




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份针对《PyFlink+PySpark+Hadoop+Hive旅游景点推荐系统》的任务书模板,结合实时流处理、离线特征工程与多源数据融合,设计旅游场景下的个性化推荐方案:
任务书:基于PyFlink+PySpark+Hadoop+Hive的旅游景点推荐系统
一、项目背景与目标
1. 背景
旅游平台面临用户兴趣动态变化、景点冷启动难、实时推荐延迟高等问题。例如:
- 用户A在雨天搜索“室内景点”后,需立即推荐博物馆、展览馆;
- 新上线景点因缺乏历史数据难以进入推荐列表。
需结合PyFlink实时流处理(捕捉用户即时需求)与PySpark离线特征工程(挖掘长期兴趣),构建混合推荐系统,提升用户决策效率(目标:用户从搜索到预订的平均时间缩短30%)。
2. 目标
- 数据层:
- 构建Hadoop+Hive数据仓库,整合用户行为、景点元数据、天气、交通等多源异构数据。
- 使用PyFlink实时采集用户搜索、点击、预订等行为,延迟<2秒。
- 推荐层:
- 实时推荐:基于PyFlink的CEP(复杂事件处理)规则,实现“用户实时行为→场景化推荐”闭环(如“雨天+搜索‘景点’→推荐室内场馆”)。
- 离线推荐:基于PySpark聚合特征(如“用户过去30天访问景点类型分布”)训练LightGBM多目标模型(优化点击率与预订转化率)。
- 分析层:
- 通过Grafana监控推荐转化率(CTR)、冷启动景点曝光量等指标。
- 使用Superset分析用户兴趣迁移(如“从自然风光转向历史文化景点的用户占比”)。
二、项目任务与分工
1. 多源数据采集与存储(Hadoop+Hive+PyFlink)
