Ziegler C N, et al. Improving Recommendation Lists Through Topic Diversification[C]. WWW, 2005.
[4] Book-Crossing Dataset. http://www2.informatik.uni-freiburg.de/~cziegler/BX/
[5] Mnih A, Salakhutdinov R R. Probabilistic Matrix Factorization[C]. NIPS, 2007.
备注:
- 可根据实际数据规模调整技术选型(如用Spark Streaming替代Kafka处理实时数据)。
- 建议补充集群资源消耗(CPU、内存)的量化分析,增强可行性论证。
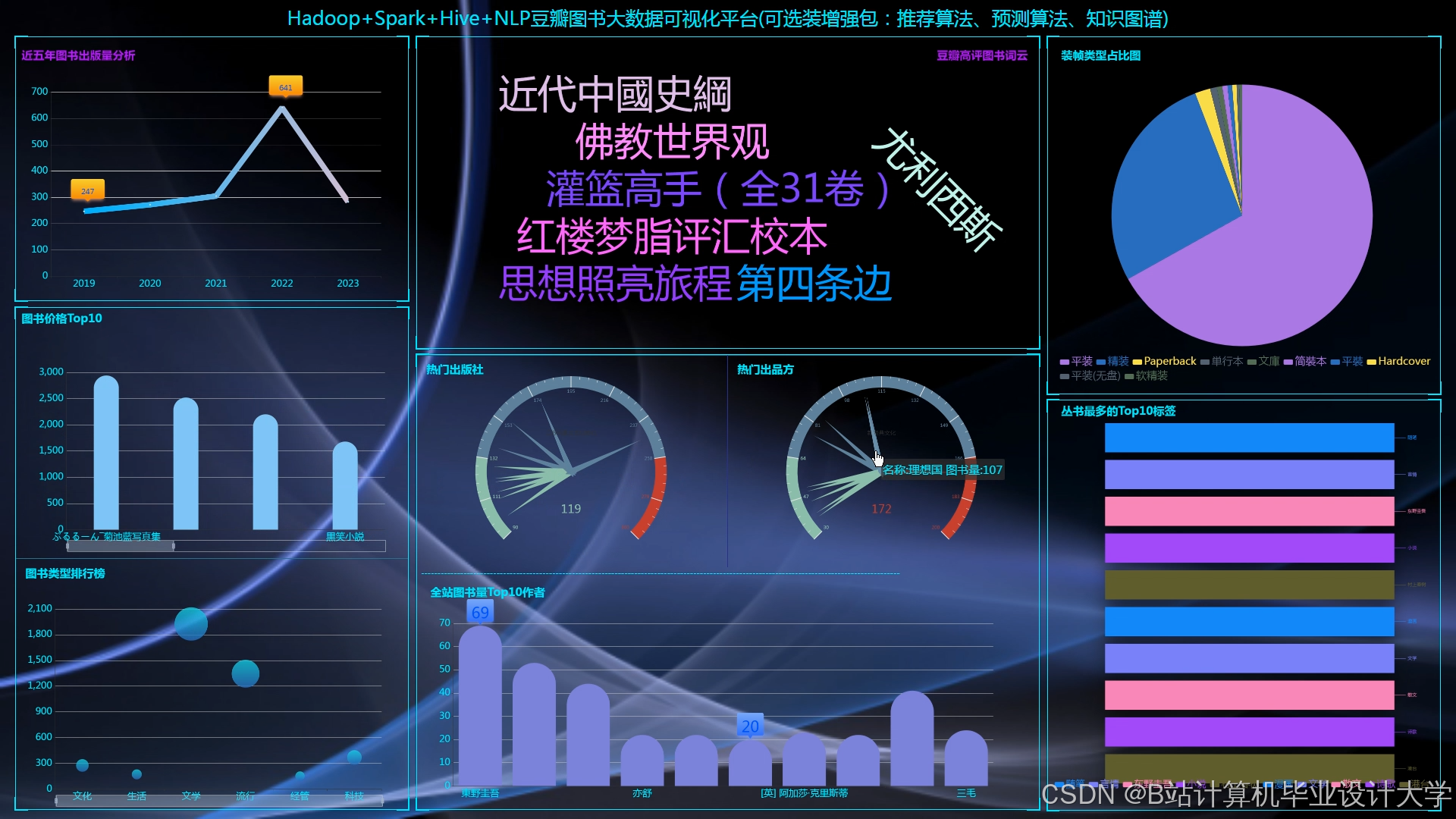
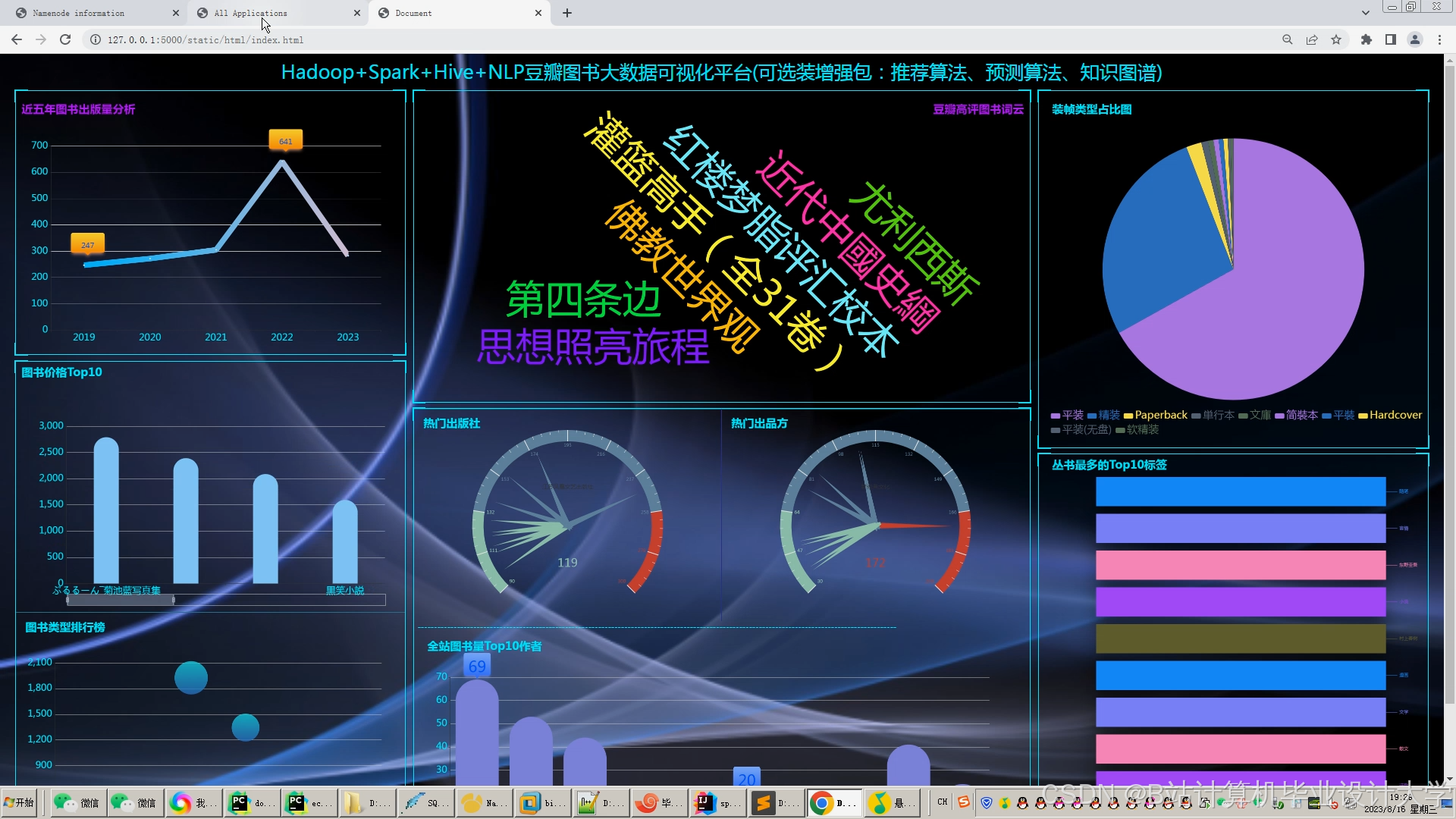
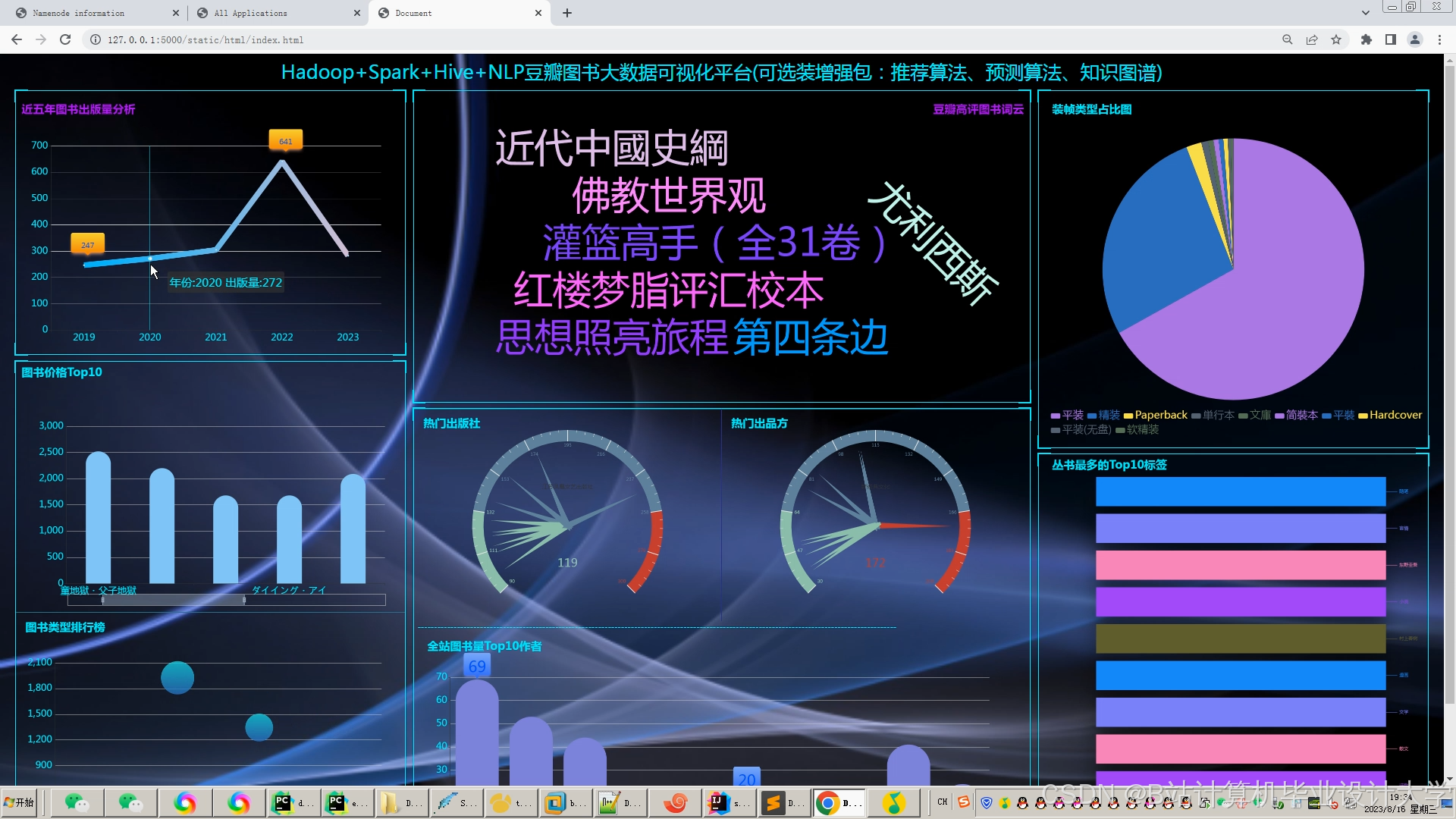
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











