




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是为《Django+大模型中华古诗词知识图谱可视化与智能问答系统》设计的任务书模板,涵盖技术架构、功能模块、任务分解及实施计划:
任务书:基于Django与大模型的中华古诗词智能分析系统
一、项目背景
- 文化价值
- 中华古诗词是传统文化瑰宝,但现有数字资源分散(如诗词网站、学术数据库),缺乏系统性关联与智能化检索。
- 用户需求从“关键词搜索”向“语义理解”“知识推理”升级(如“李白的诗中哪些提到月亮?”)。
- 技术机遇
- 知识图谱:构建“诗人-作品-意象-朝代”多维度关联网络,支持复杂语义查询。
- 大模型能力:利用LLM(如Qwen、DeepSeek)解析自然语言问题,结合图谱生成精准回答。
- 可视化交互:Django快速搭建Web平台,集成D3.js/ECharts实现动态图谱展示。
- 项目意义
打造集“知识存储、语义检索、智能问答、可视化分析”于一体的古诗词文化传承工具,助力教育与研究。
二、项目目标
1. 核心功能
- 知识图谱构建
- 输入:结构化数据(诗人信息、诗词文本、注释)与非结构化数据(学术文献、网络解析)。
- 输出:包含5类实体(诗人、诗词、朝代、意象、地点)和8类关系(创作于、提及、属于、风格相似)的图谱。
- 智能问答
- 输入:自然语言问题(如“苏轼和辛弃疾的豪放词有哪些异同?”)。
- 输出:基于图谱的回答,附诗词原文、创作背景及对比分析。
- 可视化分析
- 提供3种视图:诗人关系网络图、诗词意象词云、朝代诗词数量时间轴。
2. 性能指标
- 图谱规模:覆盖10,000+首诗词、2,000+位诗人、500+个核心意象。
- 问答精度:复杂问题(多跳推理)回答准确率≥85%,简单问题(单实体查询)准确率≥95%。
- 响应速度:90%请求在1.5秒内返回结果(含图谱渲染)。
三、技术方案
1. 系统架构
mermaid
graph TD | |
A[数据源] --> B[知识抽取模块] | |
B --> C[Neo4j图数据库] | |
C --> D[Django Web服务] | |
D --> E[大模型问答引擎] | |
D --> F[D3.js可视化] | |
E --> G[用户交互] |
2. 关键技术模块
| 模块 | 技术选型 | 功能描述 |