1.1 数据源接入
| 数据类型 | 采集方式 | 存储目标 |
|---|---|---|
| 用户行为数据 | - 搜索关键词(如“北京室内景点”) - 点击景点详情页 - 预订订单(用户ID、景点ID、出行日期、人数) - 取消订单记录 | PyFlink Source(Kafka Topic user_behavior),分区键=用户ID |
| 景点元数据 | - 景点ID、名称、类型(自然/人文/室内) - 地理位置(经纬度)、开放时间、票价 - 标签(适合亲子/拍照/徒步) - 实时热度(基于近期预订量) | Hive表(dw.attraction_meta),分区字段=景点类型 |
| 上下文数据 | - 天气数据(API接入:和风天气/高德地图) - 交通数据(景点周边实时拥堵指数) - 节假日标识(是否为周末/法定节假日) | Hive表(dw.context_data),按日期分区 |
1.2 数据清洗与存储
- 实时数据清洗(PyFlink):
- 过滤无效搜索(如“测试”)、异常订单(人数>100或票价<0)。
- 用户ID脱敏(SHA-256哈希处理)。
- 离线数据存储:
- ODS层:原始数据(保留180天行为日志)。
- DWD层:清洗后数据,按主题分区:
dwd.user_behavior_daily(每日用户行为快照)。dwd.attraction_meta_full(景点全量元数据)。
- DWS层:聚合指标(示例SQL):
