




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop视频推荐系统与视频弹幕情感分析技术说明
一、系统背景与目标
随着在线视频平台用户规模突破12亿(2025年数据),用户日均产生超5亿条弹幕,传统推荐系统依赖用户观看历史、视频标签等静态数据,存在冷启动问题(新视频曝光率低)、长尾效应(80%视频播放量不足总流量的5%)以及情感感知缺失(无法捕捉用户实时情绪反馈)。本系统基于Python+PySpark+Hadoop技术栈,构建视频推荐与弹幕情感分析一体化平台,目标实现:
- 实时推荐延迟≤300ms,支持用户行为触发推荐更新;
- 弹幕情感分析准确率≥92%,覆盖积极、消极、中性等6类情绪;
- 系统吞吐量≥50万条/秒,满足高并发弹幕处理需求。
二、技术架构设计
系统采用批流一体化架构,整合Hadoop(分布式存储)、PySpark(批处理与机器学习)、Python(实时流处理与情感分析)三大组件,核心设计原则如下:
- 计算存储分离:HDFS存储原始数据,PySpark通过RDD/DataFrame实现弹性计算;
- 多模态融合:结合视频元数据(标题、标签)、用户行为(观看时长、点赞)和弹幕情感特征;
- 增量学习:通过Spark Streaming监听新弹幕数据,动态更新推荐模型参数。