|---|---|---|
| 知识抽取 | Python + SpaCy + 规则引擎 | 从文本中识别实体(如“李白”)与关系(如“《静夜思》-创作于-唐朝”) |
| 图谱存储 | Neo4j Cypher | 存储诗人、诗词、意象等节点及关系,支持高效图查询 |
| 大模型集成 | Qwen-7B/DeepSeek-R1 | 解析用户问题意图,生成Cypher查询语句或直接调用图谱API |
| Web服务 | Django + RESTful API | 提供问答接口、图谱数据查询、用户管理(如收藏诗词) |
| 可视化 | D3.js + ECharts | 动态渲染关系网络、词云、时间轴,支持缩放与点击交互 |
3. 大模型与图谱协同流程
- 用户提问(如“王维的山水诗中常出现哪些意象?”)→ 大模型解析为结构化查询:
json{"task_type": "意象分析","poet": "王维","genre": "山水诗","limit": 5} - 系统响应:
- 调用Neo4j查询意象高频词 → 大模型生成回答:
“王维山水诗中高频意象包括‘空山’(出现12次)、‘明月’(9次)、‘青松’(7次),体现其‘诗中有画’的禅意风格。”
- 调用Neo4j查询意象高频词 → 大模型生成回答:
四、任务分解与里程碑
阶段1:数据层建设(4周)
- 任务1.1:数据收集与清洗
- 爬取《全唐诗》《全宋词》等开源数据集,整合诗词文本、注释、诗人生平。
- 使用OpenRefine去除重复数据,标准化朝代名称(如“唐”→“唐朝”)。
- 任务1.2:知识抽取与图谱构建
- 开发SpaCy规则模型,识别诗词中的诗人、意象、地点实体。
- 编写Cypher脚本,批量导入Neo4j(示例):
cypherCREATE (p:Poet {name: '李白', dynasty: '唐朝'})CREATE (poem:Poem {title: '静夜思', content: '床前明月光...'})CREATE (p)-[:WROTE]->(poem)
- 任务1.3:图谱质量验证
- 随机抽样100首诗词,人工检查实体识别准确率(目标≥90%)。
阶段2:大模型微调与问答引擎开发(3周)
- 任务2.1:微调LLM理解古诗词语义
- 在“古诗词问答对”数据集上微调Qwen-7B,强化对意象、典故的解析能力。
- 示例训练数据:
json{"input": "‘春风又绿江南岸’中的‘绿’字好在哪里?","output": "‘绿’字动态化描写春色,兼具视觉与生机感,比‘到’‘过’更生动。"}
- 任务2.2:开发问答路由逻辑
- 区分事实性问题(查询图谱,如“李清照的丈夫是谁?”)与分析性问题(调用LLM,如“比较柳永与秦观的词风”)。
- 任务2.3:实现回答可解释性
- 在回答中标注数据来源(如“根据《宋史》记载…”或“基于图谱中50首词的统计分析”)。
阶段3:Web平台开发(3周)
- 任务3.1:Django后台搭建
- 设计数据库模型(用户、诗词收藏、问答日志),配置Django Admin管理界面。
- 任务3.2:开发RESTful API
- 封装图谱查询接口(如
/api/poet/李白/poems)与问答接口(/api/ask)。
- 封装图谱查询接口(如
- 任务3.3:集成可视化组件
- 使用D3.js实现诗人关系力导向图,支持点击节点查看诗词详情。
- 使用ECharts生成朝代诗词数量堆叠柱状图。
阶段4:系统测试与优化(2周)
- 任务4.1:功能测试
- 模拟100个用户提问,验证问答准确率与图谱渲染正确性。
- 任务4.2:性能优化
- 对Neo4j查询添加索引(如
CREATE INDEX ON :Poem(title)),减少响应时间。 - 使用Django缓存(Redis)存储高频问答结果。
- 对Neo4j查询添加索引(如
- 任务4.3:部署上线
- 部署至腾讯云CVM,配置Nginx反向代理与HTTPS证书。
五、资源与风险评估
1. 资源需求
- 硬件:1台8核32G服务器(Neo4j+Django)、1台GPU服务器(LLM微调)。
- 数据:需获取《全唐诗》《全宋词》文本、诗人维基数据、学术注释库。
- 人员:NLP工程师(1人)、前端开发(1人)、全栈开发(1人)。
2. 风险与应对
- 风险1:古诗词语义复杂导致LLM误答 → 增加人工审核环节,对高风险回答(如涉及历史争议)标记“仅供参考”。
- 风险2:图谱关系缺失影响查询结果 → 开发数据补全脚本,从学术文献中抽取隐含关系(如“苏轼受佛学影响”)。
- 风险3:Django并发性能不足 → 优化数据库查询(使用
select_related/prefetch_related),添加异步任务队列(Celery)。
六、交付成果