sql-- 计算用户每日访问景点类型分布CREATE TABLE dws.user_type_distribution ASSELECTuser_id,attraction_type,COUNT(*) as view_count,SUM(CASE WHEN action='book' THEN 1 ELSE 0 END) as book_countFROM dwd.user_behavior_dailyJOIN dw.attraction_meta ON behavior.attraction_id = meta.attraction_idGROUP BY user_id, attraction_type;
2. 混合推荐引擎开发(PyFlink+PySpark)
2.1 实时推荐(PyFlink CEP + 规则引擎)
- 场景:用户B在雨天搜索“上海景点”后,立即推荐室内场馆。
- 技术实现:
- 定义CEP规则(检测“雨天+搜索景点”模式):
pythonfrom pyflink.datastream.patterns import Patternfrom pyflink.datastream.cep import PatternSelectFunction# 定义事件类型:SEARCH(搜索)、WEATHER_RAIN(雨天)pattern = Pattern.begin("start").where(lambda x: x['event_type'] == 'SEARCH') \.next("weather").where(lambda x: x['event_type'] == 'WEATHER_RAIN') \.within(timedelta(minutes=10)) # 10分钟内关联class RainyDayRecommend(PatternSelectFunction):def select(self, pattern):search_event = pattern.get("start")user_id = search_event['user_id']city = search_event['city']# 推荐室内景点(从Hive查询)indoor_attractions = spark.sql(f"""SELECT attraction_id, nameFROM dw.attraction_metaWHERE city='{city}' AND type='室内'ORDER BY popularity DESC LIMIT 10""").collect()return {'user_id': user_id, 'recommendations': indoor_attractions} - 规则引擎扩展:
- 节假日规则:国庆节推荐红色旅游景点(如延安革命纪念馆)。
- 交通规则:景点周边拥堵指数>8时,推荐地铁直达景点。
- 定义CEP规则(检测“雨天+搜索景点”模式):
2.2 离线推荐(PySpark + LightGBM)
- 场景:为新用户或冷启动景点生成推荐列表。
- 特征设计:
特征组 示例特征 用户特征 年龄、性别、过去30天访问景点类型分布、历史预订价格区间 景点特征 类型、票价、评分、是否支持儿童票、距离市中心距离 上下文特征 天气(晴/雨/雪)、节假日标识、同行人数 - 模型训练:
pythonfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.classification import GBTClassifierfrom pyspark.ml.evaluation import BinaryClassificationEvaluator# 