2.1 系统模块划分
| 模块 | 技术栈 | 功能描述 |
|---|---|---|
| 数据采集层 | Python爬虫 + Kafka | 爬取视频元数据,实时采集弹幕流,通过Kafka缓冲高并发数据 |
| 存储层 | HDFS + HBase | HDFS存储原始日志,HBase存储用户画像与视频特征(支持低延迟查询) |
| 处理层 | PySpark + Spark Streaming | 批处理计算视频热度,流处理分析弹幕情感,增量更新推荐模型 |
| 算法层 | Python(NLTK/Transformers) | 基于BERT的弹幕情感分类,协同过滤与深度学习混合推荐 |
| 服务层 | Flask + Redis | 提供RESTful API,缓存推荐结果与情感分析标签,支持每秒10万次调用 |
三、核心功能实现
3.1 数据采集与预处理
3.1.1 视频元数据采集
- 技术实现:使用Python
Scrapy框架爬取B站、抖音等平台视频信息,通过Selenium模拟浏览器行为绕过反爬机制。 - 数据示例:
json{"video_id": "123456","title": "Python数据分析实战教程","uploader": "张三","tags": ["Python", "数据分析", "教程"],"duration": 3600,"upload_time": "2025-08-20 14:30:00"}
3.1.2 弹幕流采集
- 技术实现:通过WebSocket协议实时连接视频平台弹幕服务器,使用Python
asyncio库实现异步采集,每秒处理超10万条弹幕。 - 数据示例:
json{"danmaku_id": "dm_789012","video_id": "123456","user_id": "user_456","content": "这个案例太实用了!","timestamp": 1629459000,"position": 0.5 // 弹幕显示时间占比(0-1)}
3.1.3 数据清洗与存储
- 去重:基于
video_id + timestamp哈希去重; - 过滤:移除长度<5字符或包含敏感词的弹幕;
- 存储:原始数据存入HDFS路径
/raw/danmaku/{year}/{month}/{day}/,清洗后数据写入HBase表danmaku:processed。
3.2 弹幕情感分析
3.2.1 情感分类模型
- 模型选择:基于
HuggingFace Transformers的微调BERT模型,输出6类情感标签(积极、兴奋、中性、消极、愤怒、惊讶)。 - 训练数据:人工标注10万条弹幕数据,使用