- 系统代码:GitHub仓库(含Django项目、知识抽取脚本、LLM微调代码)。
- 数据资产:Neo4j图谱数据库(dump文件)、清洗后的诗词文本集。
- 测试报告:问答准确率统计、性能测试结果、用户反馈汇总。
项目负责人:XXX
起止日期:202X年XX月XX日 - 202X年XX月XX日
此任务书可结合实际数据规模调整技术选型(如替换Neo4j为JanusGraph支持分布式图存储),重点突出“知识图谱+大模型”的语义理解与推理能力设计。
运行截图
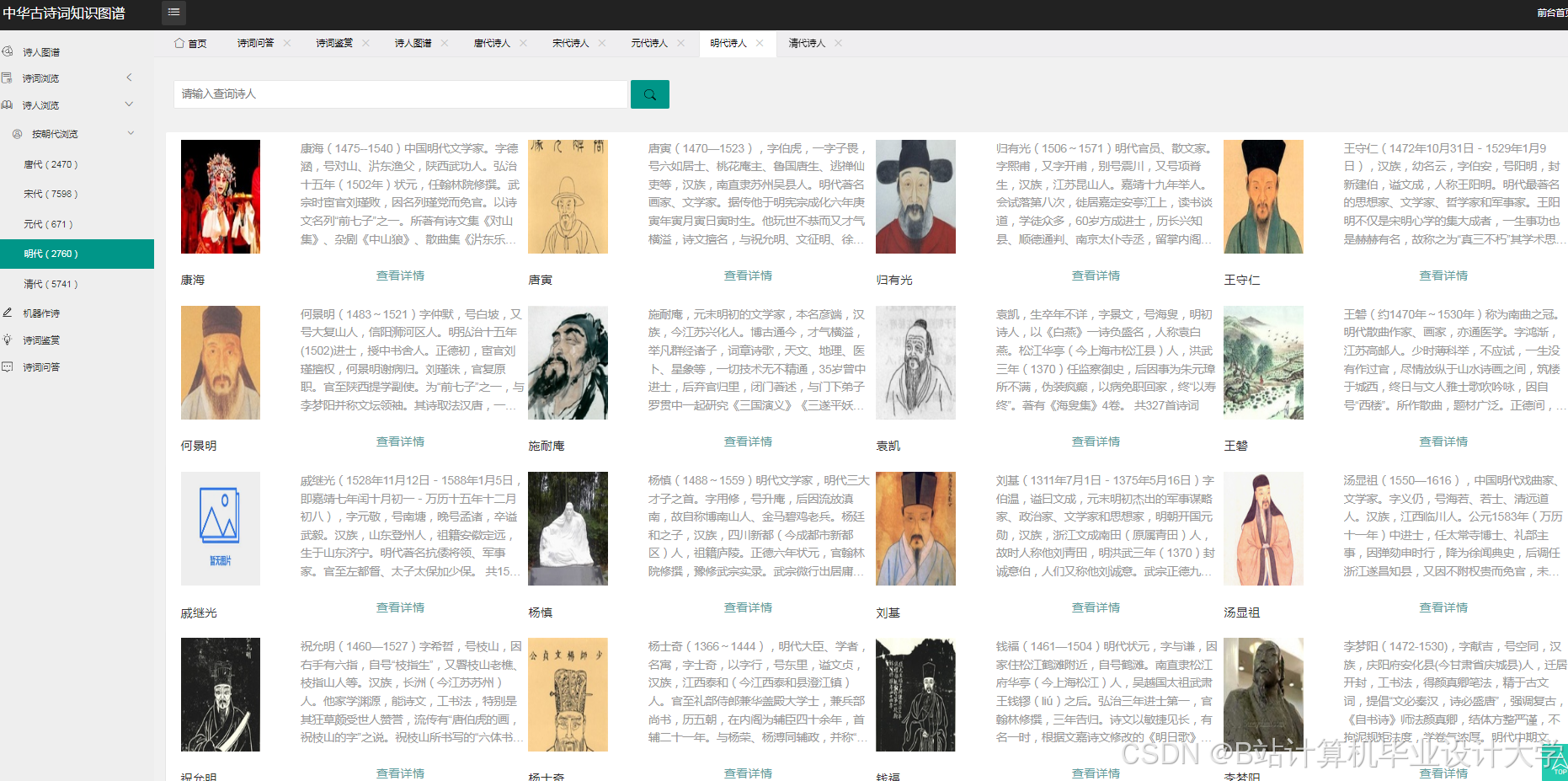
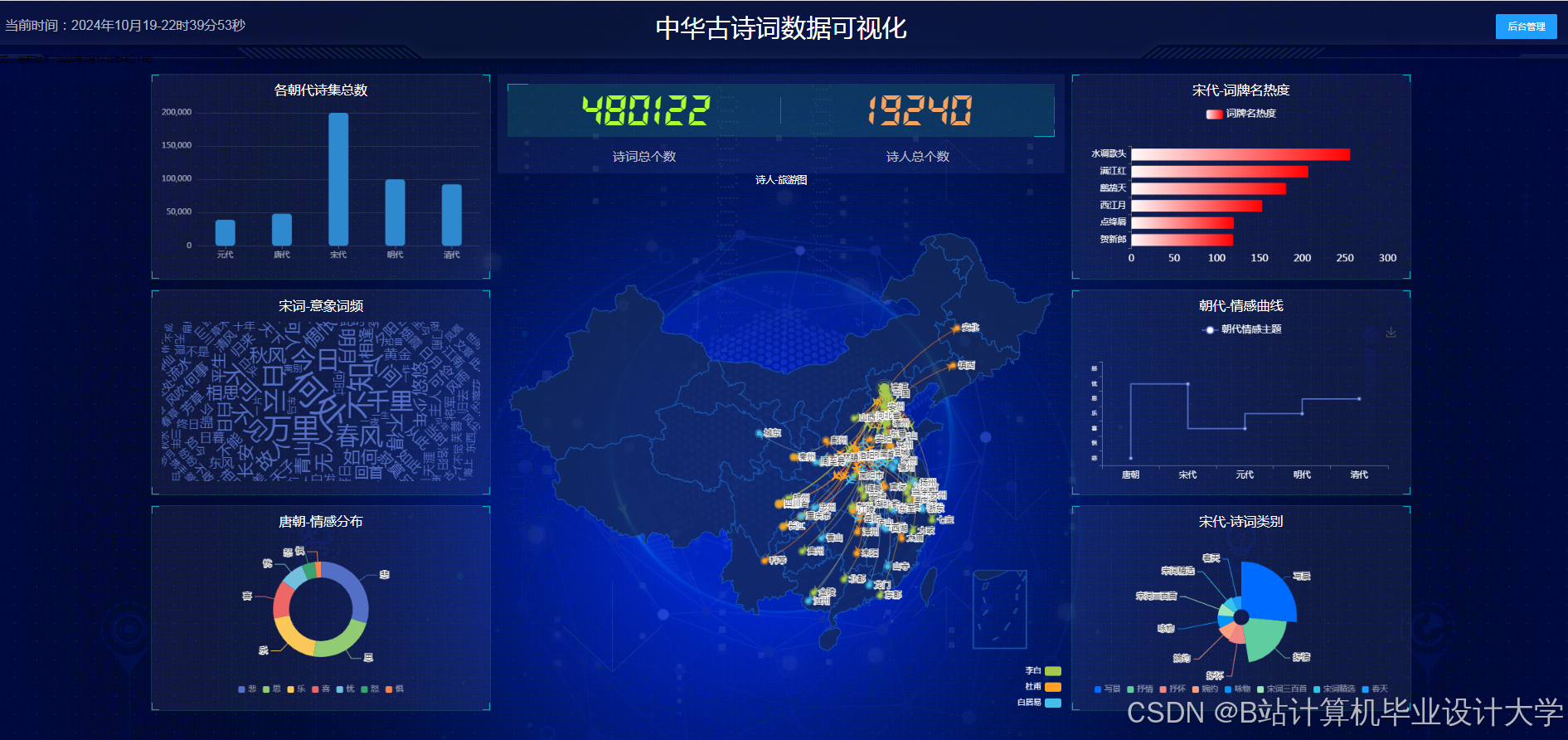
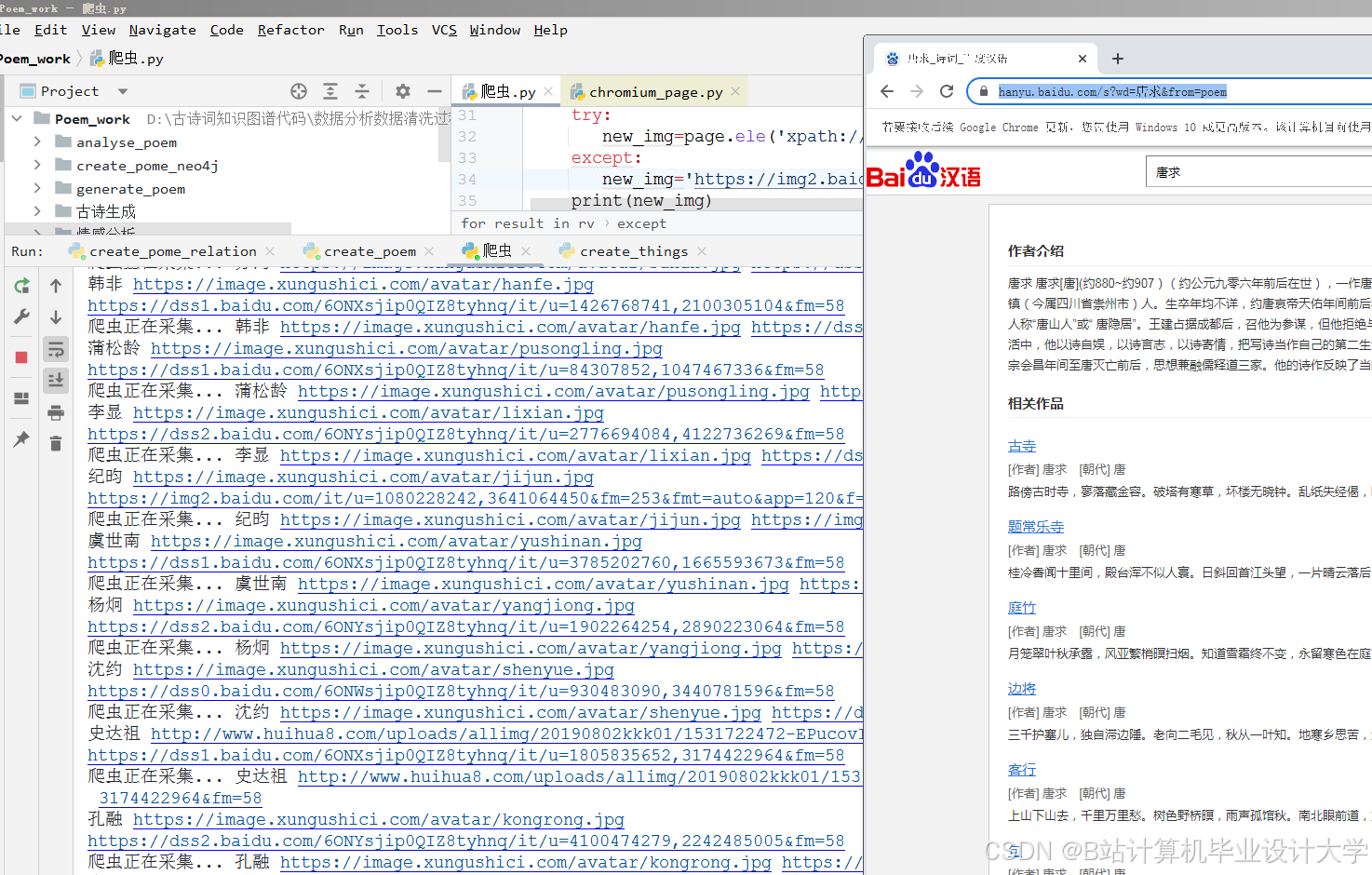
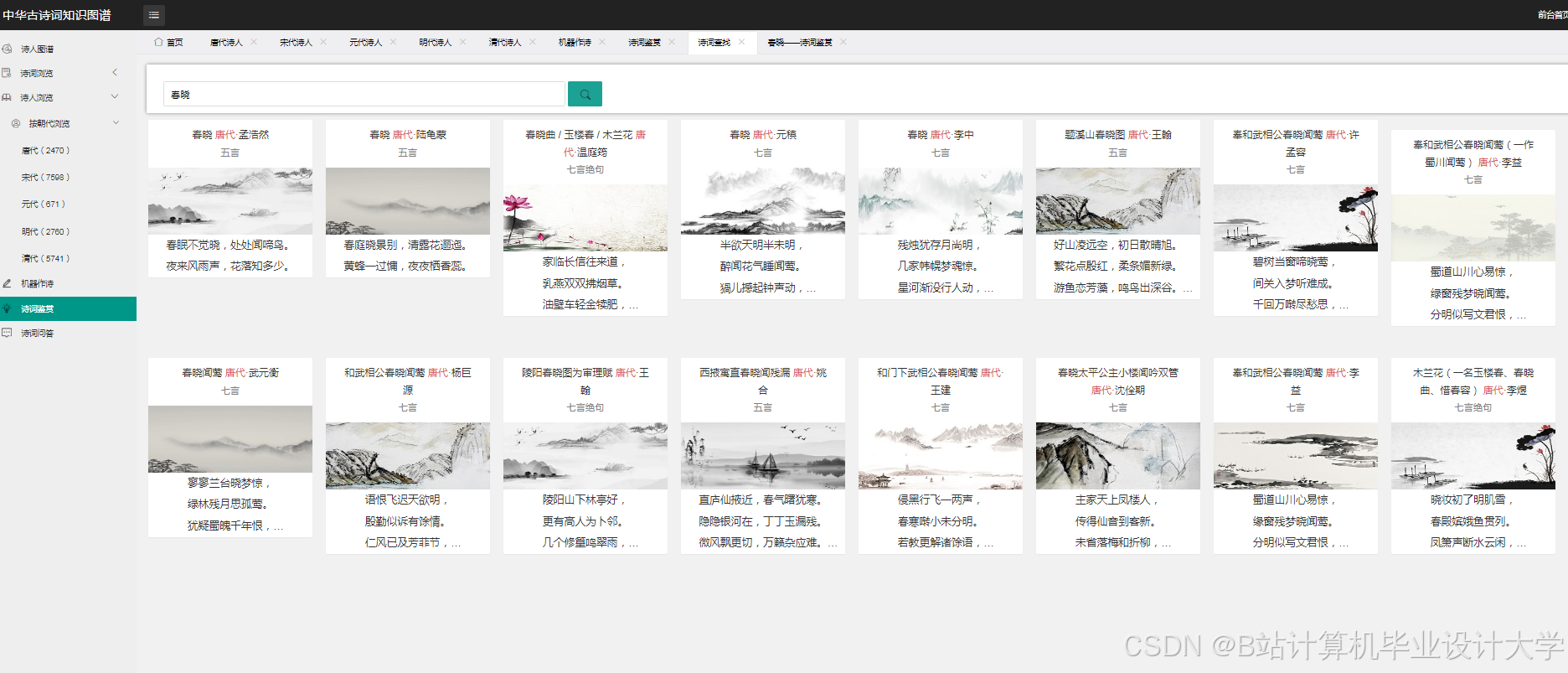
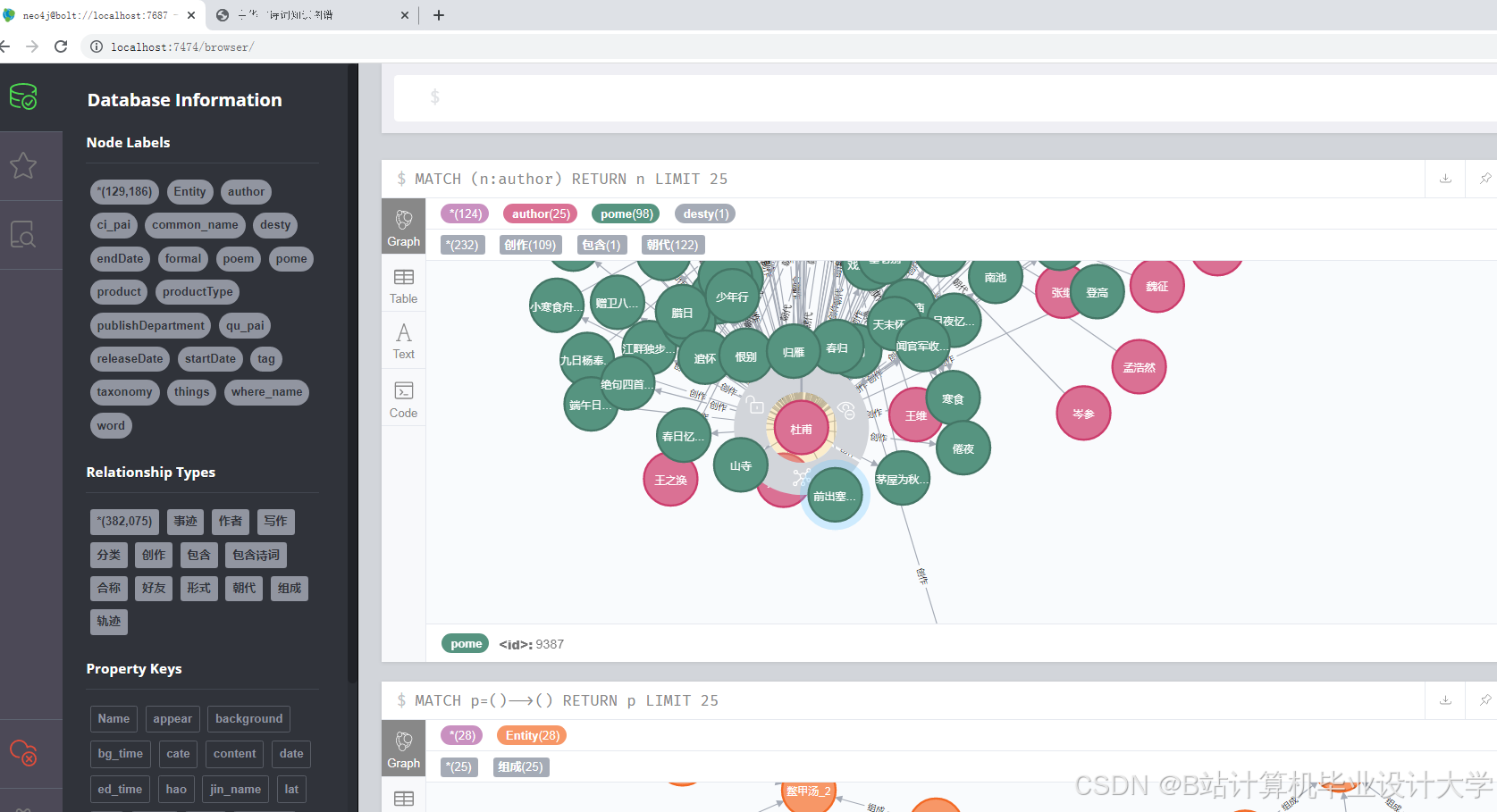
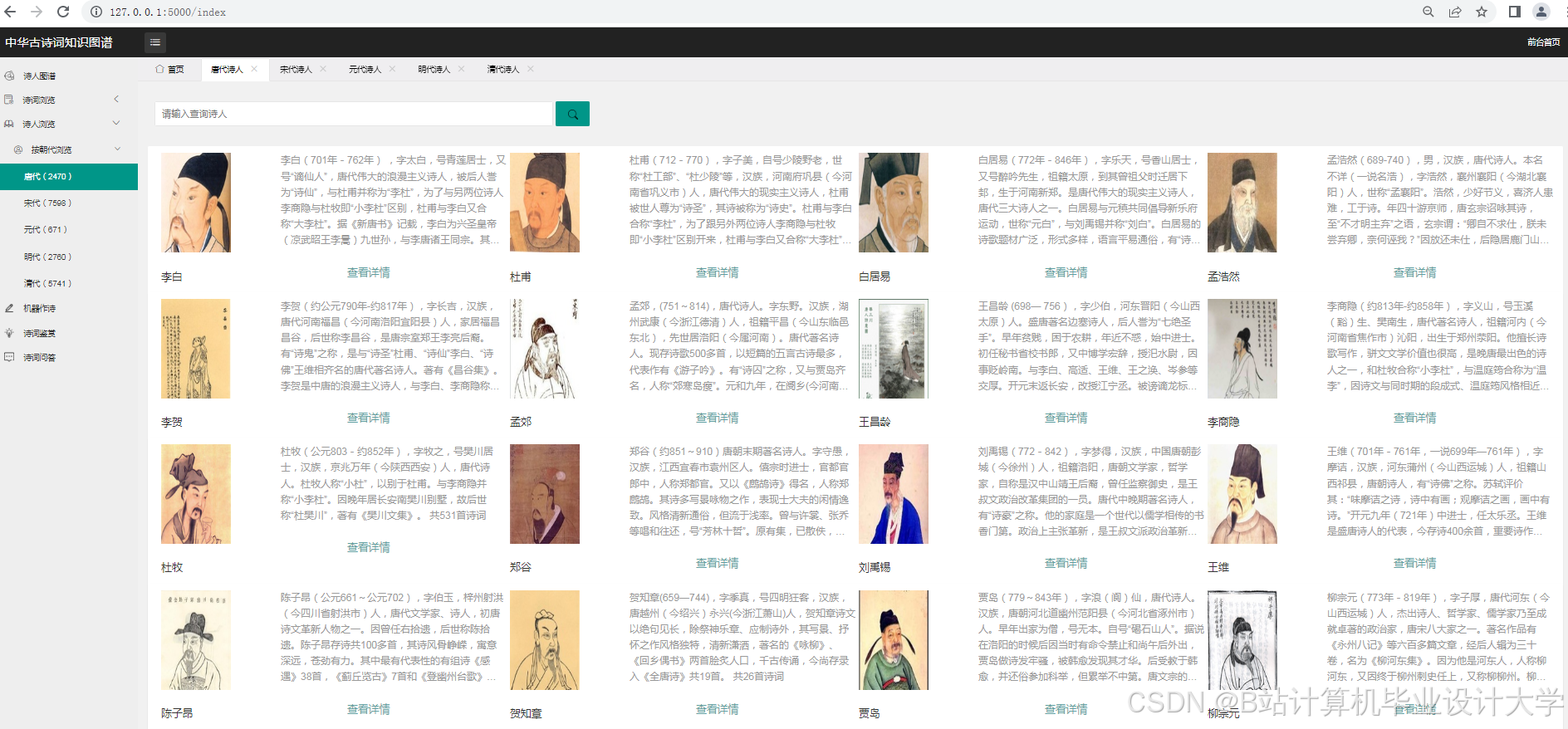

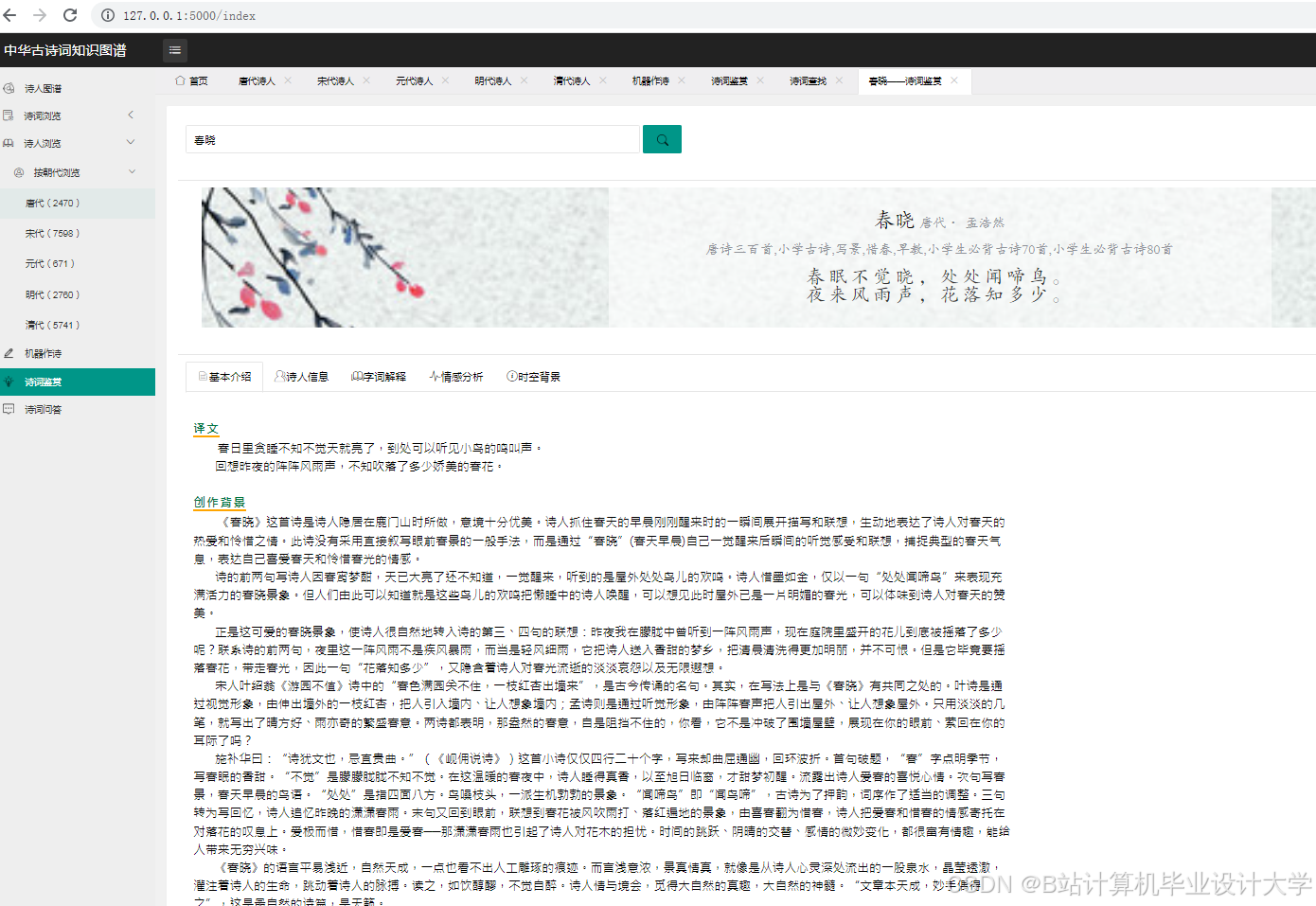