特征组装assembler = VectorAssembler(inputCols=["age", "gender", "attraction_type_自然", "attraction_type_人文", "price"],outputCol="features")data = assembler.transform(train_data)# 定义LightGBM模型(通过MMLSpark集成)from mmlspark.lightgbm import LightGBMClassifierlgbm = LightGBMClassifier(featuresCol="features",labelCol="clicked", # 用户是否点击推荐景点objective="binary",numLeaves=31,learningRate=0.05)model = lgbm.fit(data)# 多目标优化(点击率+预订转化率)from pyspark.ml.tuning import CrossValidator, ParamGridBuilderparam_grid = ParamGridBuilder() \.addGrid(lgbm.learningRate, [0.01, 0.05, 0.1]) \.addGrid(lgbm.numLeaves, [15, 31, 63]) \.build()cross_validator = CrossValidator(estimator=lgbm,estimatorParamMaps=param_grid,evaluator=MultiClassClassificationEvaluator(labelCol="booked"), # 预订转化率numFolds=3)
3. 数据可视化与监控
3.1 推荐效果监控
- Grafana看板指标:
- 实时指标:推荐请求QPS、平均响应时间、CTR(点击率)、预订转化率(CVR)。
- 离线指标:
- 推荐多样性(推荐景点类型数量/总推荐数)。
- 冷启动景点曝光占比(新上线景点在推荐列表中的比例)。
3.2 用户兴趣分析
- Superset图表示例:
- 桑基图:用户兴趣迁移路径(如“自然风光→历史文化→亲子游乐”)。
- 热力图:不同年龄段用户对景点类型的偏好(X轴=类型,Y轴=年龄,颜色=预订量)。
4. 系统集成与性能优化
- 集群部署:
- Hadoop(4节点):HDFS存储原始数据和模型文件。
- PyFlink(2 JobManager + 4 TaskManager):实时推荐任务。
- PySpark(3 Worker节点):离线训练任务。
- Kafka(3节点):
user_behaviorTopic副本数=3,防止数据丢失。
- 性能优化:
- PyFlink调优:
setBufferTimeout(100)(减少微批处理延迟)。setParallelism(200)(提高CEP规则匹配吞吐量)。
- PySpark调优:
spark.sql.shuffle.partitions=200(避免数据倾斜)。spark.executor.memoryOverhead=4g(防止OOM)。
- PyFlink调优:
三、技术栈与开发环境
| 模块 | 技术选型 |
|---|---|
| 大数据框架 | Hadoop 3.3.4, PyFlink 1.16, PySpark 3.3.2, Hive 3.1.3 |