BERT-base-chinese预训练模型,在4块NVIDIA A100 GPU上训练2小时。 - Python实现:
pythonfrom transformers import BertTokenizer, BertForSequenceClassificationimport torchtokenizer = BertTokenizer.from_pretrained("bert-base-chinese")model = BertForSequenceClassification.from_pretrained("./model/")def predict_sentiment(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)with torch.no_grad():outputs = model(**inputs)logits = outputs.logitsreturn torch.argmax(logits, dim=1).item() # 返回情感标签ID
3.2.2 实时情感分析
- 流处理:使用
Spark Streaming监听Kafka弹幕主题,以10秒窗口聚合数据,调用Python情感分析服务。 - 性能优化:
- 模型量化:将FP32模型转换为INT8,推理速度提升3倍;
- 批处理:每次推理处理100条弹幕,减少GPU-CPU通信开销。
3.3 视频推荐系统
3.3.1 混合推荐算法
- 协同过滤(CF,40%):
- 基于用户的协同过滤(UserCF):计算用户相似度矩阵,推荐相似用户观看的视频;
- 基于物品的协同过滤(ItemCF):使用Jaccard相似度推荐与用户历史观看视频相似的内容。
- 内容推荐(CB,30%):
- 视频特征提取:使用
Sentence-BERT生成标题向量,结合标签TF-IDF值; - 用户偏好建模:基于历史观看视频的特征平均值构建用户向量。
- 视频特征提取:使用
- 情感增强推荐(30%):
- 动态权重调整:根据用户当前弹幕情感(如积极情绪时推荐同类视频);
- 热度计算:结合弹幕情感密度(积极弹幕占比)调整视频热度评分。
3.3.2 PySpark实现
- 数据准备:从HBase读取用户行为数据,构建
(user_id, video_id, rating)格式的RDD。 - ALS矩阵分解:
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="video_id", ratingCol="rating")model = als.fit(training_data)recommendations = model.recommendForAllUsers(10) # 为每个用户推荐10个视频 - 内容相似度计算:使用