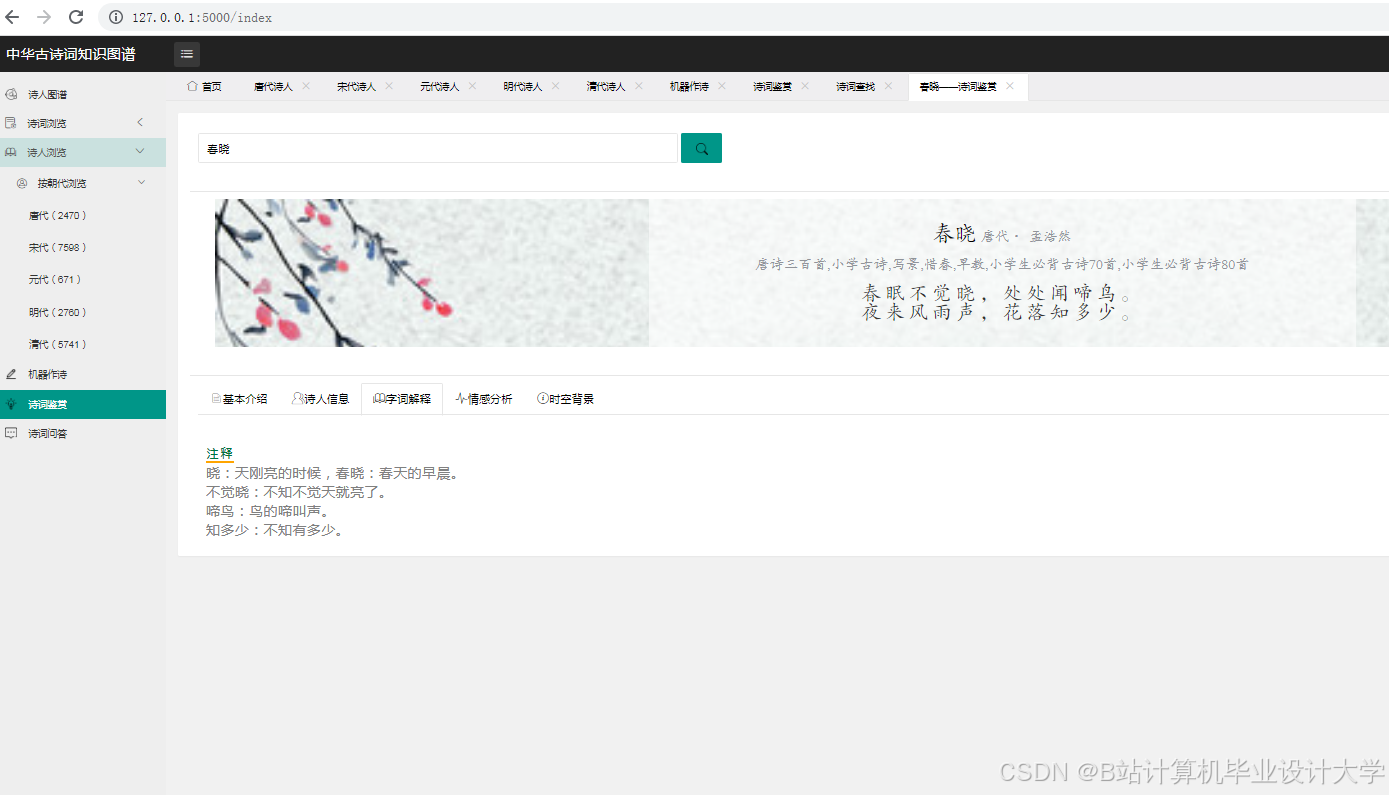
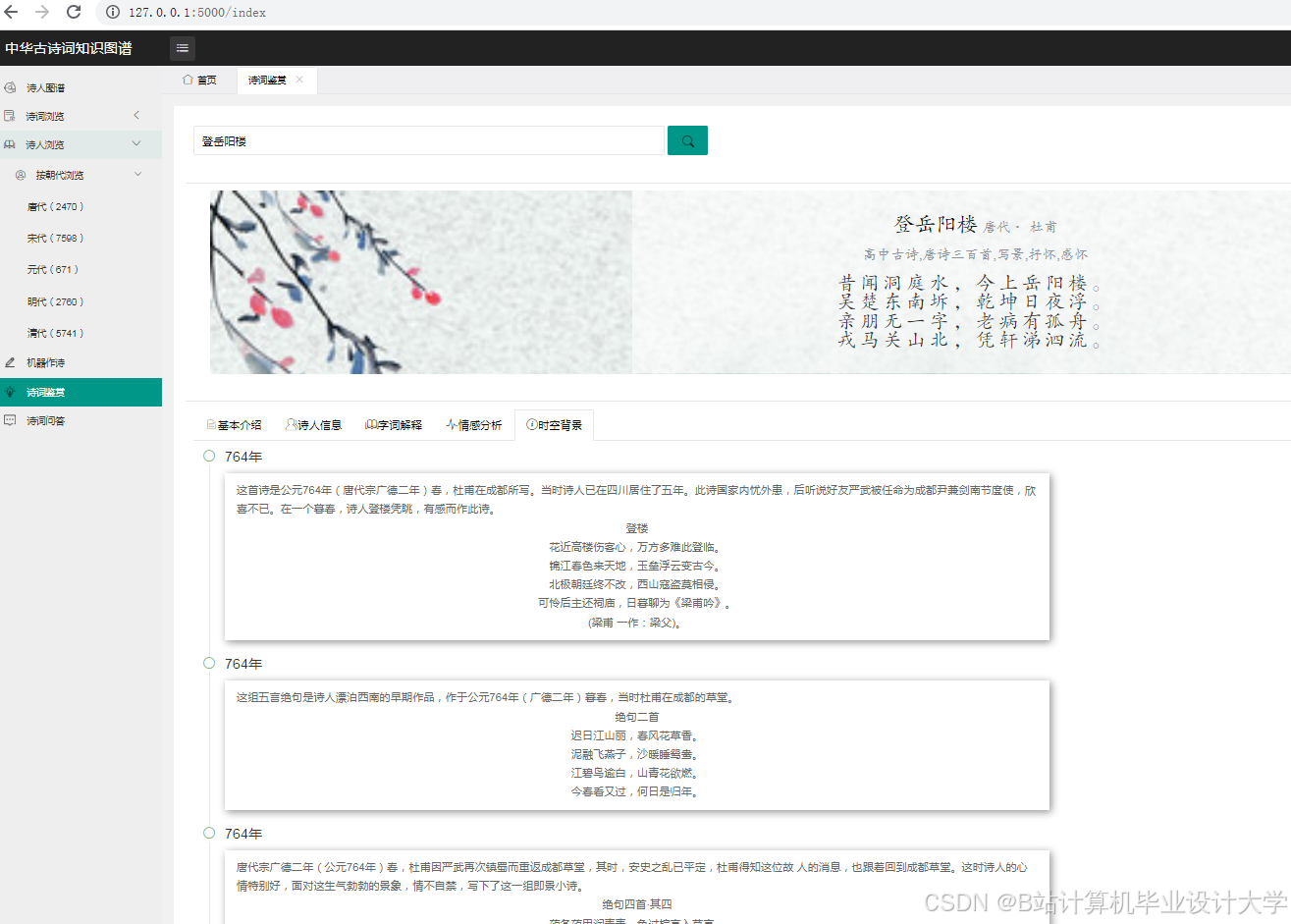
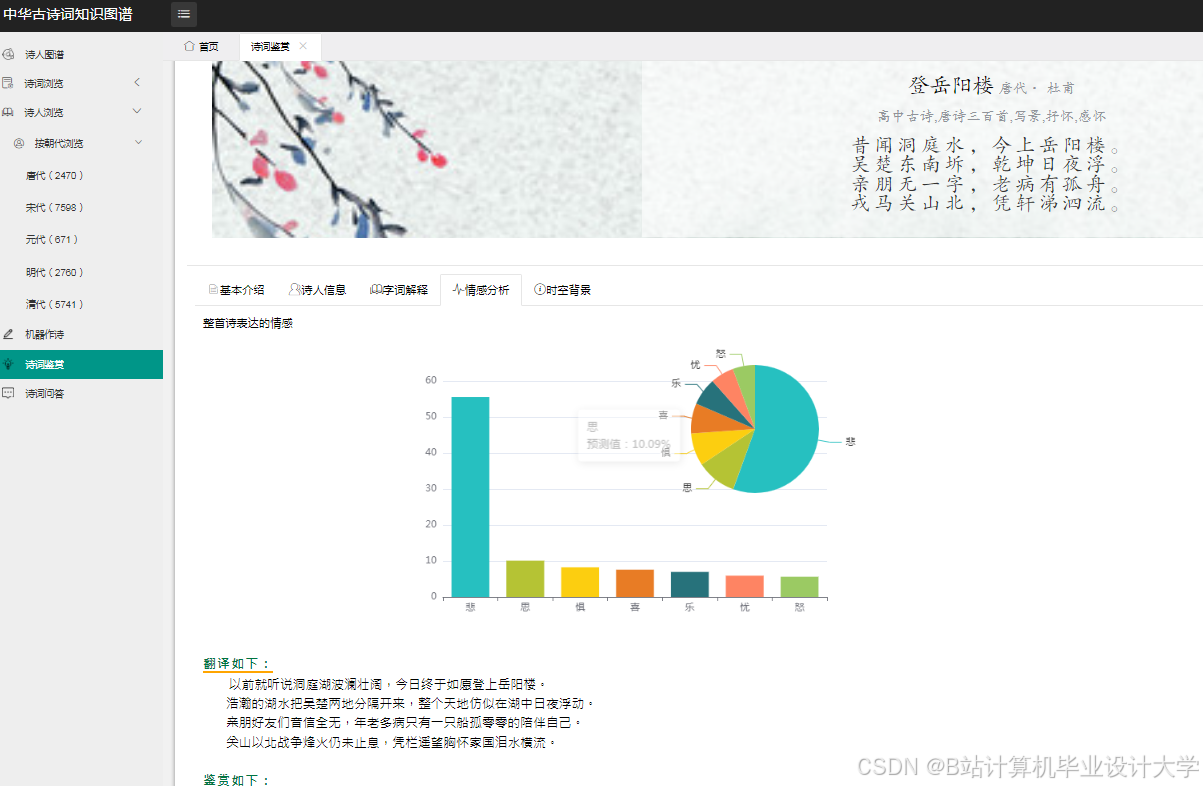
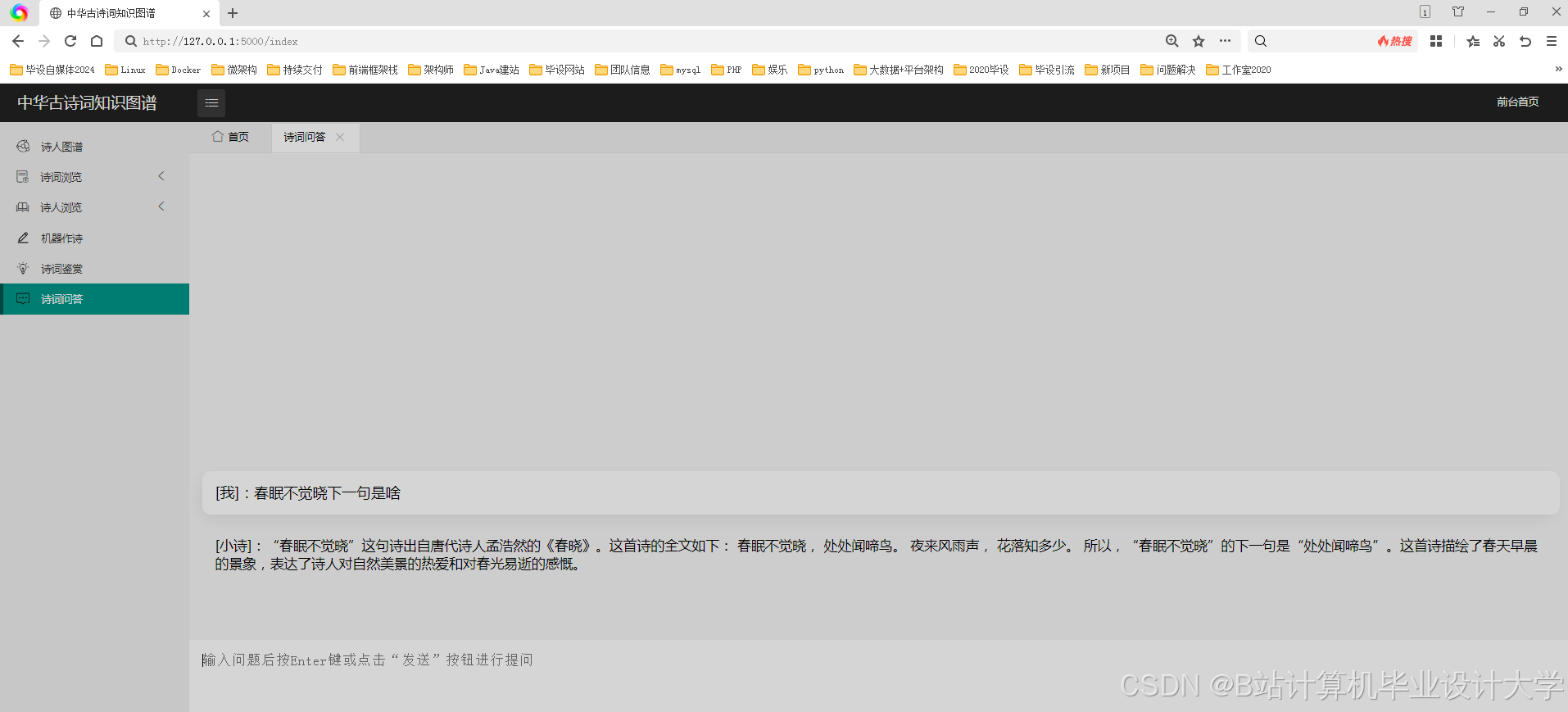
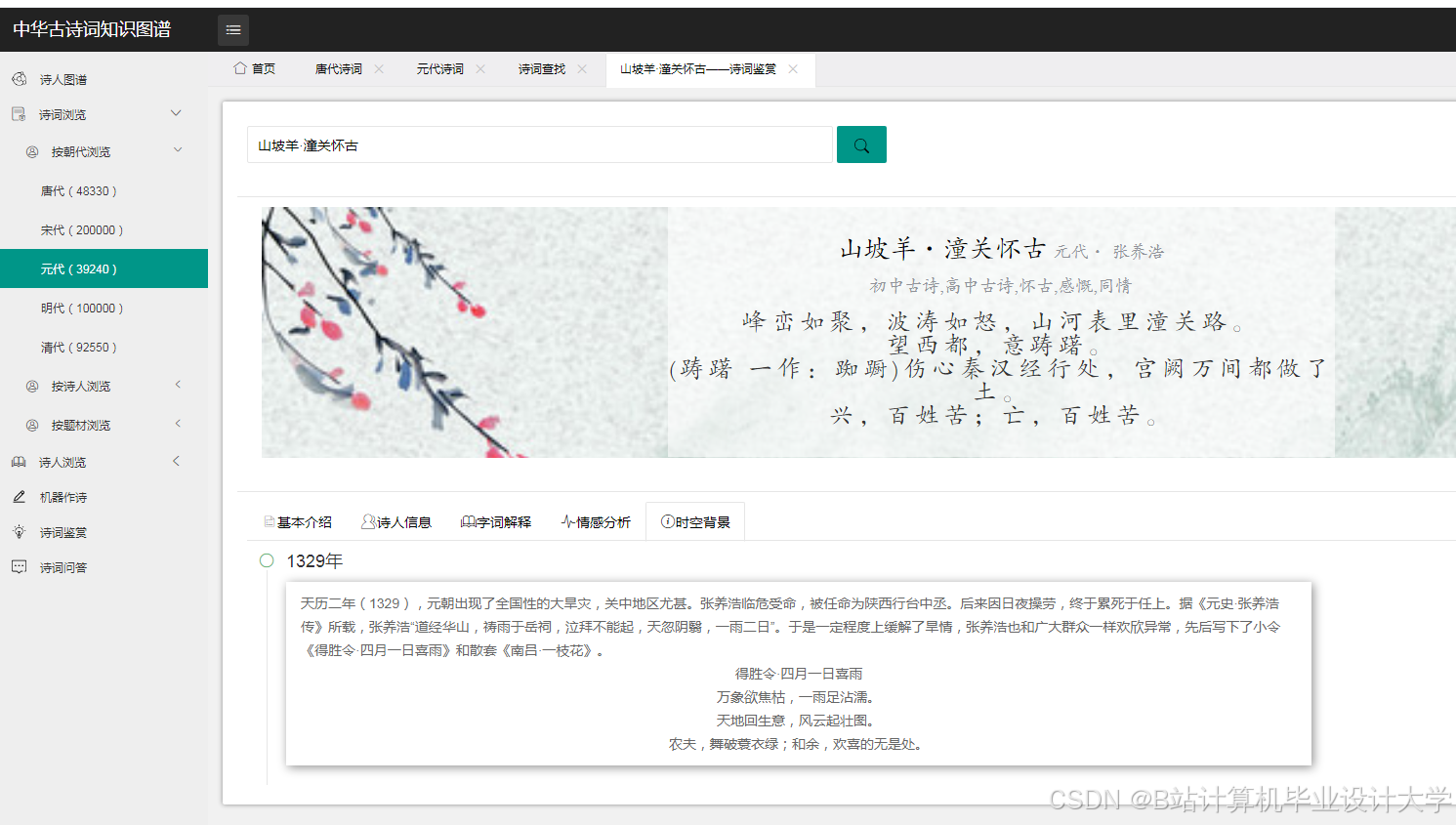
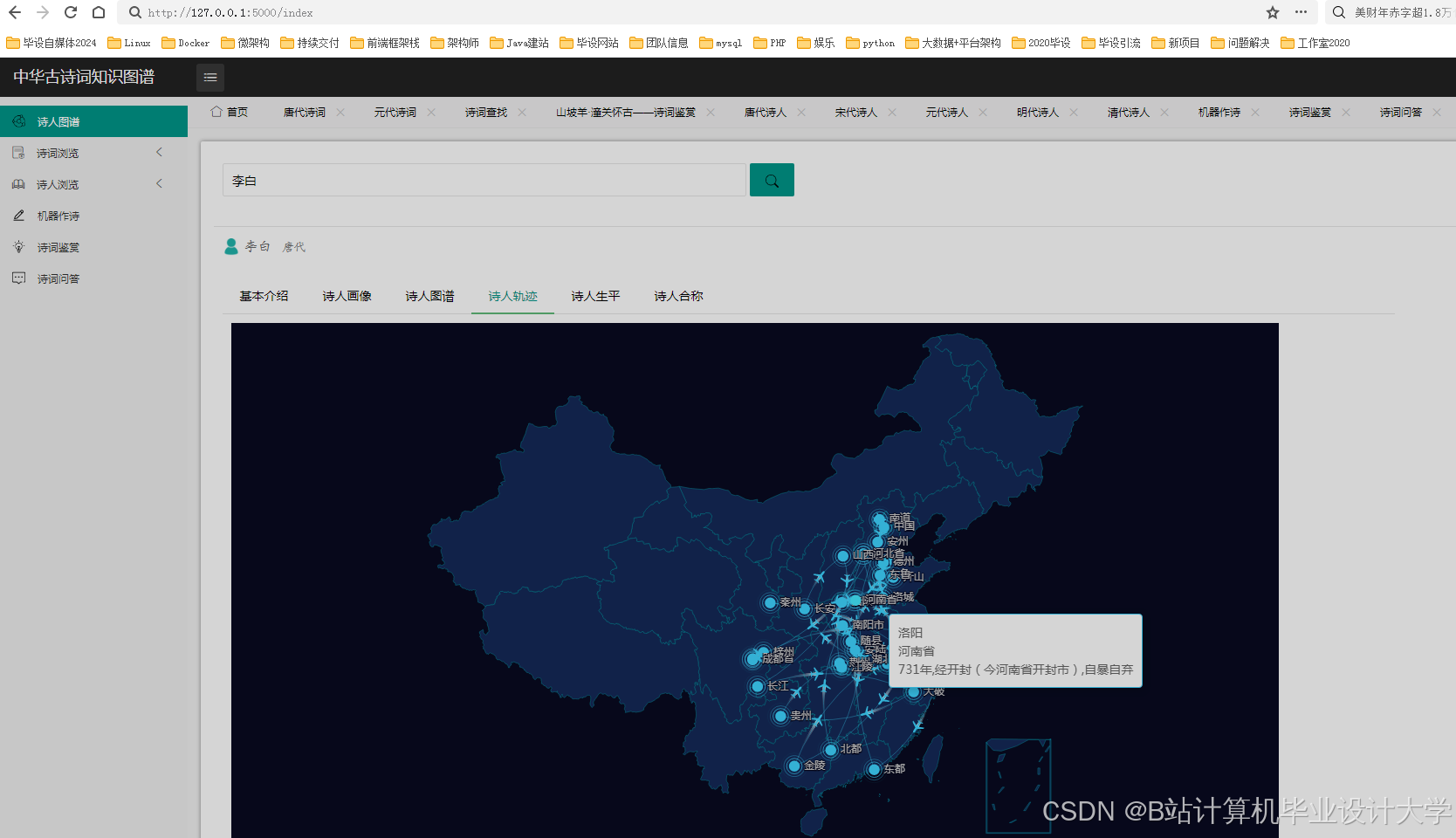
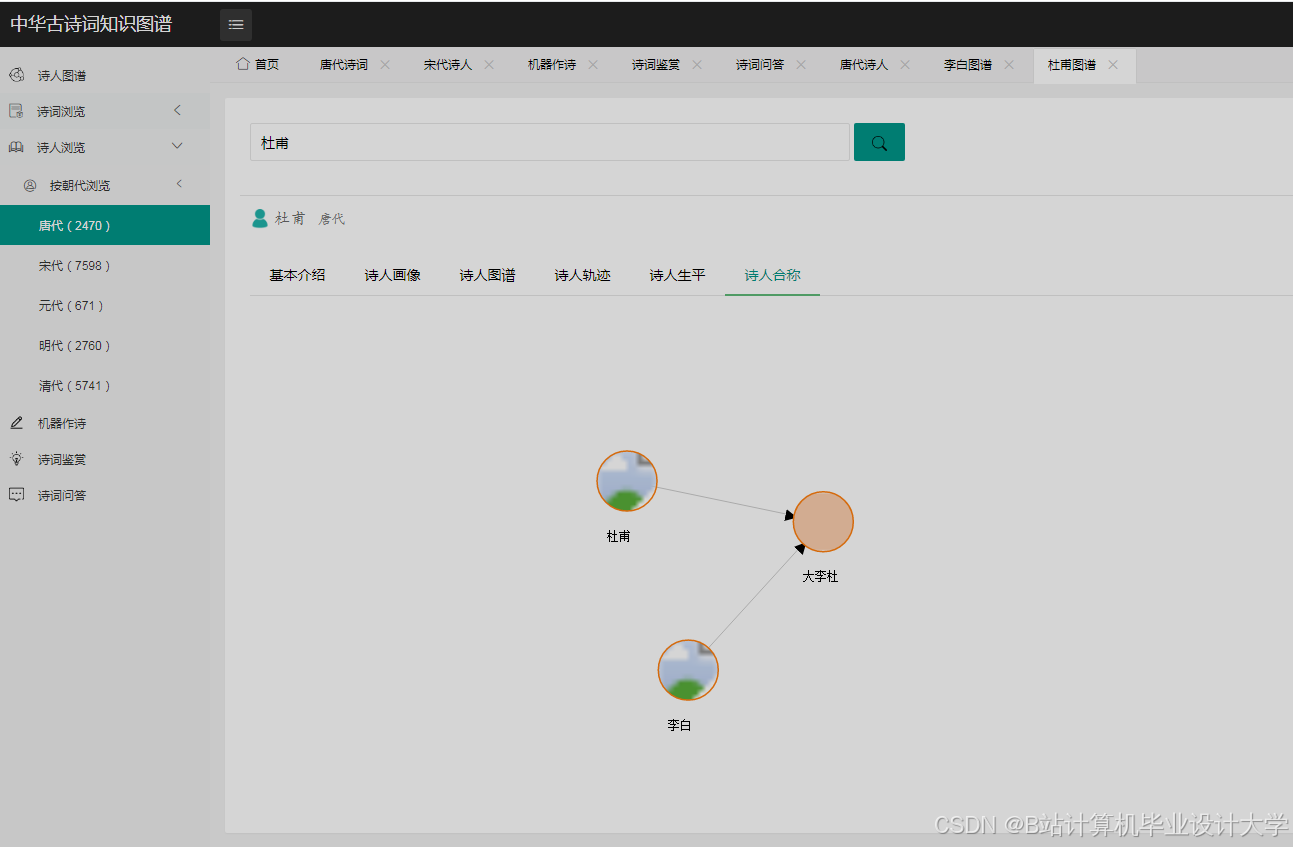
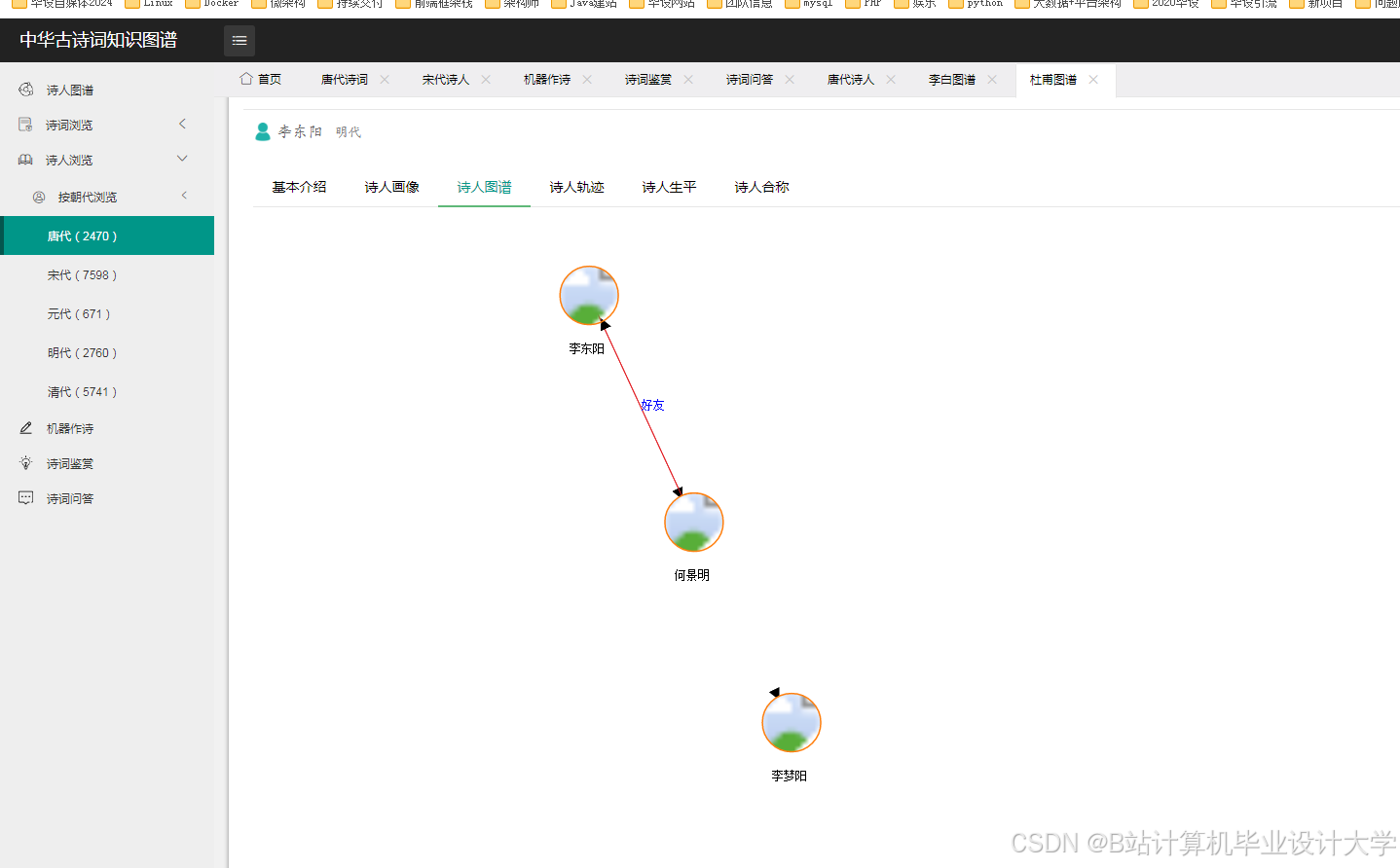
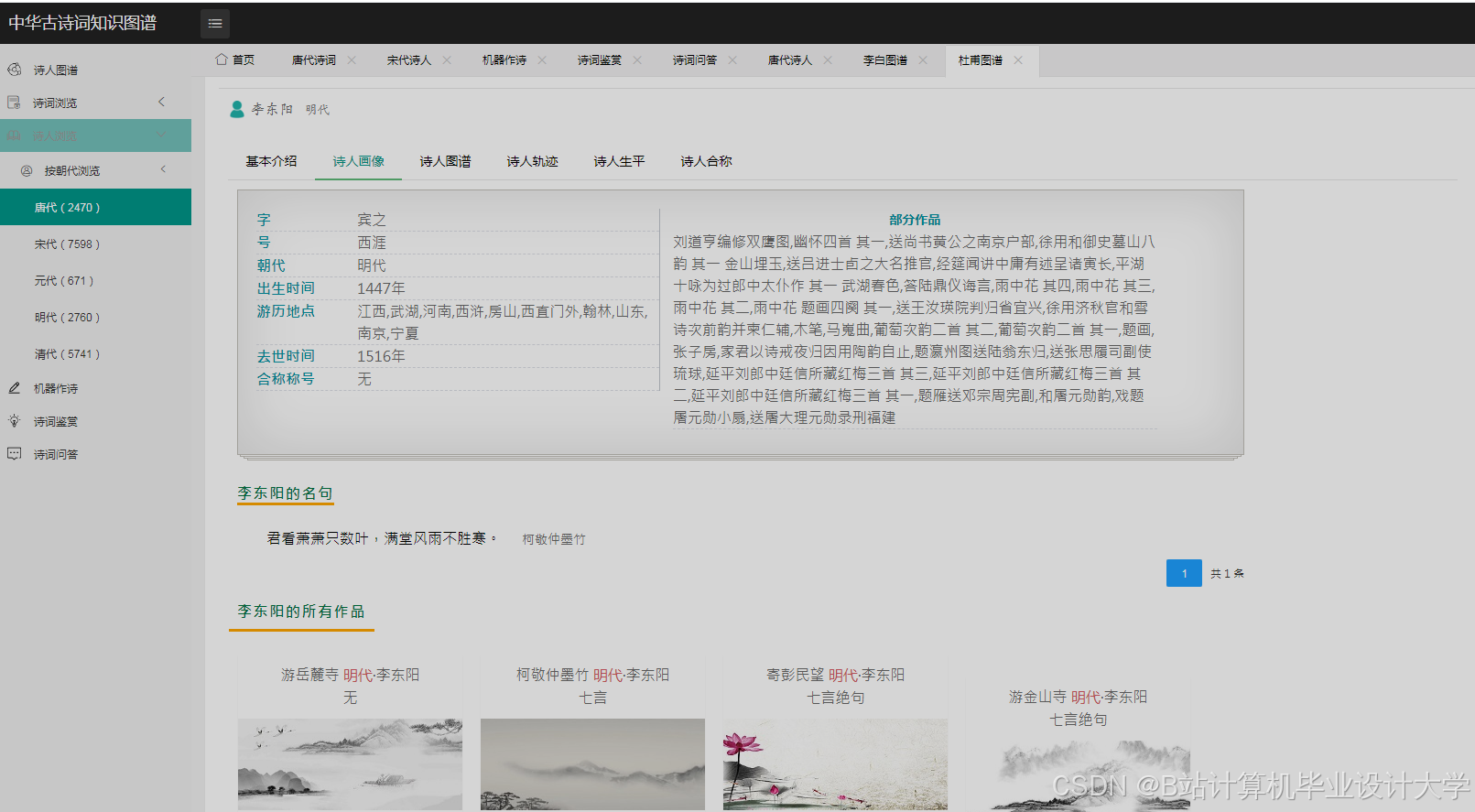
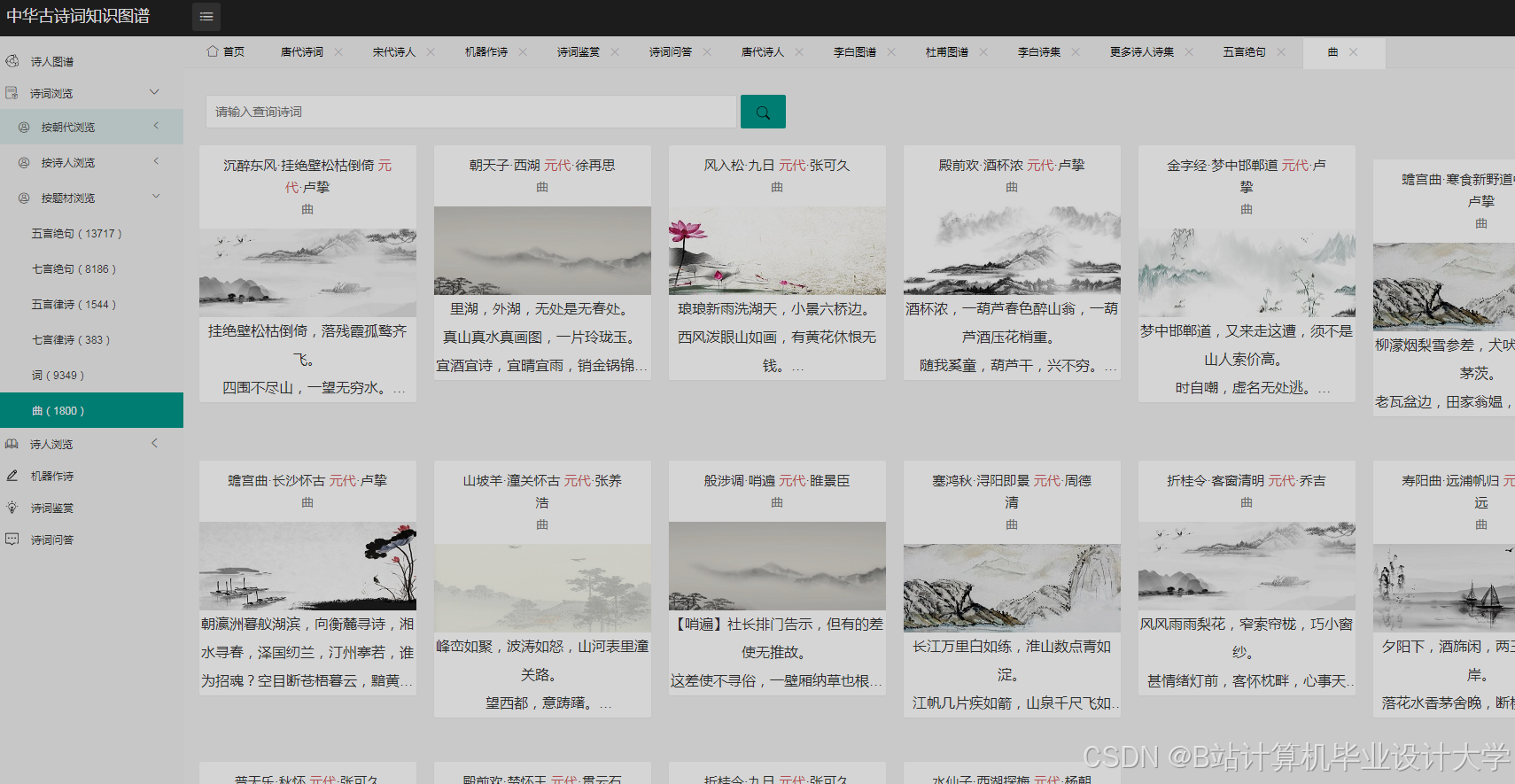
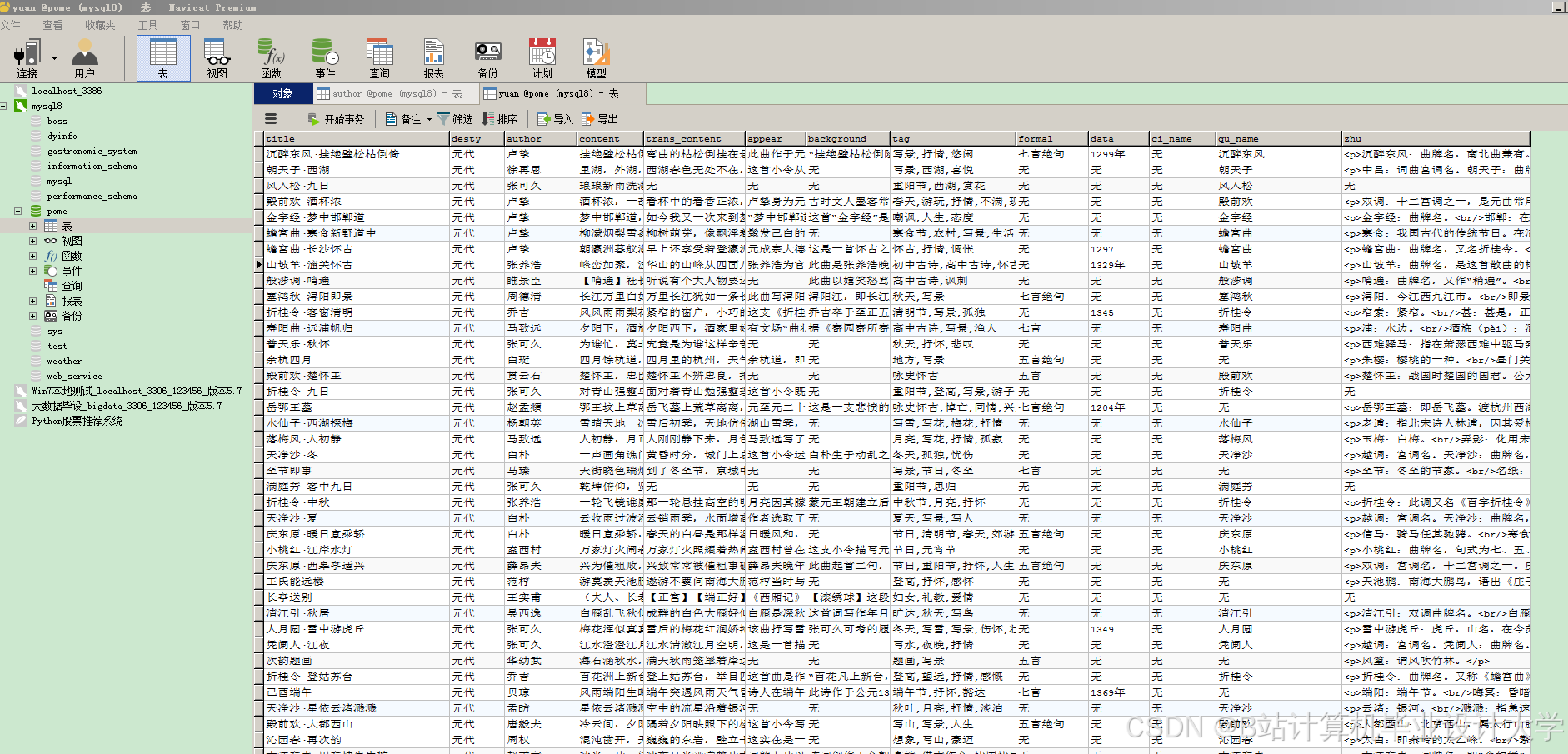
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