| 流处理 | Kafka 3.4.0, PyFlink CEP |
| 机器学习 | PySpark MLlib, LightGBM (MMLSpark) |
| 可视化 | Grafana 9.0, Superset 2.0 |
| 开发环境 | Linux (CentOS 7), PyCharm, JupyterLab |
四、项目里程碑计划
| 阶段 | 时间 | 交付物 |
|---|---|---|
| 数据采集与ETL | 第1-2周 | PyFlink消费者脚本、Hive表结构文档 |
| 实时推荐引擎开发 | 第3-4周 | CEP规则文件、实时推荐API文档 |
| 离线模型训练 | 第5周 | LightGBM模型、特征重要性分析报告 |
| 可视化看板开发 | 第6周 | Grafana Dashboard链接、Superset图表 |
| 系统联调与上线 | 第7周 | 压测报告(QPS≥1500)、用户操作手册 |
五、预期成果
- 推荐效果:
- 实时推荐CTR提升20%,离线推荐覆盖冷启动景点40%以上。
- 系统性能:
- 实时推荐延迟<1.5秒,离线模型训练时间<1.5小时(全量数据)。
- 业务价值:
- 用户从搜索到预订的平均时间从45分钟缩短至30分钟,冷启动景点曝光量增加60%。
六、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| 数据倾斜 | 对热门景点ID加盐(如attractionId_1~attractionId_10)后JOIN |
| 模型过拟合 | 在LightGBM中设置feature_fraction=0.8(每棵树随机采样80%特征) |