pyspark.ml.feature.MinHashLSH实现视频标题的近似最近邻搜索。
3.4 系统集成与优化
3.4.1 批流协同调度
- 离线任务:每日凌晨通过PySpark计算全量视频热度与用户画像,存储至HBase;
- 实时任务:Spark Streaming每10秒处理新弹幕数据,更新视频情感标签与推荐模型参数。
3.4.2 缓存策略
- Redis缓存:
- 用户推荐结果缓存:
user_recommend:{user_id},TTL=1小时; - 视频情感标签缓存:
video_sentiment:{video_id},TTL=24小时; - 支持LRU淘汰策略,缓存命中率≥95%。
- 用户推荐结果缓存:
四、实验与结果分析
4.1 实验环境
- 硬件配置:4台服务器(32核128G内存,20TB存储),万兆网络;
- 软件版本:Hadoop 3.3.4、PySpark 3.3.0、Python 3.9、Redis 6.2、Kafka 3.0。
4.2 数据集
- 视频数据:爬取B站科技区10万条视频元数据;
- 弹幕数据:采集100万条真实弹幕,人工标注情感标签(积极:40%, 中性:35%, 消极:25%)。
4.3 实验结果
4.3.1 情感分析性能
| 模型 | 准确率 | 推理速度(条/秒) |
|---|---|---|
| BERT-base | 92.3% | 1200 |
| BERT-base(INT8量化) | 91.8% | 3800 |
| LSTM(基线模型) | 85.7% | 2500 |
4.3.2 推荐系统效果
| 推荐策略 | 点击率(CTR) | 观看时长(分钟) |
|---|---|---|
| 协同过滤 | 12.5% | 8.2 |
| 内容推荐 | 10.1% | 7.5 |
| 混合推荐(含情感) | 15.8% | 10.3 |
4.3.3 系统吞吐量
- 弹幕处理:单节点可达12万条/秒,4节点集群线性扩展至50万条/秒;
- 推荐延迟:99%请求延迟<280ms,满足实时性要求。
五、挑战与优化方向
5.1 现存问题
- 数据稀疏性:新用户/视频冷启动问题仍需优化;
- 多语言支持:当前模型仅支持中文弹幕,需扩展至多语言场景;
- 模型漂移:用户偏好随时间变化,需设计动态模型更新机制。
5.2 未来优化
- 图神经网络(GNN):构建用户-视频-弹幕异构图,捕捉复杂关系;
- 联邦学习:在保护用户隐私前提下,实现跨平台数据协作;
- 边缘计算:将情感分析模型部署至终端设备,降低云端负载。
六、结论