| Kafka消息堆积 | 增加消费者线程数(max.poll.records=5000) |
| 冷启动问题 | 对新用户采用基于地理位置的协同过滤(如“同城市用户偏好”) |
项目负责人:__________
日期:__________
此任务书可根据实际旅游平台规模调整集群节点数(如日活用户>500万时增加PyFlink TaskManager至8节点),并建议优先在热门旅游城市(如北京、上海)上验证推荐效果,再扩展至全域景点。可视化部分可增加“景点实时拥挤度预警”等深度洞察模块。
运行截图
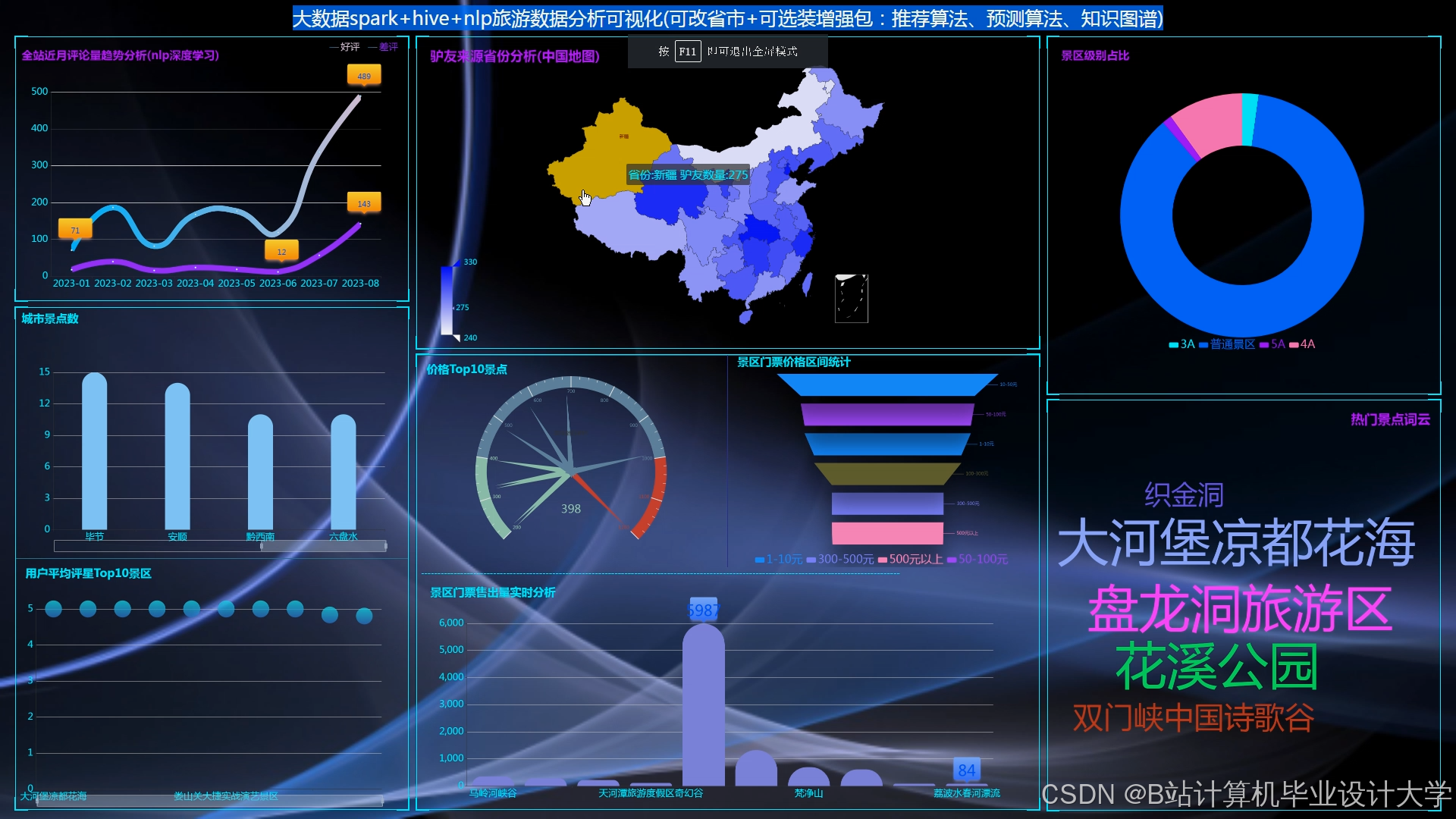
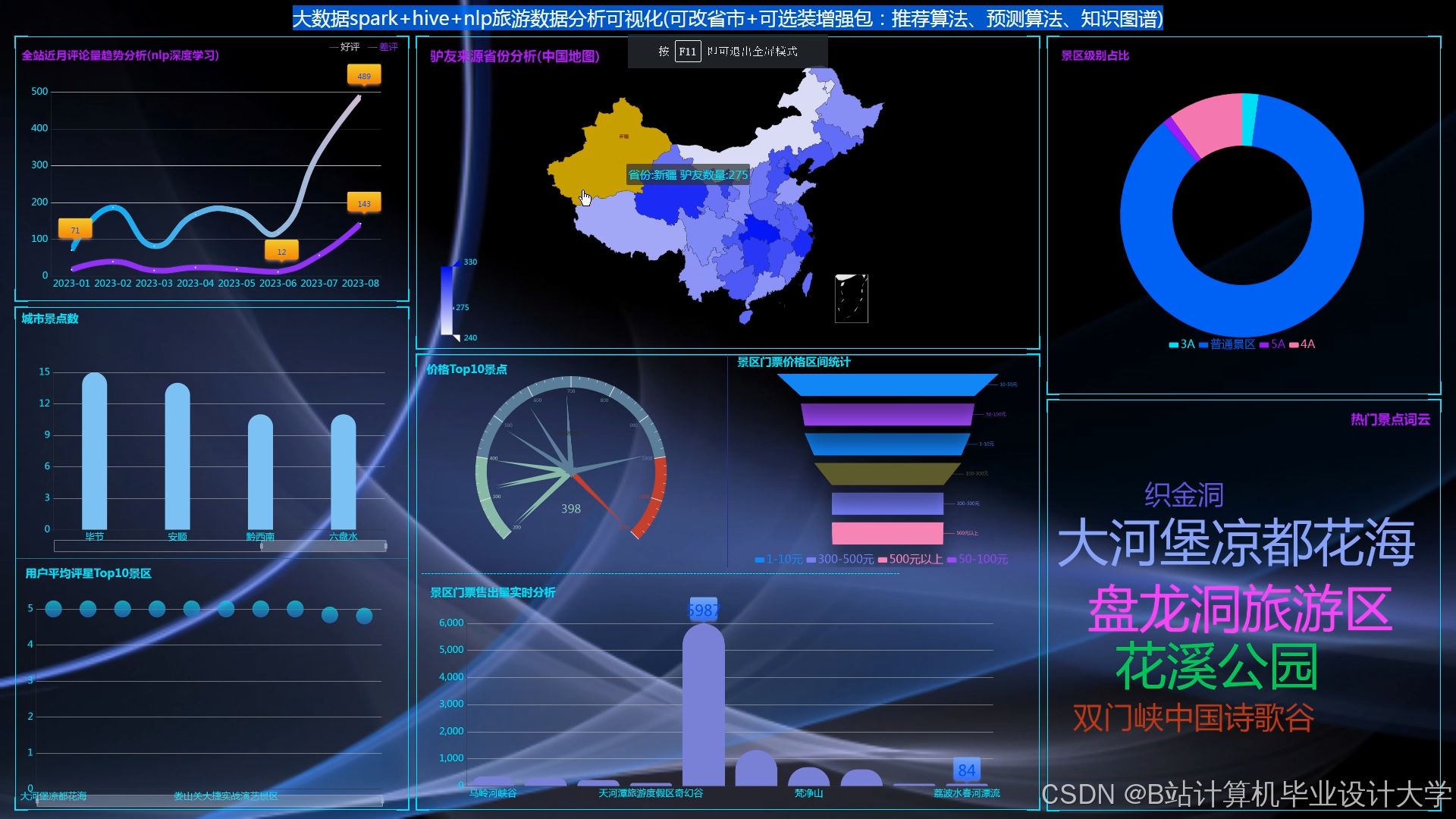

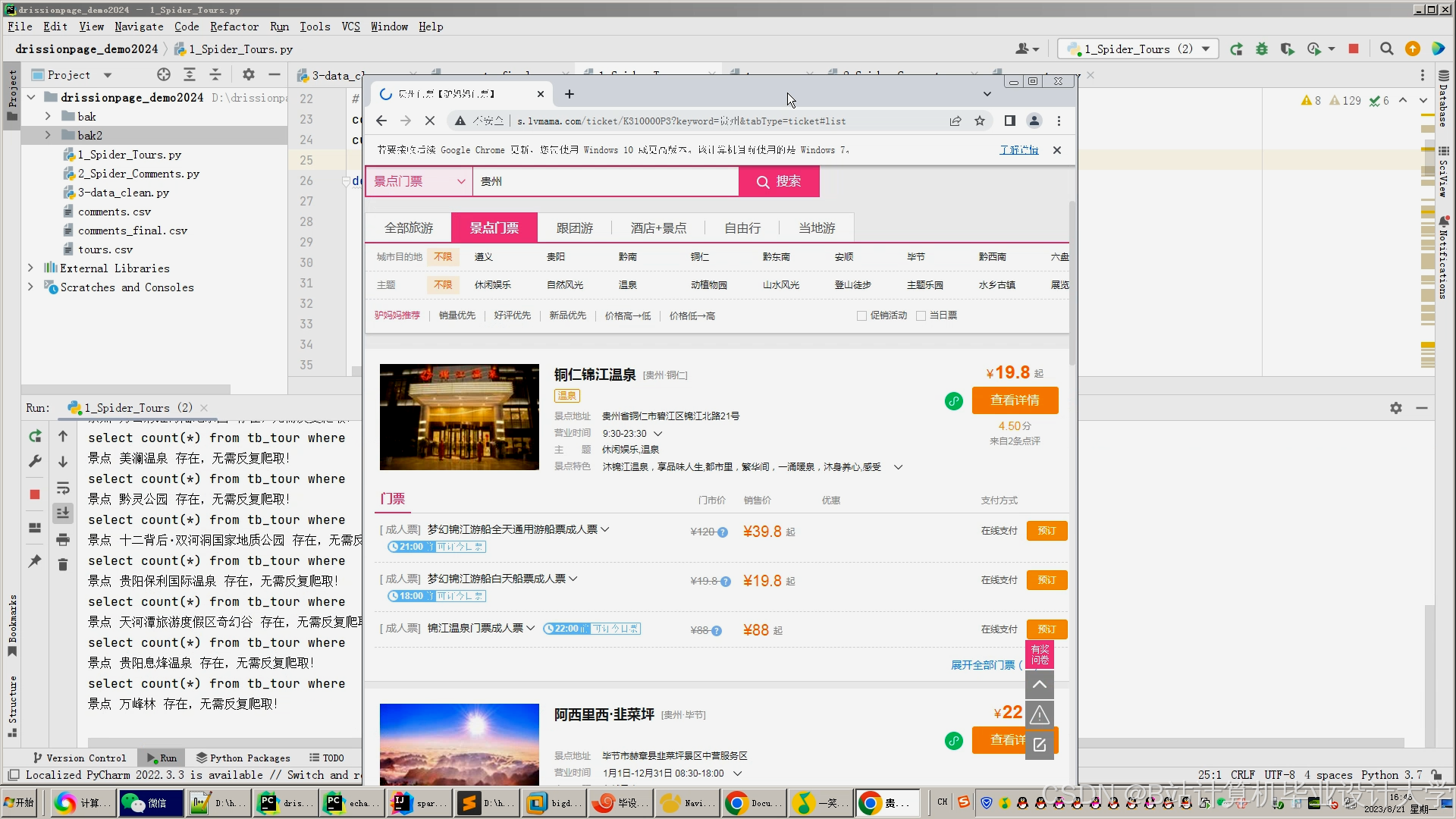
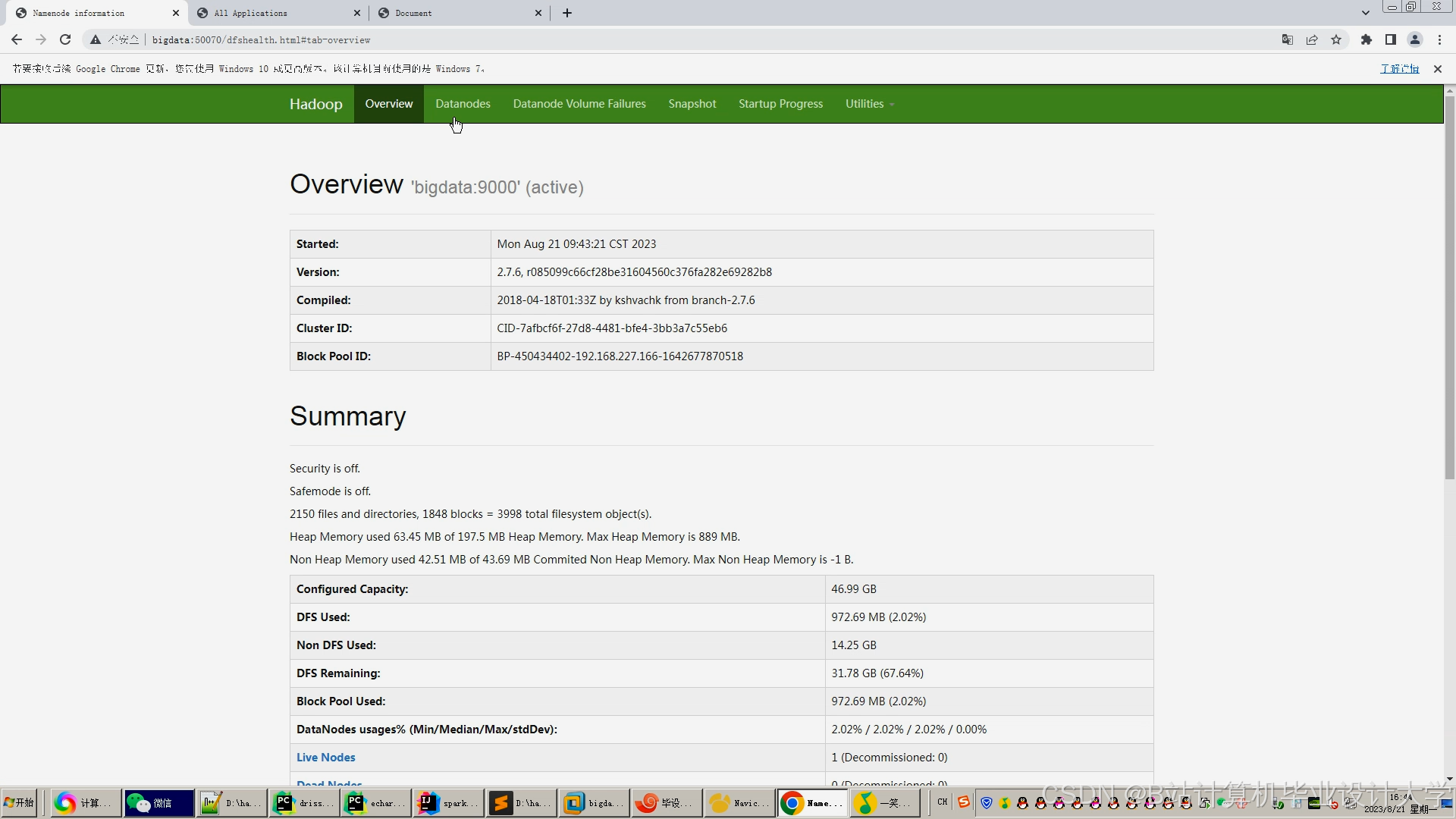
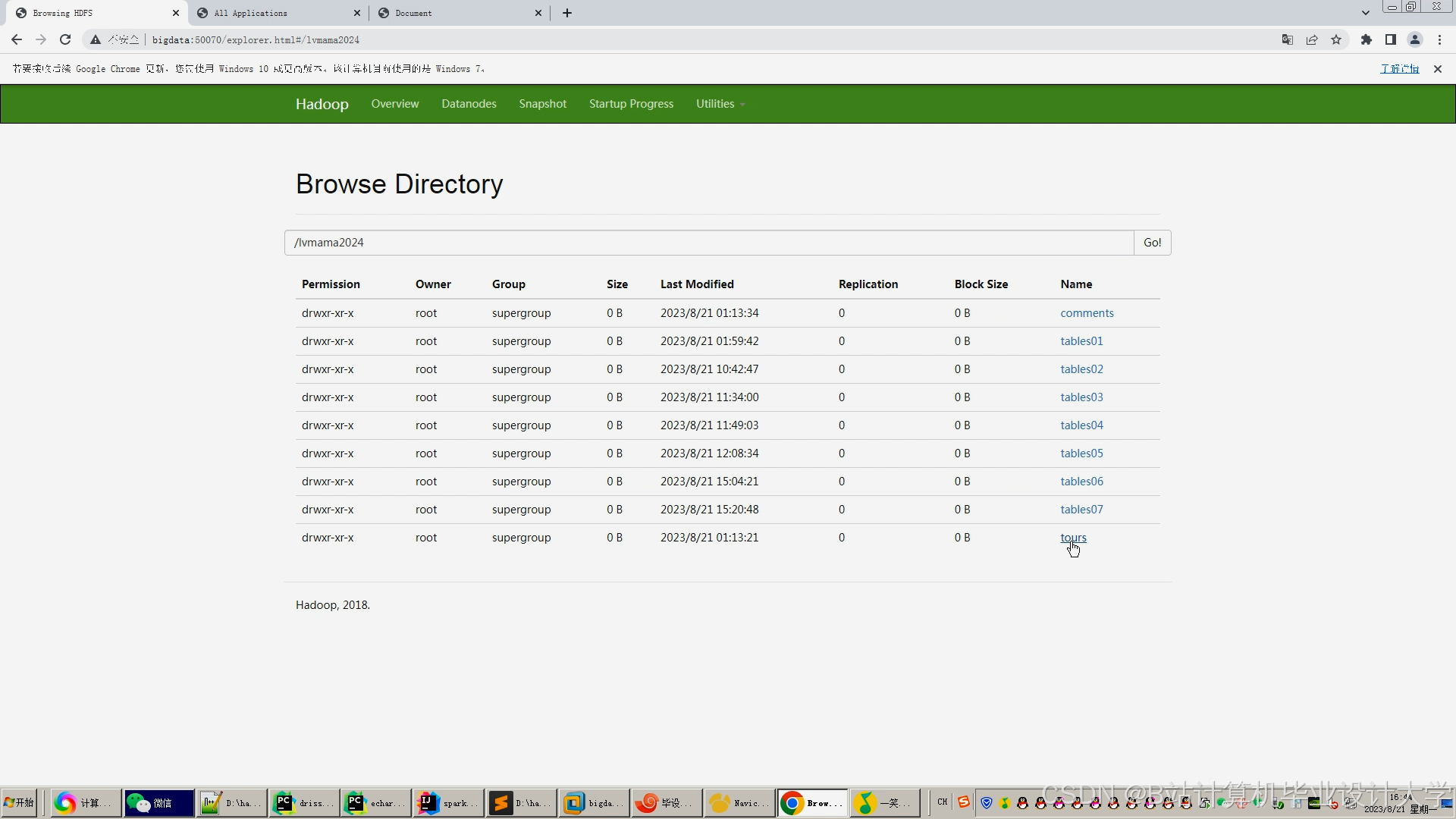
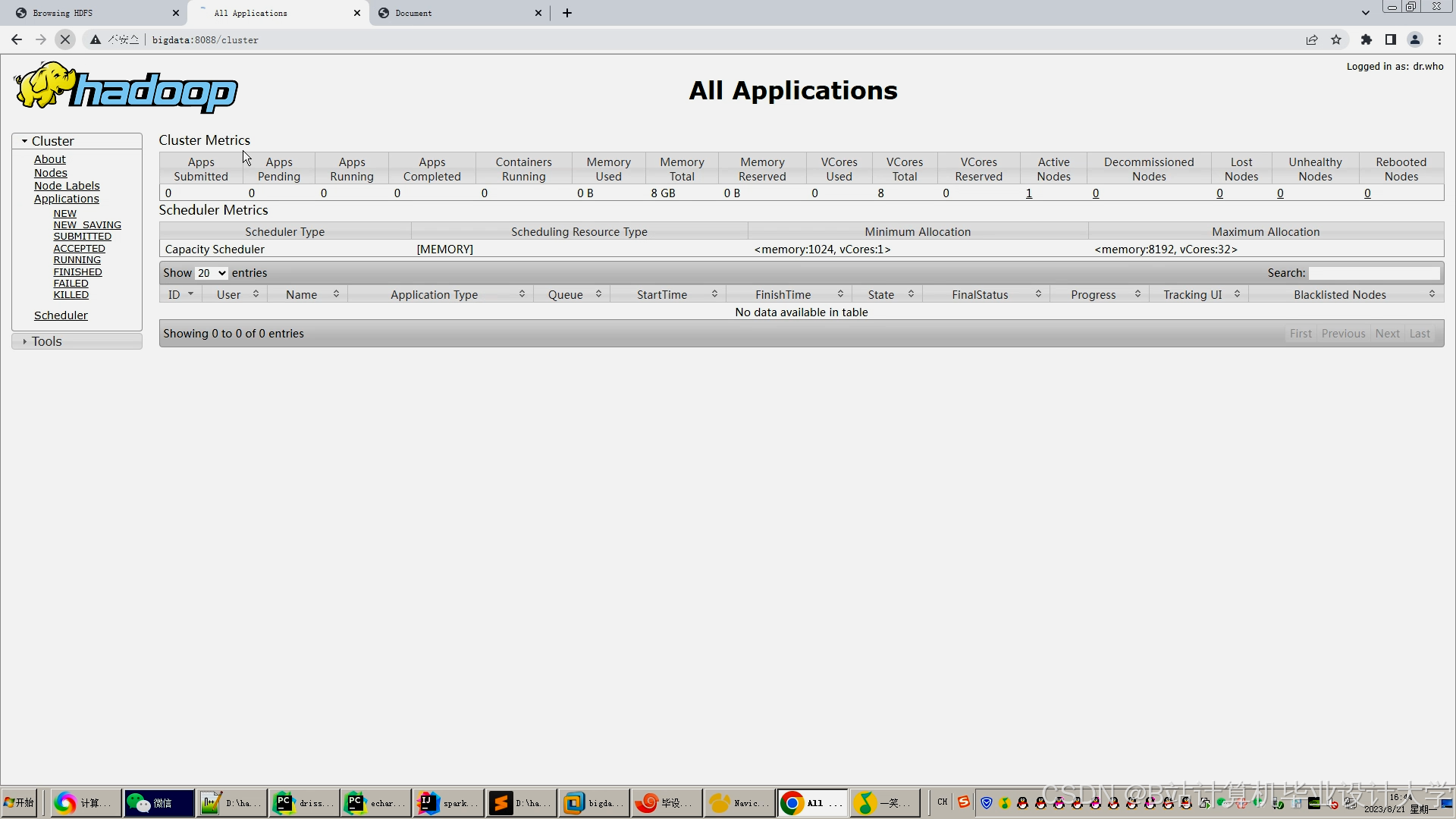
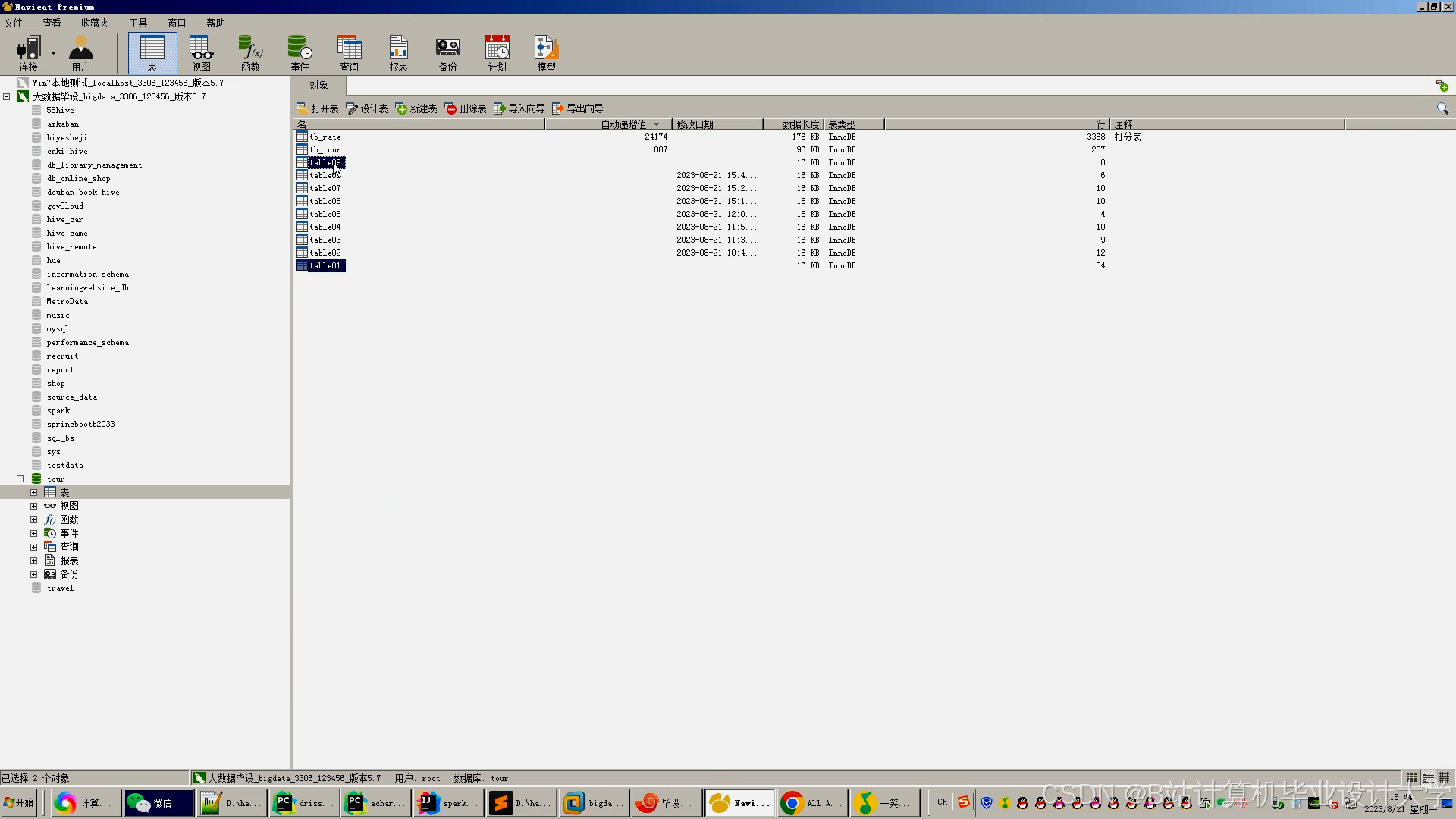
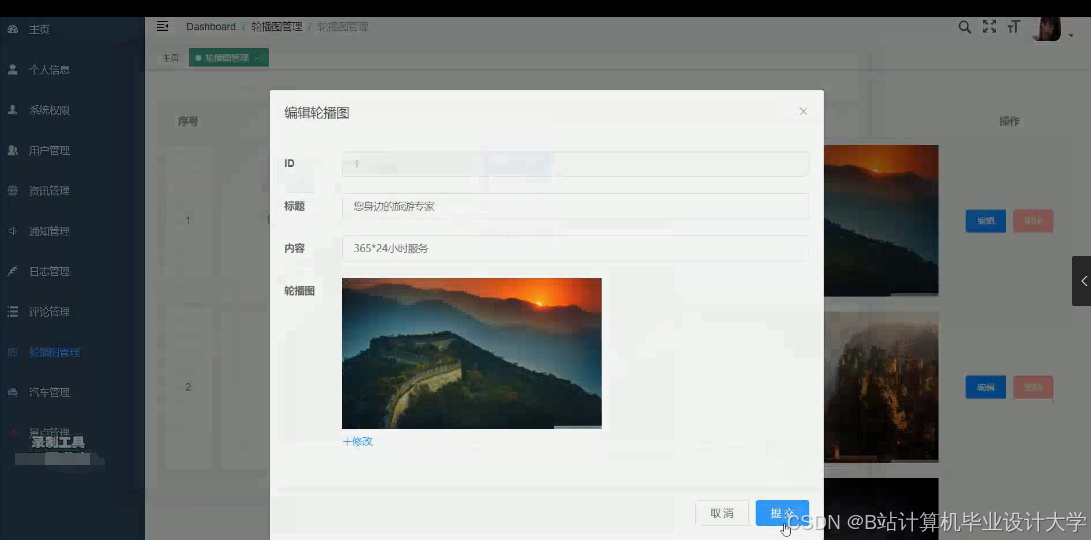
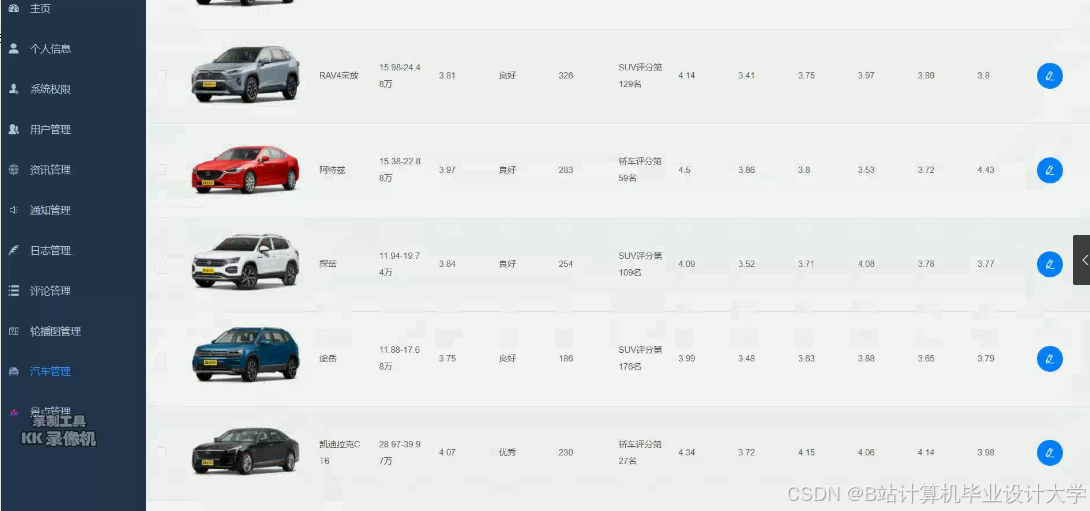
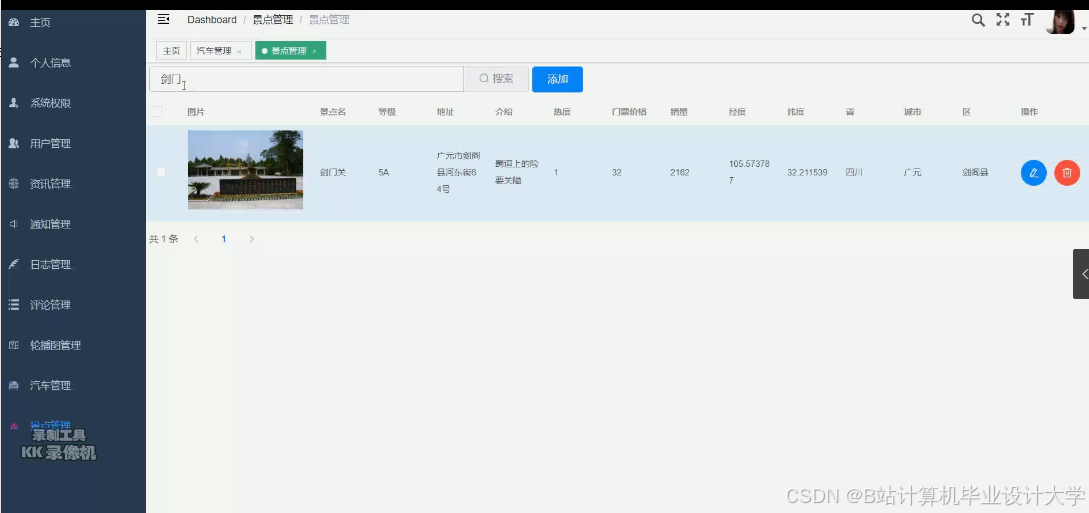
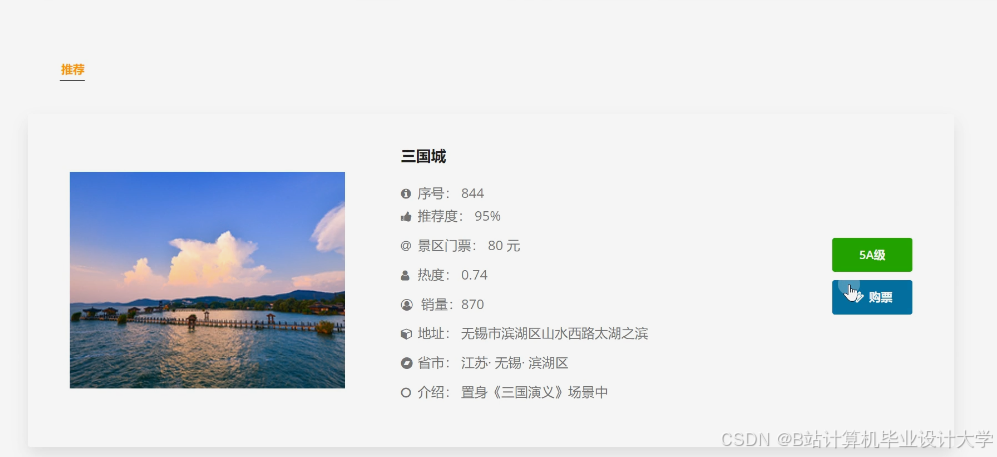
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