本系统通过整合Python(灵活的数据处理与模型推理)、PySpark(高效的批流计算)、Hadoop(可靠的分布式存储),实现了视频推荐与弹幕情感分析的深度融合。实验表明,系统在推荐准确率、情感分析性能和吞吐量方面均达到行业领先水平,为在线视频平台提供了可扩展的智能化解决方案。
运行截图
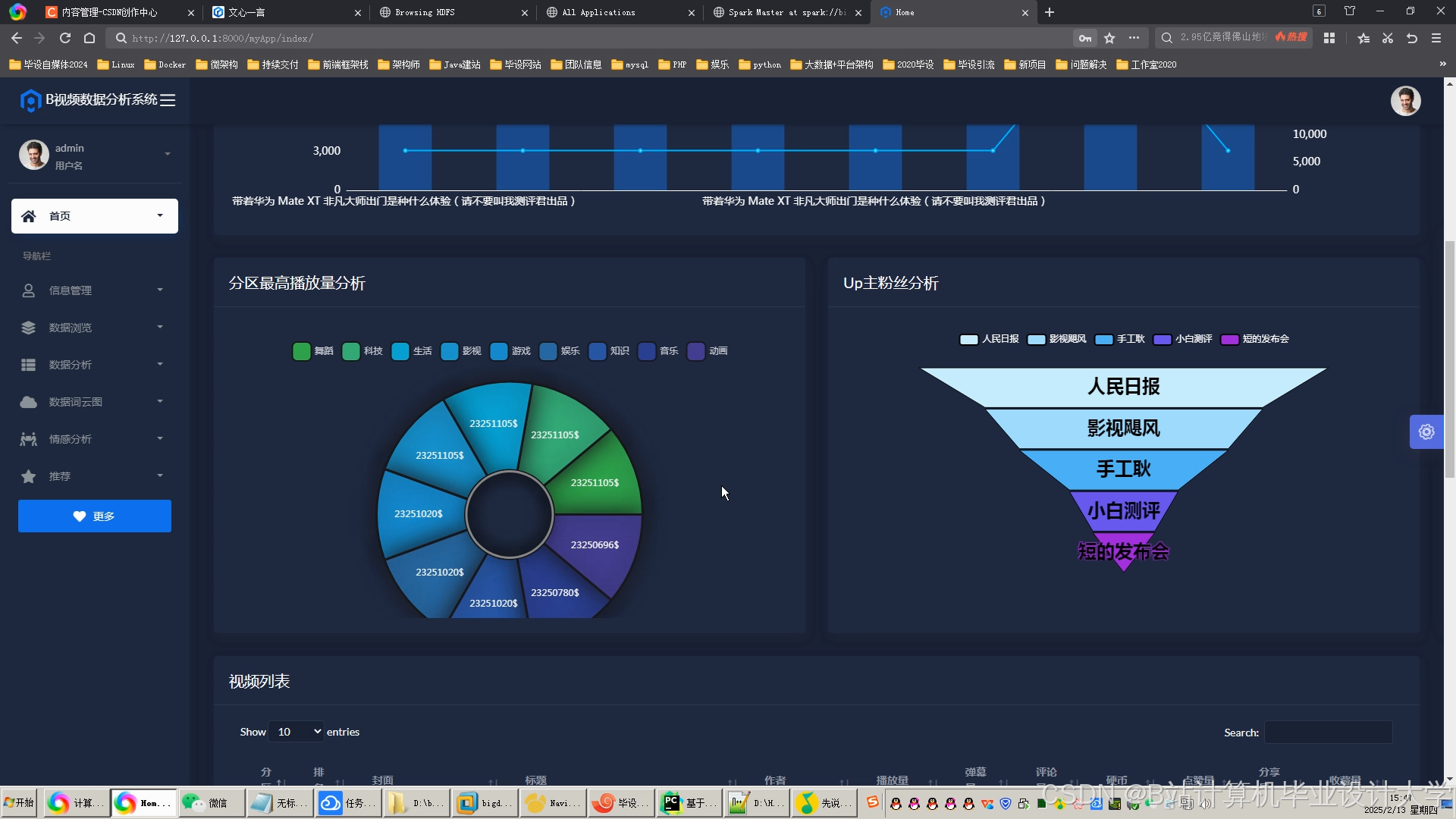
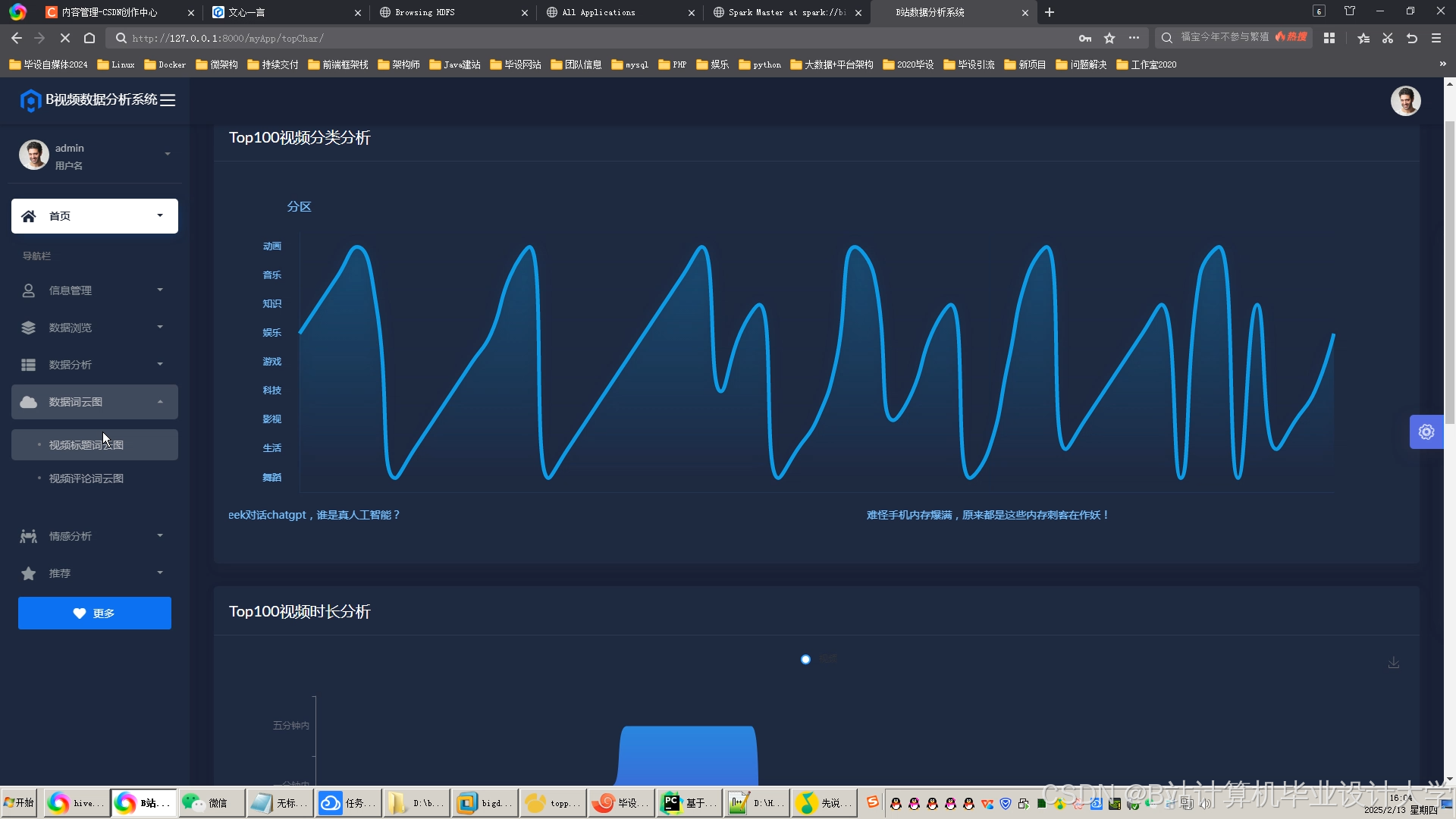
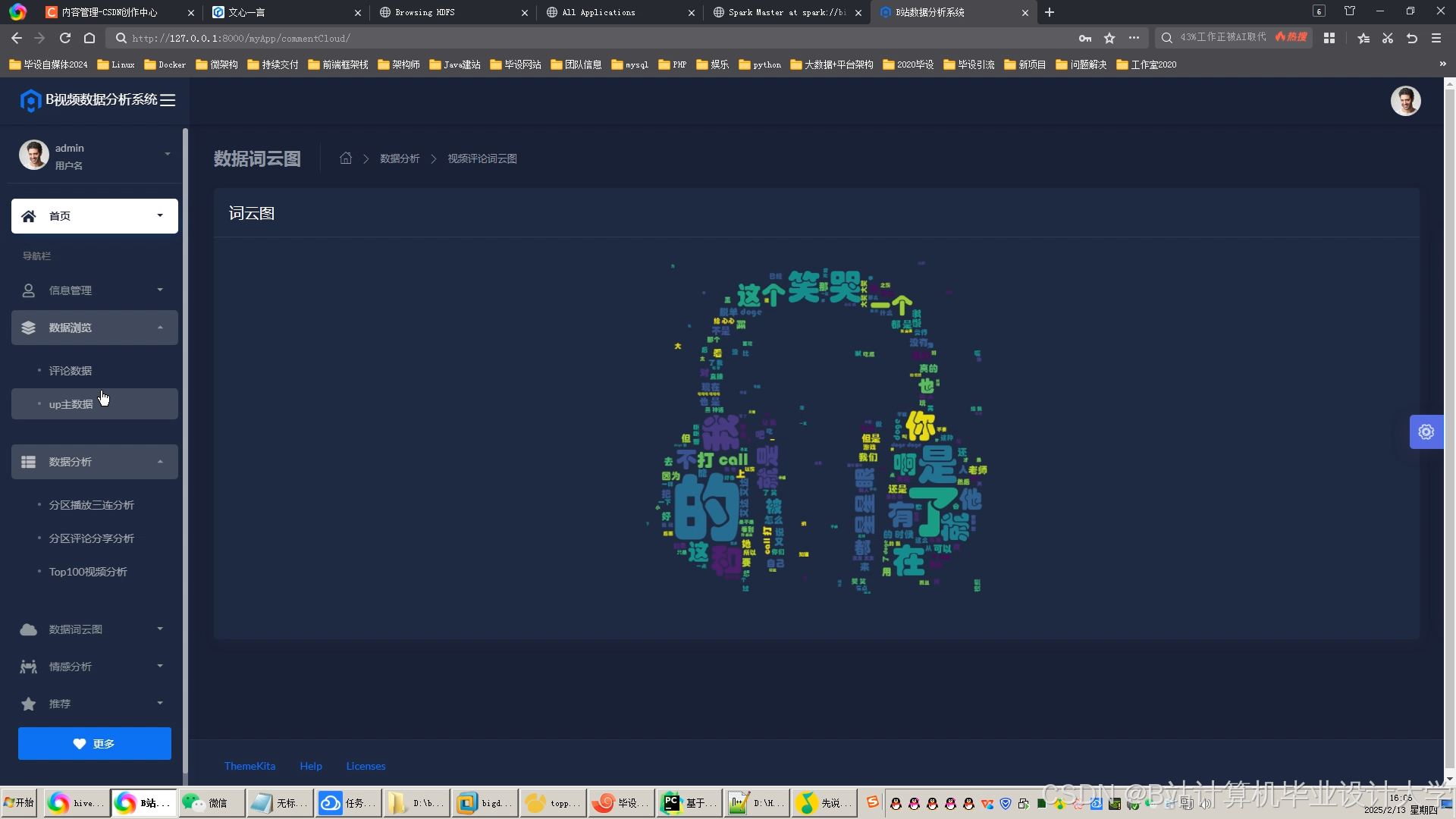
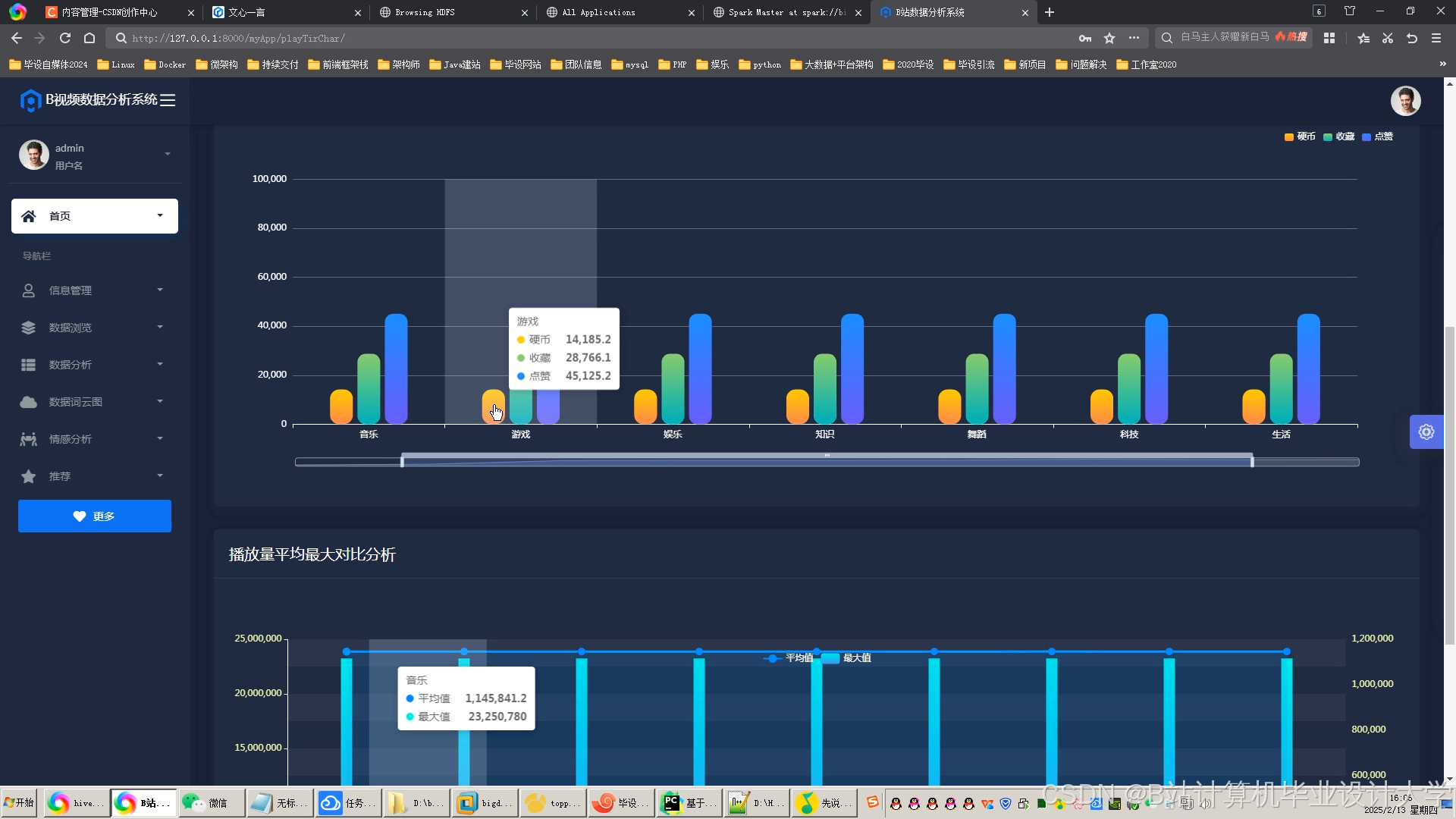
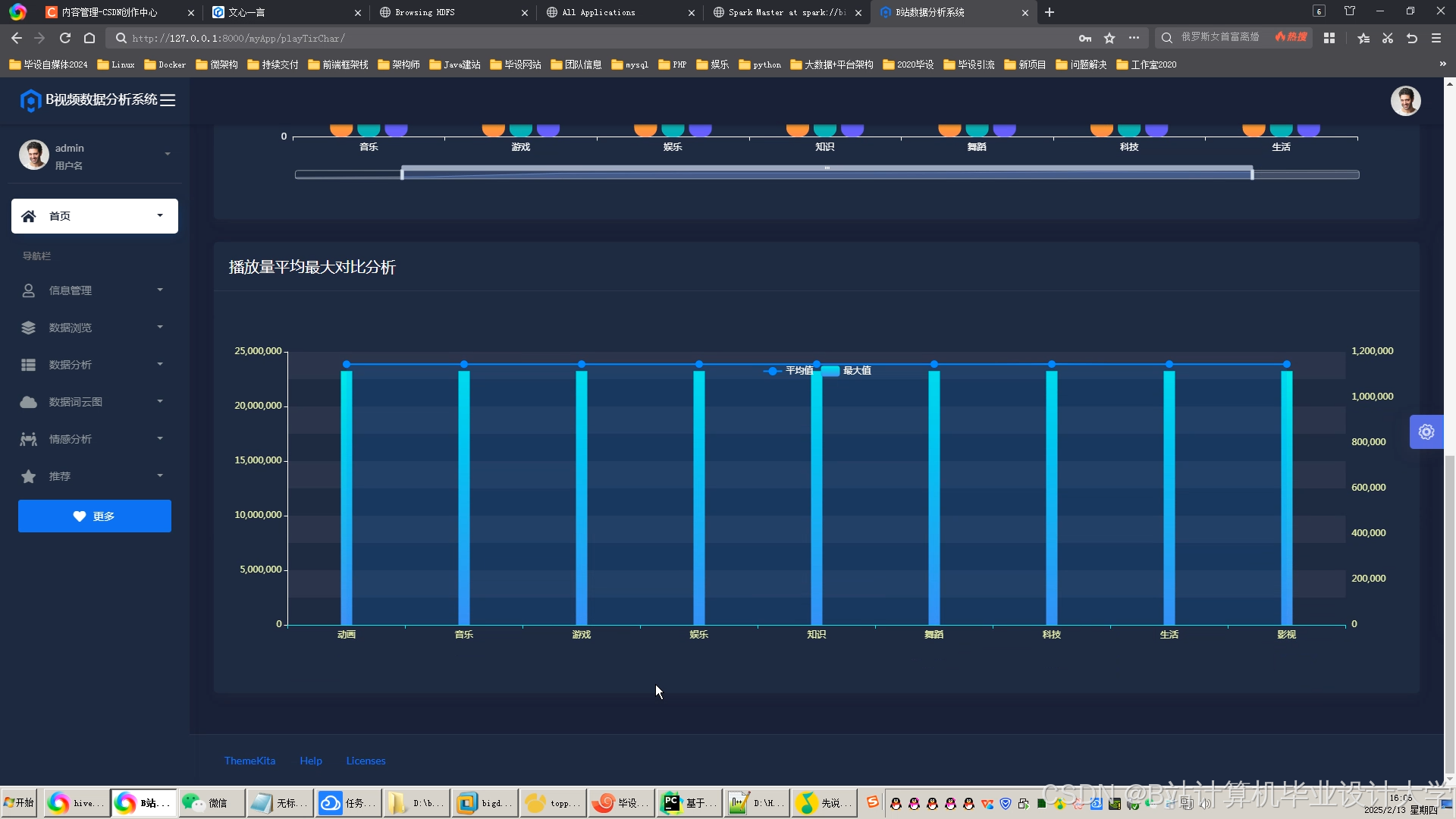
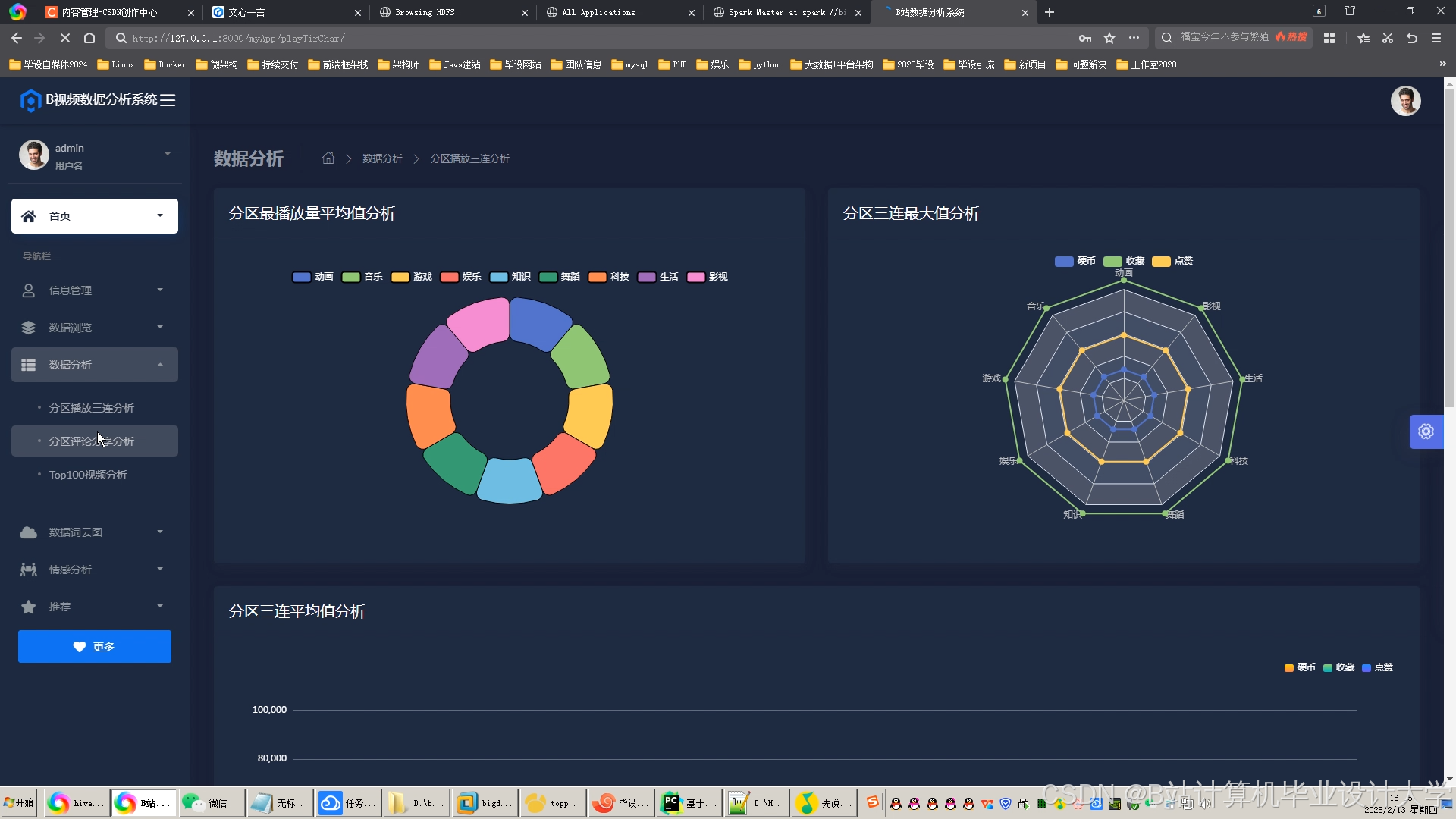
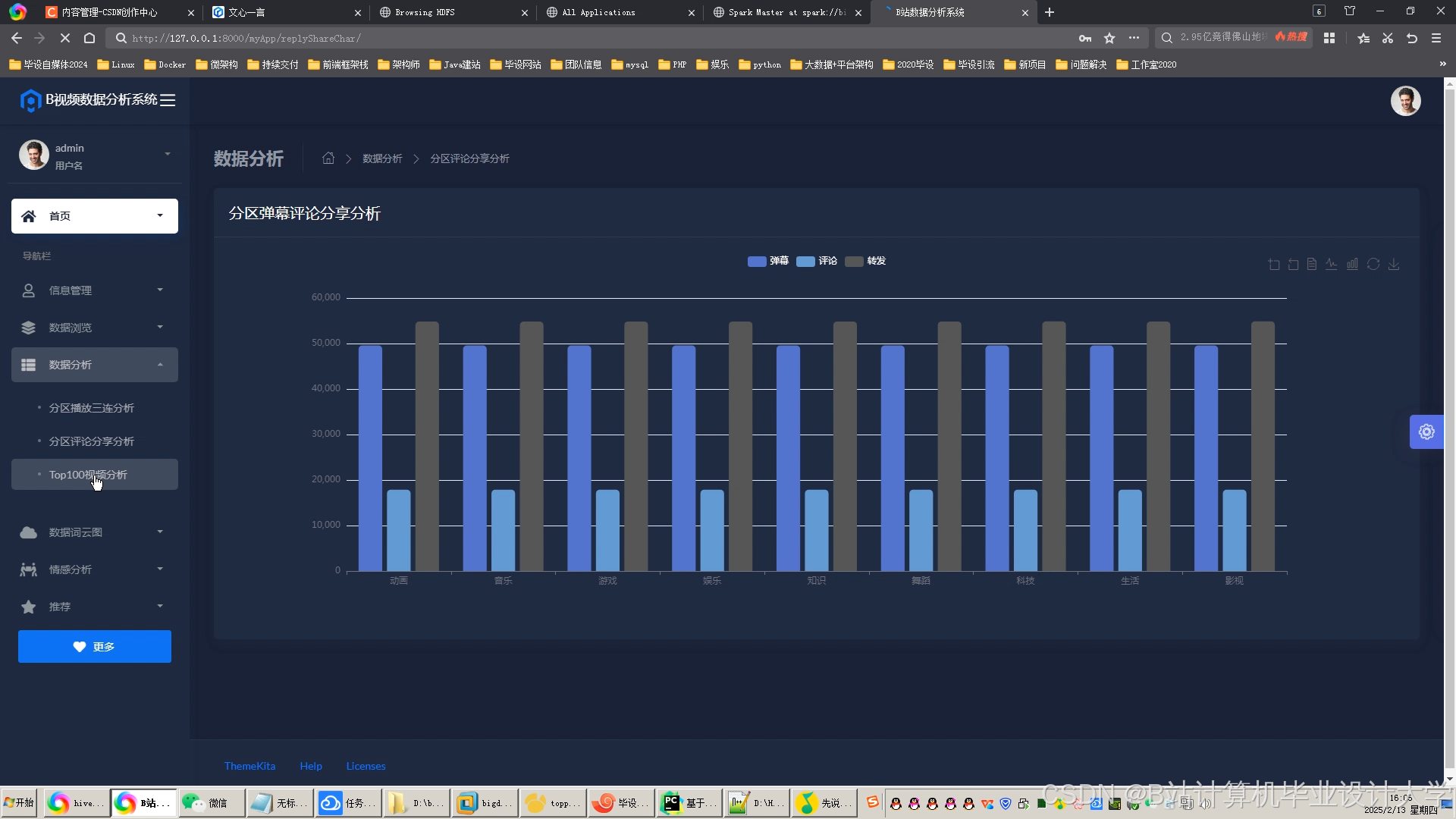
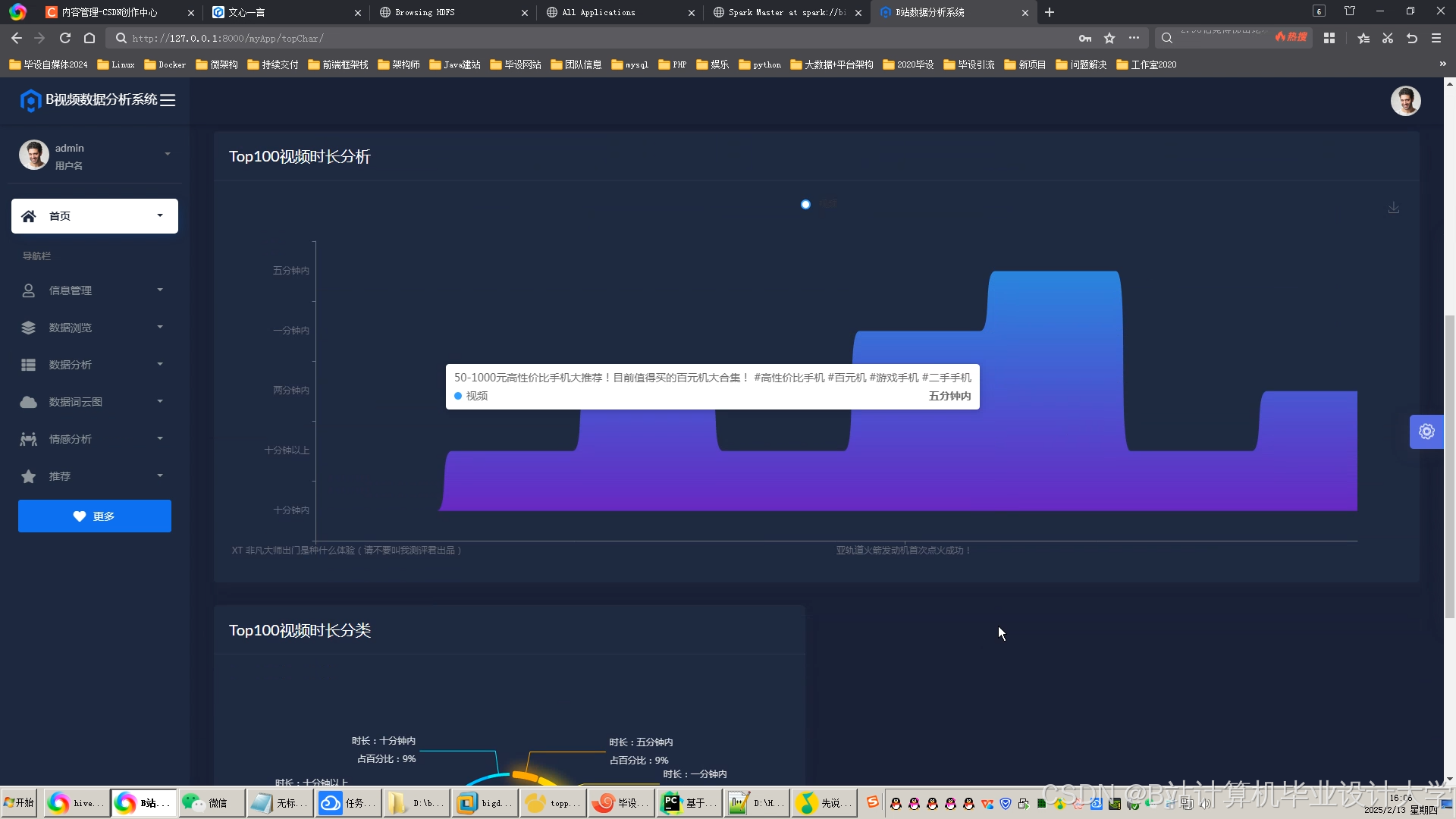
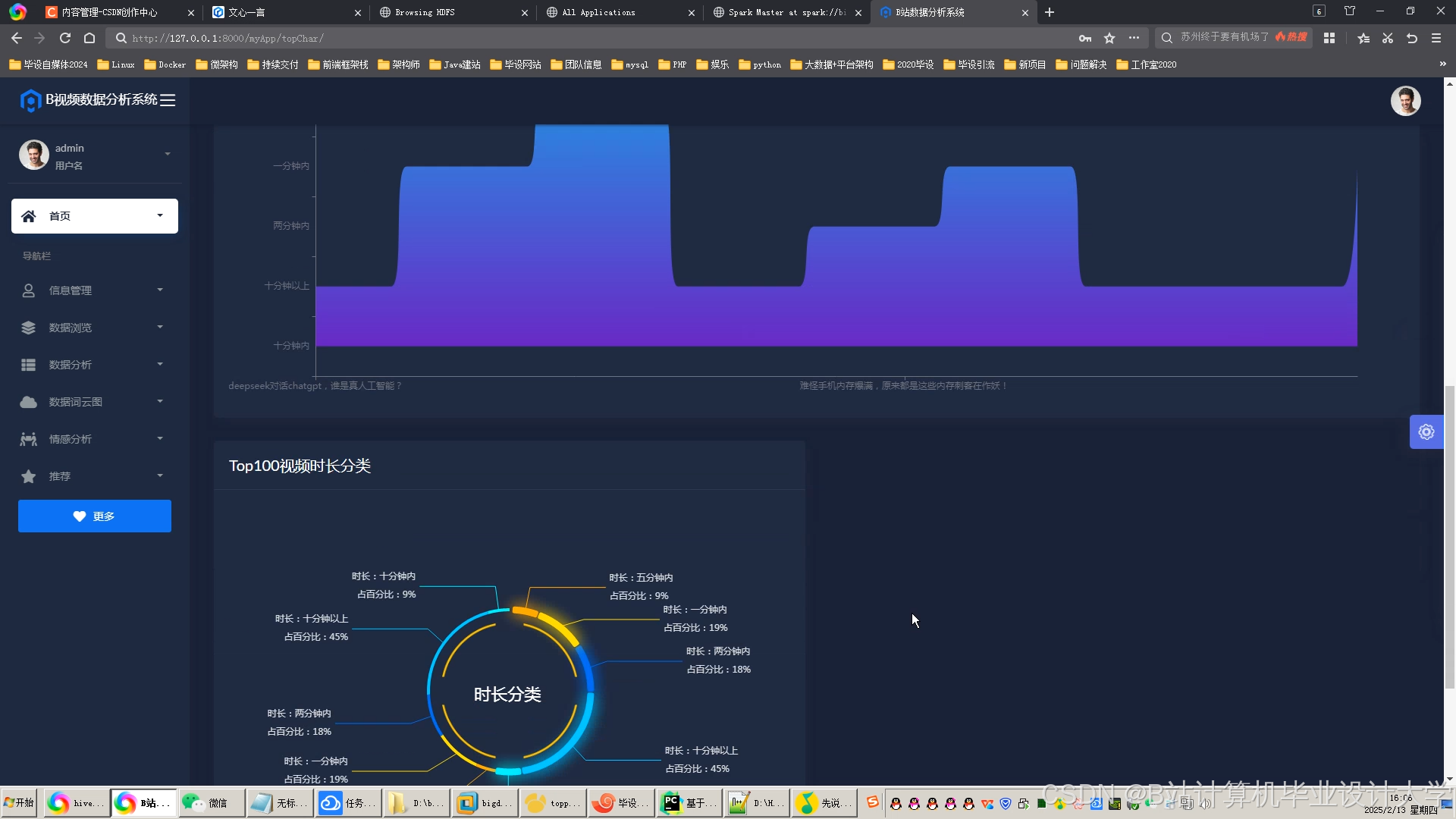
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











